
Why Deployment and Monitoring Are Central to Production-Grade ML Systems
This article examines the necessity of deployment, the importance of monitoring, the key components that require monitoring, and how engineers select deployment platforms.


Table of Content
Introduction
Why Deployment Is Necessary
Industrial Reality
Why Monitoring Is Critical After Deployment
What We Monitor in ML Systems
System Level Monitoring
Data Level Monitoring
Model Level Monitoring
Platforms for Deploying Machine Learning Systems
AWS EC2
Google Clound Run
Microsoft Azure
Render
Choosing the Right Deployment Platform
Understanding AWS EC2 Fundamentals (Storage, Security, and Instance Types)
Connecting GitHub and EC2 Securely Using Secrets
Automated Deployment to EC2 Using GitHub Actions
Conclusion
1. Introduction
Machine learning systems do not create value at the moment a model finishes training. Value is created only when that model is deployed into a real system, exposed to live data, and continuously monitored to ensure reliability over time.
In modern Machine Learning Engineering (MLE), deployment and monitoring are not optional add-ons. They are foundational engineering responsibilities that determine whether a model survives outside experimentation.
This article explores why deployment is necessary, why monitoring is critical, what must be monitored, and how engineers choose deployment platforms in real-world production systems.

2. Why Deployment Is Necessary
A trained model that exists only in a notebook or local environment is effectively inert. It cannot serve users, integrate with applications, or respond to real-time data.
Deployment converts a trained model into a running service capable of:
Accepting input from users or systems
Producing predictions automatically
Running continuously without manual intervention
Without deployment:
Models remain experimental artifacts
There is no business or product impact
Feedback loops for improvement do not exist
a. Industry Reality
At Netflix, recommendation models are deployed as low-latency services responding to millions of requests per second. A highly accurate model that cannot be deployed reliably is functionally useless.
Similarly, Uber’s pricing and demand forecasting models must operate continuously. Any deployment failure directly affects rider experience and revenue.
Deployment is the transition point where machine learning becomes infrastructure.
3. Why Monitoring Is Critical After Deployment
Once deployed, a model enters a dynamic and often adversarial environment. Real-world data changes. User behavior evolves. Infrastructure degrades. Assumptions made during training eventually become invalid.
Common causes of post-deployment failure include:
Changes in incoming data distributions
Seasonal or behavioral shifts
System-level failures
Gradual performance degradation (concept drift)
Monitoring ensures that failures are detected early, diagnosed correctly, and addressed before they escalate.
At LinkedIn, even small degradations in feed-ranking models can significantly impact engagement metrics. Continuous monitoring enables rapid detection and controlled rollbacks.
Monitoring is not about perfection it is about maintaining trust in production systems.
4. What We Monitor in ML Systems
Monitoring in machine learning systems operates across three interconnected layers. Treating monitoring as “accuracy tracking” alone is a common and costly mistake.
a. System-Level Monitoring

This layer ensures that the underlying infrastructure remains healthy.
Key metrics include:
CPU and memory utilization
Disk and network usage
API latency and error rates
If system resources are exhausted or latency spikes, even a perfect model becomes unusable.
b. Data-Level Monitoring
This layer focuses on the inputs entering the model.
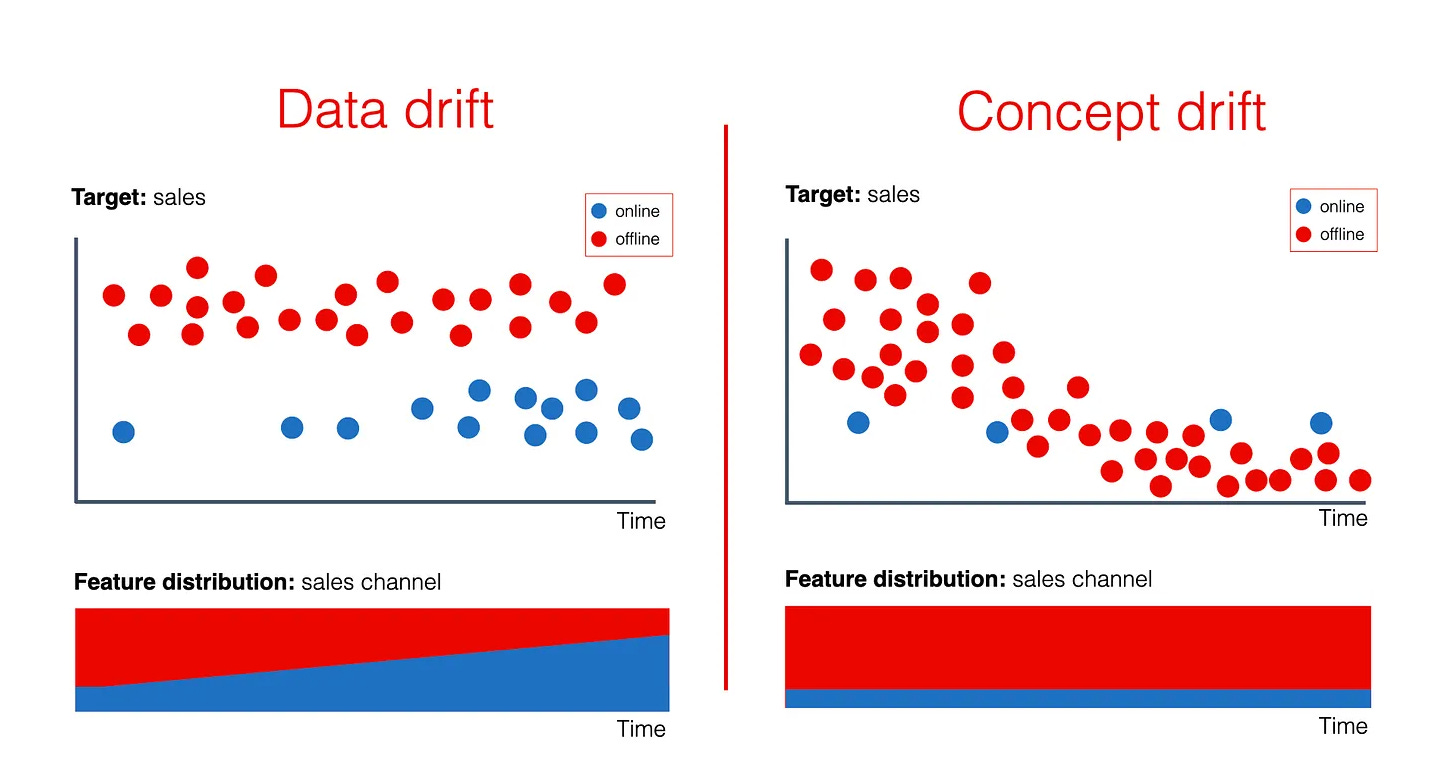
What is monitored:
Input feature distributions
Missing or invalid values
Sudden statistical shifts indicating data drift
At Airbnb, pricing and demand models rely heavily on data-level monitoring. Changes in travel patterns can silently invalidate training assumptions if not detected early.
c. Model-Level Monitoring

This layer evaluates model outputs, not just labels.
Typical metrics include:
Prediction distributions
Reconstruction error (for anomaly detection systems)
Ground-truth-based metrics when labels are available
In anomaly detection systems used for cybersecurity or finance, rising reconstruction error often provides the earliest signal of abnormal system behavior.
5. Platforms for Deploying Machine Learning Systems
Different deployment platforms exist because no single solution fits all production requirements. The choice depends on control, scalability needs, and operational maturity.
a. Amazon EC2
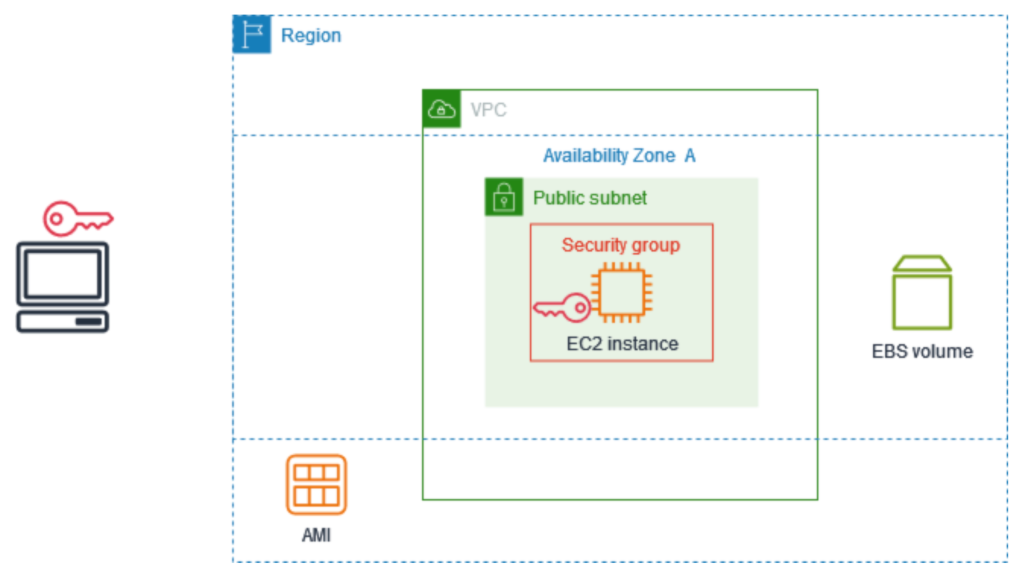
Figure: Amazon EC2 provides full control over the deployment environment using virtual machines.
A virtual machine–based deployment model offered by Amazon Web Services.
Advantages
Full control over operating system, dependencies, and runtime
Seamless integration with Docker and CI/CD pipelines
Ideal for research workflows, custom ML pipelines, and live demos
Limitations
Manual scaling
Requires system administration expertise
Monitoring and security must be explicitly configured
EC2 is commonly used in early-stage ML products and research-heavy environments where flexibility is essential.
b. Google Cloud Run

A serverless container deployment platform from Google Cloud.
Advantages
Automatic scaling
No server management
Pay-per-use pricing
Well suited for stateless inference APIs
Limitations
Limited infrastructure control
Cold-start latency
Unsuitable for long-running ML jobs
Cloud Run excels when traffic patterns are unpredictable and operational simplicity is prioritized.
c. Microsoft Azure

A comprehensive cloud ecosystem offered by Microsoft Azure.
Advantages
Strong integration with enterprise systems
Managed ML services available
Advanced monitoring and logging tools
Limitations
Steeper learning curve
Higher cost for small projects
Configuration complexity
Azure is frequently chosen in regulated industries and enterprise-heavy environments.
d. Render
A lightweight deployment platform focused on developer experience.
Advantages
Extremely easy setup
Minimal configuration
Ideal for demos and prototypes
Limitations
Limited customization
Not suitable for heavy ML workloads
Restricted control over scaling
Render is best suited for educational content, proofs of concept, and lightweight demonstrations.
6. Choosing the Right Deployment Platform
Platform selection should be driven by engineering constraints, not popularity.
General guidelines:
Full control and live demonstrations → Amazon EC2
Stateless ML APIs with variable traffic → Google Cloud Run
Enterprise-grade production systems → Microsoft Azure
Simple demos with minimal setup → Render
Choosing the correct platform reduces operational friction and allows teams to focus on model quality rather than infrastructure firefighting.
7. Understanding AWS EC2 Fundamentals (Storage, Security, and Instance Types)
Before deploying anything to AWS EC2, it is essential to understand the core building blocks that make an instance usable and secure.
Storage (EBS Volumes)
Every EC2 instance requires storage to hold the operating system, application code, logs, and Docker artifacts. This is provided using Elastic Block Store (EBS) volumes, which act like virtual hard disks attached to the instance. EBS ensures data persistence even if the EC2 instance is stopped or restarted.
Security Groups
Security Groups act as virtual firewalls for EC2. They control inbound and outbound traffic rules. For deployment workflows, the most critical rule is allowing SSH access on port 22, typically restricted to trusted IPs or GitHub Actions runners. Without proper security group configuration, remote access to EC2 is impossible.
PEM File (Key Pair)
AWS uses public–private key authentication instead of passwords. When creating an EC2 instance, a key pair (.pem file) is generated.
The private key (.pem) stays with you
The public key is stored on the EC2 instance
This key pair enables secure SSH access and is later reused inside CI/CD pipelines.
Instance Types (t2 vs t3)
t2 instances are older burstable instances suitable for lightweight workloads.
t3 instances are newer, more cost-efficient, and provide better baseline performance.
For Docker-based ML or backend deployments, t3.micro or t3.small is generally preferred due to better CPU credit handling.
8. Connecting GitHub and EC2 Securely Using Secrets
Directly hardcoding credentials inside GitHub workflows is insecure. Instead, GitHub Actions uses encrypted secrets to establish a secure connection between GitHub and EC2.
Required GitHub Secrets
Each secret has a specific role:
EC2_HOST
The public IP address or DNS of the EC2 instance.EC2_USER
The default SSH username (for Ubuntu AMI, this isubuntu).EC2_SSH_KEY
The private.pemkey contents used for SSH authentication.DOCKER_COMPOSE_DIR
The directory path on EC2 wheredocker-compose.ymlis located.GHCR_PAT (GitHub Container Registry Personal Access Token)
Used to authenticate Docker with GitHub Container Registry (ghcr.io) so private images can be pulled securely.
Snapshot from our actual implementation.
These secrets allow GitHub Actions to authenticate with EC2 without exposing credentials in the repository.
9. Automated Deployment to EC2 Using GitHub Actions
- name: Deploy to AWS EC2
uses: appleboy/ssh-action@v0.1.7
with:
host: ${{ secrets.EC2_HOST }}
username: ${{ secrets.EC2_USER }}
key: ${{ secrets.EC2_SSH_KEY }}
port: 22
script: |
docker login ghcr.io -u ${{ github.repository_owner }} -p ${{ secrets.GHCR_PAT }}
cd ${{ secrets.DOCKER_COMPOSE_DIR }}
docker-compose pull
docker-compose down
docker-compose up -d
Above is the deployment step used inside the GitHub Actions workflow:
What this workflow does
Establishes SSH Connection
GitHub Actions securely connects to the EC2 instance using the SSH private key.Authenticates Docker with GHCR
Logs into GitHub Container Registry to pull private Docker images.Navigates to Deployment Directory
Moves to the directory containingdocker-compose.yml.Pulls Latest Images
Ensures the EC2 instance always runs the latest container versions.Restarts Services Cleanly
Stops existing containers and redeploys them in detached mode.
This results in a fully automated CI/CD pipeline, where every push to GitHub triggers a fresh deployment on EC2.

10. Conclusion
Deployment and monitoring complete the ML lifecycle by ensuring models move reliably from development to production while remaining observable and controllable. Automated CI/CD with cloud infrastructure enables consistent, repeatable deployments, while monitoring detects failures, performance drift, and system anomalies early. Together, they transform experimental models into robust, production-grade systems suitable for real-world use.
To understand further , please watch the video on deployment
Thanks for sharing this. I believe creating Ai systems comes with great responsibilities and best practices to be followed. I am trying to make it easy for others with best practices baked in. Still in early phase but here is completely free open source framework on shipping production ready agents in production. https://github.com/Agent-Shipping-Kit/agent-ship