
Transformers for Vision and Multimodal LLMs: Lecture 1
An introduction to the bootcamp.


Welcome to the first lecture of the new bootcamp on transformers for vision and multimodal large language models. I am Dr. Sreedath Panat, PhD from MIT and co-founder of Vizuara AI Labs. Over the next series of lectures, I will guide you through the foundations, evolution, and current state of computer vision with transformers.

This bootcamp is not only about building models but also about developing intuition for when to apply them, understanding their strengths and limitations, and learning how they are shaping real-world applications.
My journey into AI and vision
My academic background is rooted in mechanical engineering, but much of my research gradually led me toward computer vision and artificial intelligence. At MIT, one of my thesis projects focused on autonomous solar panel cleaning. Solar panels accumulate dust, which reduces efficiency, and the industry often uses billions of gallons of water each year for cleaning.

To address this, I developed a robotic system that used cameras and convolutional neural networks to classify particle sizes on the panels. Based on the particle size, the system adjusted the cleaning voltage automatically. This project demonstrated the practical power of computer vision while addressing a sustainability challenge.
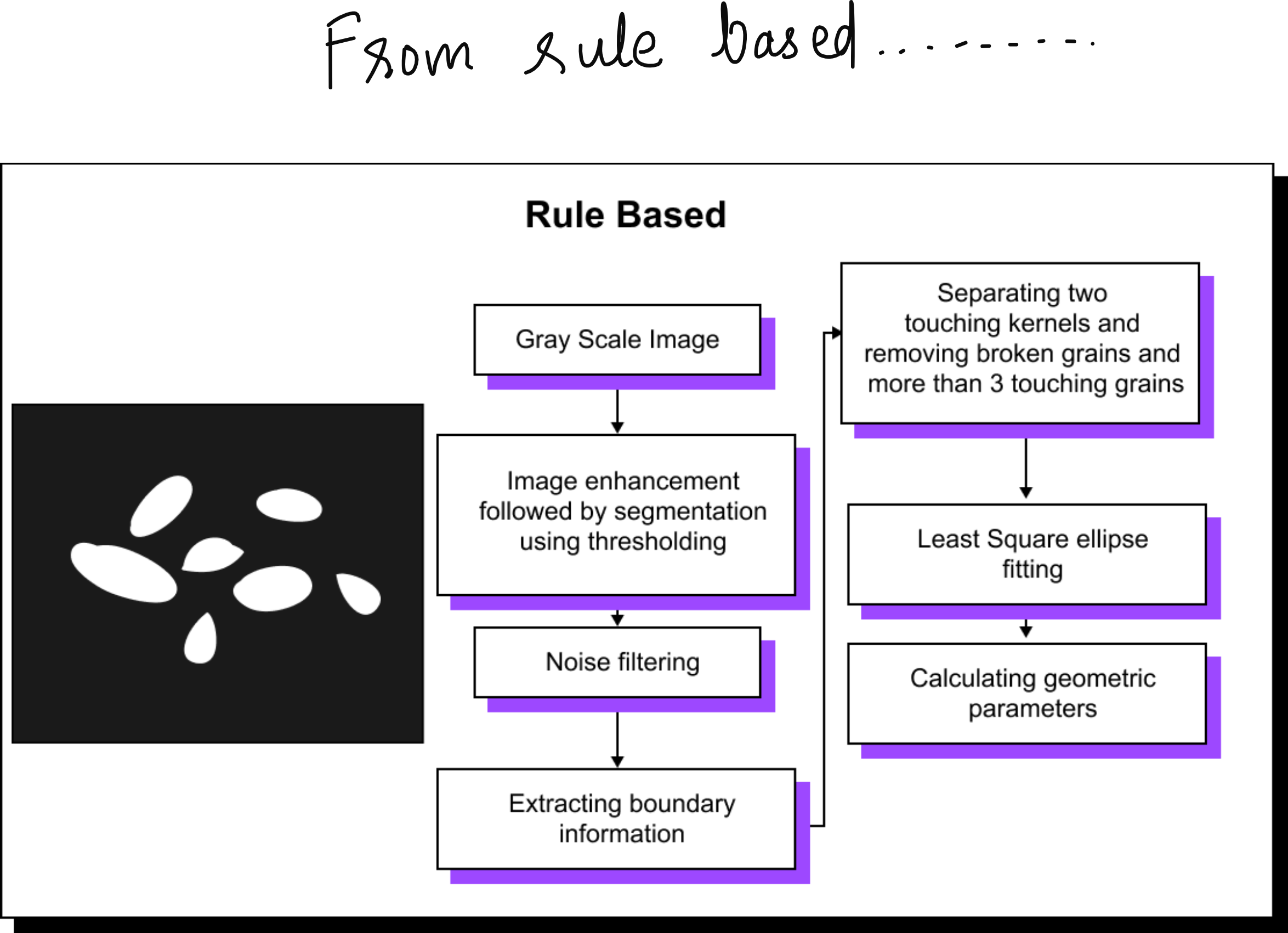
Even before MIT, I had my first exposure to computer vision at IIT Madras around 2015. I worked on a project to classify varieties of rice grains from images. At that time, we relied on hand-engineered features. We applied thresholding, edge detection, and ellipse fitting to estimate grain dimensions. The method worked but was labor intensive and brittle when applied to new conditions.
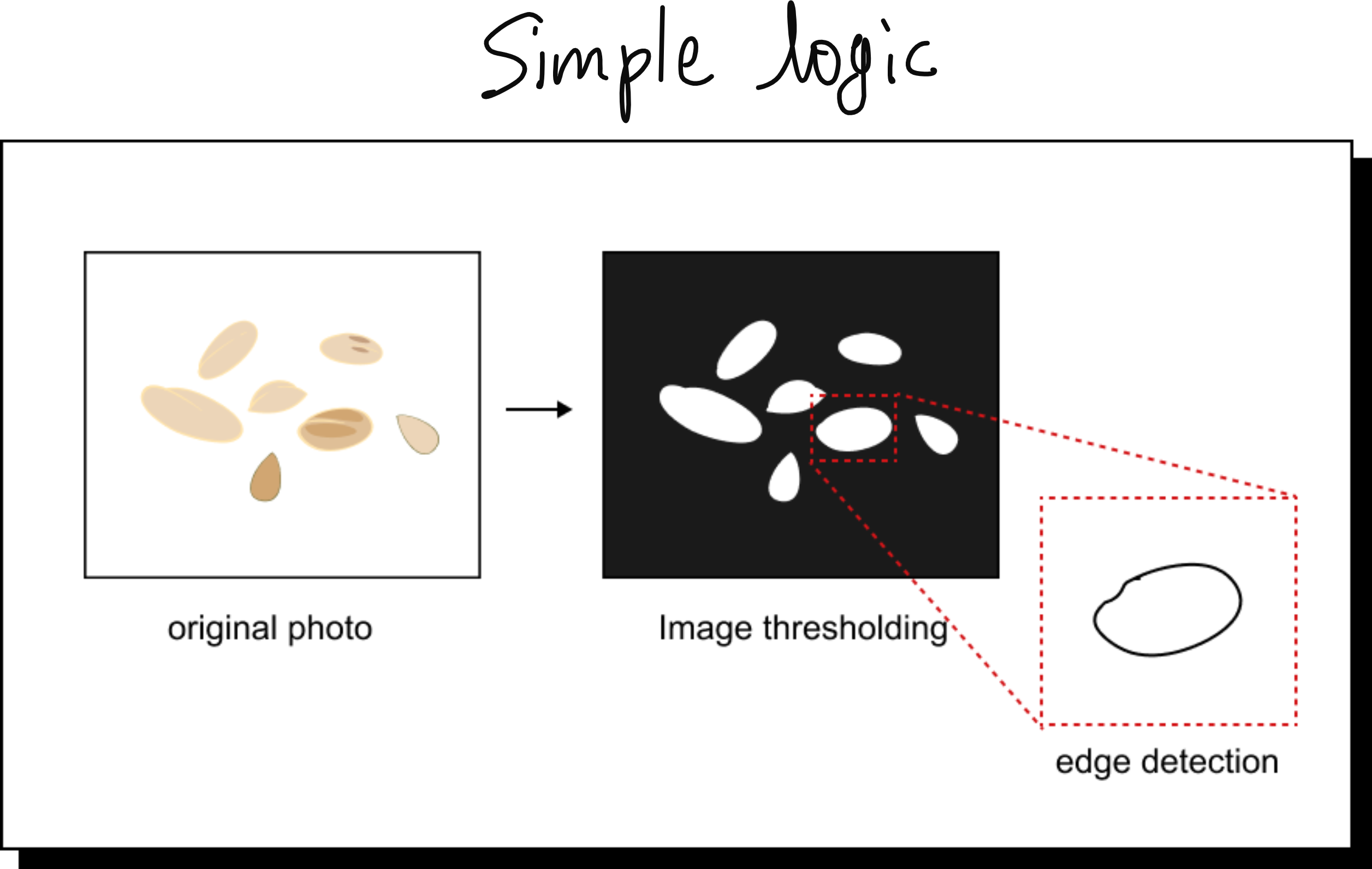
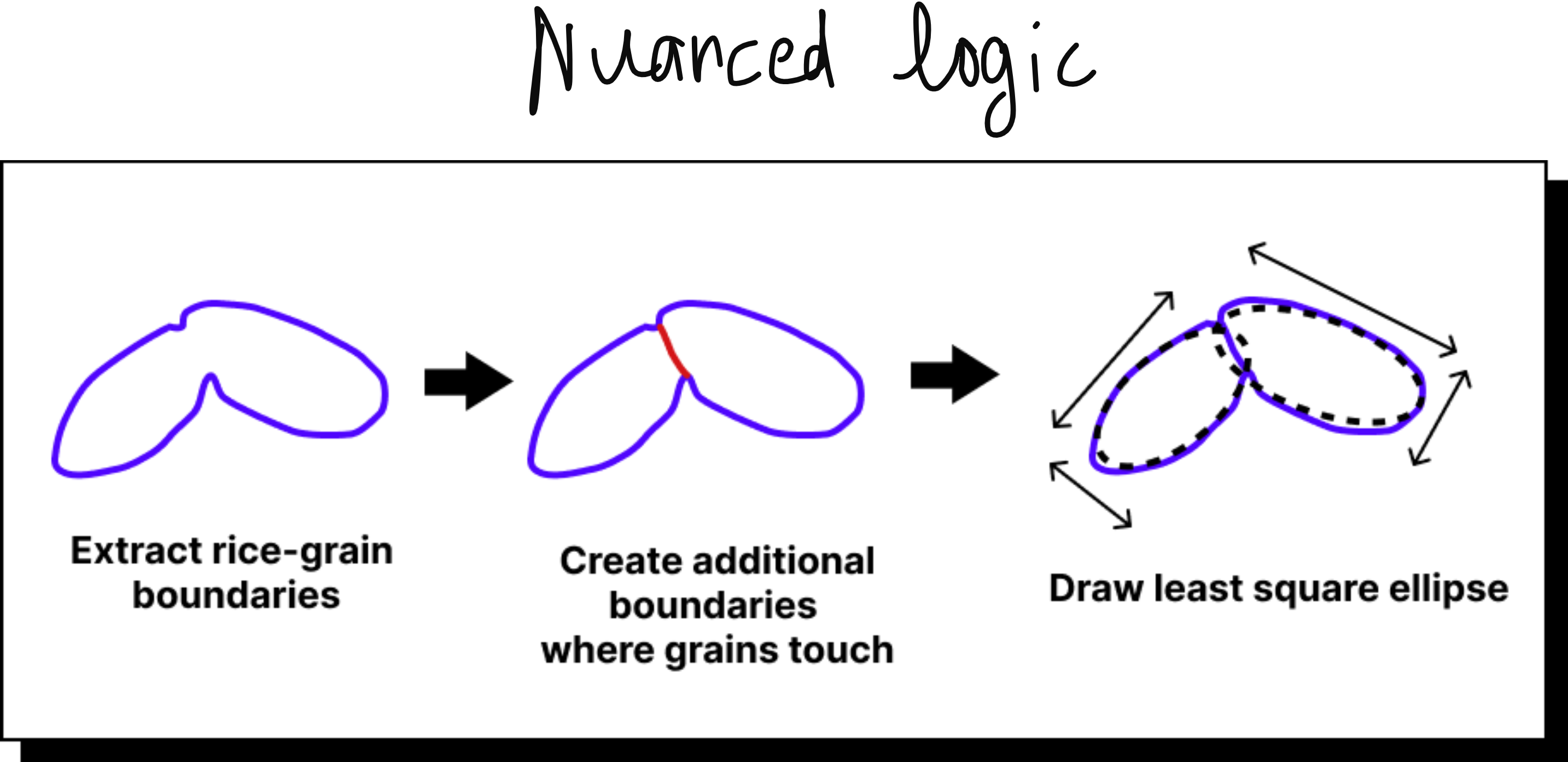
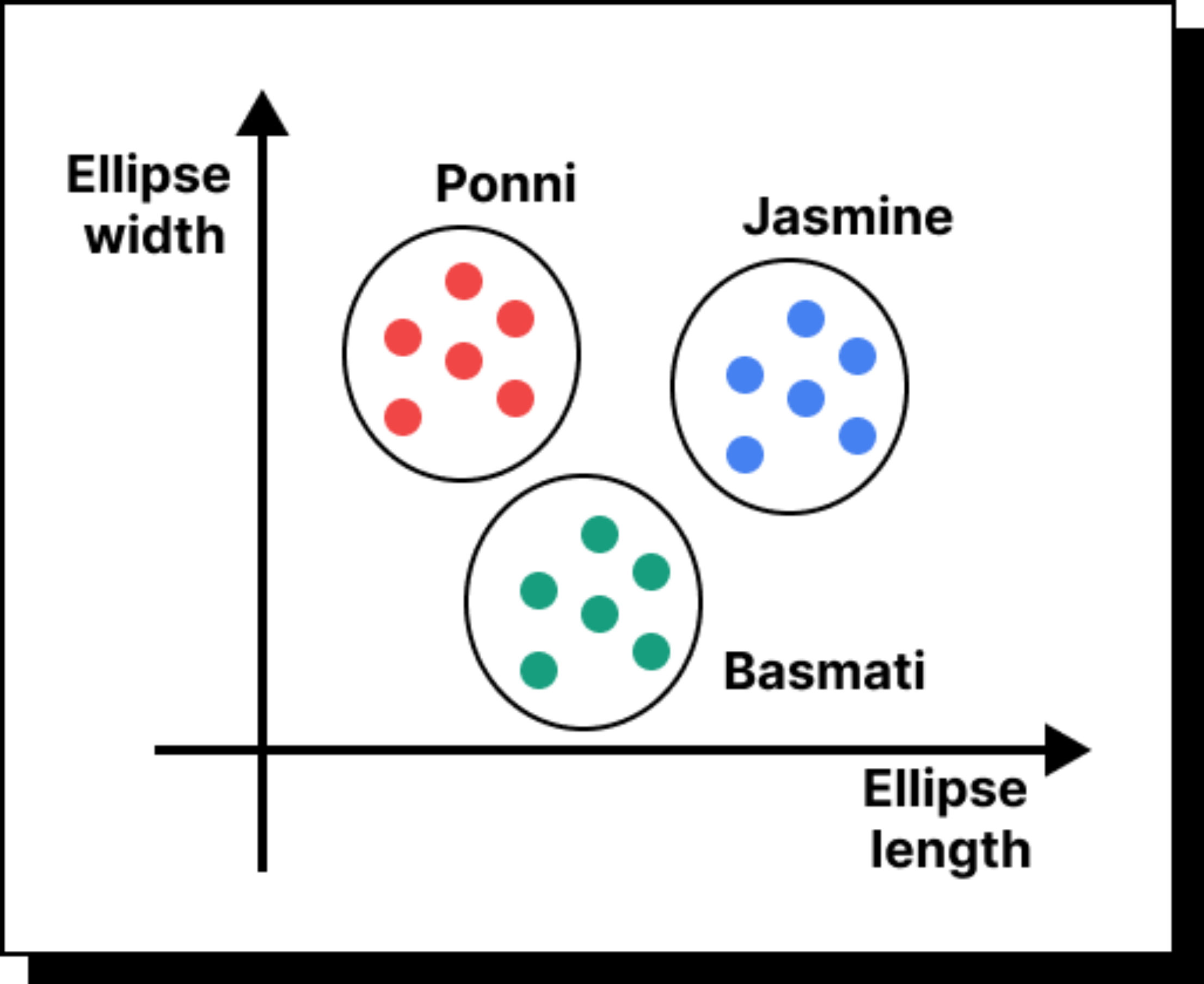
By the time I presented this work at the International Conference on Machine Vision (ICMV) in France, it was already clear that deep learning was overtaking rule-based systems. The release of AlexNet in 2012 had marked a turning point, and convolutional neural networks quickly became the dominant approach for vision tasks. That was when I realized the shift was irreversible.
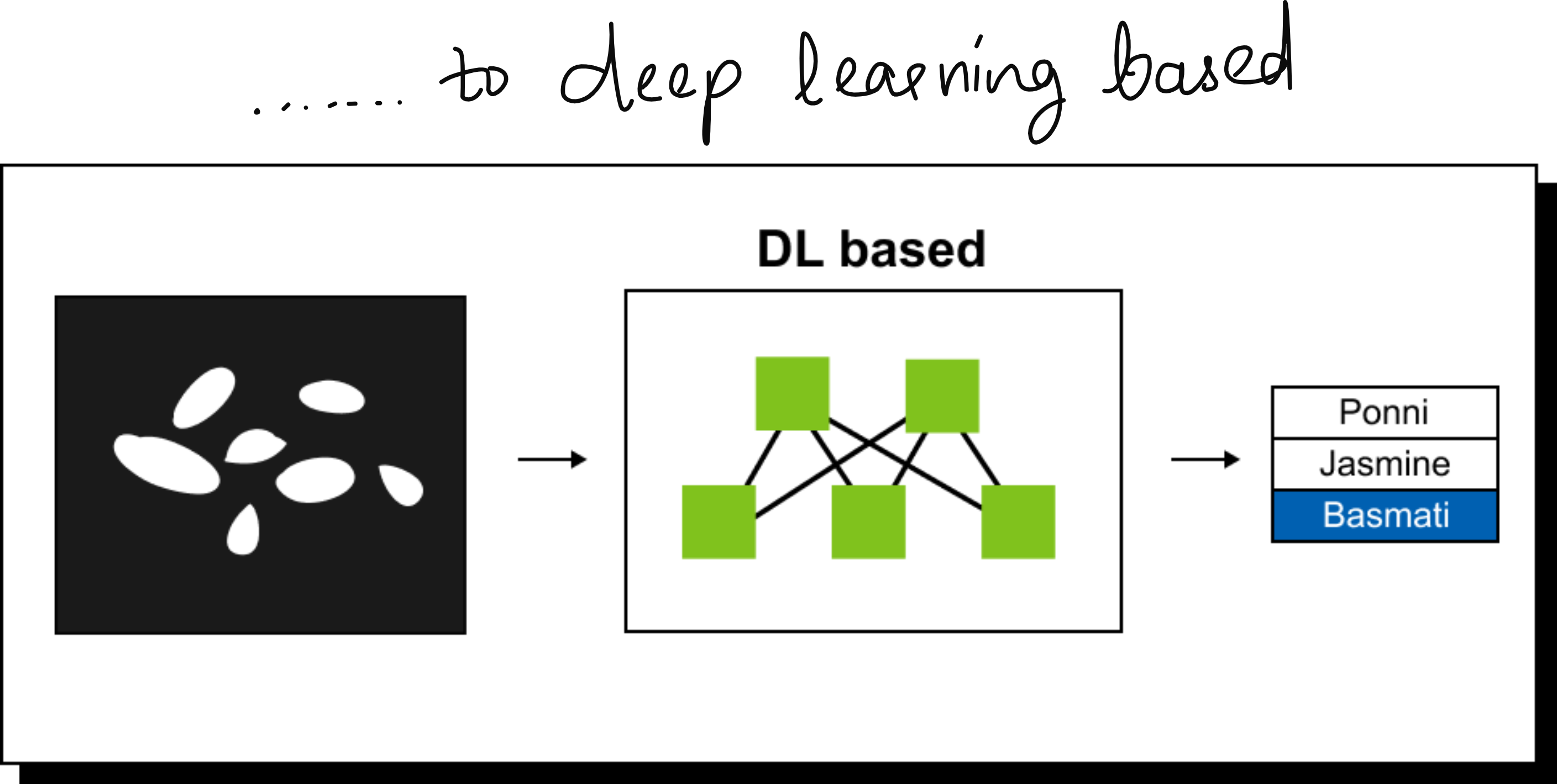
The 3 eras of Computer Vision
Looking back, we can see three broad eras in the evolution of computer vision.
Before 2012: Computer vision was built around handcrafted filters and classical machine learning models like support vector machines or k-means clustering.
2012 to 2020: Convolutional neural networks dominated, excelling in classification, detection, and segmentation tasks.
From 2020 onwards: Transformers have become the state of the art. The introduction of the vision transformer showed that attention-based architectures could outperform CNNs on many tasks, and since then the field has rapidly moved in this direction.
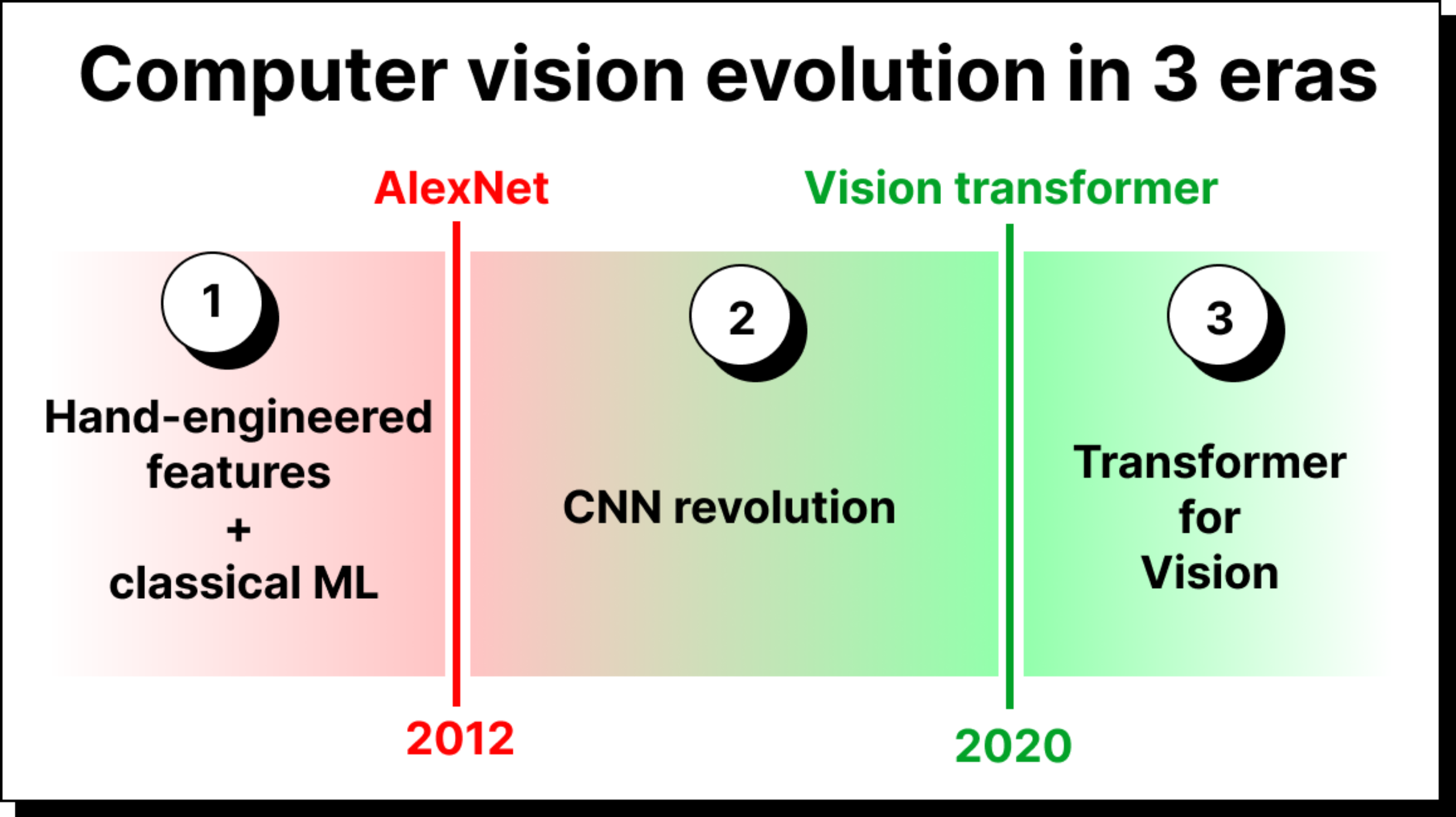
Despite this, CNNs are not obsolete. In certain applications, especially where efficiency is critical, CNNs continue to perform very well. The key is to understand where each method applies best.
Why transformers for vision?
CNNs rely heavily on local receptive fields. They capture spatial hierarchies but struggle with long-range dependencies. Transformers, built on self-attention, directly model relationships across the entire image. This gives them an advantage when global context is important.
Since the introduction of Attention Is All You Need in 2017, and the Vision Transformer paper in 2020, transformers have extended far beyond text. Today, nearly every frontier in computer vision research involves transformer-based models, from classification and segmentation to video understanding and multimodal reasoning.
Curriculum of the bootcamp
This bootcamp is organized into modules. It begins with a quick review of convolutional neural networks to explain their value and their limitations. From there, we move into the transformer architecture itself, learning about embeddings and attention mechanisms.
Subsequent modules cover:
Vision transformers and their variants such as Swin Transformer.
Transformers for detection and segmentation, including DETR, Mask2Former, and the Segment Anything Model.
Video transformers like TimeSformer and Video MAE.
Vision-language models such as CLIP, BLIP, and Flamingo.
Multimodal large language models that combine text, vision, and other modalities.
Generative models for vision, with a focus on Stable Diffusion.
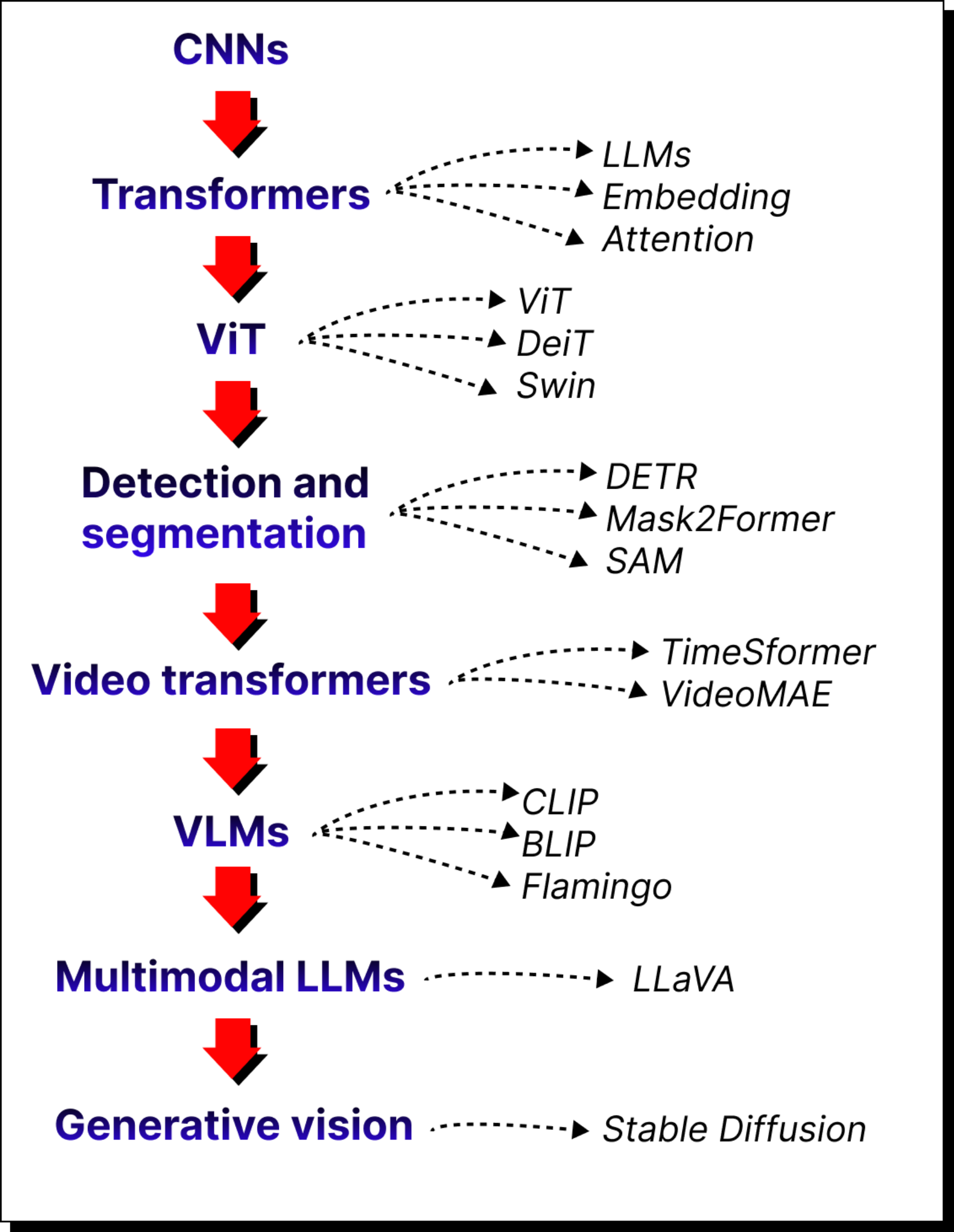
By the end, you will have an end-to-end understanding of how transformers are applied to vision and multimodal tasks, along with hands-on coding practice.
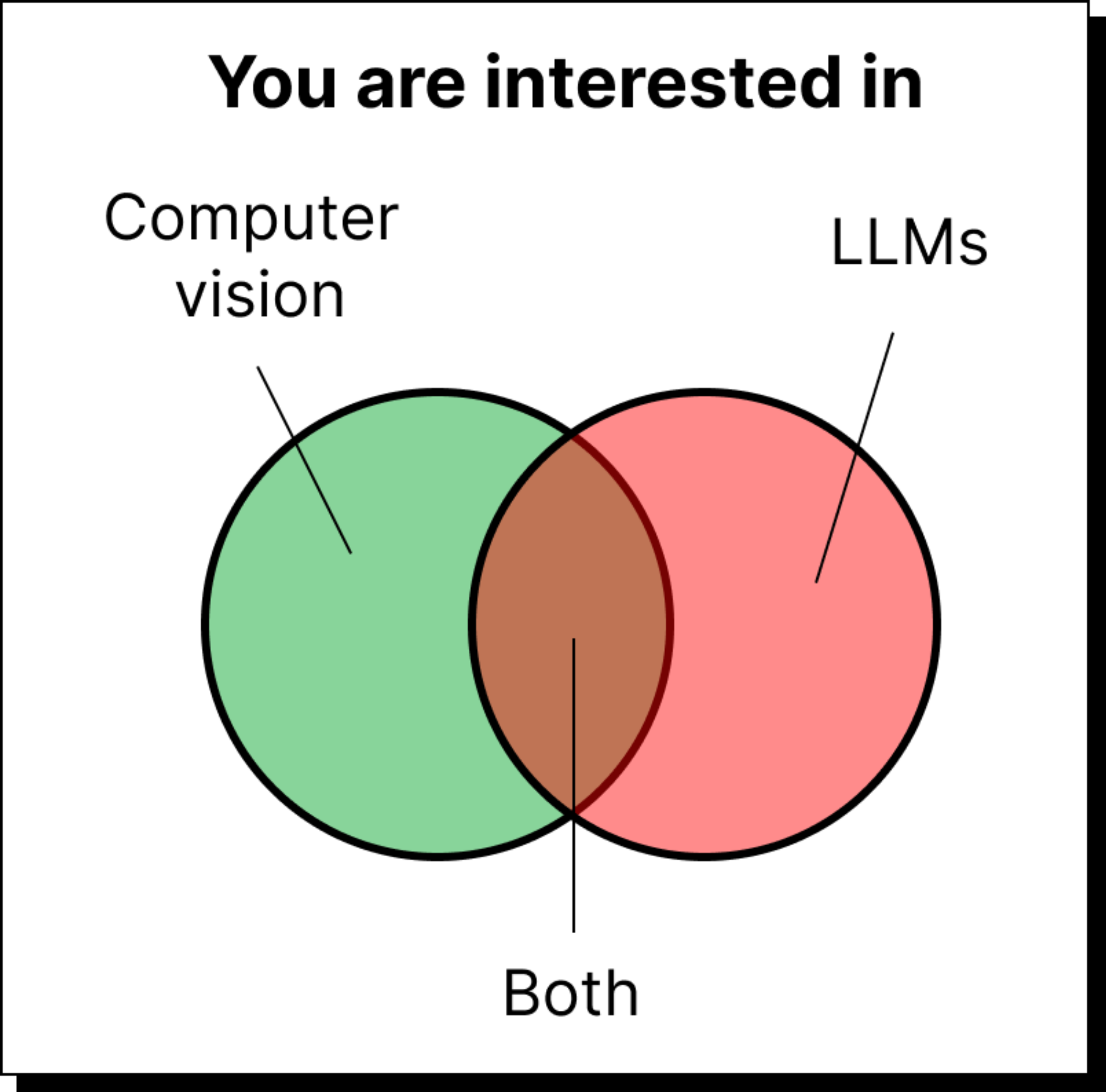
Who is this meant for?
You can be in any of the buckets show below. If so, this bootcamp is perfectly suited for you.
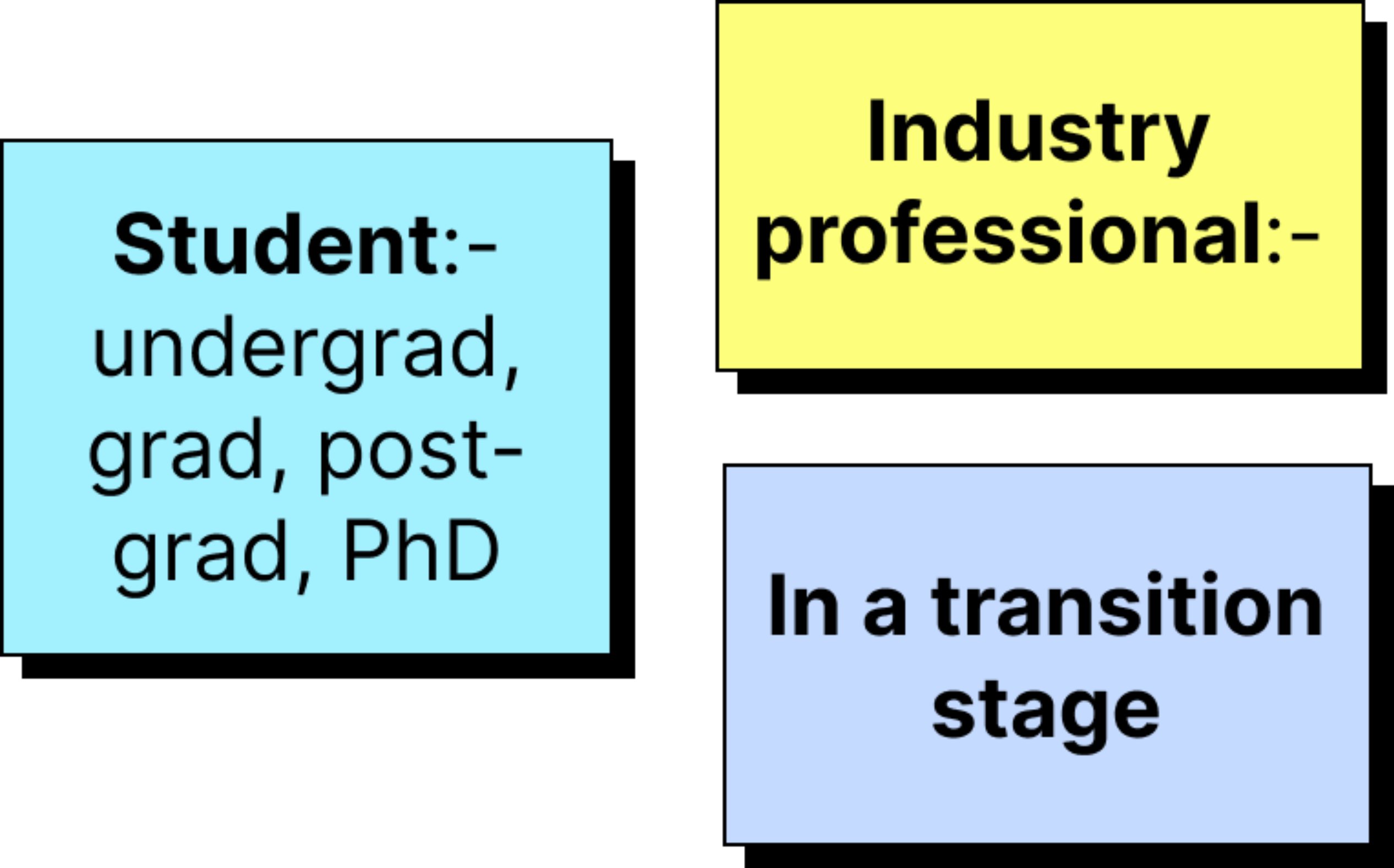
Real-world applications
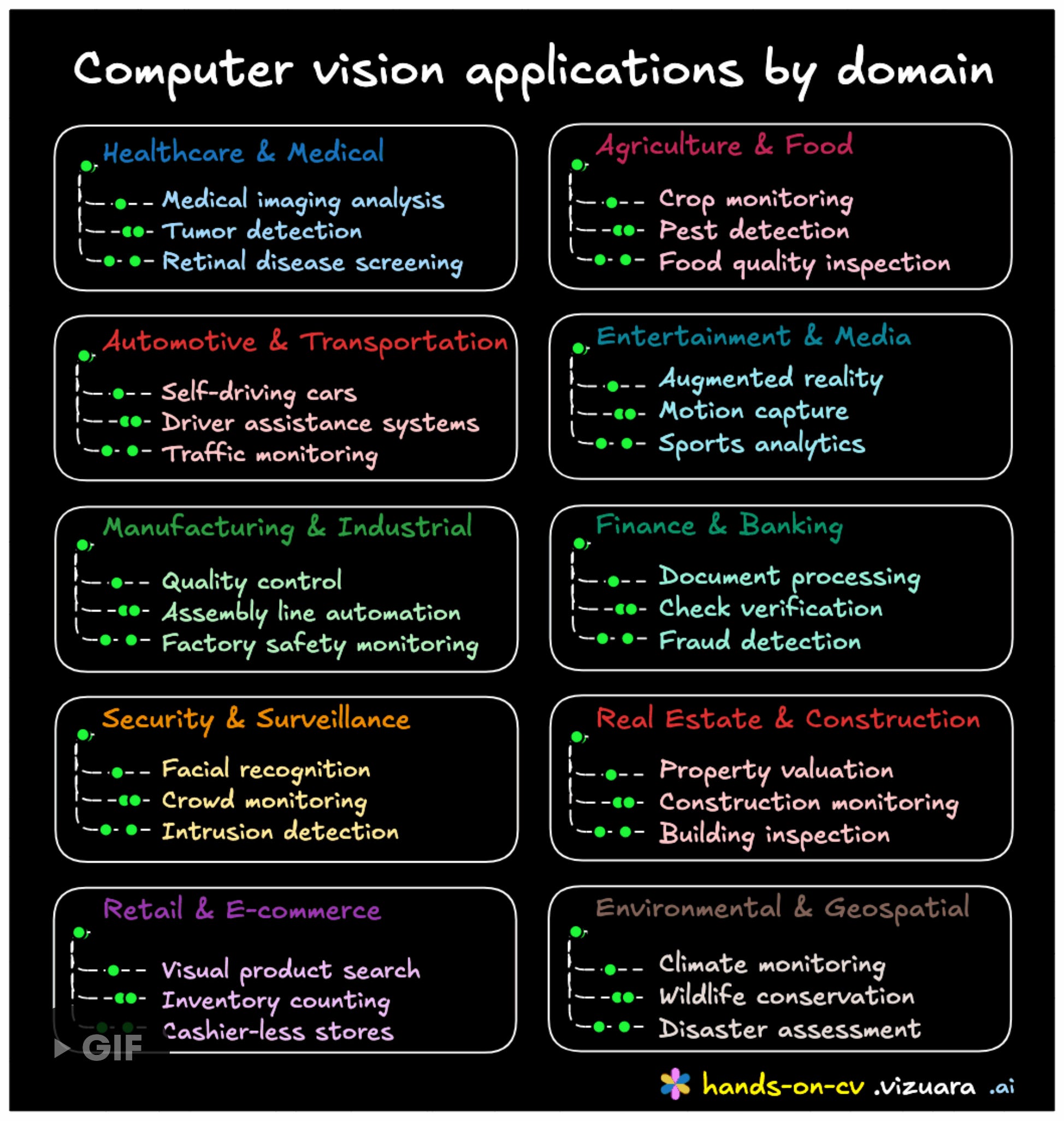
Computer vision is not just about consumer-facing applications like face recognition or self-driving cars. Much of its impact happens behind the scenes:
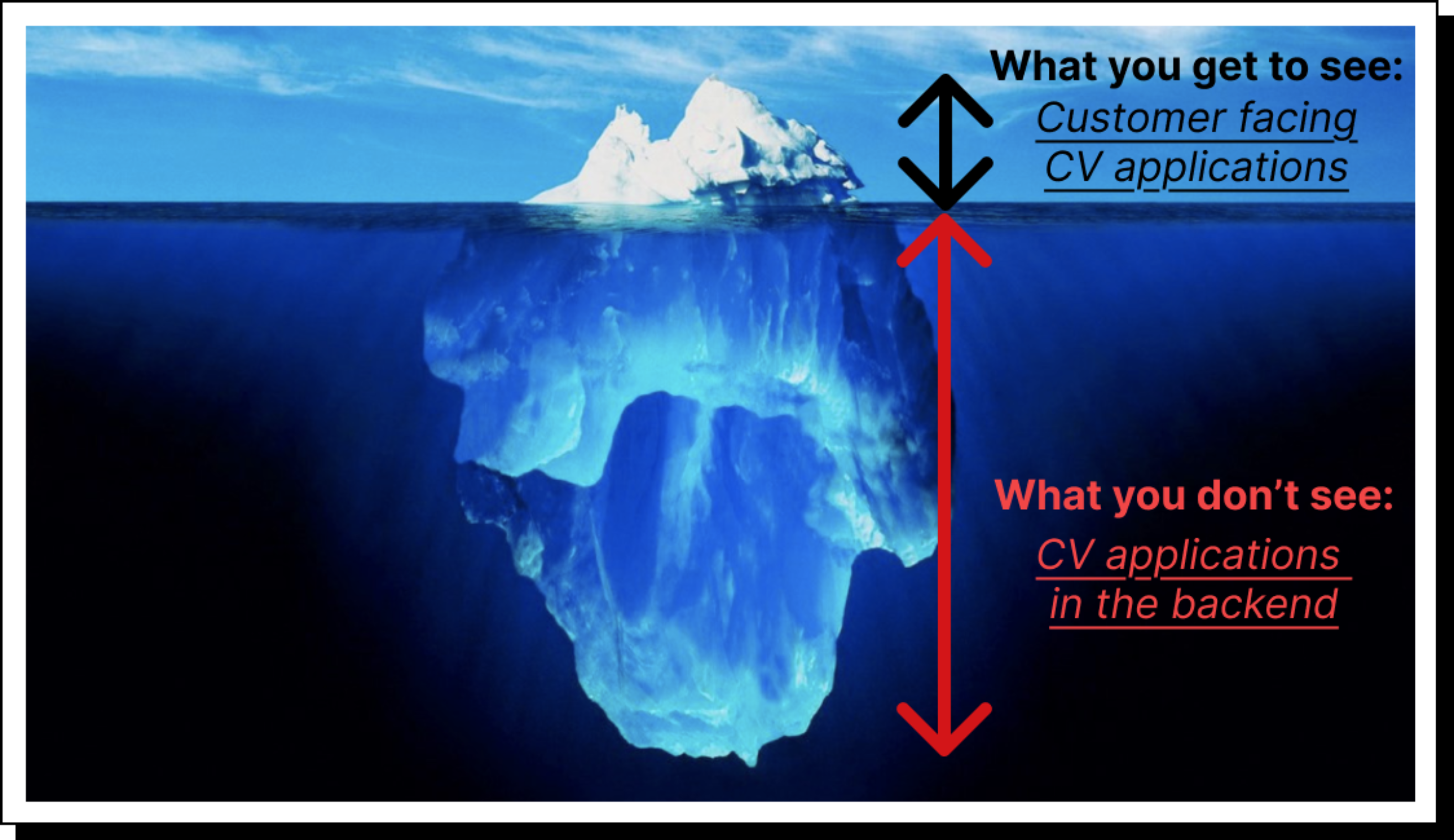
Warehousing and logistics: Robots in Amazon warehouses rely heavily on vision.
Agriculture: Farmers use computer vision to monitor pesticide spraying and crop health.
Banking: Mobile check deposits depend on vision algorithms for verification.
Climate and environment: Satellite and drone imagery help track deforestation, poaching, and climate change.
Manufacturing: Vision ensures safety compliance on factory floors.
Sports analytics: Pose detection in gameplay footage provides insights to coaches.
With transformers, many of these applications are moving toward multimodal AI, where vision interacts seamlessly with text, audio, and other modalities.
Prerequisites and learning approach
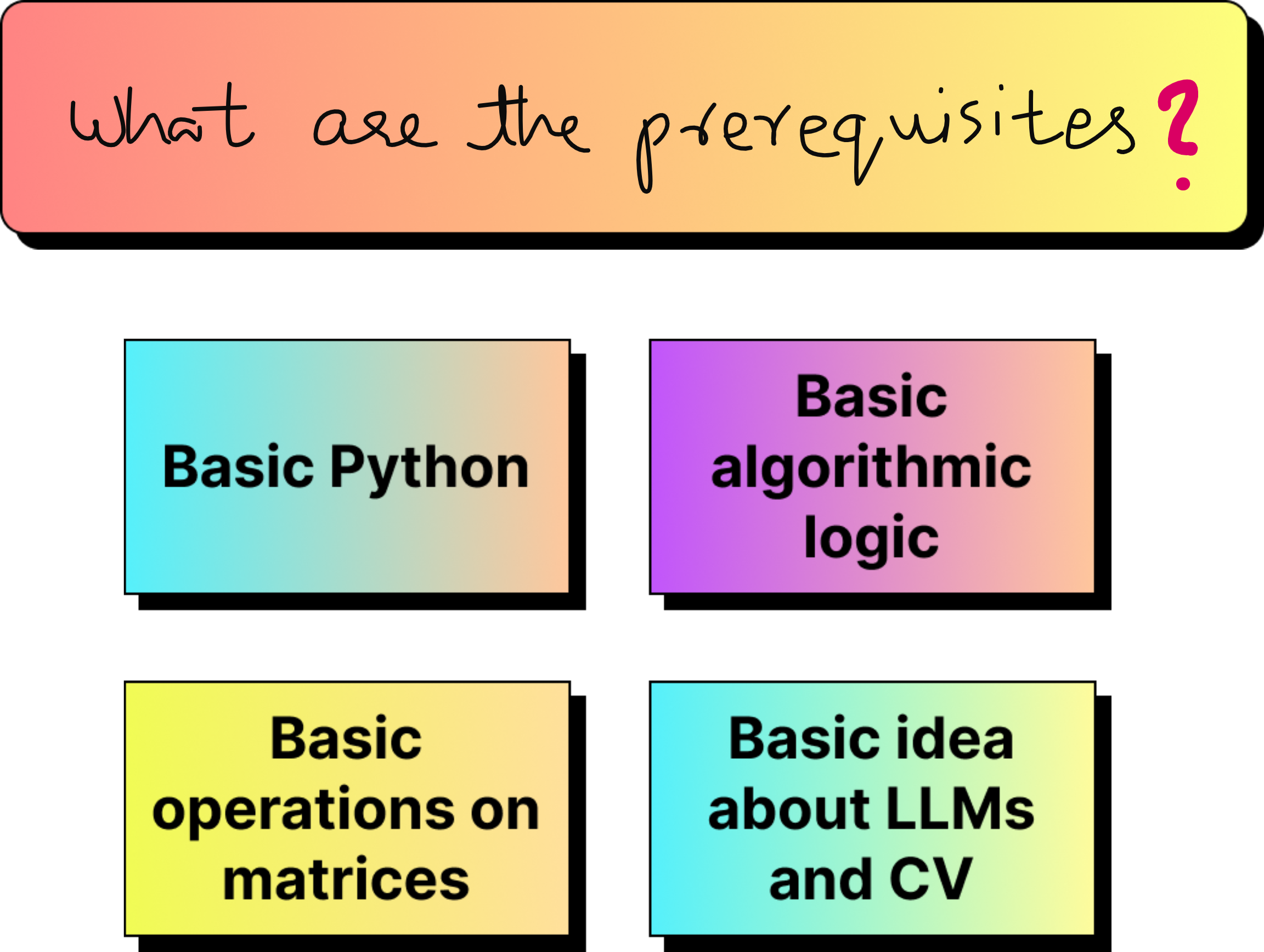
This bootcamp is intended to be beginner friendly. The prerequisites are minimal: basic knowledge of Python, some exposure to PyTorch or TensorFlow, and a basic understanding of linear algebra operations like matrix multiplication. If you are new to these, you will need to put in some extra effort in the beginning, but you will be able to follow along.
The lectures are long-format, typically between 30 and 90 minutes, much like a university class. I encourage you to code along with me, pause the videos when needed, and re-watch challenging sections. Some concepts, such as attention mechanisms, will require multiple passes to fully absorb.
There are two versions of the course. The free version is available on YouTube in a dedicated playlist. The Pro version, available through Vizuara’s website, includes additional resources such as detailed notes, code repositories, a Discord community, hands-on assignments, and certification opportunities.
The bigger picture
Most people are familiar with visible computer vision applications such as facial recognition or self-driving cars. However, many of the most impactful uses happen behind the scenes. Logistics companies rely on vision for warehouse automation. Agriculture firms use it to monitor pesticide spraying. Banks use it for check verification. Climate scientists use it to monitor forests and wildlife through satellite imagery.
Transformers are pushing the boundaries further, enabling multimodal systems that can connect vision, text, and even audio into a single reasoning framework.
Closing thoughts
It is easy to begin a course with enthusiasm but much harder to sustain it through to the end. My request to you is simple: stay consistent, practice coding, take notes, and revisit difficult concepts. If you commit to this bootcamp, by the end you will not only understand transformers for vision but also gain the ability to apply them to real-world problems.
This is an exciting time to be part of computer vision and artificial intelligence. I look forward to guiding you through this journey.
Lecture video
PRO content: What will you get ?
