
What exactly is a Data efficient image Transformer (DeiT)?
And how does it use teacher-student model?

Table of Content
Problem with vision transformers
Introduction to the DeiT paper
Introduction to the teacher-student model
What is knowledge distillation?
DeiT architecture
CLASS and DISTIL tokens
The distillation mechanism
DeiT loss function overview
What is KL divergence loss?
So, how good was DeiT compared to other models?
Key points to note in DeiT architecture
DeiT loss function detailed
Ground-truth (standard classification) loss
Teacher (distillation) loss
What is the teacher?
What does the teacher provide?
Why is temperature used?
Why multiply by T^2?
Final combined loss
Coding DeiT from scratch
Conclusion
Other resources
Problem with vision transformers
Vision Transformer (VIT) requires a huge amount of data for training. More importantly, ViTs do not assume locality or translation invariance, unlike CNNs.
Convolution has a property called translation invariance or translation equivariance, as shown in the figure below.
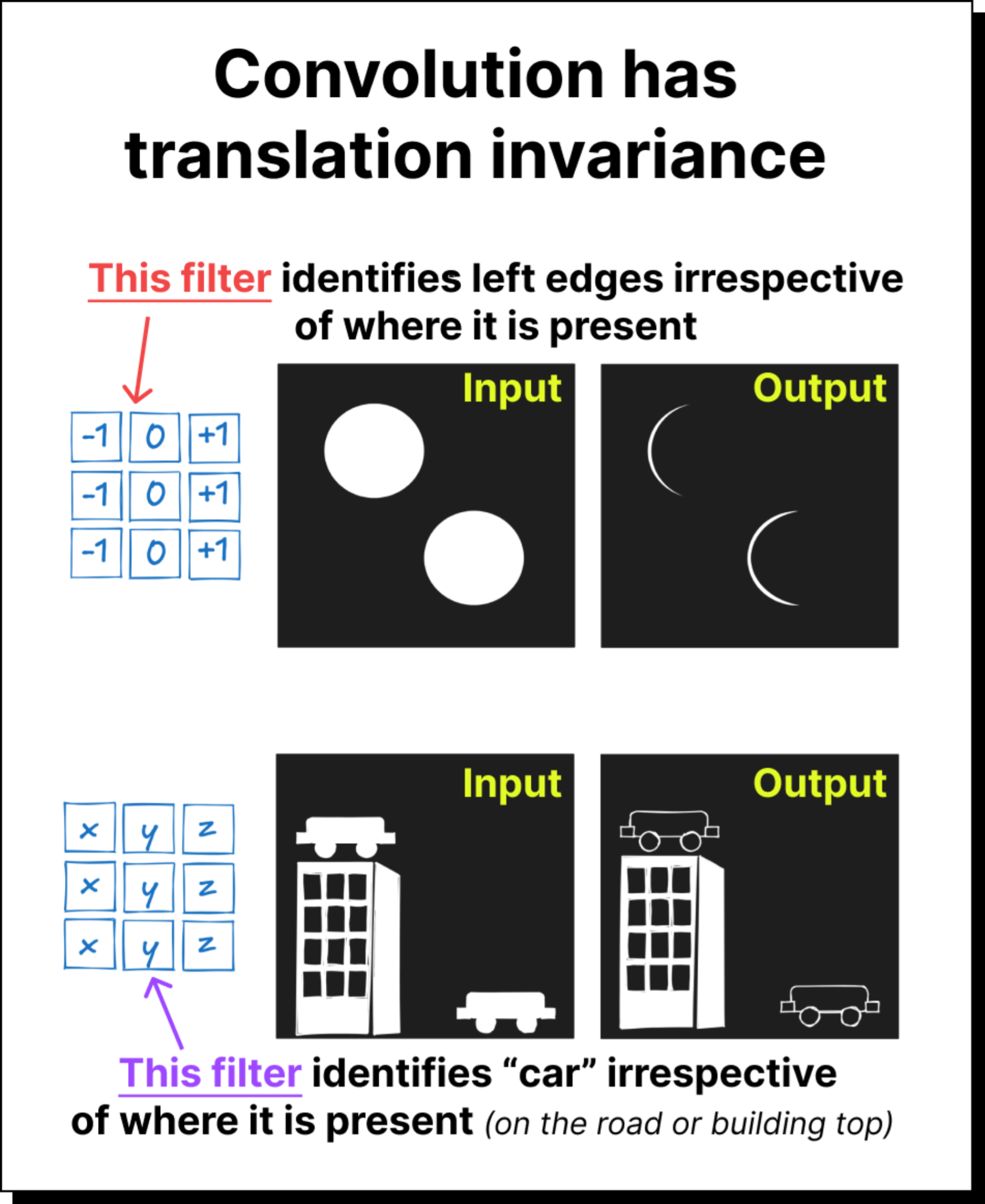
Convolution also comes with locality bias meaning features are assumed to be local.
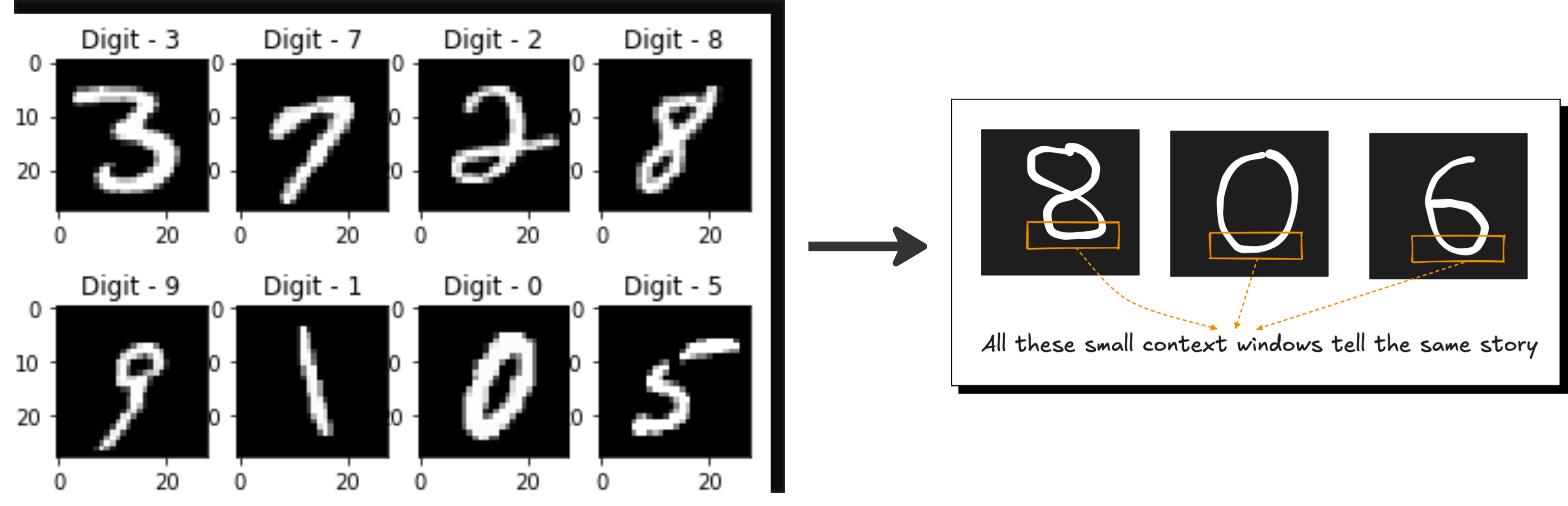
Many image-based applications require long-range dependencies. For example, if there is a person who is crossing a street, a self-driving car should ideally not move forward even if the light is green. It doesn’t matter how far the pixels corresponding to the green light and the pixels corresponding to the person are. So this is something that convolution will struggle to capture.
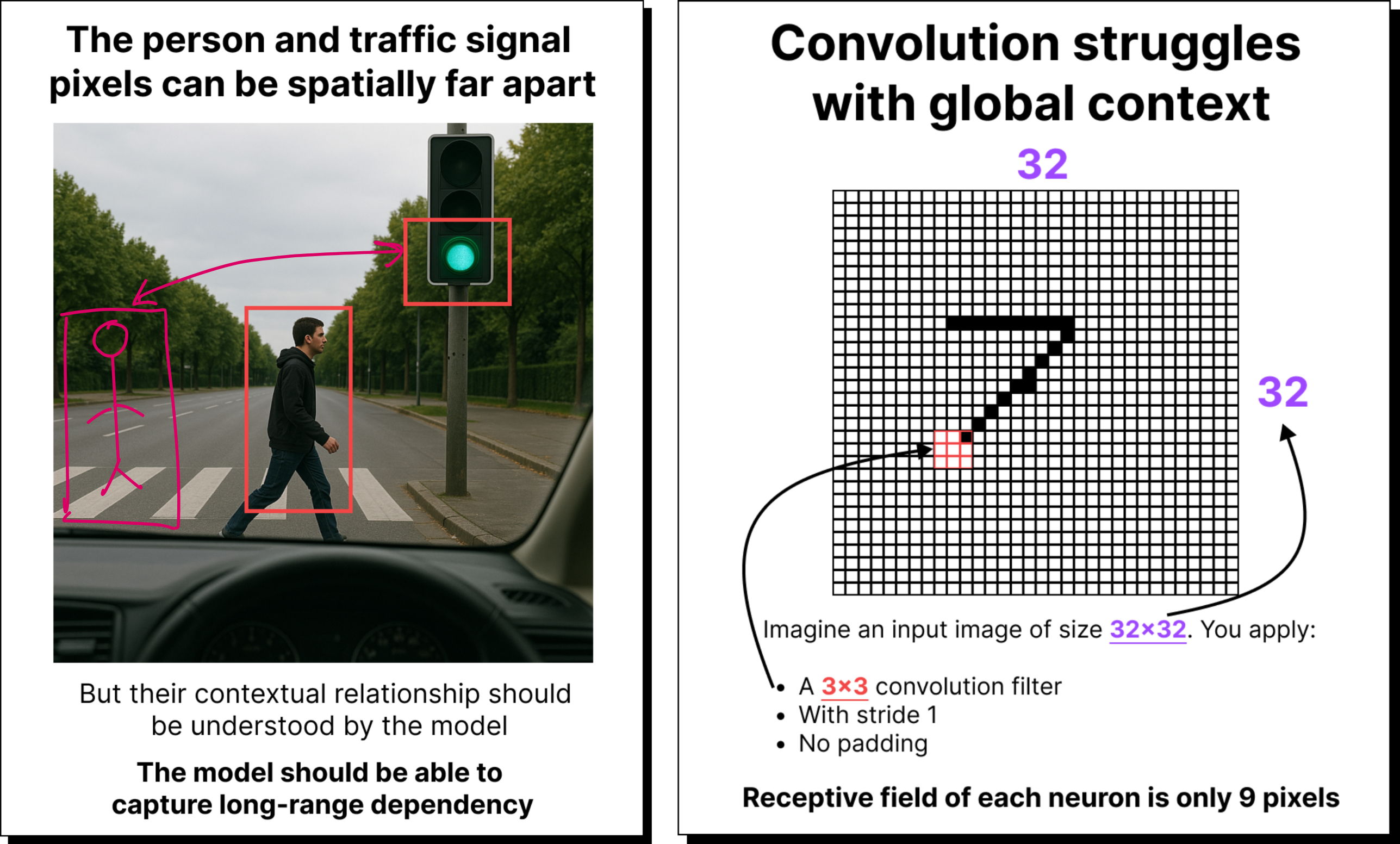
And for the above reasons Vision Transformer has the following shortcomings:
They need to “learn” these properties from data instead of being built into the architecture.
As a result, ViTs need huge labeled datasets and long training schedules to reach the same performance as CNNs.
Introduction to the DeiT paper
The data-efficient image transformer paper was written by a team of researchers from Facebook AI Research. It has more than 10,000 citations now and is regarded as one of the most seminal papers that extended the capabilities of Vision Transformer.

This is the link to the paper published on arXiv: https://arxiv.org/abs/2012.12877

The DeiT paper aimed to make Transformers data-efficient enough to train on standard ImageNet-1k (1.2M images) without pretraining. Please note that the original ViT model was trained on around 300 million images.
I am copying the snippet below directly from the DeiT paper, which quotes the ViT paper.

The paper “Data-efficient Image Transformers (DeiT)” (ICML 2021) showed that ViTs can be trained from scratch without large datasets by introducing knowledge distillation from a strong CNN teacher.
Now this begs the question: what exactly is a teacher-student model>
Introduction to the teacher-student model
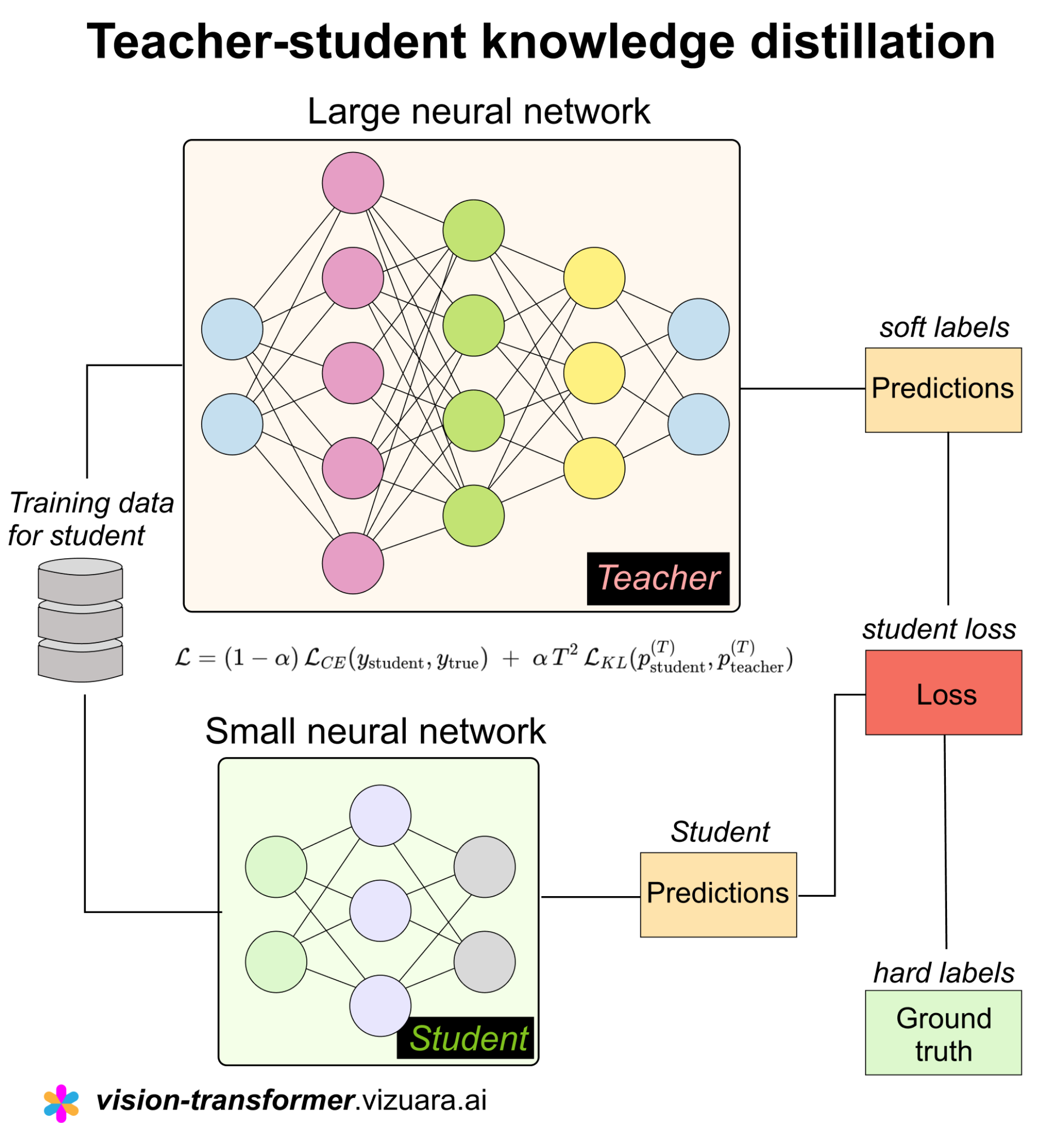
The teacher-student model is a very intuitive way of thinking about how knowledge can be transferred from a complex system to a simpler one. It mirrors how learning often happens in real life as well.
In this setup, the teacher is usually a large, powerful, and well-trained model that has learned rich representations from data, often with high accuracy but also high computational cost, while the student is a smaller, lighter model that we actually want to deploy in practice because it is faster, cheaper, and more efficient to run.
Instead of training the student directly on hard labels alone, the idea is to let the student learn by observing the teacher’s behavior, especially the probability distributions or soft predictions that the teacher produces, because these predictions contain much more information than just the final class label. They reflect the teacher’s understanding of similarities and ambiguities in the data.
What is knowledge distillation?
Knowledge distillation is the formal process by which this transfer from teacher to student occurs, and the key insight is that the soft targets produced by the teacher encode what is often called dark knowledge, meaning information about how the teacher ranks different classes and how confident it is in each.
During training, the student is optimized to match these soft outputs, typically using a softened softmax with a temperature parameter, along with or sometimes instead of the original ground truth labels.
This helps the student learn smoother decision boundaries and capture generalization patterns that would be very hard to infer from hard labels alone, especially when the dataset is small or noisy.
As a result, the student often performs surprisingly well, sometimes approaching the teacher’s accuracy while using a fraction of the parameters and compute.


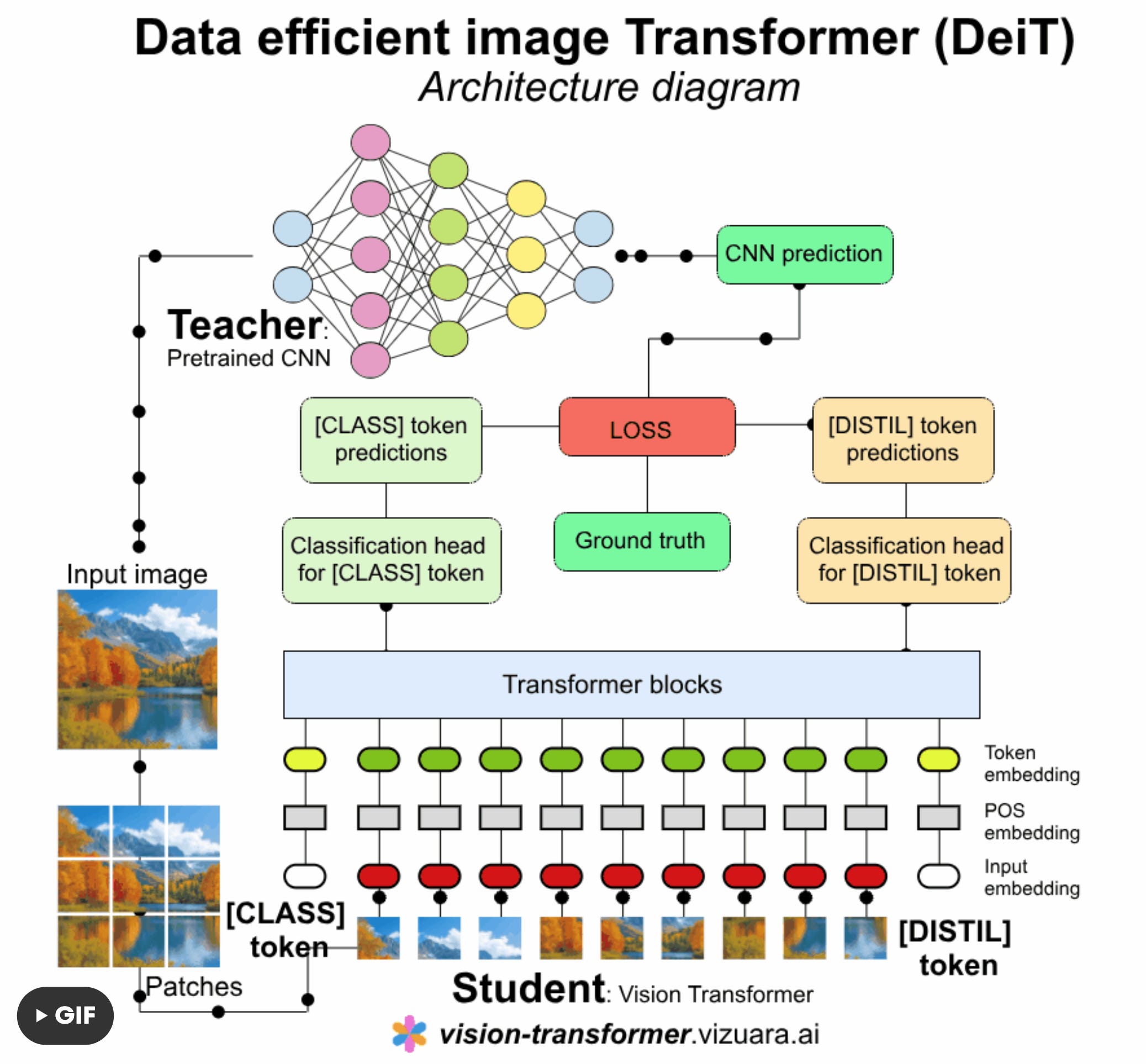
DeiT architecture
DeiT retains the ViT architecture:
Patch embedding → positional embedding → transformer encoder → classification head.
Each image is divided into fixed-size patches, flattened, and linearly projected into embedding vectors.
The below architecture diagram of DeiT is the modified version, which I have adopted from the DeiT paper.
CLASS and DISTIL tokens
The most significant difference between DeiT and other architectures is the Distillation Token. The original Vision Transformer only had the classification token, also known as the class token.
Two special tokens are appended: the [CLS] token for class prediction and the [DIST] token for distillation learning.
Both tokens are updated through all transformer layers via self-attention.
The MLP head at the top maps the final embedding of the [CLS] token (for standard classification) and the [DIST] token (for teacher supervision) into class probabilities.
The distillation mechanism
The knowledge distillation mechanism happens through a teacher-student style setup.
Teacher-Student setup: A pretrained CNN (teacher) guides the transformer (student).
In performing knowledge distillation, we can use hard distillation or soft distillation.

DeiT uses hard distillation, where the [DIST] token learns from the teacher’s output while the [CLS] token learns from the ground truth labels.
DeiT loss function overview
In DeiT, the loss function is built to help a Vision Transformer learn efficiently from limited data. The core idea is that the model should learn from two sources at the same time.
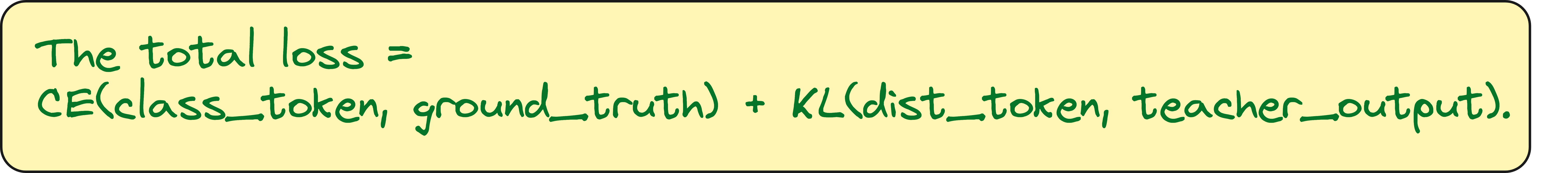
The first loss is a standard cross-entropy loss. This loss is computed between the class token output and the ground truth label. This part is exactly the same as regular supervised training. It ensures that the model learns the actual classification task correctly.
The second loss is also a cross-entropy loss. This time it is computed between the distillation token output and the teacher’s predicted label. In DeiT, the teacher gives a hard label, not a soft probability distribution. Because of this, DeiT uses hard distillation instead of the usual KL-divergence-based soft distillation.
The final training loss is simply the sum of these two losses. In most cases, they are averaged. This forces the student transformer to agree with both the dataset labels and the teacher’s decisions. During inference, the model can use the class token alone or combine both outputs.
What is KL divergence loss?
Kullback–Leibler divergence, usually called KL divergence, is a loss function that measures how different two probability distributions are. It is not a distance in the strict mathematical sense. Instead, it tells us how much information is lost when one distribution is used to approximate another. In machine learning, it is commonly used when both the target and the prediction are probability distributions.
The KL divergence loss between a teacher distribution P and a student distribution Q is written as:
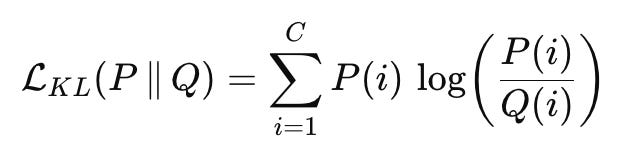
Here, C is the number of classes, P(i) is the probability assigned by the teacher to class i, and Q(i) is the probability assigned by the student to the same class.
In knowledge distillation, these probabilities usually come from a softmax with temperature T, so the loss is often written as:
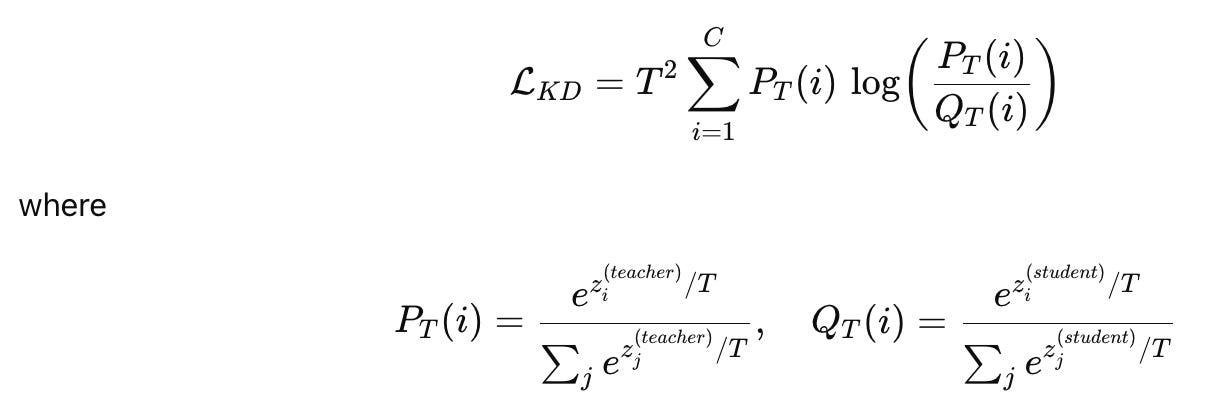
Let us take a straightforward classification example with three classes, say cat, dog, and horse, and assume we already have a well trained teacher model and a smaller student model that we want to train using KL divergence. For one input image, the teacher does not just say “this is a cat”; instead, it outputs probabilities like cat 0.7, dog 0.2, horse 0.1, which already tell us that the image looks mainly like a cat, with some similarity to a dog and very little to a horse. This full probability vector is the teacher distribution.
Now assume the student model, for the same image, outputs cat 0.4, dog 0.4, horse 0.2, which clearly shows confusion between cat and dog and more uncertainty overall. KL divergence compares these two distributions class by class and asks a simple question: how much information is lost if the student’s distribution is used instead of the teacher’s distribution. Since the student assigns much less probability to the cat compared to the teacher and too much probability to the dog and horse, the KL divergence value will be high.
During training, the KL divergence loss pushes the student to move closer to the teacher’s behavior. Over time, the student updates its parameters so that its output slowly becomes something like cat 0.65, dog 0.25, horse 0.1, which is much closer to what the teacher believes. When the two distributions become similar, the KL divergence becomes small, and this indicates that the student has successfully absorbed the teacher’s knowledge, not just the final label, but also the relative confidence across classes.
So, how good was DeiT compared to other models?
DeiT outperformed ViT and comparable-size EfficientNet models (SOTA at the time) in terms of performance and accuracy.
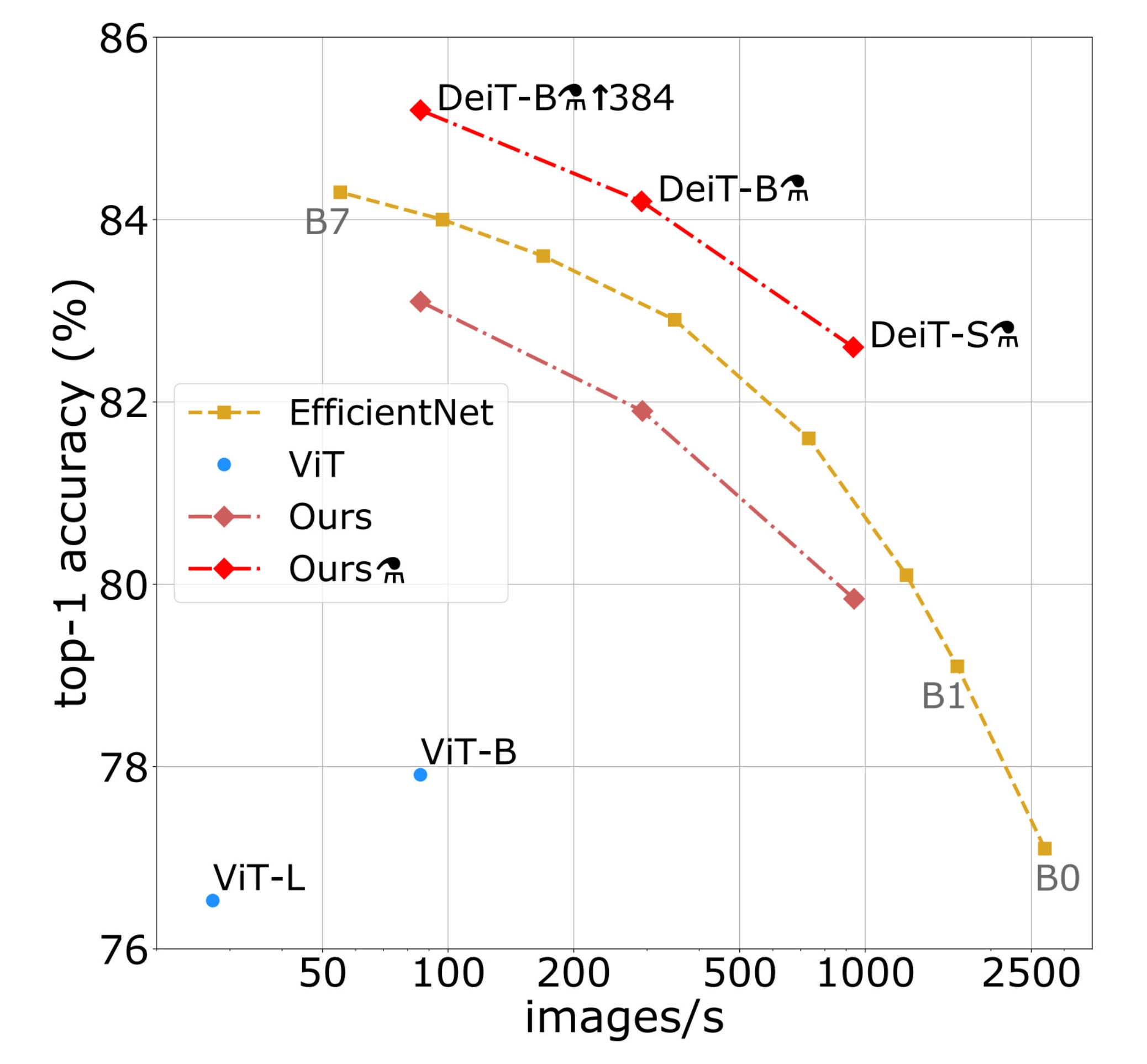
Key points to note in DeiT architecture
I am noting these points here as a reminder to myself and also for those what had the same questions as me.
DISTIL token is randomly initialized just like CLASS token
We use pretrained CNN or ViT
CNN is used only for producing soft/hard targets using given input image
CNN does not directly influence the value of DISTIL
DeiT loss function - detailed
Big picture first. DeiT trains a Vision Transformer using two teachers at the same time:
The real ground-truth label
A strong CNN teacher’s prediction
The model is asked to satisfy both, and the final loss is a weighted combination of these two objectives.
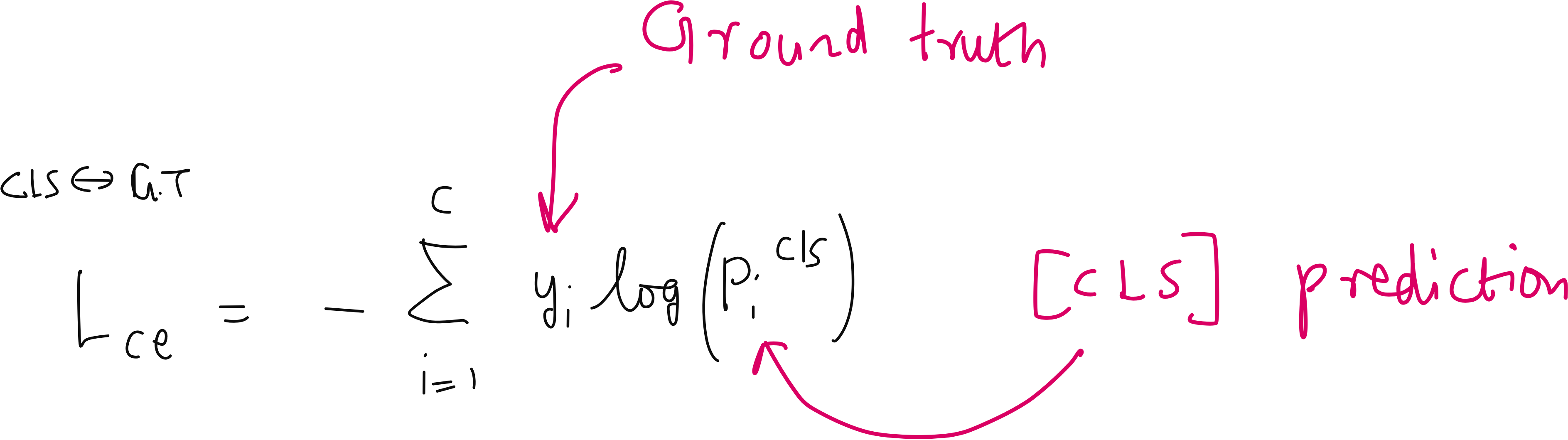
Ground-truth (standard classification) loss
What is happening conceptually? The Vision Transformer produces a prediction using its [CLS] token. This prediction is compared with the true label provided in the dataset.
If the model assigns high probability to the correct class → good.
If it assigns probability to the wrong class → penalty.
Why is this needed? This ensures the model learns: “What class does this image actually belong to?” This is just normal supervised learning.
Teacher (distillation) loss
This is the key innovation of DeiT.
What is the teacher?
A pretrained CNN (for example, RegNet).
The CNN is fixed - it is not trained further.
What does the teacher provide?
Instead of a single hard label, the teacher gives:
A soft probability distribution over all classes
Example intuition:
“This image is 70% cat, 20% dog, 10% fox”
This contains much richer information than a single label.
Why is temperature used?
The teacher’s logits are divided by a temperature TTT before softmax.
Higher temperature → softer probabilities.
This reveals:
Which wrong classes are less wrong
How the teacher ranks alternatives
So the student learns relative class similarities, not just the top-1 answer.
Why multiply by T^2?
When the temperature increases:
Gradients become smaller
Learning signal weakens
Multiplying by T^2 correctly rescales gradients, ensuring:
The distillation signal remains strong
Training stays stable
This is a standard trick from knowledge distillation.
Final combined loss
DeiT does not choose between the two losses - it weighs them.
One term forces correctness w.r.t ground truth
The other forces the imitation of the CNN teacher
A weighting factor decides how much to trust each source.
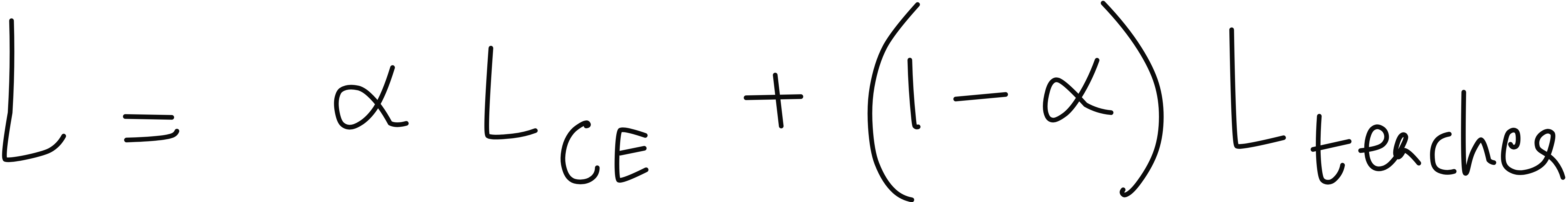
Coding DeiT from scratch
If you wish to code DeiT from scratch, you can do so along with me. Check this out:
If you wish to get access to our code files, handwritten notes, all lecture videos, Discord channel, and other PDF handbooks that we have compiled, along with a code certificate at the end of the program, you can consider being part of the pro version of the “Transformers for Vision Bootcamp”. You will find the details here:
https://vision-transformer.vizuara.ai/
Other resources
If you like this content, please check out our research bootcamps on the following topics:
CV: https://cvresearchbootcamp.vizuara.ai/
GenAI: https://flyvidesh.online/gen-ai-professional-bootcamp
RL: https://rlresearcherbootcamp.vizuara.ai/