
What Duolingo, Uber, and Netflix Teach Us About ML That Works
In this article we will discuss about the difference between Data Scientist and ML Engineer and then we will discuss about Agile Principles aligned with ML Engineering.


Table of content
Introduction: What Is ML Engineering Really About?
A Foundation of Simplicity
Co-opting Principles of Agile Software Engineering
3.1. Communication and Co-operation
3.2. Embracing and expecting change
DevOps vs MLOps: Understanding the Difference
1) Introduction: What Is ML Engineering Really About?
ML Engineering is a recipe of
1)Technology (tools, frameworks, algorithms)
2)People (collaborative work, communication)
3)Process (software development standards, experimentation rigor, Agile methodology)
Striking the right balance between technical execution and collaboration by co-developing maintainable solutions with internal stakeholders in an inclusive and cooperative manner significantly increases the chances of building enduring ML solutions.
Earlier Data Scientist’s job use to revolve around these three steps:
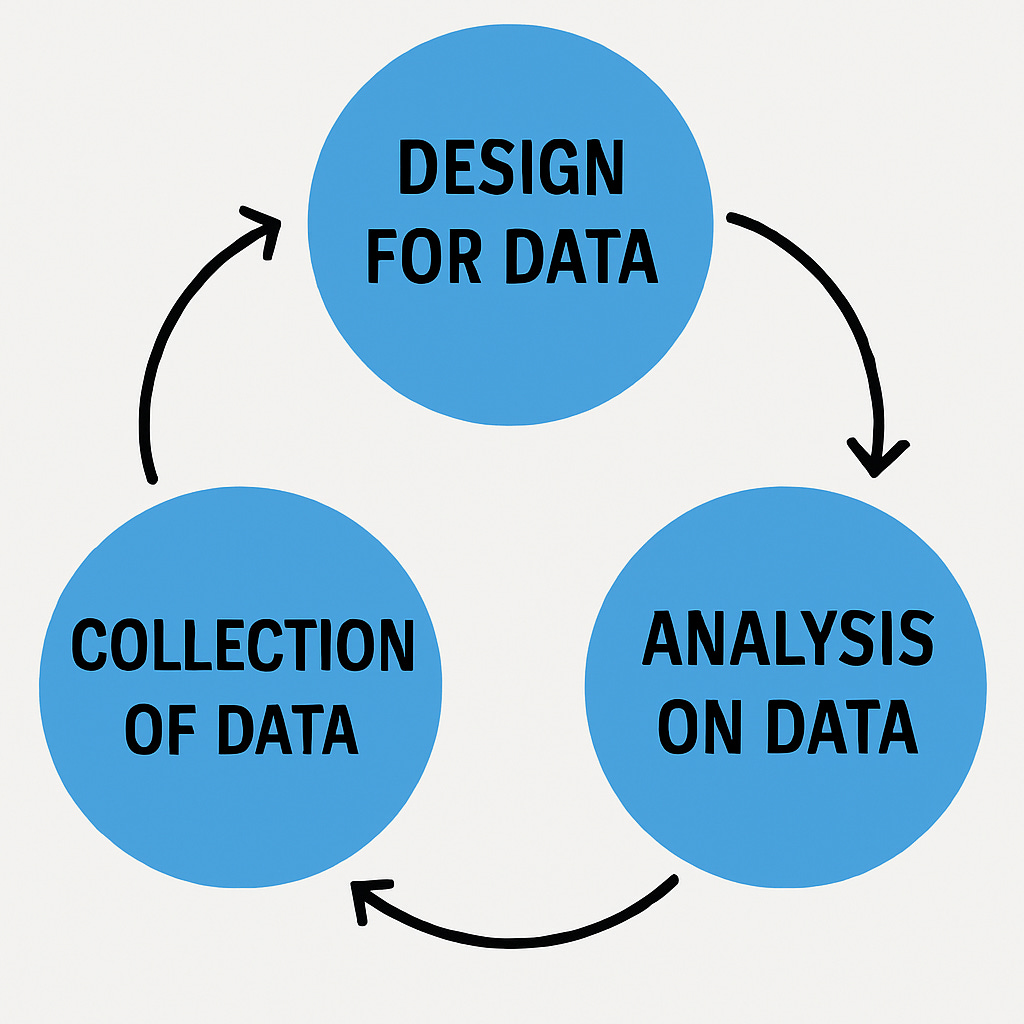
In Modern Era, Data Scientists majorly focuses on Analysis of Data and rest two are managed by Data Engineers in many companies.
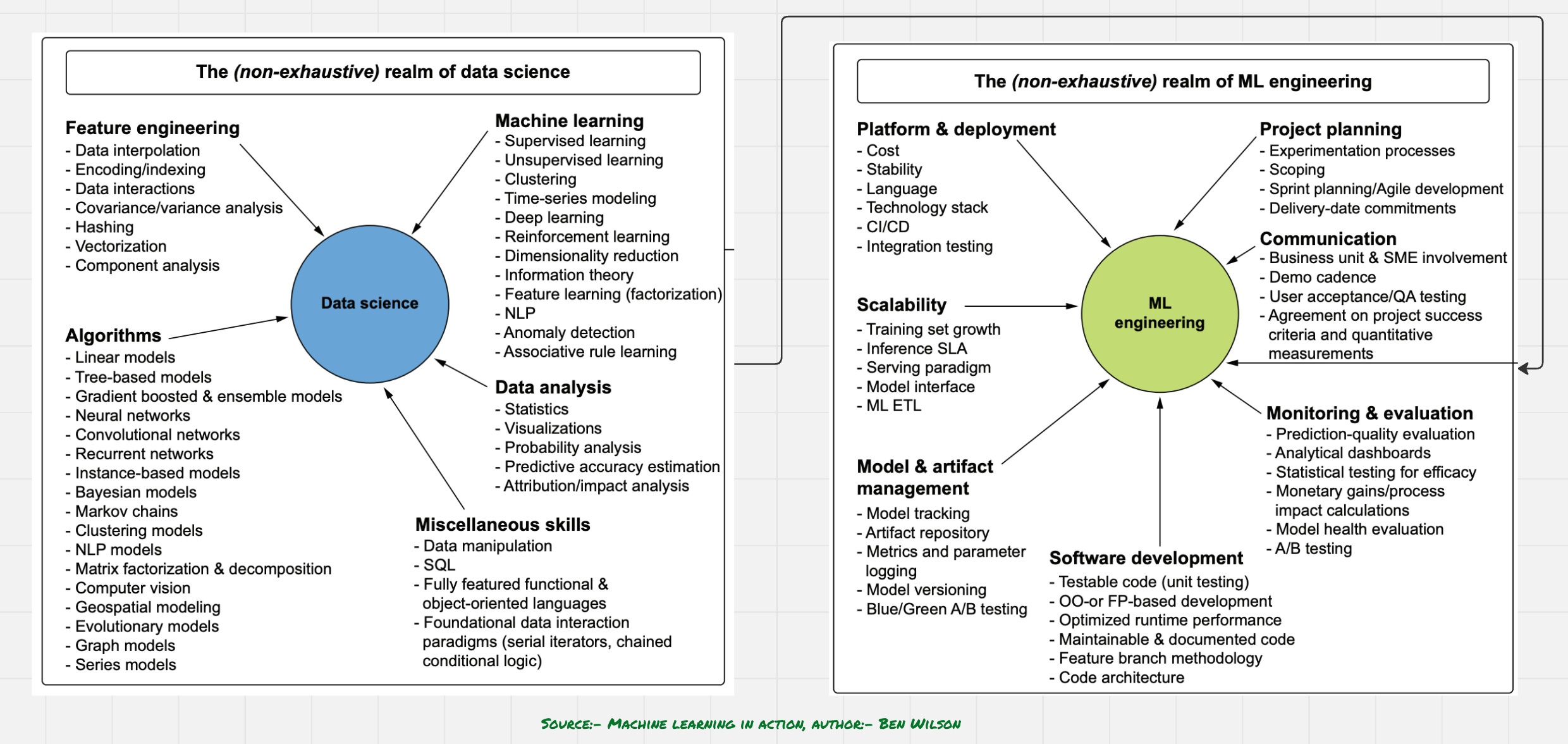
Let us Understand the difference between Data Scientist and ML Engineer
Focus: A Data Scientist dives into data to uncover insights, run experiments, and build predictive models. A Machine Learning Engineer takes those models and makes sure they run efficiently in production environments.
Skills: Data Scientists lean on statistics, data wrangling, and storytelling. Machine Learning Engineers bring strong software engineering, system design, and deployment skills.
Goal Orientation: The Data Scientist’s goal is to understand the problem and find the right model. The Machine Learning Engineer’s goal is to build scalable, maintainable solutions that work reliably in the real world.
Now let’s explore how taking a simple approach in large, complex projects can help complete them with limited resources and reduced costs.
2) A Foundation of Simplicity
Simplicity reduces risk by minimizing technical debt, easing debugging, and speeding up deployment.
Simple models are more interpretable, making collaboration with non-technical stakeholders easier.
Fewer components mean fewer points of failure, which enhances system reliability.
Faster iteration cycles allow for quicker experimentation and feedback loops.
Below are the some examples that will help us in understand how simple approach can save cost and effort in big projects.
1)Customer Complaint Classification: A basic decision tree offers clear, understandable outputs, ideal for support teams compared to a complex deep learning model.
2) Sales Forecasting: Linear regression can deliver actionable insights with minimal setup, unlike ensemble models that are harder to tune and explain.
3) Co-opting Principles of Agile Software Engineering
What Is Agile?
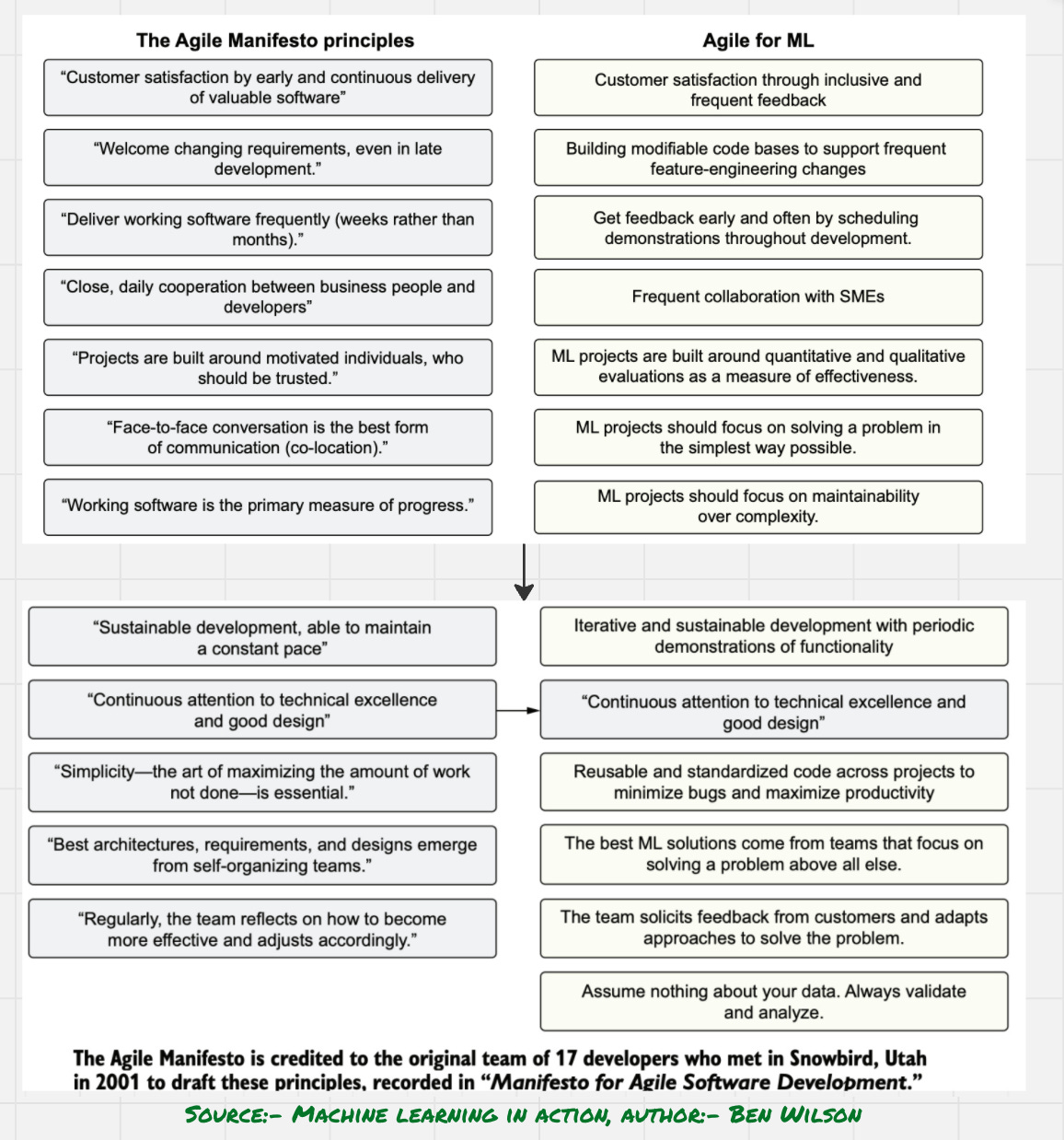
Agile is a development methodology emphasizing iterative progress, stakeholder collaboration, and adaptability to change. Originally formalized in the Agile Manifesto, it guides teams to deliver value incrementally rather than waiting for a final, monolithic release.
Core principles include:
Early and continuous delivery of valuable software
Embracing changing requirements, even late in development
Frequent delivery of working software in short cycles
Close collaboration between cross-functional teams
Reflecting regularly to adapt and improve
Agile aims to reduce project risk, respond quickly to uncertainty, and keep the customer at the center of development.
Applying Agile in Machine Learning (Agile for ML)
Unlike traditional software, ML projects involve experimentation, evolving datasets, and uncertain outcomes. Applying Agile to ML requires contextual adaptations.
Agile practices in ML focus on:
Building modular, modifiable pipelines for frequent iteration (e.g., feature engineering, model versioning)
Delivering incremental improvements and early prototypes (e.g., proof-of-concept models)
Soliciting feedback from SMEs and business stakeholders during development
Prioritizing maintainability and reproducibility over model complexity
Validating assumptions using data-driven tests and metrics, not intuition
Agile ML integrates software engineering rigor with the uncertainty of research, aligning development cycles with measurable business outcomes.
Real-World Agile ML Case Studies

1. Amazon – Recommendation Systems
Introduced recommendation models incrementally through A/B testing.
Used clickstream data to validate model impact on key KPIs like sales and session duration.
Demonstrated how continuous deployment and feedback loops enable scalable personalization.
2. Mayo Clinic – Clinical Risk Prediction
Developed ML models for patient risk classification with doctors in the loop.
Adjusted data pipelines and model explanations based on clinical feedback.
Highlighted the importance of explainability, transparency, and domain input.
3. Uber – Surge Pricing Optimization
Collaborated with operations teams to refine models based on real-world fairness and feedback.
Deployed region-specific versions of pricing models in smaller experimental groups before scaling.
Focused on operational impact over pure model accuracy.
4. Duolingo – Adaptive Learning Algorithms
Used simpler, interpretable models to test hypothesis-driven updates.
Ran frequent controlled experiments (A/B testing) to evaluate user engagement and learning outcomes.
Emphasized iterative learning over deep model complexity.
5. Walmart – Inventory Demand Forecasting
Piloted basic time-series models across selected locations.
Incorporated store-level feedback to revise feature sets and seasonal components.
Deployed models incrementally to reduce operational risk.
With this slight modification to the principles of Agile development, we have a base of rules for applying DS to business problems.
Every Agile Principle is important in the ML Pipeline but let us understand basic and important two principles.
3.1) Communication and Co-operation
1)Collaboration is even more vital in ML than in traditional Agile because the work is complex and often unfamiliar to non-technical teams.
2)Regular, clear discussions between ML teams and business units help avoid misunderstandings and reduce costly rework.
3)Strong communication within the ML team itself is the second key to project success.
4)Working solo may work in school, but not in real ML projectsteamwork is essential for solving complex problems effectively.
Engaging more with your team leads to better ideas and stronger solutions. If you leave out your peers or business stakeholders, even in small decisions, there's a high chance the final outcome won't match their needs or expectations.
3.2) Embracing and expecting change
1)Change is inevitable in ML projects – from goals and algorithms to data assumptions and even the solution type (e.g., replacing ML with a simple dashboard).
2)Expecting change helps teams focus on the real goal – solving business problems, not chasing tools, trends, or fancy models.
3)Planning for change means designing modular, flexible systems – loosely coupled components make future updates much easier.
4)Agile methodology fits well with ML work – its iterative approach supports building adaptable, evolving solutions.
5)Thinking ahead saves effort – without this mindset, even small changes may require complete rewrites.
4)DevOps vs MLOps: Understanding the Difference
What is DevOps?
DevOps is a set of practices that integrates software development (Dev) and IT operations (Ops) to shorten the software development life cycle and deliver high-quality software continuously. It emphasizes automation, continuous integration/continuous delivery (CI/CD), monitoring, and collaboration.
Key Characteristics:
CI/CD pipelines for code deployment
Infrastructure as Code (IaC)
Version control for application code
Automated testing
Monitoring and alerting in production
Source:- https://dlab.berkeley.edu/
What is MLOps?
MLOps (Machine Learning Operations) extends DevOps principles to machine learning systems. It addresses the unique challenges of ML such as model versioning, data drift, reproducibility, and experiment tracking. It brings together ML engineers, data scientists, and DevOps teams to operationalize ML models.
Key Characteristics:
CI/CD/CT pipelines (T = Continuous Training)
Versioning of datasets and models
Experiment tracking and model registries
Monitoring for model drift and performance degradation
Governance for reproducibility and compliance
Let us understand the difference between them using Netflix Case Study:

The Challenge
Netflix aimed to improve its personalized recommendation system, helping users discover content tailored to their interests. However, doing this at a global scale while ensuring reliability and responsiveness required both advanced machine learning and robust engineering practices.
How DevOps Helped
From a system engineering perspective, DevOps practices ensured that Netflix’s infrastructure remained scalable and efficient:
The backend was structured using microservices, with each service responsible for a specific function such as content delivery or authentication.
CI/CD pipelines allowed developers to frequently push updates to production without disrupting service.
Uptime and system performance were continuously monitored to ensure a smooth user experience.
Where MLOps Added Value
On the machine learning side, Netflix implemented MLOps to manage the full lifecycle of its models:
Automated pipelines were used to train recommendation models using user behavior data.
Both datasets and trained models were version-controlled to maintain reproducibility.
A real-time feature store and drift detection tools helped identify shifts in user behavior, enabling timely model retraining.
Shadow testing was applied to evaluate new models in parallel before making them live, reducing risks.
The Outcome
By aligning DevOps for infrastructure with MLOps for machine learning workflows, Netflix successfully retrains models daily and deploys them with zero user disruption. This integrated approach supports their goal of delivering constantly improving, personalized content recommendations at massive scale.
This is the future of ML Engineering: one where simplicity, collaboration, and operational excellence lead the way. Whether you're building a recommendation engine or a chatbot, these principles hold true.
To help you better understand these concepts, check out the video at the link below:
In the next article, we will explore the importance of Planning and Scoping and why it is essential not only for small projects but also for large-scale initiatives in big tech companies.
Interested in learning AI/ML LIVE from us?
Check this out: https://vizuara.ai/live-ai-courses