
What Would Jeff Bezos Say About Your ML Planning?
In this article we will briefly discuss about the planning in the ML Project and how despite of being strong in Technical Knowledge , poor planning can lead to failure of project before starting.


Table of content
Before You Model: Why ML Projects Fail Before They Start
The Real Bottleneck Isn’t Modeling, It’s Misalignment
Start with Bezos' Favorite Question: "Why Are We Building This?"
Common Planning Pitfalls and How to Avoid Them
4.1) Assumption of Business Knowledge
4.2) Assumption of Data Quality
4.3) Assumption of Functionality
4.4) Curse of knowledge
4.5) Analysis - Paralysis
1)Before You Model: Why ML Projects Fail Before They Start
When we think about failed machine learning (ML) projects, we often blame the usual suspects: bad models, poor data, overfitting, platform limitations, or lack of compute. But in reality, most failures happen long before a single line of code is written. They begin with poor planning and unclear scope.
In this article, we’ll unpack some of the most common hidden killers of ML projects based on real-world patterns observed across hundreds of teams and explore how proper planning can save your next big ML idea from quietly collapsing.
2)The Real Bottleneck Isn’t Modeling, It’s Misalignment
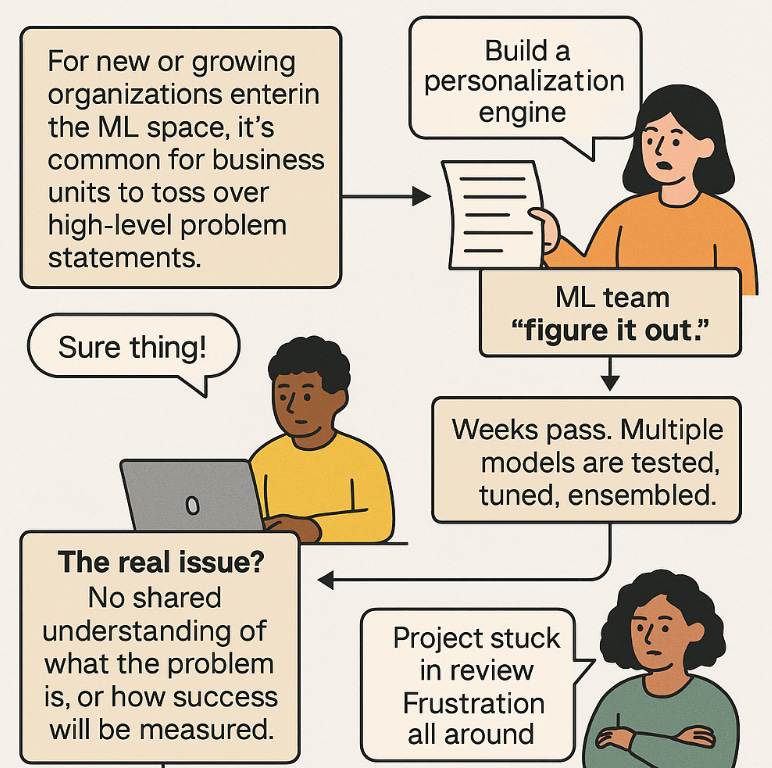
For new or growing organizations just entering the ML space, it’s common for business units to toss over high-level problem statements, “Build a personalization engine” and expect the ML team to “figure it out.” The team, trained in isolation and theory, responds by diving headfirst into experimentation. Weeks pass. Multiple models are tested, tuned, ensembled. Results are inconclusive. The project gets stuck in review. Everyone’s frustrated.
Case Study: Spotify’s Playlist Ranking Rollout
Spotify began their recommendation journey not with deep learning but with collaborative filtering and lightweight heuristics. They validated performance using playlist completion rates and skip behavior to gradually refine their engine without over-engineering it upfront.
The real issue? No shared understanding of what the problem is, or how success will be measured.
3)Start with Bezos' Favorite Question: "Why Are We Building This?"
Before diving into modeling, call a kickoff meeting and ask the most important question of the project:
“Why are we building this?”

This one prompt uncovers what matters to each stakeholder. Is it sales uplift? Better UX? Increased session duration? These early conversations shape everything from the data you collect to how you evaluate success.
Why it matters:
1. Clarifies Business Intent Stakeholders might have wildly different expectations. One team might care about engagement, another about retention, another about reducing costs. Without a shared “why,” your model might solve a problem no one really has or miss the core opportunity entirely.
2. Shapes the Modeling Pipeline Your metrics, features, and even labels will depend on the goal. Optimizing for click-through rate vs. long-term retention? That changes everything from how you prepare training data to how you interpret success.
3. Prevents Gold-Plating Technical teams may be tempted to over-engineer or chase state-of-the-art performance. A clearly defined purpose helps rein in scope creep and ensures the solution stays useful, not just impressive.
4. Promotes Cross-Functional Collaboration It’s not just about ML anymore. Product, design, marketing all bring pieces of the puzzle. This question opens the door for inclusive planning and better human-centric outcomes.
Bonus: Ask “Why now?” That uncovers urgency, risk, and context insight that’s just as valuable for prioritization and storytelling later on.
4)Common Planning Pitfalls and How to Avoid Them
4.1) Assumption of Business Knowledge
Machine learning teams are often unaware of detailed internal business rules. Meanwhile, business teams assume those rules are universally understood. For instance, a stakeholder may expect certain products to always appear at the top of recommendations because of partnership agreements but never actually say so.
Fix: Involve subject matter experts early in the planning phase. Let them walk through how product logic works, and make implicit rules explicit.
Case Study: E-Shop’s Duplicate Listings Problem
An e-commerce company launched a demo where 300 recommendations ended up being just 4 products repeated in different colors. The ML team had no idea that catalog visibility was governed by promotional agreements. It wasn’t a bad model, it was a gap in understanding. The right fix wasn’t better modeling but integrating business logic.

4.2) Assumption of Data Quality
Sometimes data seems clean on the surface, but it holds hidden inconsistencies. You might trust the pipeline or assume it’s been validated until your output reveals odd results like 20 color variants of the same shoe.
Fix: Always validate your data. Run quick statistical summaries. Ask basic questions like “Are these distributions expected?” or “Why do we have so many rows with the same label?” A 10-minute data review can save weeks of rework.
Source:- heavy.ai
4.3) Assumption of Functionality
A model may technically work, but still deliver a poor user experience. Recommending the same product someone just purchased last week, while logical from a model’s perspective, may seem irrelevant or annoying to a user.

Fix: Define clear behavioral expectations in advance. Ask the business team early on what would make a recommendation feel useful or frustrating?
Case Study: Grocery App Recommender Backlash
In one grocery delivery app, a demo showed users getting recommendations for detergent they had just ordered the week before. The ML team saw it as correct behavior. The business team saw it as a broken experience. The fix was simple, filter out recent purchases, but it required clarity in scope, not complexity in modeling.

4.4) Curse of Knowledge
ML teams sometimes speak in advanced technical terms without realizing that their audience may not have the same background. RMSE, attention scores, loss functions, these may mean little to someone focused on business impact.
Fix: Start your explanation at a high level. Let the audience guide how deep you go. Focus on clarity over precision when discussing technical decisions with non-technical teams.
4.5) Analysis Paralysis

With so many options available, it’s easy for ML teams to try every possible model or algorithm in search of the “perfect” one. But trying too many things at once can paralyze progress.
Fix: Choose a simple, explainable approach that fits the problem well enough to test. You can always build on it later. Focus on delivering a working solution, not the most elegant one on paper.
Here is the link to lecture video to understand these concepts in depth.
In the next article, we’ll dive deeper into the planning phase and explore how well-defined scoping can significantly improve the success rate of machine learning engineering projects.