
Vision Transformer and Multimodal LLMs
Starting in less than a week


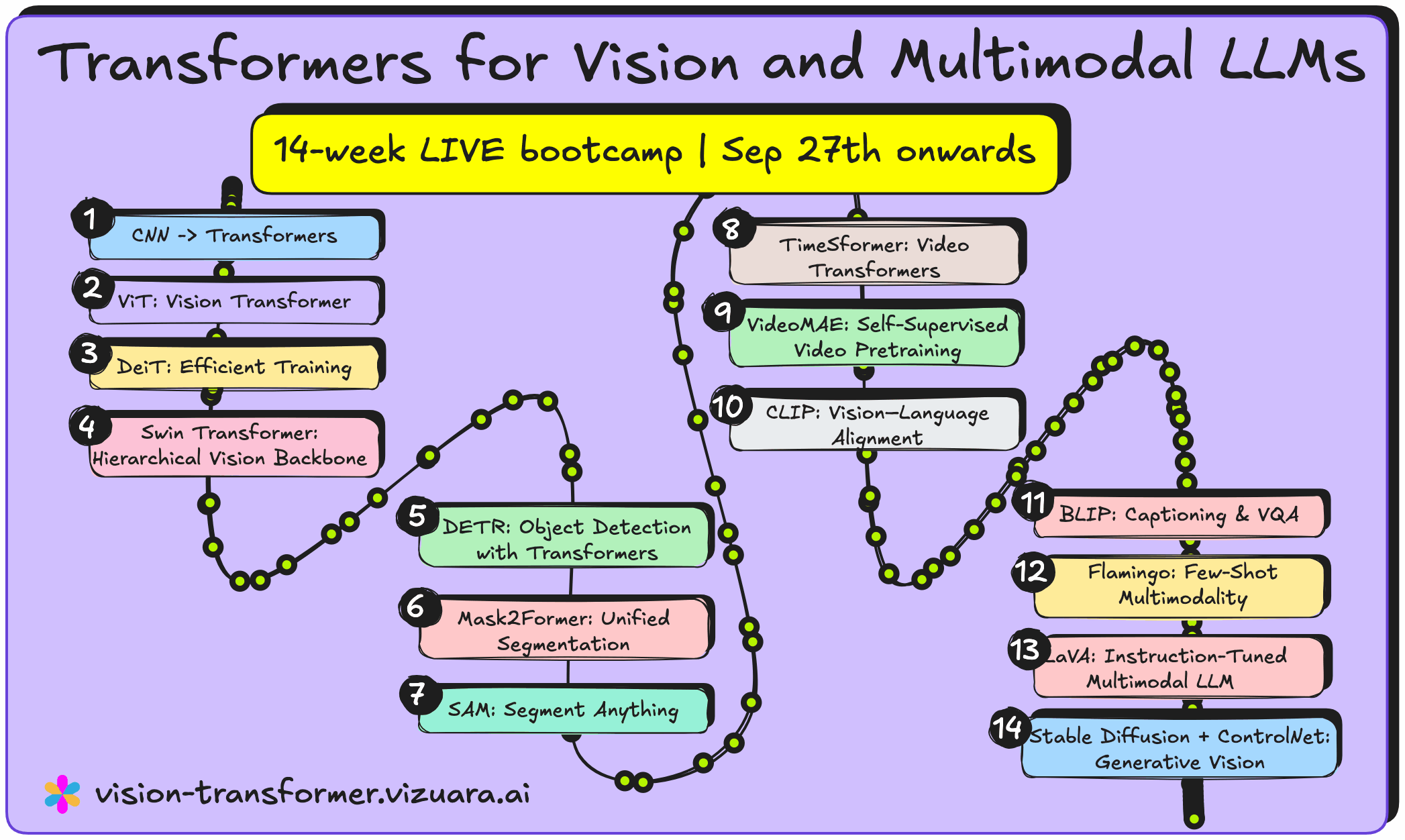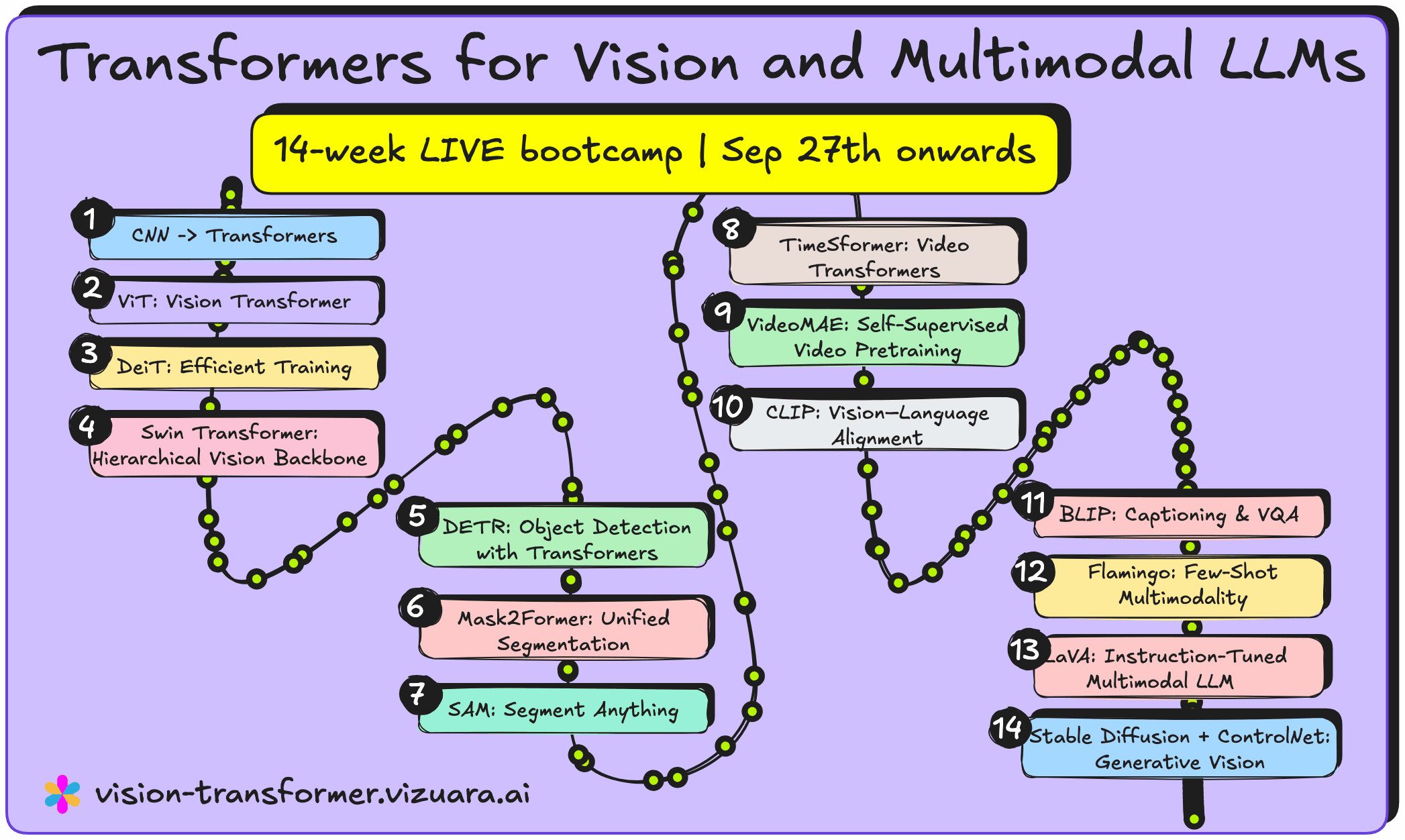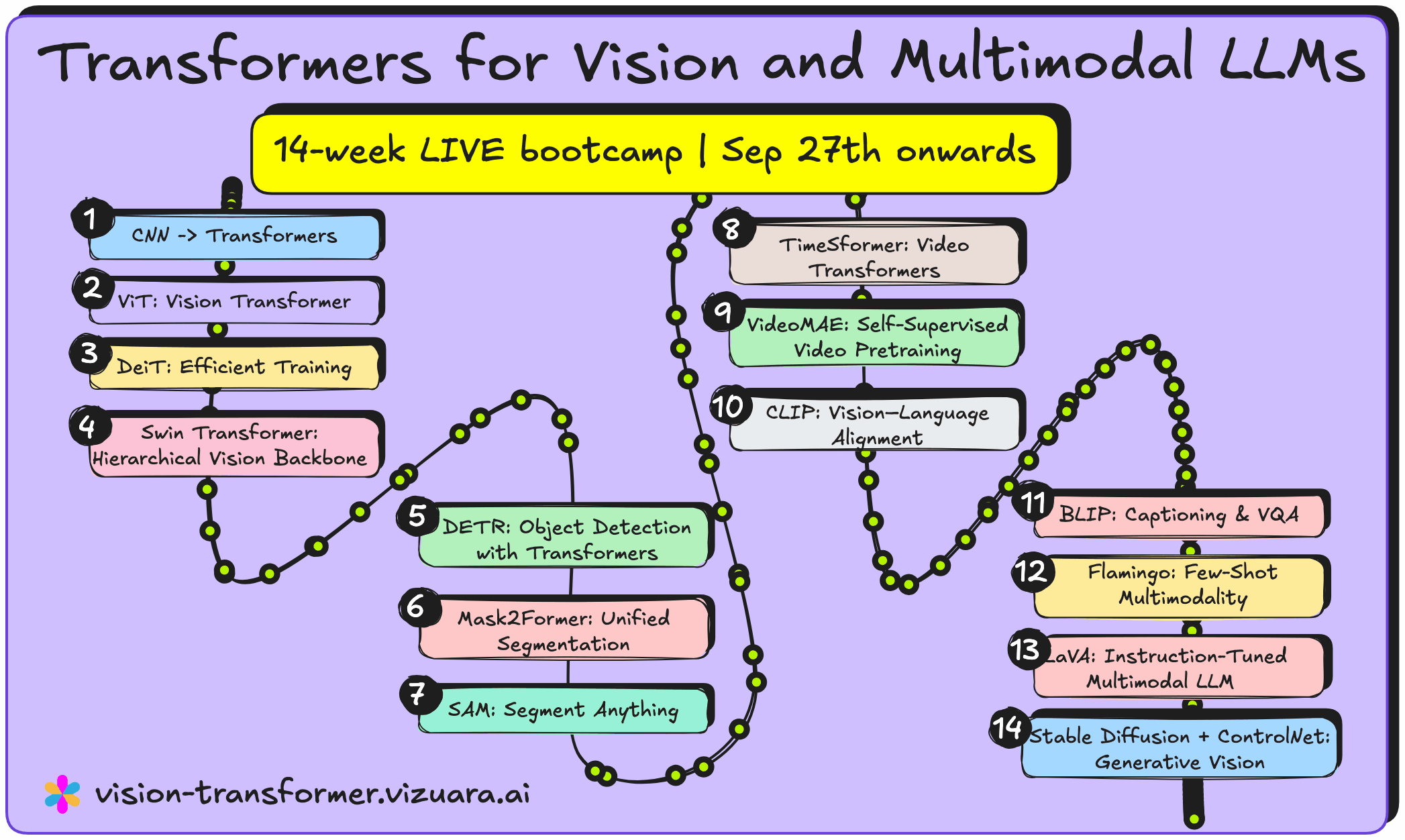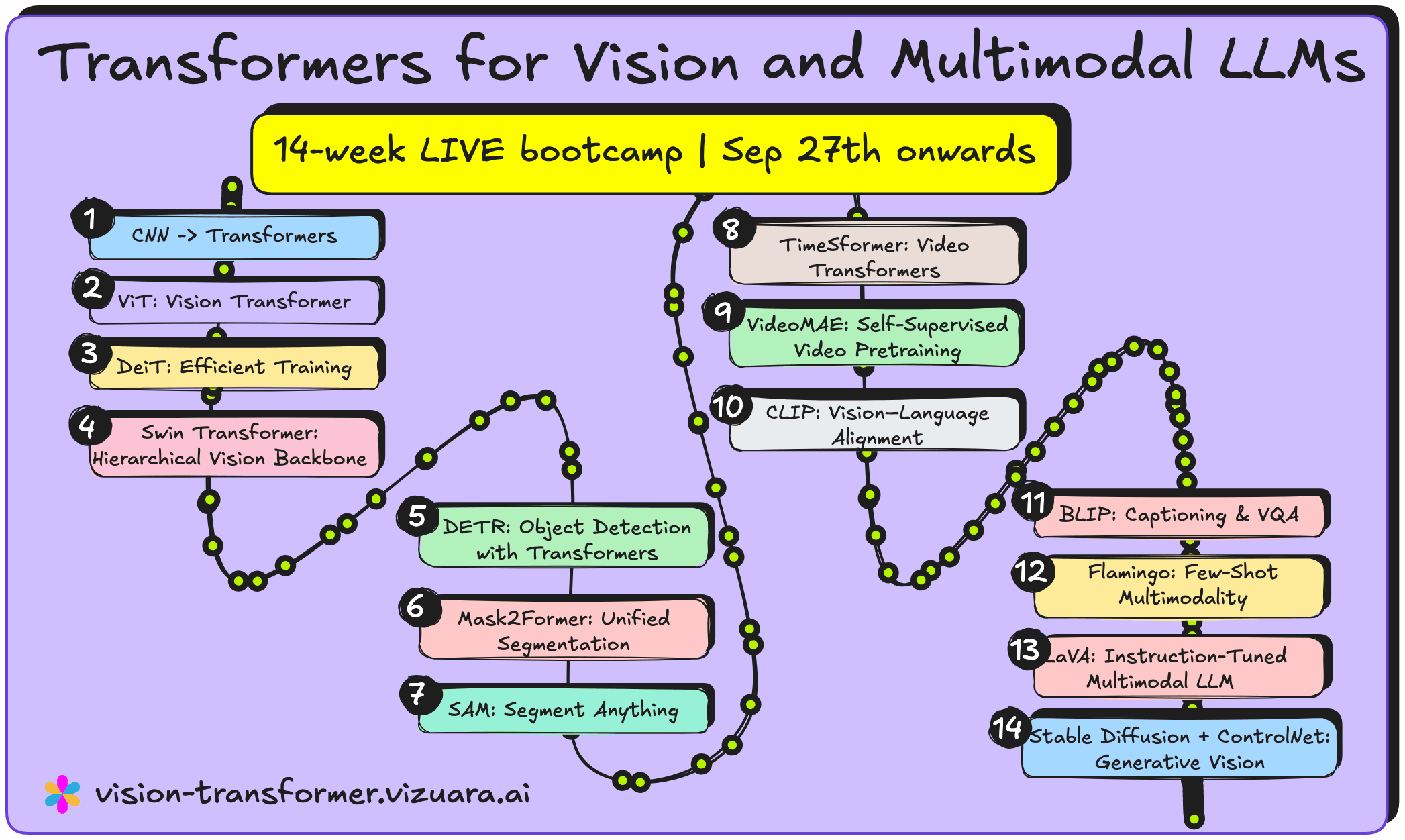
I am delighted to share that something I have been looking forward to for a long time is finally becoming a reality. At Vizuara, we are launching a brand-new 14-week live program on Transformers for Vision and Multimodal LLMs, beginning on Saturday, September 27th, 2025, with weekly sessions from 10:30 AM to 12:00 PM IST.
If you have been following the work that I, along with Raj and Rajat, have been doing, you already know that our teaching style is efficient and hands-on. This program will carry forward the same approach, with a clear emphasis on building real-world projects that you can showcase on GitHub and confidently add to your resume.
Over the 14 weeks, we will progress steadily, starting with the motivation behind the shift from CNNs to attention-based models. From there, we will cover the core vision transformer stack with ViT and DeiT, move into hierarchical backbones like Swin, and then apply these insights to detection and segmentation using DETR and Mask2Former, where you will see how set prediction and queries redefine the problem. We will go further with promptable segmentation through SAM, explore the world of video using TimeSformer and VideoMAE, and then extend to vision-language integration with CLIP, BLIP, Flamingo, and LLaVA. Finally, we will complete the journey by diving into diffusion models and ControlNet, so you gain experience in both understanding and generation in one continuous flow.
Every session will combine theory with implementation. You will fine-tune models, compare architectures, and implement systems that are small enough to complete within the bootcamp yet powerful enough to matter. By the end, you will have at least five complete projects that demonstrate valuable skills such as object detection without anchors, unified segmentation, zero-shot classification with contrastive pretraining, few-shot multimodal reasoning, and controllable image generation. All assignments will come with feedback, and all code will be written in a way that you can adapt for work and research.
I will be teaching this cohort myself. Having done my PhD at MIT, with computer vision as a core area for years, I have taught hundreds of learners, many of whom have appreciated the clarity and depth we bring to our classes. If you are a beginner with some Python and ML basics, you will be perfectly fine.
We have 2 plans. The Free plan gives you access to live and recorded lectures. The Pro plan, priced at ₹25,000, includes detailed notes, code repositories, hands-on assignments with review, office hours with our team, lifetime access, a dedicated Discord community, a certificate, and structured career guidance.
If you are looking for a program that strikes the right balance between solid theory and real implementation, and if you want to gain the confidence to both speak about and build in this rapidly advancing area, I would be glad to welcome you to the class.
Classes start September 27th. Enroll here: