
What exactly is a Vision Transformer?
And how is it different from transformer?


There was a time when Convolutional Neural Networks (CNNs) ruled the world of computer vision. If you had an image classification problem, CNNs were your go-to. The idea was intuitive and elegant: use small filters to look for patterns, share those filters across space, and stack them layer by layer to extract richer and more abstract features.
For years, this worked beautifully. CNNs were fast, parameter-efficient, and achieved breakthrough performance on datasets like ImageNet. Models like AlexNet, VGG, and ResNet became household names in the deep learning world.
But there were some major problems.
The CNN dilemma
CNNs are built on three assumptions:
Locality - Features can be detected in small local regions.
Translation invariance - A filter that detects a car should detect it whether it is at the top-left or bottom-right of the image.
Weight sharing - Filters can be reused across spatial locations to reduce parameters.
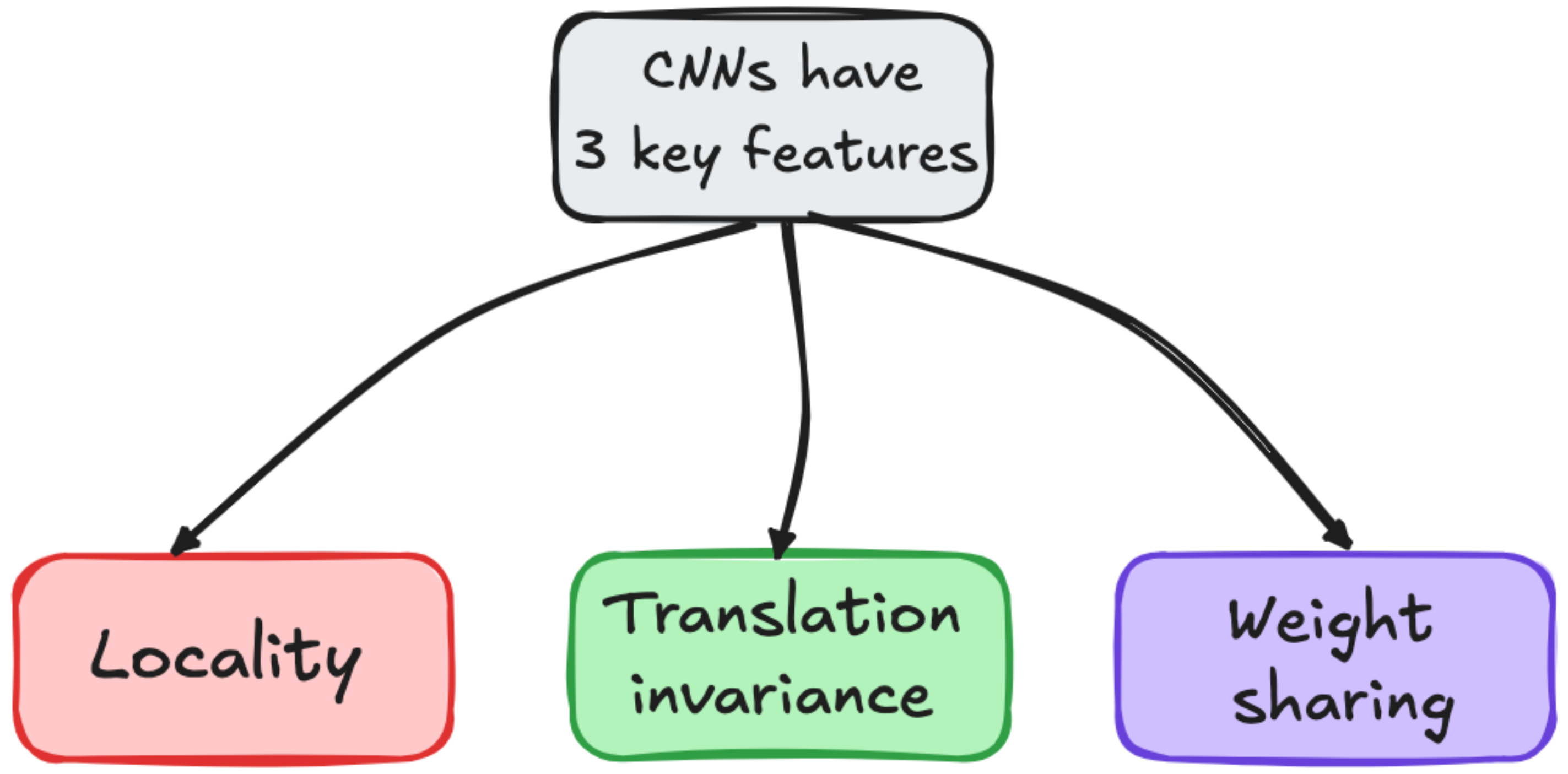
These assumptions gave us models that were lean and fast. But they also limited what CNNs could understand.
Take translation invariance. Imagine a CNN detecting a car floating in the sky. The model might confidently say “car” because the filter for detecting car-like edges activates. But it will miss the absurdity of the situation - cars do not belong on top of buildings. CNNs, in their classic form, lack an understanding of global context.

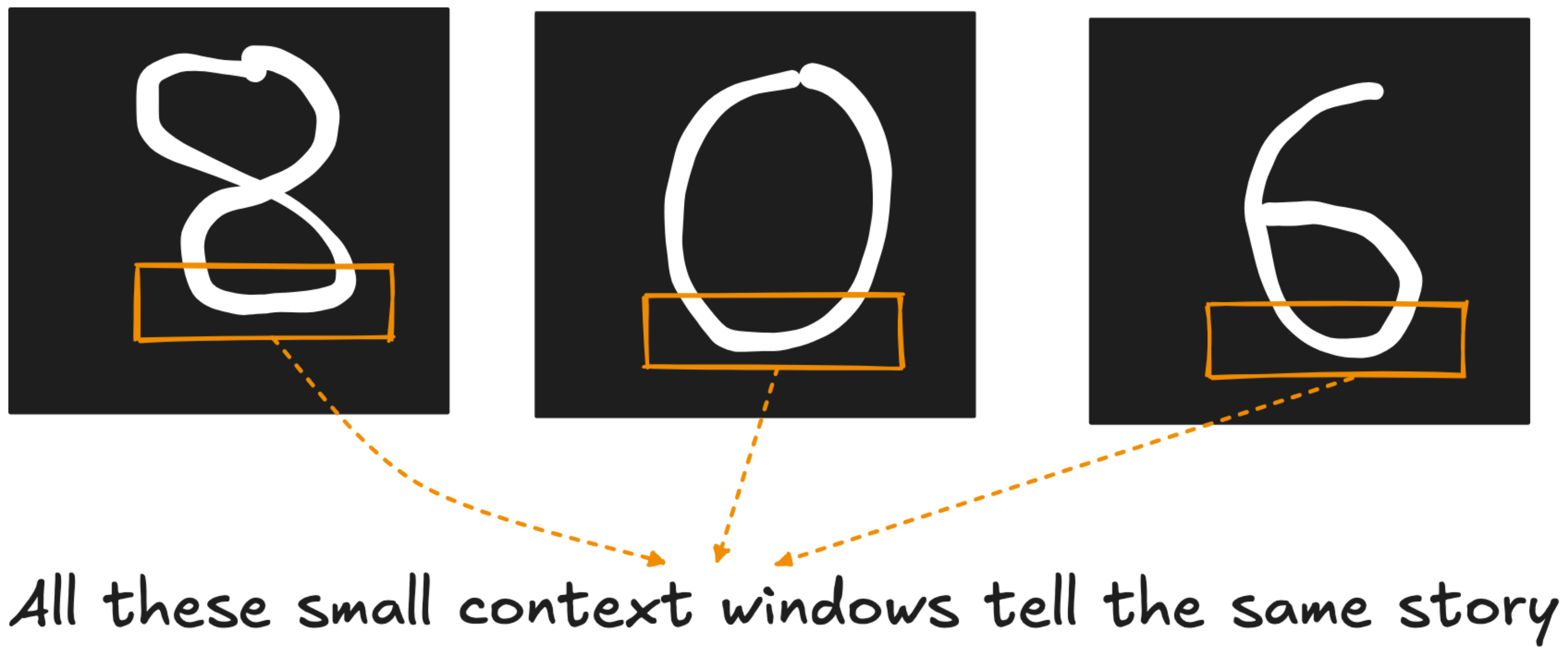
Another problem is the receptive field. A 3×3 filter looks at 9 pixels at a time. To understand the entire image, you need to stack many layers so the network can “see” more. But more layers lead to problems like vanishing gradients and long training times.


This is where Transformers come in.
Transformers: From words to vision
Originally built for language, Transformers changed everything. In 2017, the paper “Attention is All You Need” proposed an architecture that could learn dependencies between distant words using something called self-attention.

Rather than processing sequences step-by-step like RNNs, Transformers look at the entire sequence at once. Every token attends to every other token through learned attention weights.
At the heart of this architecture are three vectors:
Query (Q)
Key (K)
Value (V)
Each token creates a query to ask, “Who else in the sentence is relevant to me?” It checks against all keys (like pointers) and uses the results to weight the values. This gives us a new representation of the input, one that reflects not just the token itself, but how it relates to others.
And instead of doing this once, Transformers do this with multiple attention heads in parallel, each looking at different aspects of the relationships.


A Transformer block includes:
Multi-head self-attention
Residual (skip) connections
Layer normalization
Feed-forward neural networks (MLPs)
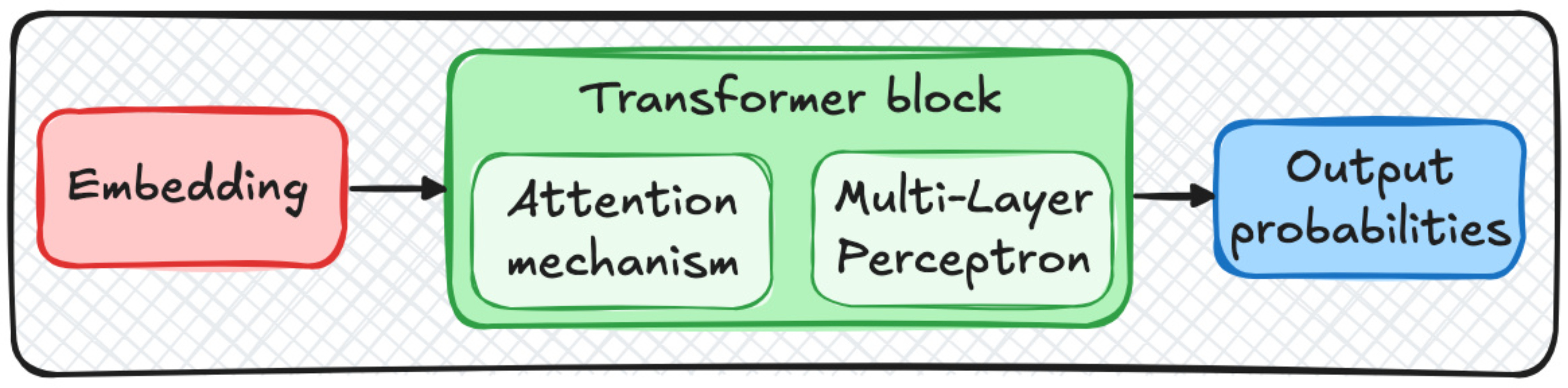
All of this is repeated multiple times (12 times in GPT-2, for instance), allowing the model to build deep, context-aware representations of input data.

But what if we applied this same idea to images?
Vision Transformer (ViT): A new paradigm
The Vision Transformer (ViT), introduced by Google Brain in the paper “An Image is Worth 16x16 Words”, does exactly that.
The idea is almost poetic:
Just as a sentence can be split into words (tokens), an image can be split into patches - and each patch can be treated like a word.
So instead of convolving filters over the image, ViT slices the image into non-overlapping patches (say, 16×16 pixels each). Each patch is flattened into a vector. If the image is 48×48 and each patch is 16×16, you get 9 patches in total.
Each patch vector is then projected into a fixed-dimensional embedding (768 in most models), and just like in text Transformers, a positional embedding is added so the model knows where each patch came from.
But there is one more trick: a special CLS token is added at the beginning of the sequence. This token learns to aggregate information from all patches. At the end of the Transformer stack, this CLS token is used for classification.


Why this works
Vision Transformers solve several limitations of CNNs:
They do not assume locality. A patch can attend to any other patch.
They do not share weights spatially, allowing more flexibility.
They allow global context learning from the very first layer, instead of waiting for receptive fields to expand.
And they scale beautifully with data. Just like GPT trained on massive text corpora, ViTs trained on huge image datasets (like JFT-300M) can generalize well across tasks.
But ViTs are data-hungry. They do not come with the same inductive biases that CNNs have, so without enough data, they can underperform. That is why pretraining (like in NLP) becomes essential.
Vision transformer architecture



From CNN to ViT: A shift in mental models
In CNNs, you learn filters. In Transformers, you learn relationships.
CNNs process pixel neighborhoods. Transformers process patch interactions.
CNNs rely on architecture depth to get global understanding. Transformers have global understanding baked in through self-attention.
If you already understand Transformers for text, transitioning to Vision Transformers is natural. The architecture is the same. Only the input changes.
What comes next?
In this lecture, we covered the entire journey:
CNN basics and limitations
Transformer internals - embeddings, attention, query/key/value, MLPs
How ViT repurposes these ideas for image classification
Why CLS token replaces the last-token logic of GPT
How to prepare image patches and compute final predictions
And how the output becomes a probability distribution across classes (e.g., 5 or 1000)
In the next session, we will implement the Vision Transformer - first on a small dataset, and then compare its performance head-to-head with a CNN trained on the exact same data.
Spoiler: the results are fascinating.
If you liked this breakdown, check out our full Computer Vision from Scratch series, and subscribe to follow our practical implementations of ViT, CNNs, and more.
See you in the next one.
Wish to learn AI/ML live from us?
Check this: https://vizuara.ai/live-ai-courses/