
UNet: the 2015 architecture with 118k+ citations that changed segmentation
And how GenAI brought it back to the center


When U‑Net first appeared in 2015, authored by Olaf Ronneberger, Philipp Fischer, and Thomas Brox, it introduced an elegantly simple but powerful convolutional‑neural‑network architecture in the paper titled “U‑Net: Convolutional Networks for Biomedical Image Segmentation”. It offered a contracting path to capture context and a symmetric expanding path to enable precise localisation, which allowed the network to be trained end‑to‑end with very few annotated samples, yet it outperformed previous methods and even won the ISBI cell tracking challenges by a significant margin - all while segmenting a 512×512 image in under a second on a modern GPU.
The fact that this paper has been cited well over 118,000 times is a testament to its foundational role in semantic segmentation, particularly in the biomedical domain.


Anatomy of the U-Net Architecture: Encoder, Bottleneck, Decoder, and Skip Connections
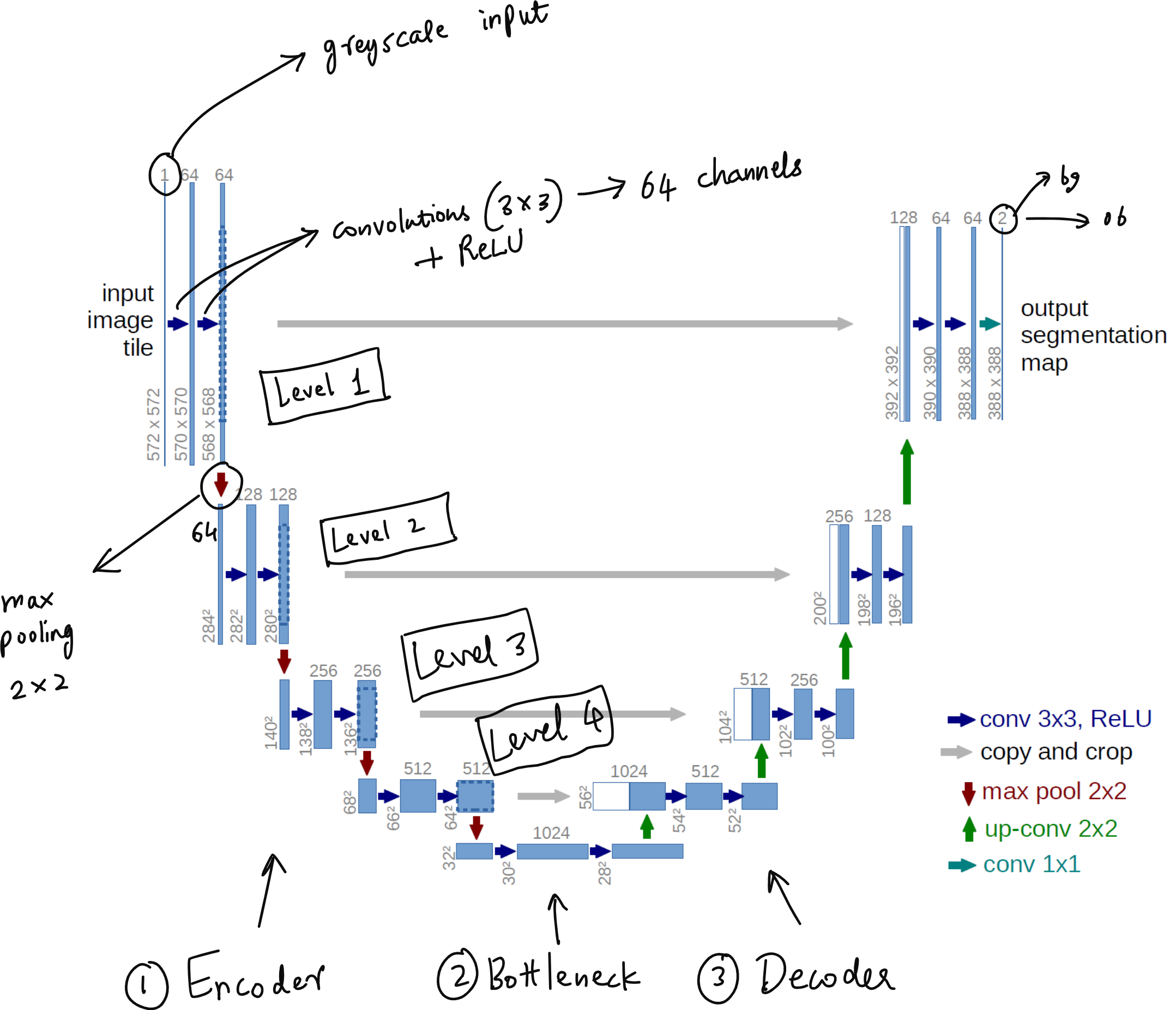
The U‑shaped design of U‑Net comprises three fundamental components: the encoder (contracting path), the bottleneck, and the decoder (expanding path).
Encoder (Contracting Path)
The encoder works by progressively reducing spatial resolution while increasing the depth of feature representations. Typically, each stage consists of two successive 3×3 convolution layers, each followed by a ReLU activation, and then a 2×2 max pooling that halves the spatial dimensions while doubling the number of feature channels. Through this, the network captures increasingly abstract and larger‑scale image context.
Bottleneck
At the bottom of the U‑shape, the bottleneck represents the most compressed level of information. It often consists of two convolution‑ReLU pairs without pooling. This compressed representation forces the model to learn the most critical features for reconstructing the output.
Decoder (Expanding Path)
The decoder reverses the encoder’s process by upsampling. At each stage, a transposed convolution (or up‑convolution) restores spatial dimensions, then halves the number of feature channels, followed by two 3×3 convolutions with ReLU activations. Crucially, each decoder stage receives skip‑connected feature maps from the corresponding encoder stage, merging low‑level spatial details with high‑level context for refined segmentation output.
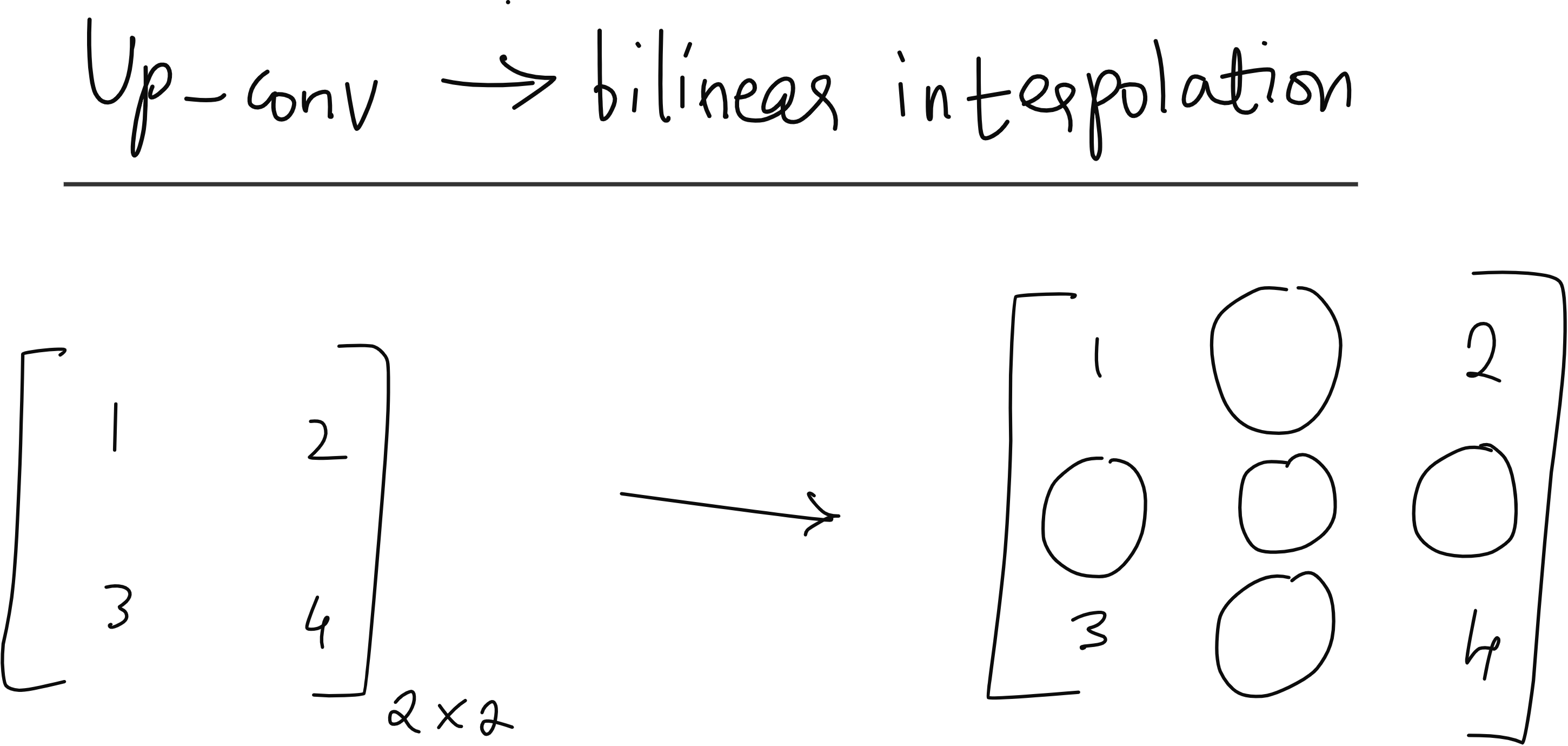
Skip Connections
Skip connections in U‑Net are vital. They bridge encoder and decoder layers at each level, allowing the decoder to access high‑resolution spatial information that would otherwise be lost through pooling operations. This makes segmentation boundaries precise and preserves fine details, which is especially critical in tasks like medical image segmentation.
Why U-Net Became So Influential
Several factors explain U‑Net’s meteoric rise:
Data Efficiency: Trained on limited labelled data via heavy data augmentation, U‑Net still delivered exceptional results.
Simplicity with Power: The architecture is conceptually transparent, yet effective, making it accessible to both researchers and practitioners.
Precision and Speed: Accurate segmentation with crisp boundaries executed in real time on modern GPUs was a rare combination at the time.
Versatility and Extensions: U‑Net’s structure inspired many successors-like UNet++ with nested dense skip pathways that reduce the semantic gap between encoder and decoder, and numerous other variants explored in medical and broader domains.

U-Net Reimagined: Its Revival in Modern Generative AI and Diffusion Models
While U‑Net started its journey in segmentation, today it plays a pivotal role in the world of generative AI, especially within diffusion models such as Stable Diffusion.
The Role of U-Net in Diffusion Models
In these generative pipelines, such as Latent Diffusion Models used by Stable Diffusion, U‑Net serves as the denoising backbone. The process begins by encoding an image into a latent space via a VAE encoder. Then, Gaussian noise is gradually added. A U‑Net model, often incorporating ResNet blocks and Transformer layers, denoises this latent representation over multiple steps using skip connections and attention mechanisms. Finally, the VAE decoder reconstructs the cleaned image back to pixel space.
According to one explanation, Stable Diffusion’s U‑Net contains about 12 encoder blocks, a middle block, and 12 decoder blocks-overall 25 blocks. Among these, eight handle the down‑ and up‑sampling, while the remaining seventeen are complex hybrid blocks with ResNet and Vision Transformer layers
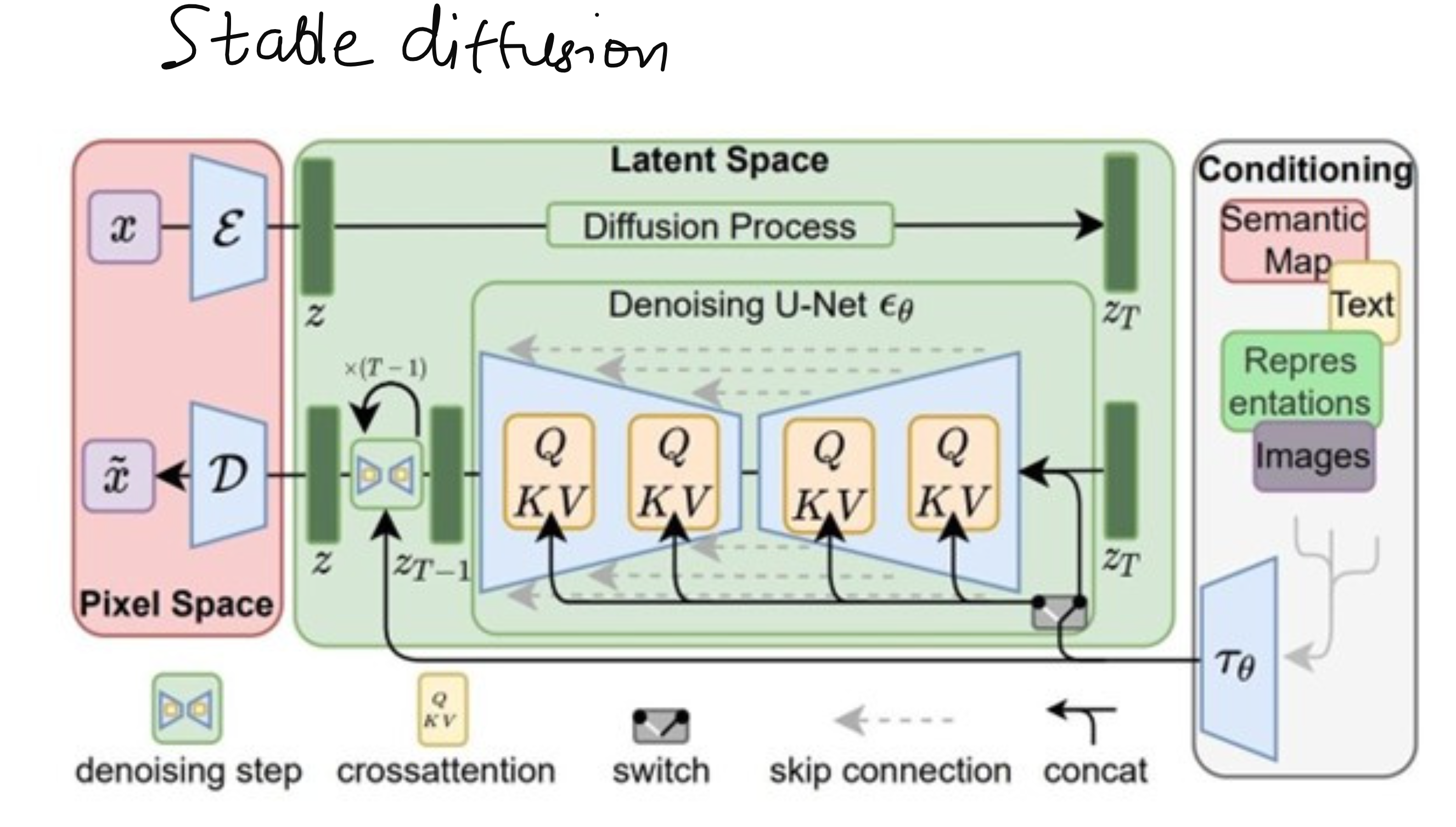
What Makes U-Net So Suited for Diffusion Models
Multiscale Feature Processing: Skip connections carry multiresolution features from encoder to decoder, vital for high‑fidelity image generation.
Temporal Feature Stability: Research shows that encoder features in diffusion U‑Nets change slowly across time‑steps, while decoder features vary more significantly, indicating the decoder’s key role in generating detailed outputs.
Efficiency and Structure: The encoder-bottleneck-decoder template is naturally aligned with iterative denoising and conditioning frameworks.
Conclusion: U-Net’s Enduring Legacy and Modern Revival
In summary, U-Net’s architecture-rooted in a contracting encoder, a central bottleneck, and an expanding decoder with skip connections-transformed the field of semantic segmentation through its data efficiency, speed, and precision. Initially conceived for medical imaging, it transcended its origins to become a foundational structure in generative models, particularly in diffusion-based image synthesis technologies like Stable Diffusion.
What began as a U-shaped network for segmenting microscopy images has now become the engine driving modern AI-powered creativity. The designs introduced in that groundbreaking 2015 paper continue to influence and enable the latest advances in generative modeling, standing testament to the durability and adaptability of thoughtful architecture design.
YouTube lecture
Wish to learn computer vision from scratch
Join our course: https://computervision.vizuara.ai/