
What exactly is inductive bias in CNN?
When is it a good thing? When is it not?


When we talk about inductive bias in a Convolutional Neural Network, we are basically referring to the built in assumptions that the architecture makes about how images are structured, and these assumptions strongly shape the way the model learns, so it is important to understand both the advantages and the limitations in a simple and intuitive way.
What is inductive bias?
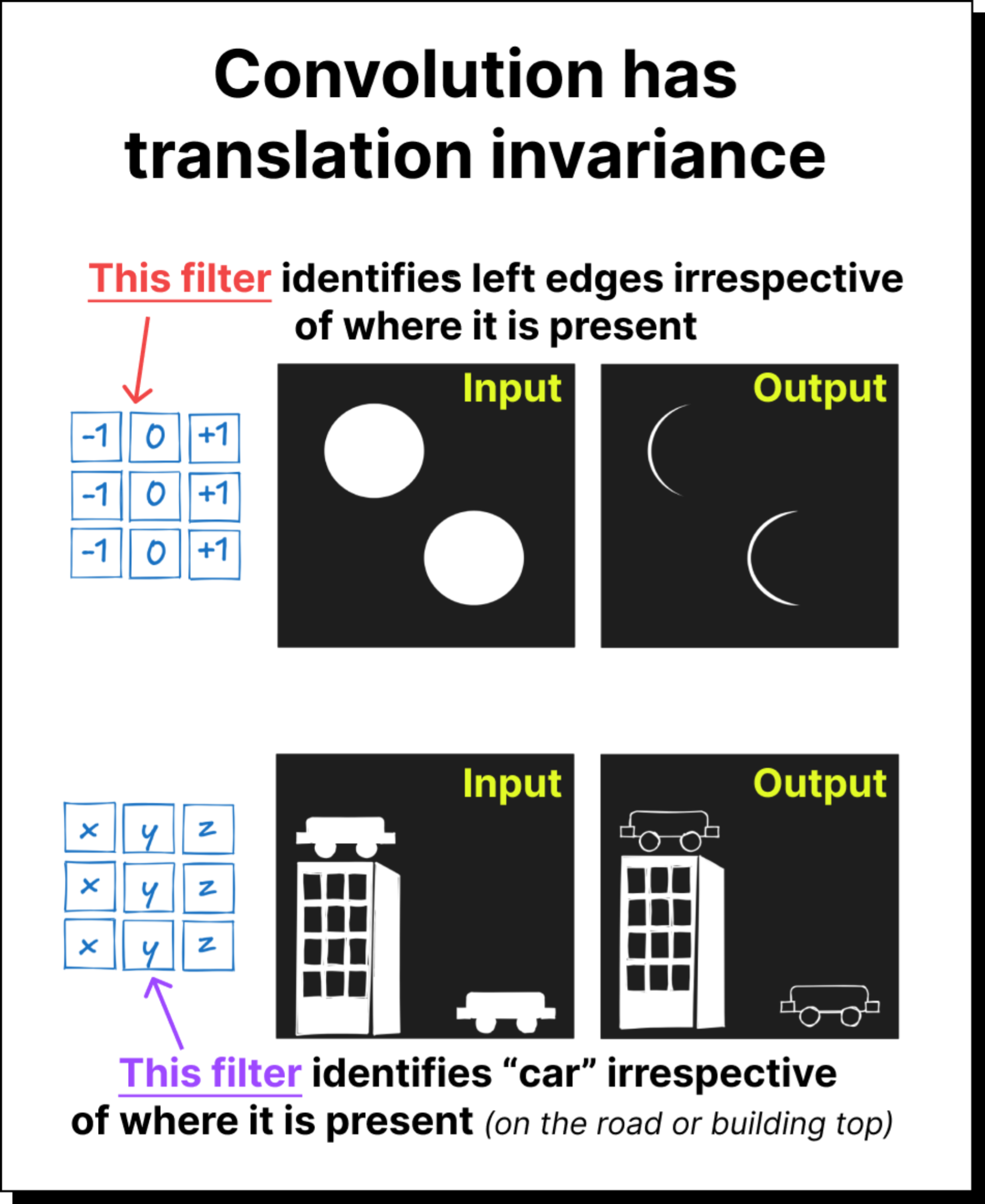
A CNN assumes that nearby pixels are related to each other and that useful patterns such as edges or textures appear in small local regions of the image, and because of this assumption the network uses small convolutional filters that slide over the image and reuse the same weights everywhere, which means the model believes that a pattern learned in one part of the image is relevant in all other parts also. This weight sharing and locality assumption forms the core inductive bias of CNNs, and it is like telling the network beforehand that images have spatial structure and that the same features can appear at different locations, so the model does not have to rediscover this fact from scratch.

When is it good?
This inductive bias is extremely good when the data actually follows these natural image properties, because it reduces the number of parameters, makes training easier, improves generalization with less data, and captures visual hierarchies naturally, which is why CNNs dominated computer vision for nearly a decade. The bias allows the model to learn edges, shapes, and object parts very efficiently, and this is exactly why CNNs perform so well on tasks like ImageNet classification or simple medical imaging where the spatial structure is consistent.
When is it not good?
However, this same inductive bias becomes a limitation when the data does not obey the assumptions that CNNs rely on, for example when long range interactions matter more than local neighborhoods, or when the spatial arrangement of features is not consistent across the dataset, or when the model needs to reason globally rather than locally. In such cases the CNN struggles because its rigid locality and translation invariance assumptions prevent it from capturing relationships that span far apart regions, which is one reason why transformers started outperforming CNNs on large scale vision tasks where global attention is important.
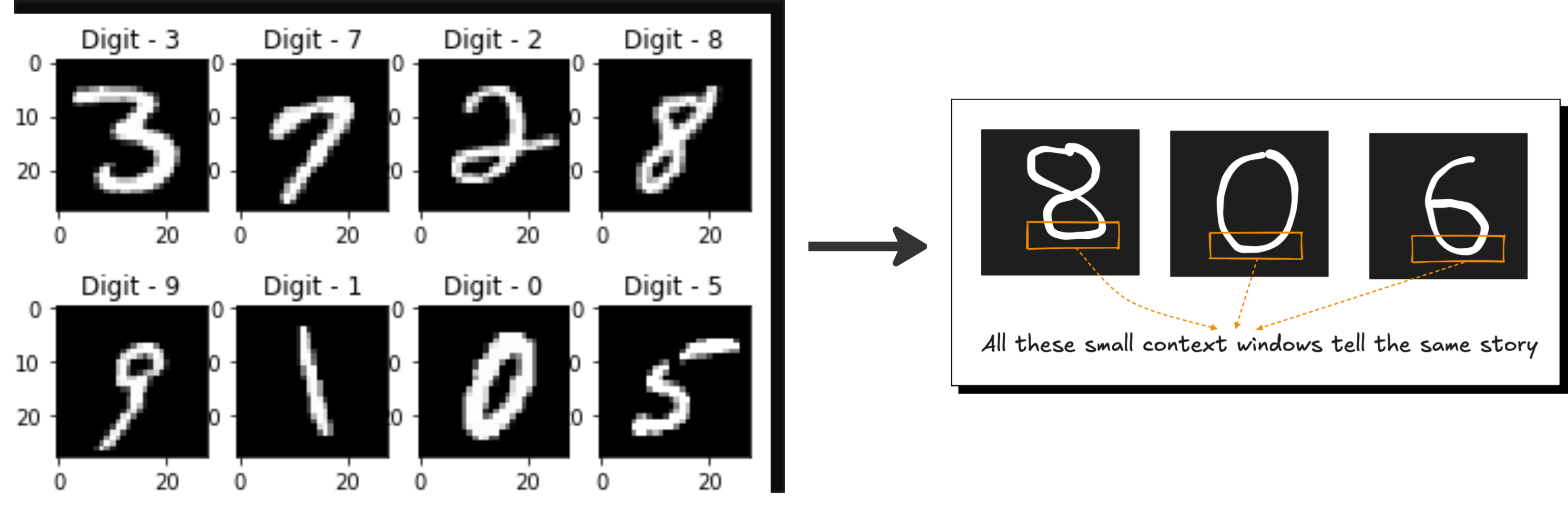
So, inductive bias in CNNs is good when the assumptions match the structure of the data and bad when the task needs flexible, global, or relational reasoning that cannot be captured by small sliding filters, and this is exactly why the field gradually moved from CNN dominance to transformer based models as datasets became larger and tasks became more complex.

The quality of these blogs is so good! Please continue to inform us with such blogs , additionally it would be nice to have further reading leading to other good sources too.