
𝗪𝗵𝘆 𝗟𝗶𝗻𝗲𝗮𝗿 𝗥𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝗼𝗻 𝗜𝘀 𝗨𝗻𝘀𝘂𝗶𝘁𝗮𝗯𝗹𝗲 𝗳𝗼𝗿 𝗕𝗶𝗻𝗮𝗿𝘆 𝗖𝗹𝗮𝘀𝘀𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻?


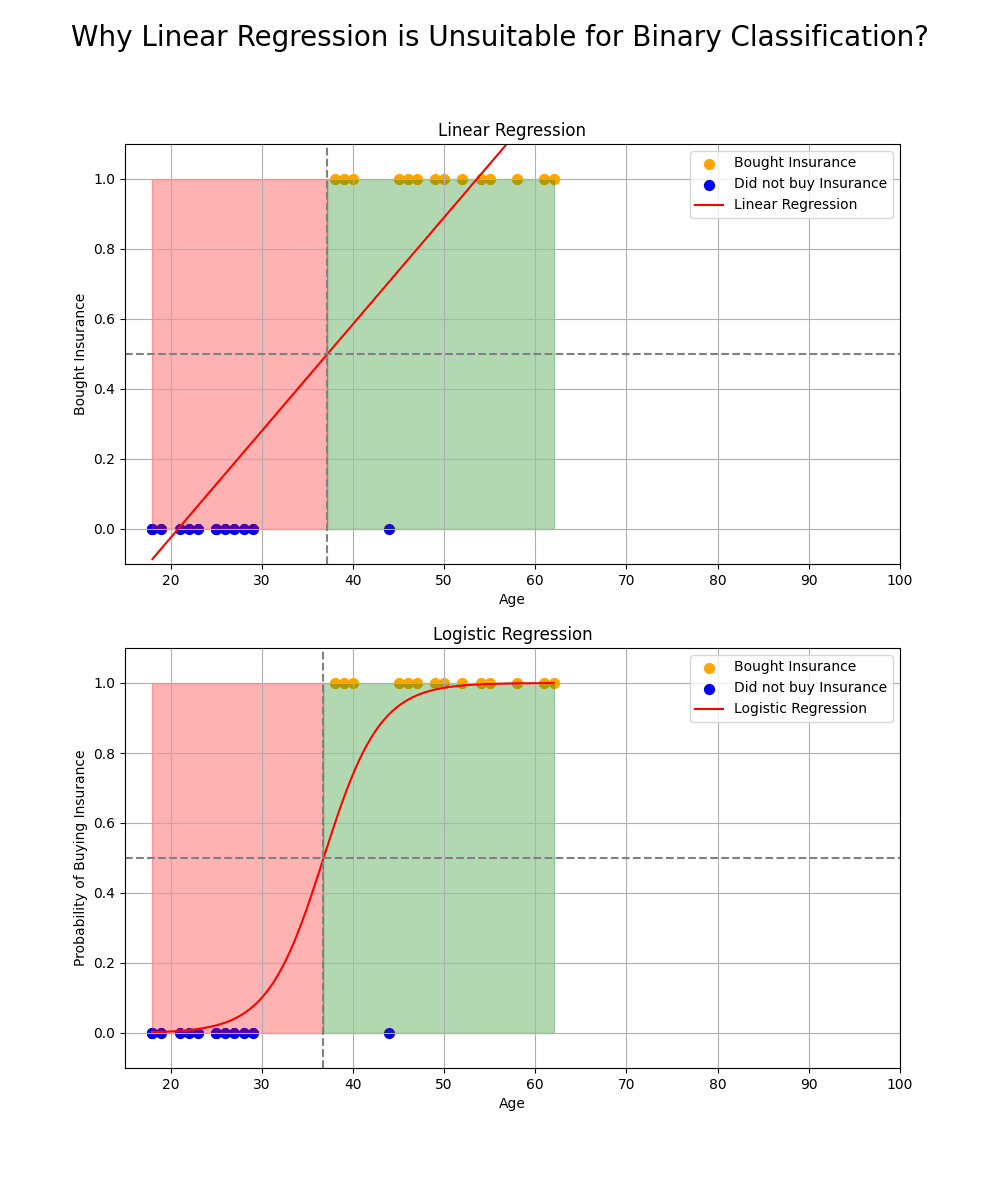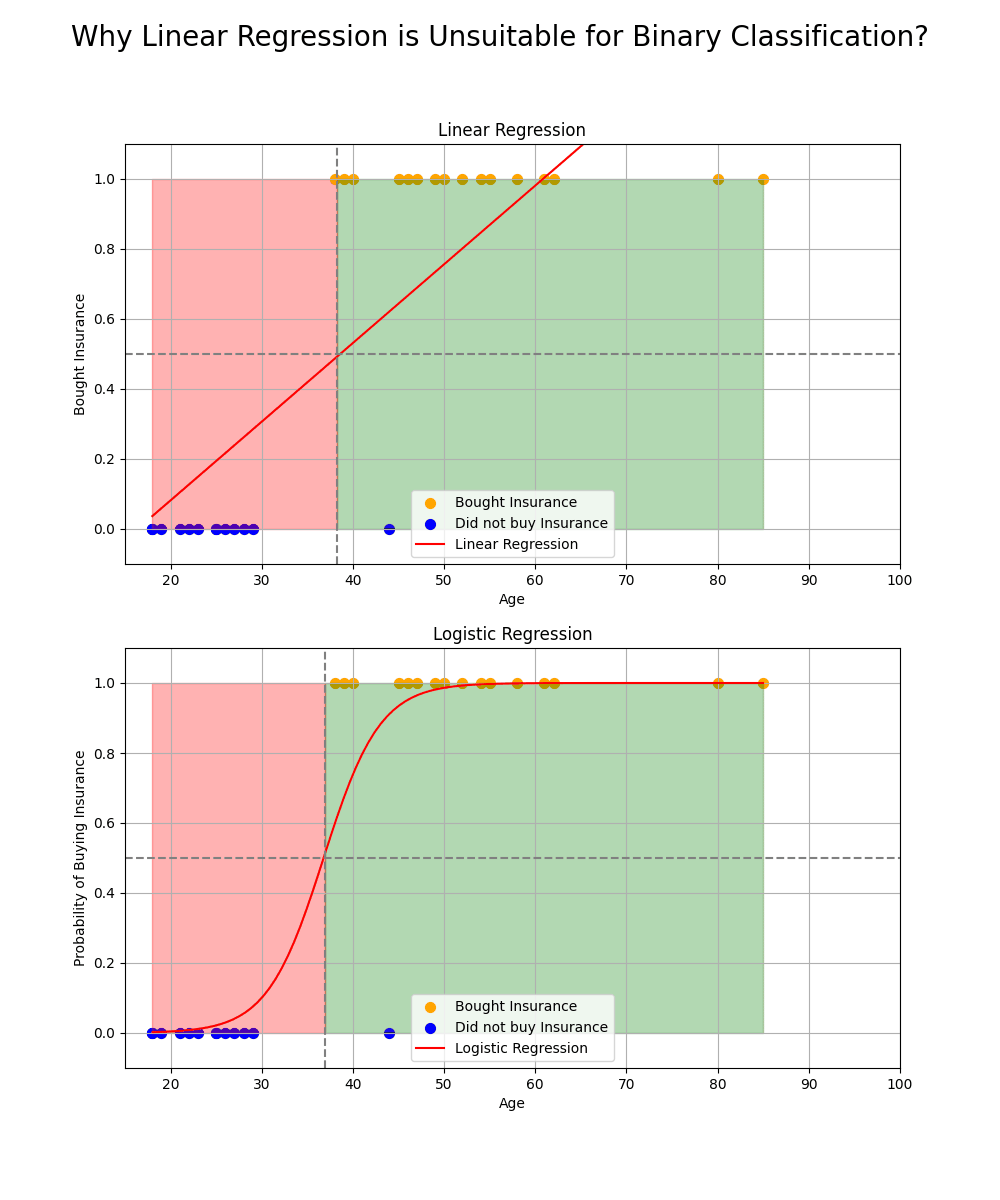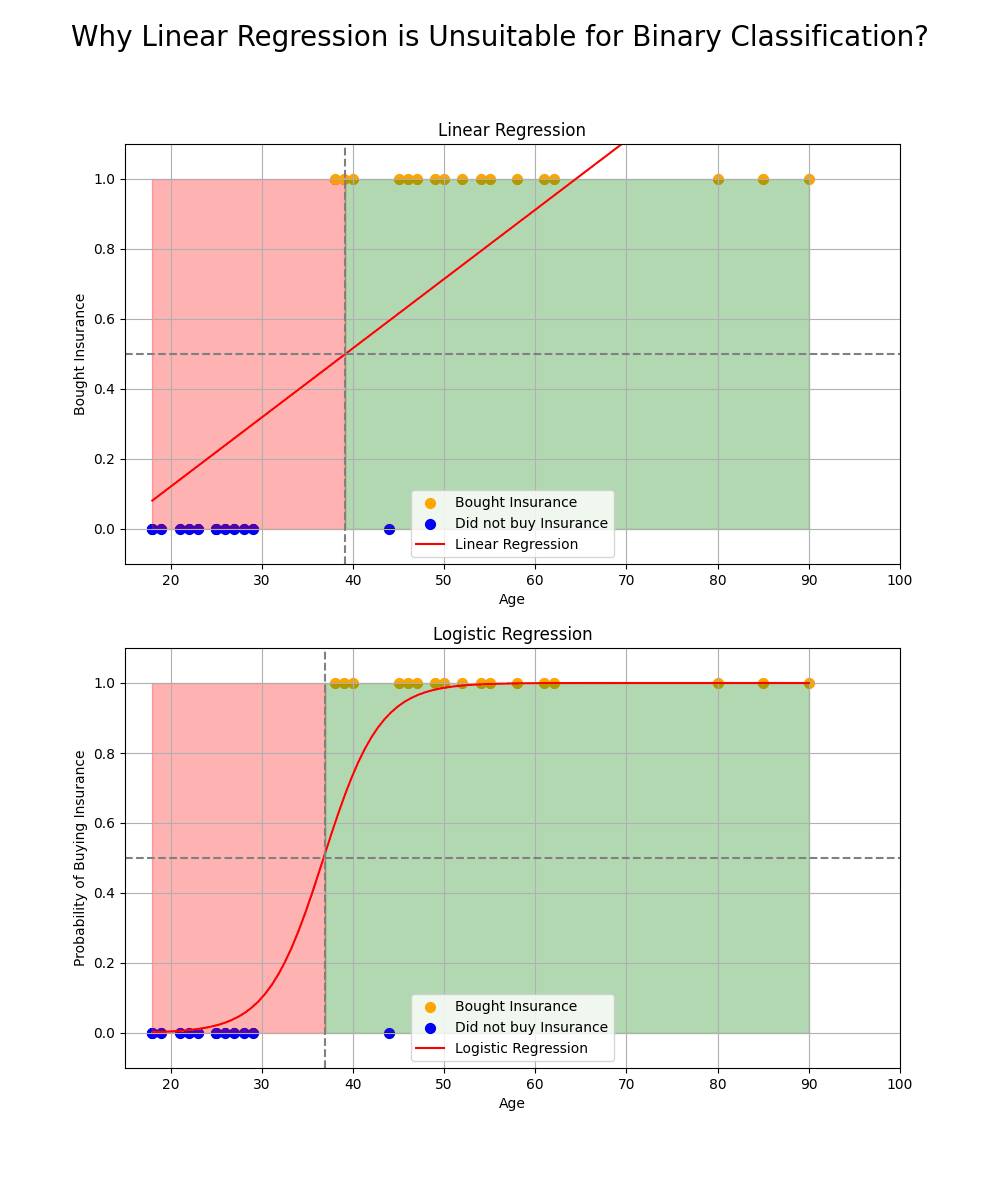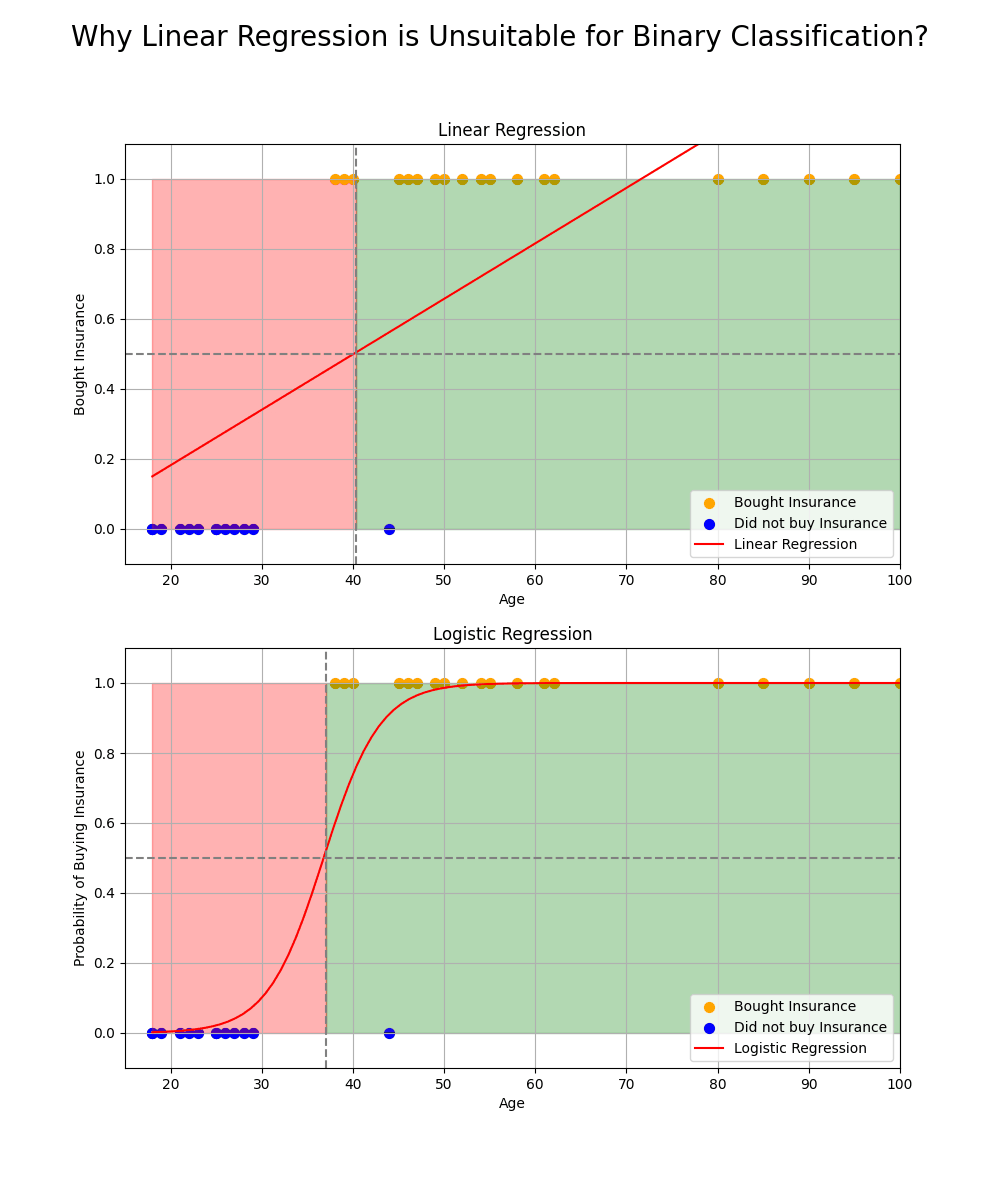
While linear regression can provide continuous output values, which may seem suitable for binary classification, it is not ideal for this purpose. Here are two key reasons why:
𝗡𝗼𝗻-𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗮𝘁 𝘁𝗵𝗲 𝗧𝗵𝗿𝗲𝘀𝗵𝗼𝗹𝗱: Linear regression typically uses a threshold to classify data, but this threshold function is not differentiable at the decision boundary. This lack of smoothness makes optimization difficult, particularly when using gradient-based methods like gradient descent.
𝗦𝗲𝗻𝘀𝗶𝘁𝗶𝘃𝗶𝘁𝘆 𝘁𝗼 𝗢𝘂𝘁𝗹𝗶𝗲𝗿𝘀: Linear regression is sensitive to outliers in the data, which can significantly affect the model's performance. Since the continuous output can range from negative to positive infinity, outliers can distort the decision boundary, leading to inaccurate classifications.
To address these issues, the threshold function (equation of separation plane) can be passed by a 𝘀𝗶𝗴𝗺𝗼𝗶𝗱 𝗳𝘂𝗻𝗰𝘁𝗶𝗼𝗻, which maps the output to a probability value in the range [0, 1]. The sigmoid function ensures that the model is not sensitive to outliers and provides a smooth, differentiable output for optimization. The result is a more reliable classification model for binary outcomes.
This transformation allows models like logistic regression to perform binary classification more effectively than linear regression.
For detailed understanding, go through this video:
I made the code for the animation public for further exploration: https://github.com/pritkudale/Code_for_LinkedIn/blob/main/Logistic_vs_linear_regression_for_binary_classification.ipynb
Stay updated with more such engaging content by subscribing to 𝗩𝗶𝘇𝘂𝗮𝗿𝗮’𝘀 𝗔𝗜 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: https://www.vizuaranewsletter.com?r=502twn
#MachineLearning #DataScience #LogisticRegression #BinaryClassification #AI #Outliers #Optimization