
Why do we need transformers for vision?
Why global context matters and how transformers deliver it unlike CNNs


Over the past decade, convolutional neural networks (CNNs) have been at the heart of computer vision. They powered breakthroughs in image classification, object detection, and segmentation. From AlexNet in 2012 to ResNets, VGG, Inception, and EfficientNet, CNNs defined what state-of-the-art meant in vision tasks.
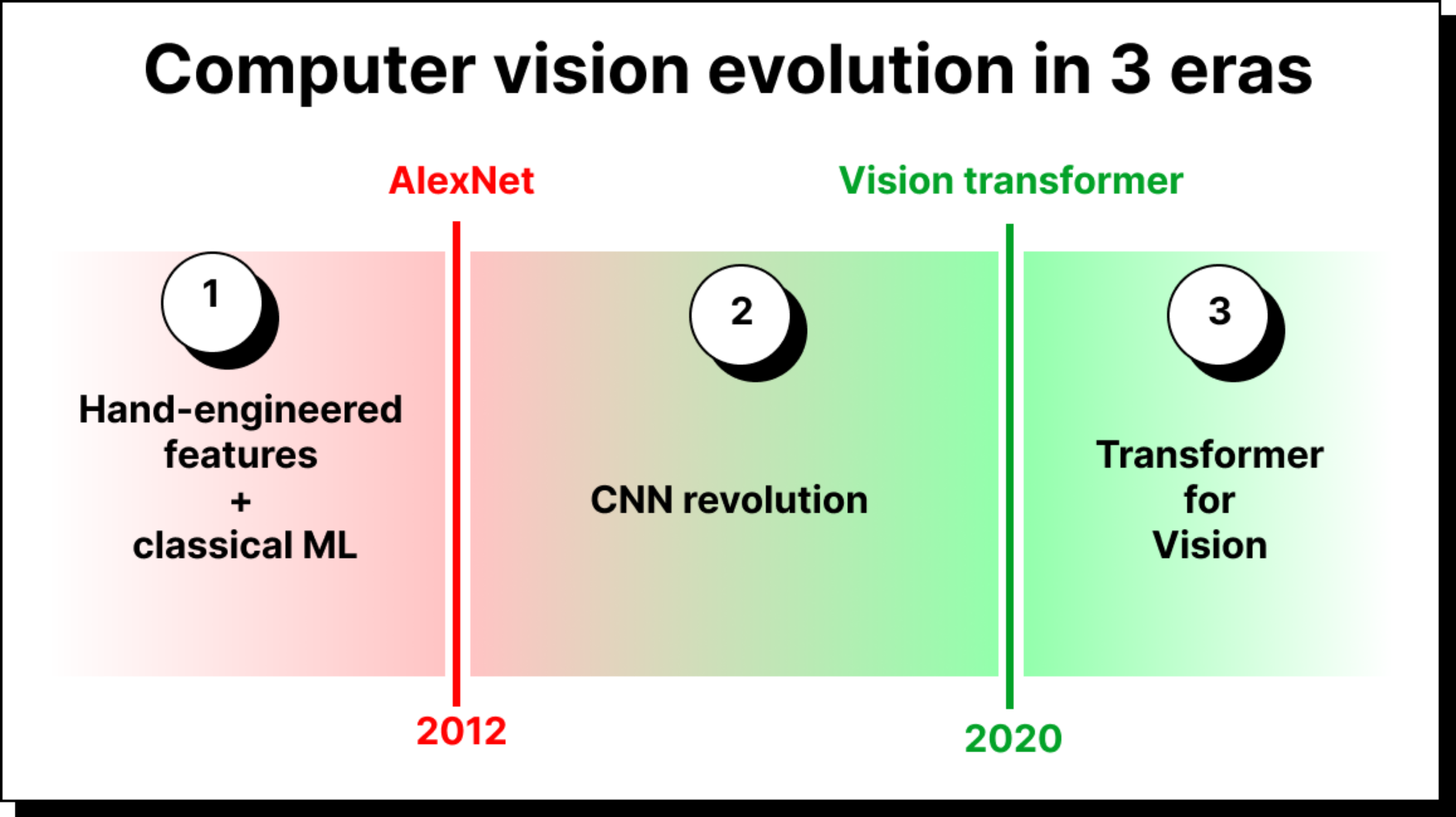
But as with every dominant paradigm, CNNs have their strengths and their limitations. Understanding both is the key to appreciating why the field has moved toward transformers for vision.
How CNNs work
CNNs process visual data using three core operations:
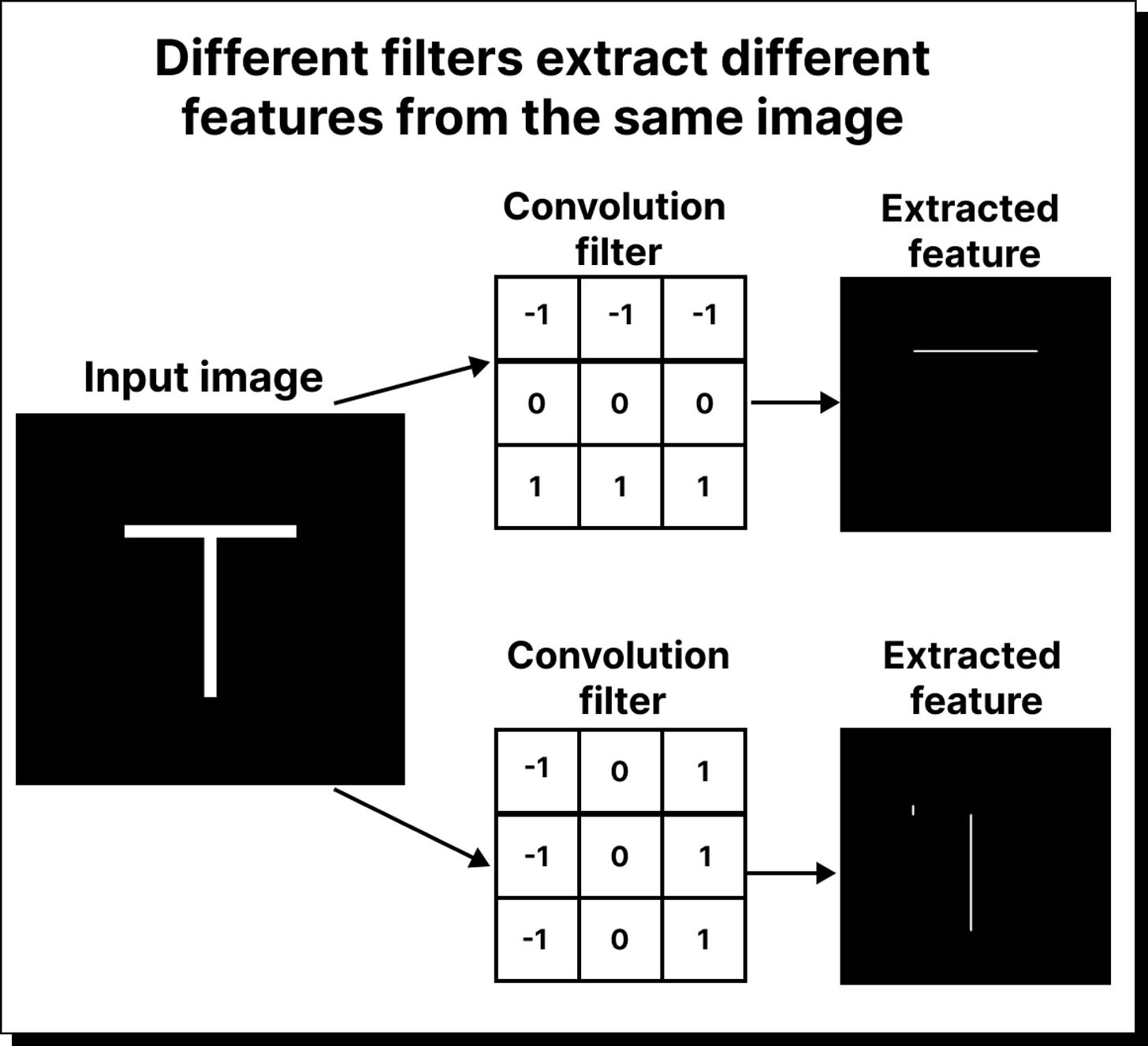
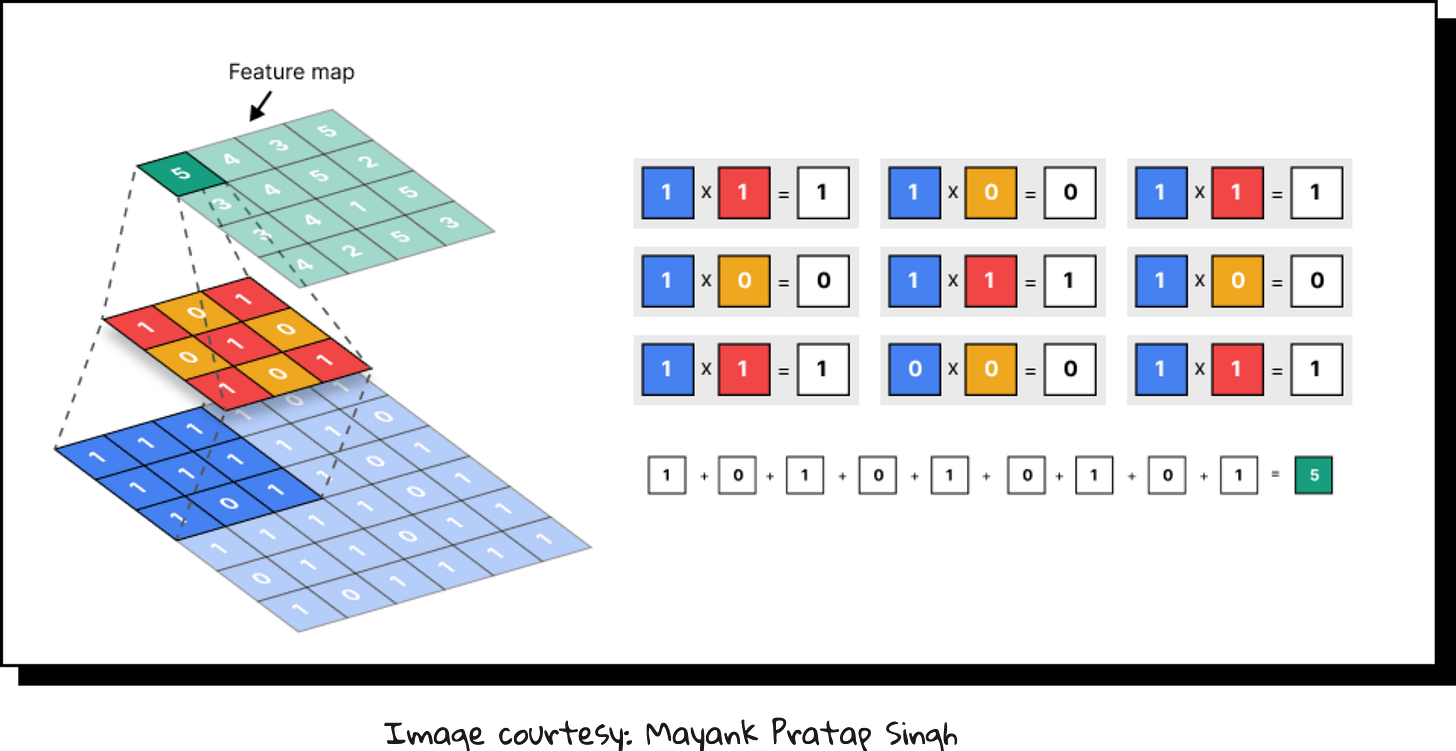
Convolution – sliding filters over the image to detect patterns like edges, textures, and shapes.

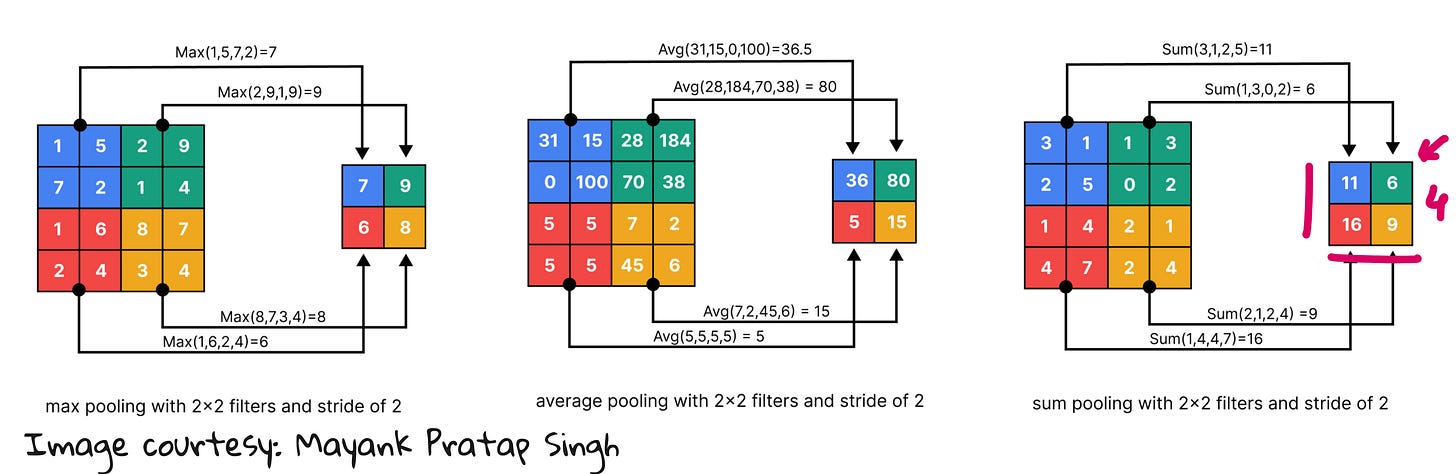
Pooling – reducing spatial resolution while preserving key features, making representations more compact.
Non-linearity – applying activation functions to introduce non-linear decision boundaries.
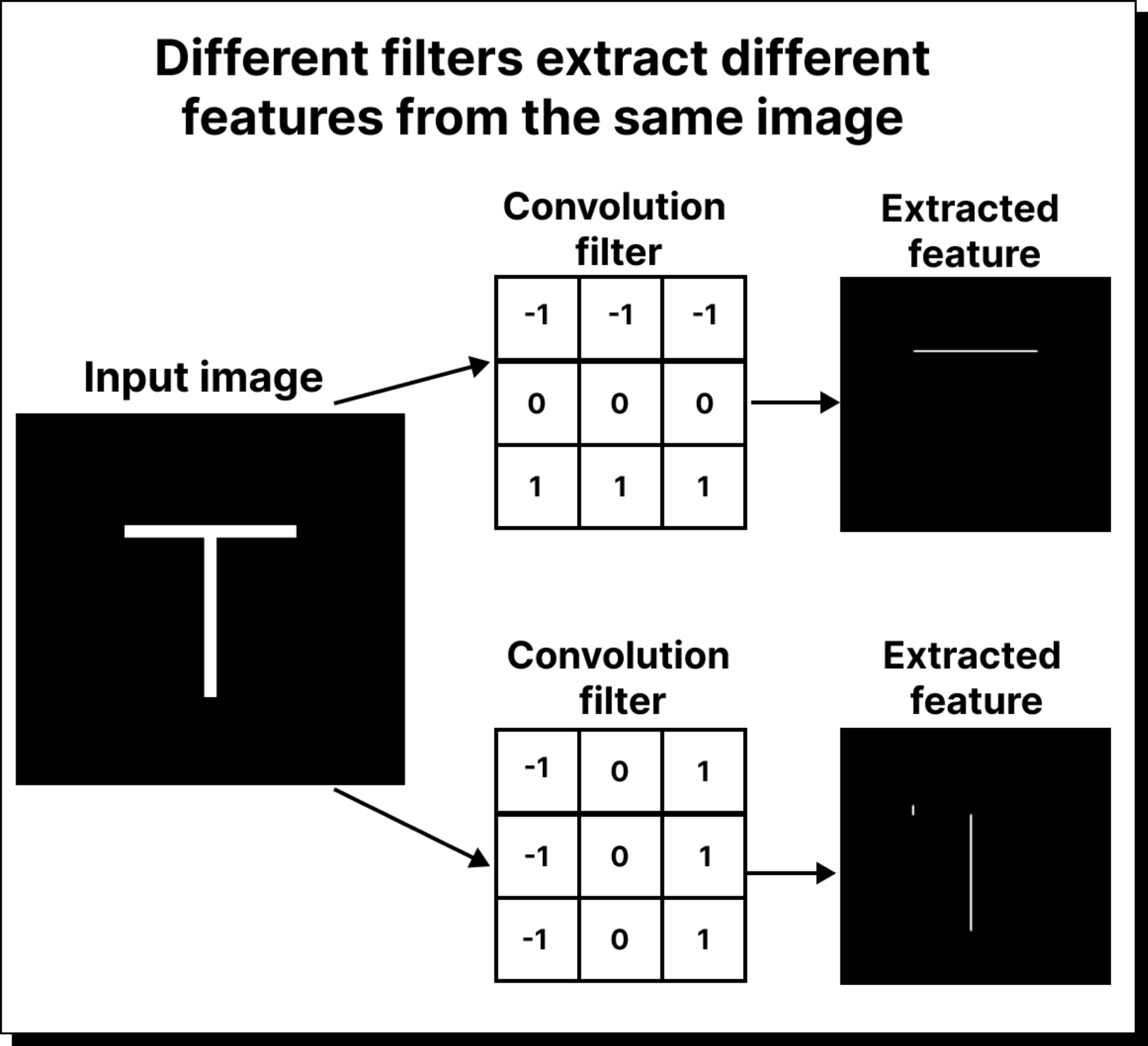
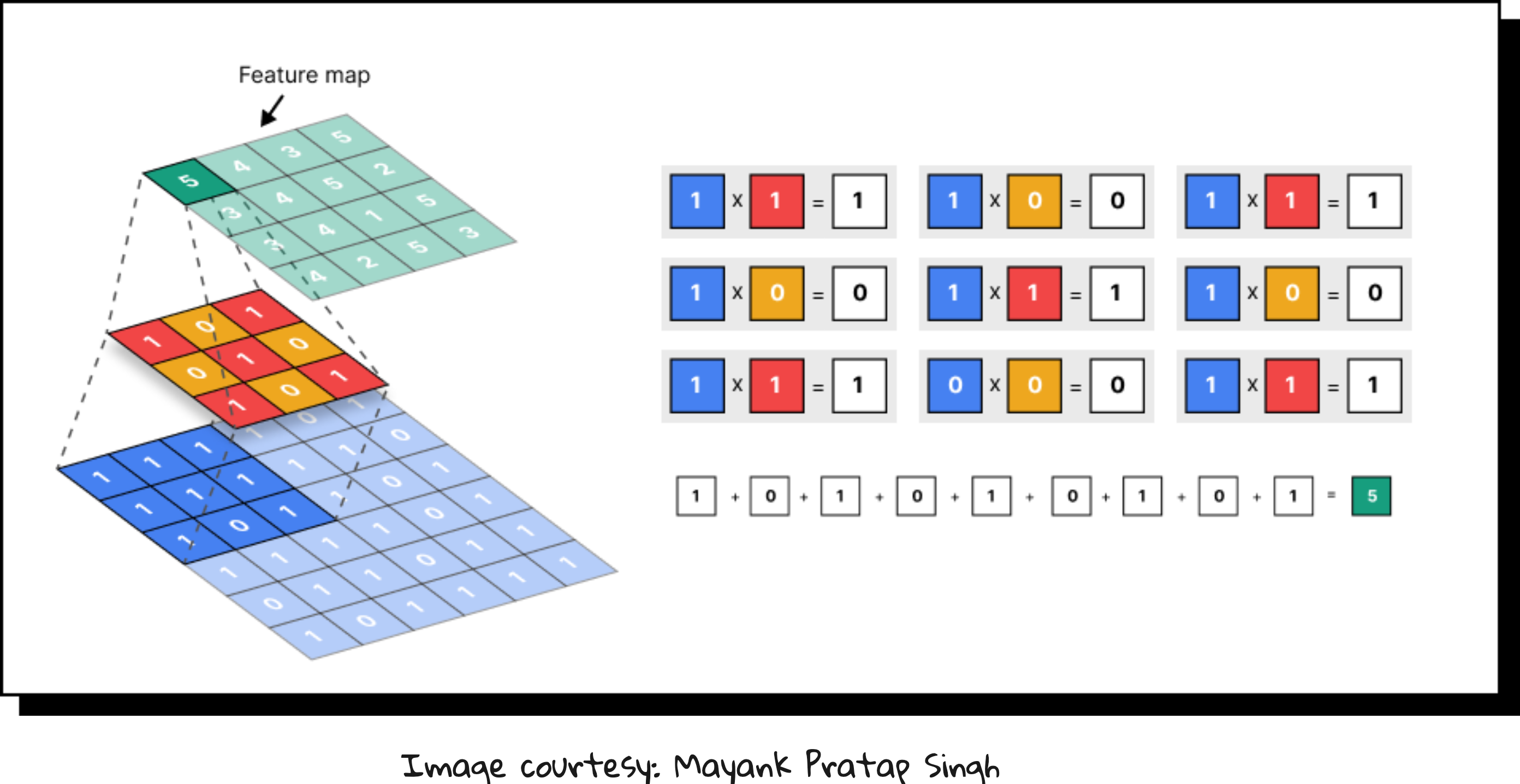
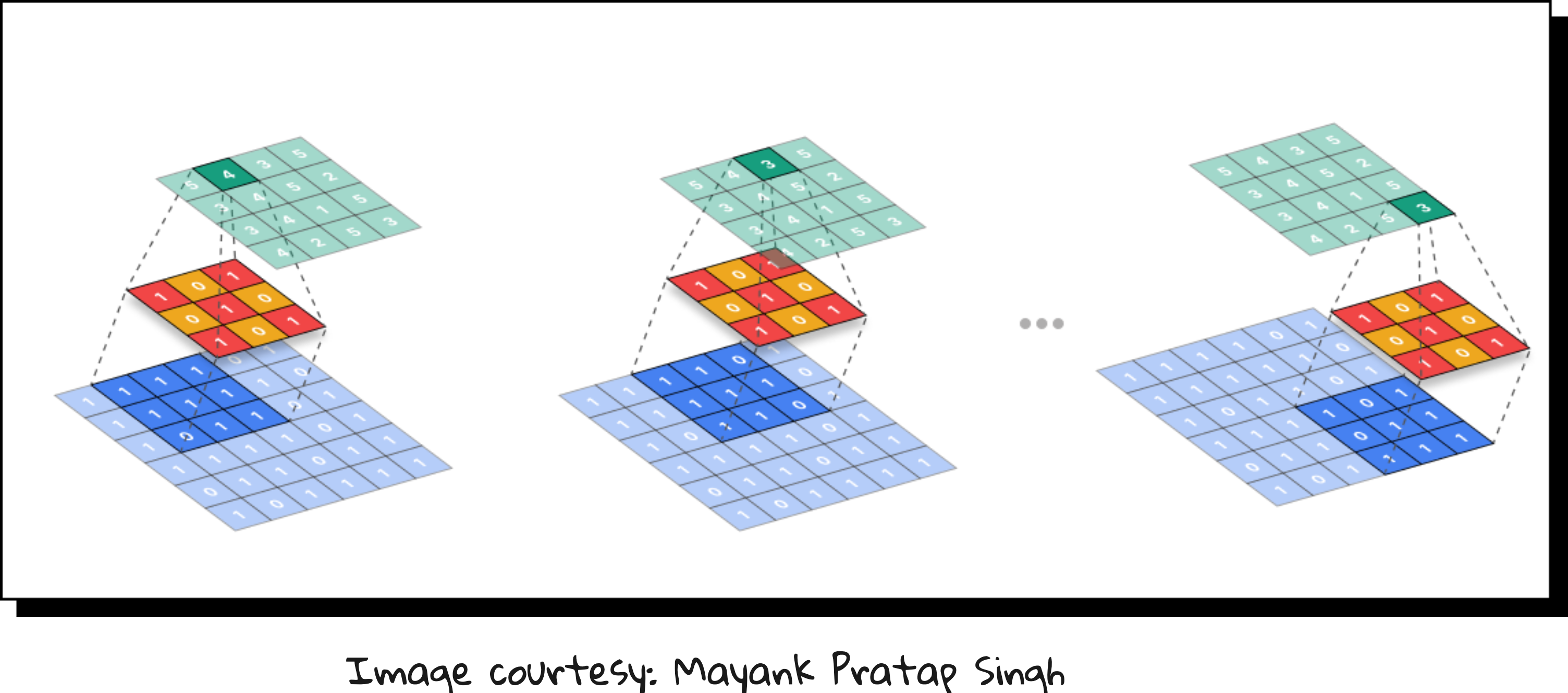
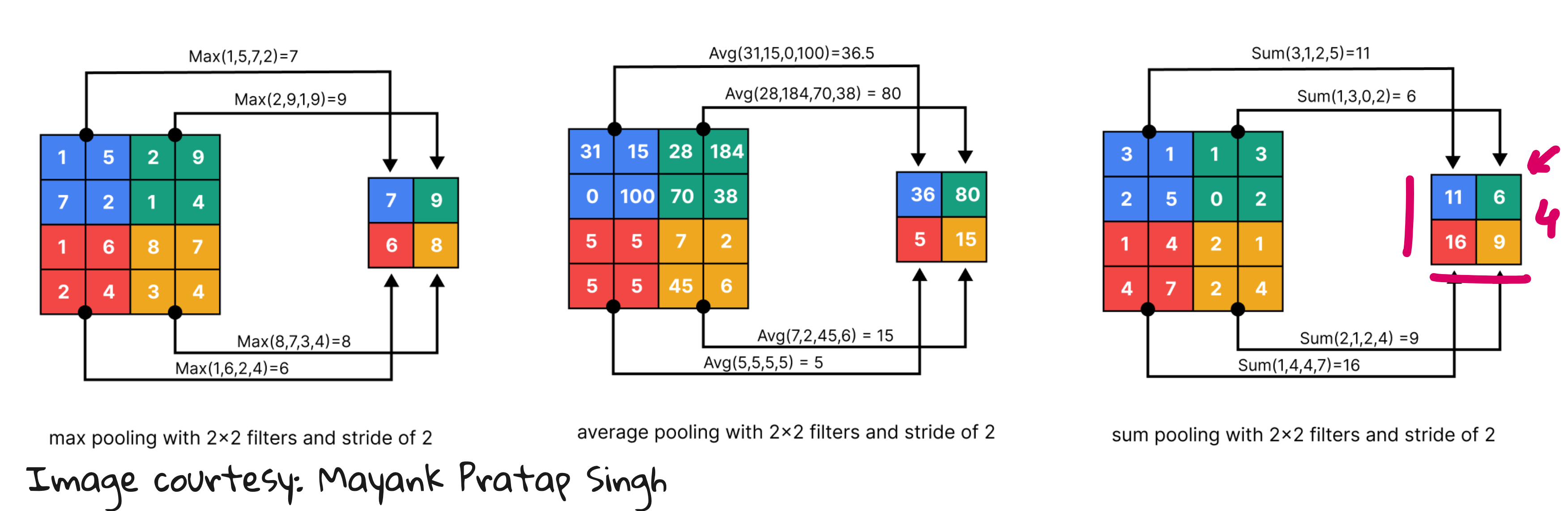
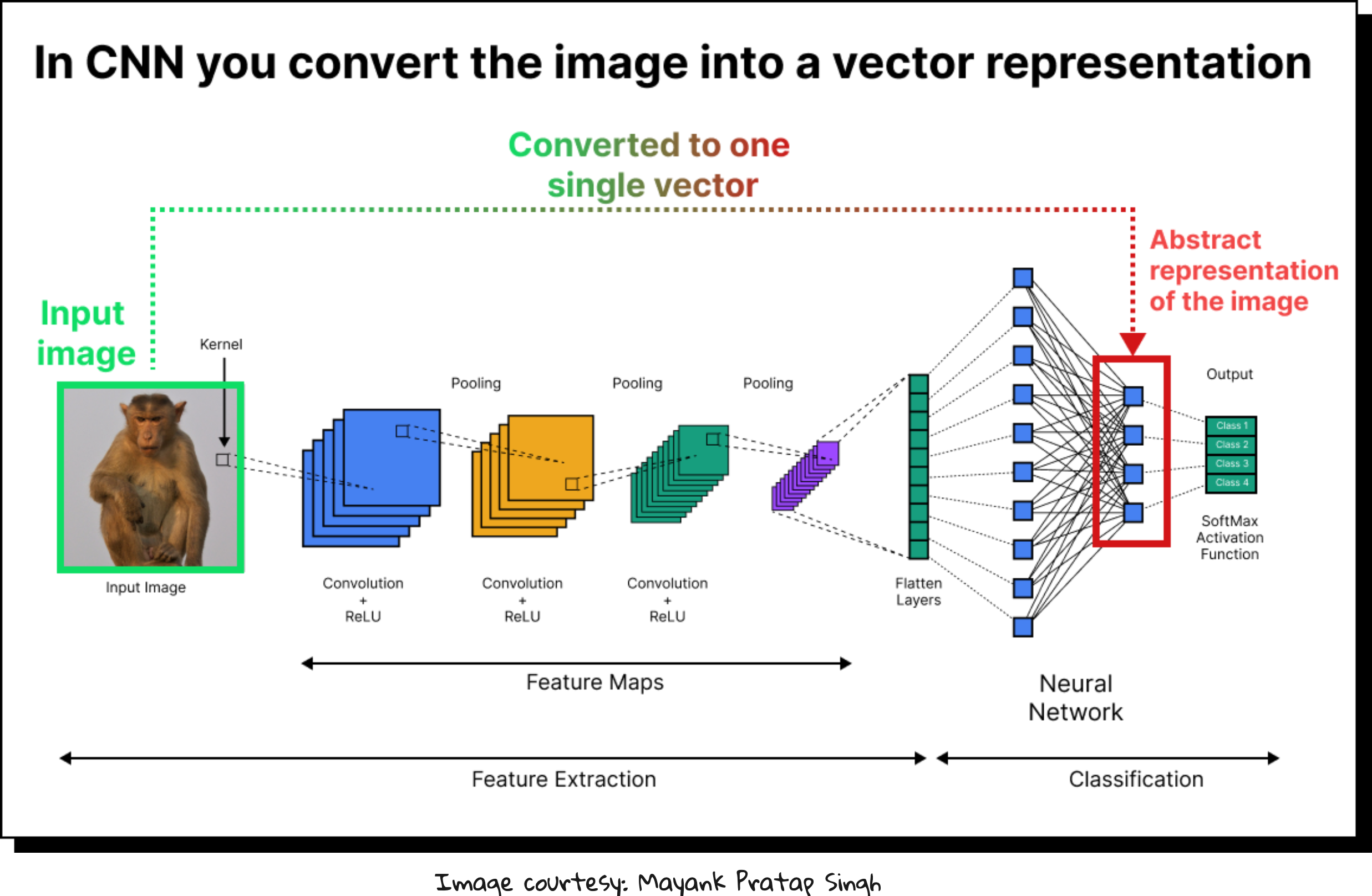
Through stacking multiple convolution and pooling layers, CNNs build hierarchical feature maps:
Lower layers capture edges and textures.
Middle layers detect parts and shapes.
Higher layers represent semantic features like objects or categories.
This hierarchical abstraction is what made CNNs so effective at tasks like image recognition.
Strengths of CNNs
CNNs have several advantages:
Local connectivity: They exploit spatial locality in images, making them efficient.
Parameter sharing: Filters are reused across the image, reducing the number of parameters.
Translation invariance: Pooling operations make CNNs robust to shifts and distortions.

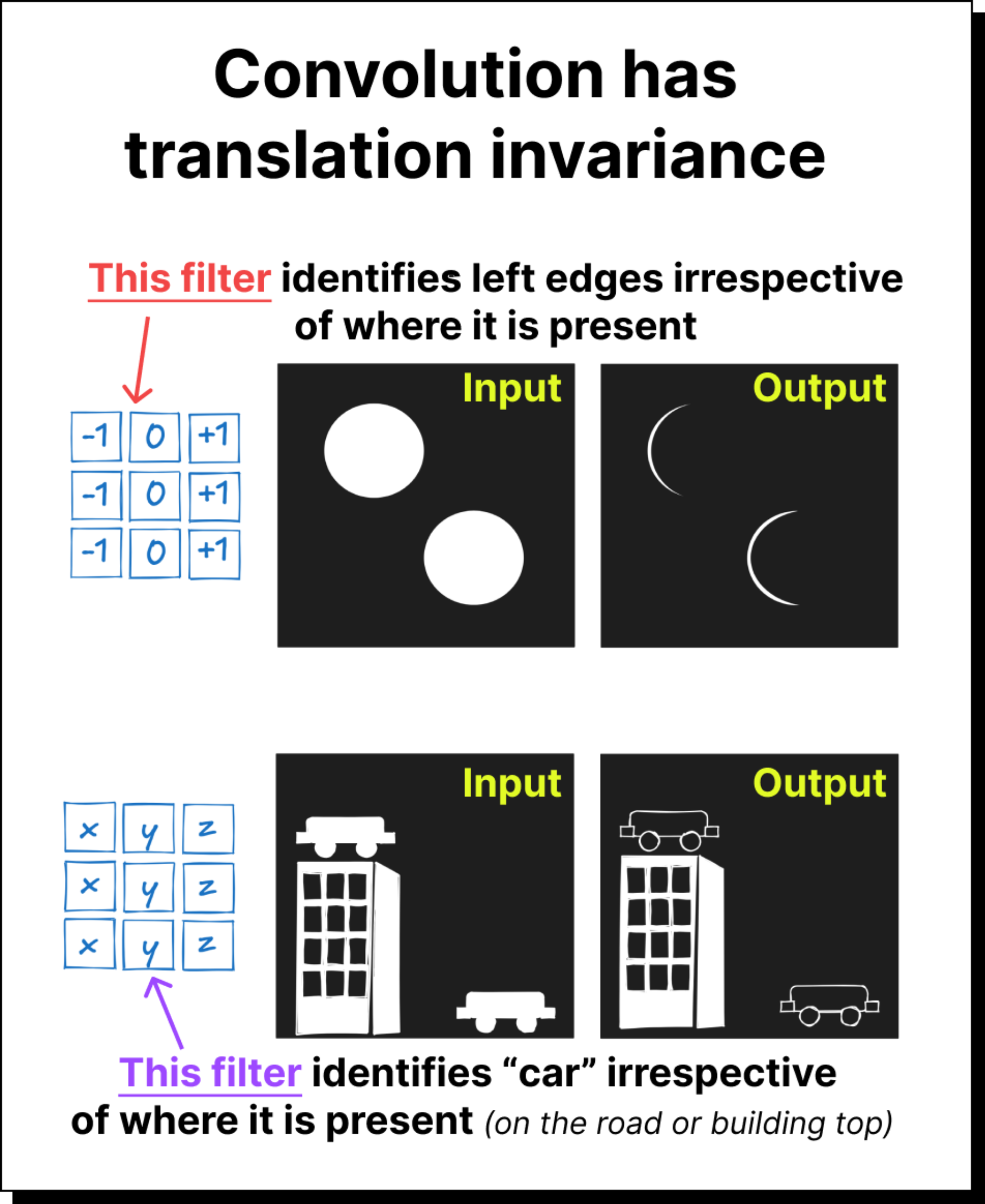
For over a decade, these properties made CNNs the default tool for vision tasks.
But CNNs have limitations
Despite their success, CNNs face important constraints:
Fixed receptive field: Each neuron only “sees” a limited region of the image. To capture global context, many layers must be stacked, increasing depth and complexity.
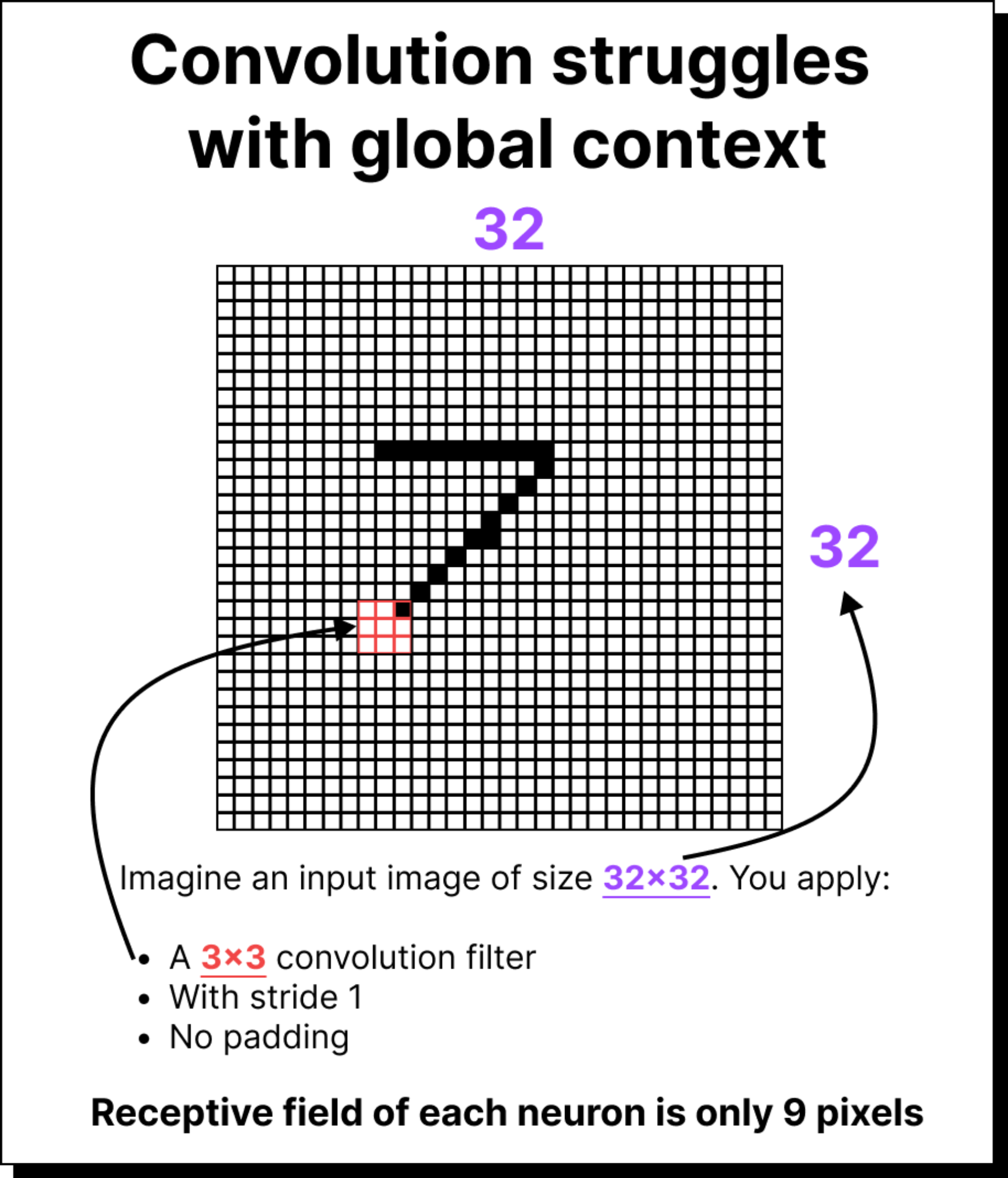

Loss of spatial relationships: Pooling discards precise positional information. This is problematic when fine-grained spatial details matter.
Difficulty with long-range dependencies: CNNs are inherently local. Capturing relationships between distant parts of an image requires very deep networks.
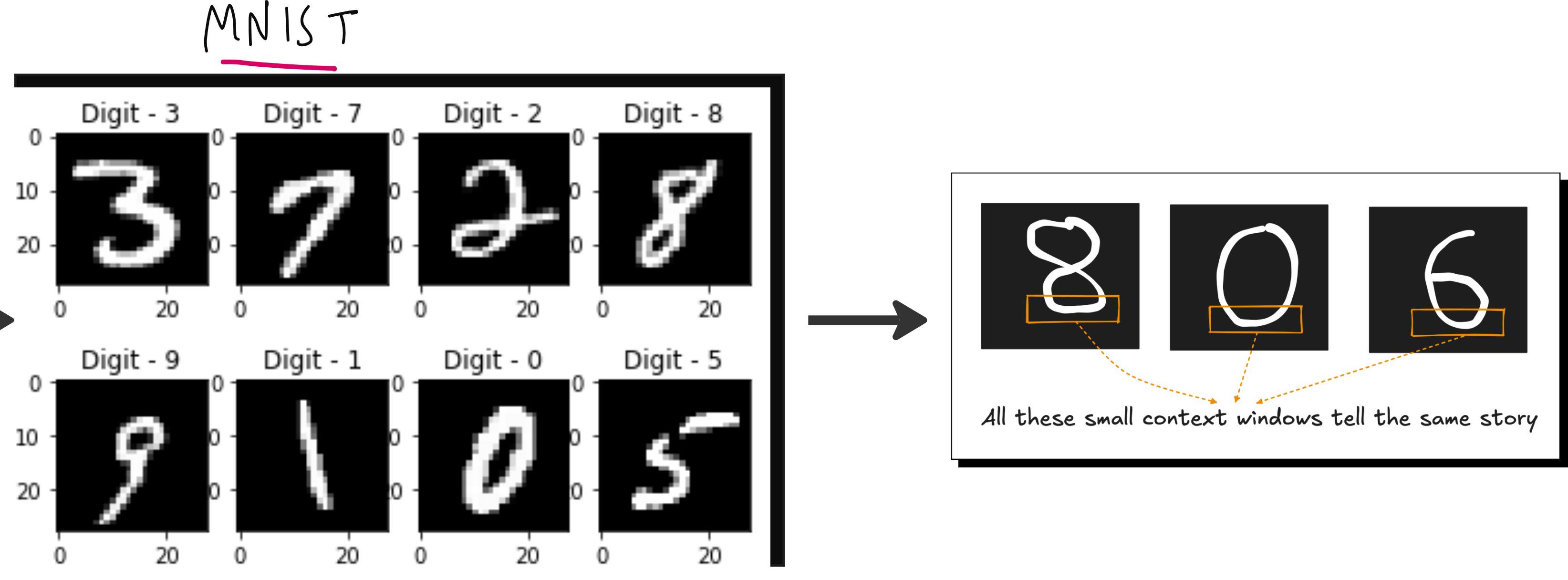
Inductive bias: CNNs assume locality and stationarity. While helpful, this inductive bias can also limit flexibility for tasks requiring broader context.
Deeper neural networks have the issue of vanishing gradient
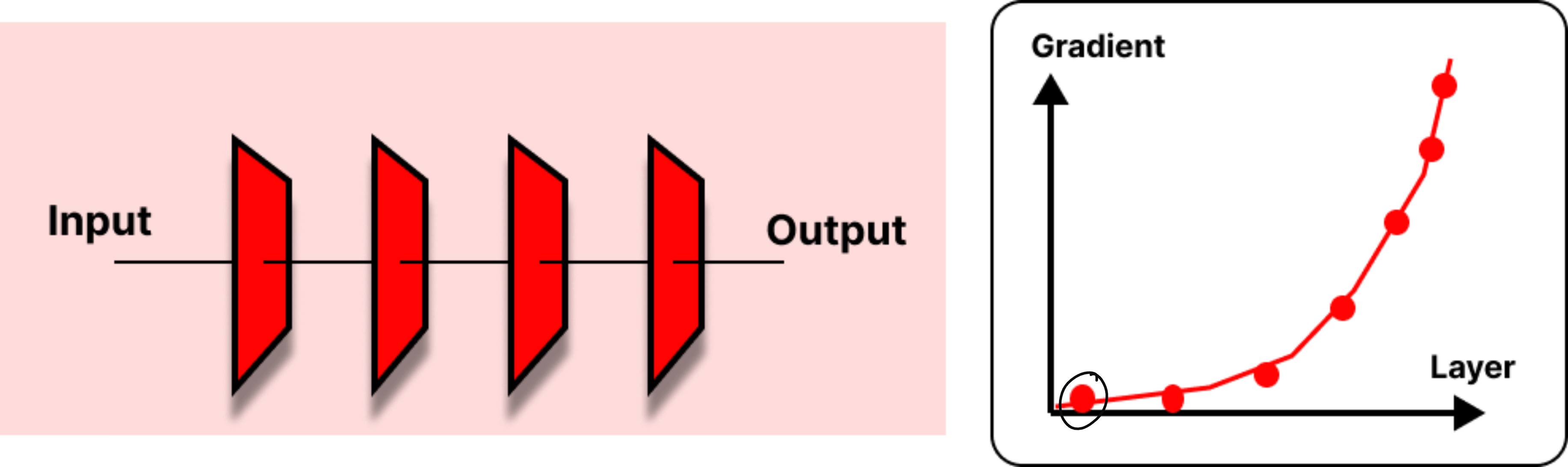
A classic example: consider an image of a pedestrian and a traffic signal. CNNs may process them independently, focusing on local patches. But to correctly infer “the pedestrian is crossing while the light is red,” the model must capture relationships across distant parts of the image.
Why transformers are needed
Transformers address the shortcomings of CNNs by introducing self-attention, a mechanism that:
Models global relationships across the entire image, not just local neighborhoods.
Allows the network to dynamically focus on the most relevant parts of the input.
Provides flexibility to handle diverse modalities (text, image, audio) in a unified framework.

In the example sentence below, “teacher” and “smiled” are far apart in the sentence. Still they are related the most. “students” and “smiled” are very close to each other. Yet it is not the students it is the teacher who smiled. This became possible due to attention mechanism in transformers.

Before attention mechanism, RNNs could only capture short range dependencies. Because of that, it worked very well on short sentence translation like below, but not for long sentences.

In 2020, the paper “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale” introduced the Vision Transformer (ViT). Instead of scanning local patches through convolution, ViT divides the image into fixed-size patches, embeds them as tokens, and processes them with a transformer architecture.
This was a paradigm shift. Vision tasks could now leverage the same architecture that had revolutionized NLP.

The Vision Transformer (ViT)
ViT works as follows:
Split the image into small patches (e.g., 16x16 pixels).
Flatten each patch and embed it into a vector representation.
Feed the sequence of patch embeddings into a standard transformer encoder.
Use self-attention to model relationships between patches, enabling the network to learn global context.
Perform classification or downstream tasks from the resulting representation.
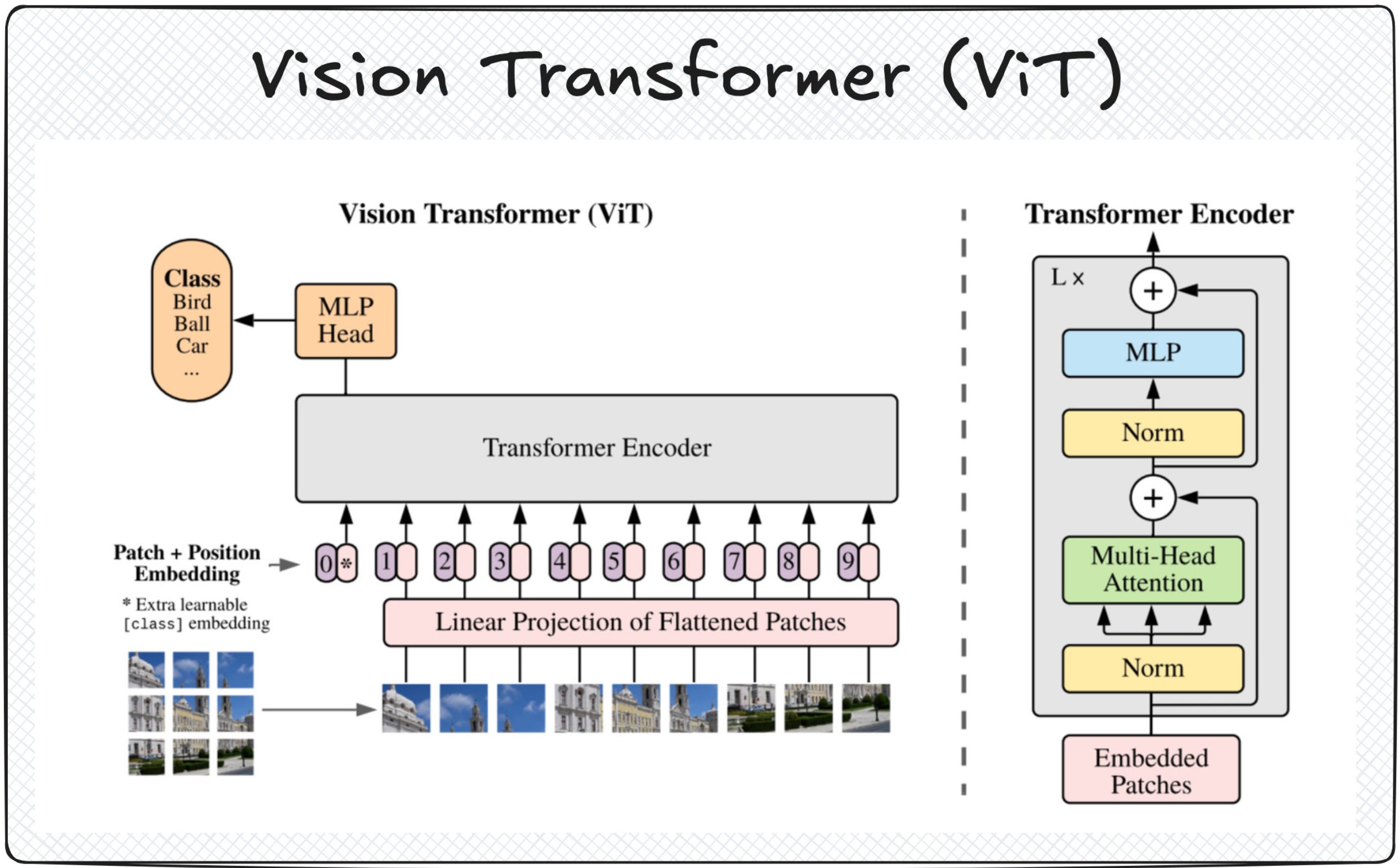
By treating image patches like words in a sentence, ViT unified language and vision under the same transformer architecture.
The impact
The impact of transformers in vision has been dramatic:
State-of-the-art results in classification, detection, and segmentation.
Stronger scalability - performance improves significantly with larger datasets and models.
Flexibility for multimodal AI - enabling vision-language models like CLIP and multimodal LLMs.
The ViT paper alone has tens of thousands of citations, showing how quickly the community has embraced transformers for vision.
Conclusion
CNNs were a remarkable step in computer vision, but their local nature made them insufficient for tasks requiring global reasoning. Transformers, with their attention-based architecture, filled this gap.
The shift from CNNs to transformers in vision mirrors what happened in NLP: a move from architectures constrained by locality to models capable of capturing broad, contextual relationships.
This is why today’s bootcamp is focused on transformers for vision and multimodal LLMs. They represent not just an incremental improvement, but a fundamental shift in how we approach perception and reasoning in AI.
Lecture video
PRO content: What will you get?
