
How GoogleNet (aka Inception V1) showed that size doesn't matter
The legendary CNN architecture that ranked #1 in ImageNet 2014 challenge


In 2014, two deep learning architectures entered a bar.
One said, "I have 138 million parameters."
The other said, "I have 6.8 million... and a first place trophy."
Guess who got the last laugh?
Welcome to the story of Inception V1, also known as GoogleNet.
This is not just a lecture recap. It is a tale of how clever architectural decisions beat brute force in the world of convolutional neural networks.
The setup: Why Inception V1 was needed
By 2014, the deep learning community had one obsession: Depth.
AlexNet had already shown in 2012 that deeper networks could smash image classification tasks.
VGGNet, introduced soon after (architecture shown in the image below), took this to the extreme: stack 3x3 filters again and again until your GPU cries.

VGGNet had:
138 million parameters
Only 3x3 convolutions
No shortcuts, no frills
Excellent accuracy, but painfully slow and expensive to train
It was a beautiful, brute-force solution. But like trying to drive a tank to the grocery store, it was a bit… much.
Enter GoogleNet: What If We Stop Being Extra?
The researchers at Google Brain asked a smart question:
"Can we build something deep and powerful, but also efficient?"
Their answer was GoogleNet, or as it was later renamed, Inception V1.

The core idea?
Why use one type of filter when you can use all of them at once?
The Inception module: Organized chaos
Each Inception module looks like a miniature neural network on its own. Inside one module, you have:
A 1x1 convolution
A 1x1 convolution followed by a 3x3
A 1x1 convolution followed by a 5x5
A 3x3 max pool followed by a 1x1 convolution
All of these happen in parallel. Then the results are concatenated across the channel dimension.


If VGGNet was a straight-laced student solving math problems line-by-line, GoogleNet was the kid who built a math-solving robot to do multiple steps at once.
But wait - Why 1x1 convolutions?
Glad you asked. These were not just added for symmetry.
1x1 convolutions reduce channel depth before applying heavier 3x3 or 5x5 convolutions.
This is like compressing a large PDF before emailing it - you get the same content, but with much less effort.
Example:
Original: 5x5x192 = 4800 weights
After 1x1 compression: 5x5x16 + 192 = 592 weights
That is a ~90% reduction in computation.
So the architecture became both deep (multiple modules in series) and wide (parallel operations inside a module) - without the bloated parameter count.

The numbers: GoogleNet vs VGG
How did it do on our the 5-Flowers dataset?
We put Inception V1 to the test on our good old 5-class Flowers dataset.

Quick recap of our journey so far:

Linear model: 40% accuracy, no activation
Fully connected MLP: Still 40%, lower loss
Regularization tricks: 50-60% accuracy
Transfer learning (ResNet): 80% validation, 100% training
AlexNet (PyTorch): 90% validation, 95% training
VGG (50 epochs): 85% validation, 75% training (slow but underfitting)
Now: Inception V1
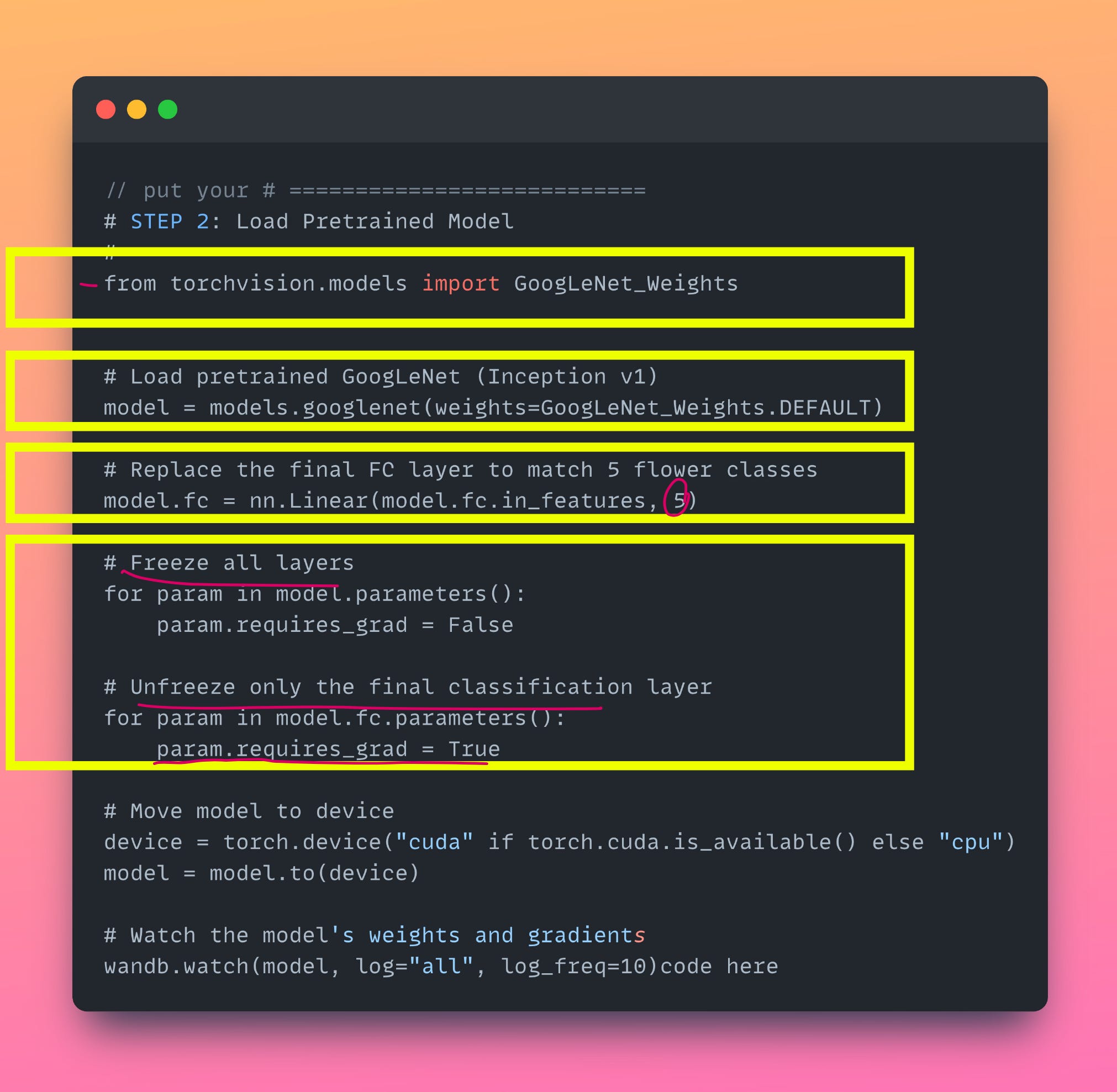
The only parts in the code where changes are made compared to say VGG is show below. I have also linked the entire Google Colab notebook at the end of this article.
Code

Inception V1 Results:
Training Accuracy: 86%
Validation Accuracy: 87-88%
Execution Time: ~1.5 hours for 50 epochs
Still underfitting slightly - but solid and stable
Compared to VGG, Inception V1 trained faster, had fewer parameters, and gave better results.
AlexNet still edges out slightly for this specific dataset, but Inception is clearly a more scalable and elegant solution for larger real-world problems.

So what do we conclude?
We froze all GoogleNet layers and only trained the classifier.
The pretrained convolutional layers already work well on natural images (like flowers).
The classifier may not have fully adapted to the training set yet, but the validation set happens to align well with the ImageNet-style features.
📌 Conclusion: Higher validation accuracy in early epochs often indicates good generalization from pretrained features - not overfitting.
Here is the full GoogleNet architecture
GoogleNet was later renamed as InceptionV1

Why Inception V1 Was a Big Deal
It showed that smarter architecture beats raw depth.
It introduced parallel filter paths within modules.
It popularized 1x1 convolutions for dimensionality reduction.
It kept the parameter count lean - just 6.8 million.
It inspired future designs like Inception V3, Inception-ResNet, and beyond.
Want to see it in action?
I have done a full walkthrough in my lecture video, including implementation using PyTorch and Transfer Learning on the Flowers dataset.
🎥 Watch the full lecture here:
🧠 Explore the visual notes (highly recommended):
https://miro.com/app/board/uXjVIpFFPZI=/?share_link_id=473186286983
💻 Run the Google Colab notebook yourself:
https://colab.research.google.com/drive/1MnOomNZBwgR5tfpc7Fy7iyEEXGVRRGsc?usp=sharing
Closing thoughts
Deep learning research is a lot like fashion.
What is hot today might be outdated tomorrow.
But some things stand the test of time - and Inception V1 is one of them.
So, the next time someone says “just make it deeper,” tell them about the 1x1 convolutions.
Sometimes, less is more - as long as it is smarter.
Interested in learning AI/ML from us LIVE?
Check this out: https://vizuara.ai/live-ai-courses