
Transfer Learning
Do not train your neural network from scratch like a rookie


Let us face it.
Most of us, at some point, have tried to train a deep neural network from scratch on a small dataset and then stared in confusion when it refused to perform better than a coin toss.
We go through the whole drill - linear layers, ReLU activations, dropout, batch normalization, early stopping. We squint at the loss curves, adjust the learning rate, and pray to the gods of stochastic gradient descent. Still, accuracy stubbornly refuses to cross 60 percent.
At this point, it is natural to feel betrayed by the hype around deep learning. And that is exactly why you need to stop building everything from scratch and embrace transfer learning - deep learning’s version of copy-paste, but intelligent.
This article is your practical, grounded, slightly sarcastic introduction to how transfer learning can make your models smarter without making you suffer.
Why training from scratch feels like being Stuck in traffic
In our computer vision course, we had a simple goal: build a classifier for a dataset with five flower types - daisy, dandelion, rose, sunflower, and tulip.
Just five classes. Seems manageable, right?
Except the dataset was not ImageNet. It was more like ImageNet’s distant, underfunded cousin - just a few thousand images, unevenly distributed, with no guarantee of clean annotations.
So we tried:
A linear model with no hidden layers: got around 30-40 percent accuracy.
A hidden layer with 128 neurons and ReLU: marginal gain in accuracy, significant drop in cross-entropy loss.
Regularization (L2), dropout, batch norm, early stopping: accuracy crawled up to 50-55 percent. Yay.
But that was the ceiling. No matter what we did, the model plateaued. It was like trying to fill a swimming pool using a coffee mug.


Why? Because deep learning needs data. A lot of it. And we did not have it.
The sanity check: Why transfer learning exists
Enter transfer learning - the idea that someone else has already done the hard work of learning from large datasets, and you can reuse that knowledge.


It is like hiring an experienced employee instead of training a fresh graduate from scratch. The experienced person has already seen hundreds of cases. They know where to look, what to ignore, and how to get results faster.


In computer vision, the experienced employee is usually a neural network trained on ImageNet - a massive dataset of over 14 million images spread across 20,000 categories. The networks trained on it have learned to recognize edges, textures, object parts, and overall shapes.
What you can do is:
Take this pre-trained model (say, MobileNetV2),
Chop off its head (the classification layer),
Add your own head (your flower classification layer), and
Train only this new part while keeping the rest frozen.
This is fixed feature extraction. You freeze the base model and use it to extract features. Then train your custom classifier on top.

What is transfer learning?
Transfer learning means taking a model trained on one task (e.g., classifying 1000 ImageNet classes) and reusing it for a new task (e.g., classifying 5 types of flowers).
Types of Transfer Learning:
Fixed feature extractor: Freeze the pretrained model and use it just to extract features.
Fine-tuning: Unfreeze a few top layers and retrain slightly for better adaptation.
What are pre-trained embeddings?
Embeddings are feature representations learned by a model.

A pretrained model is a neural network that has already learned to extract features like:
Edges
Textures
Shapes
Object parts
Full objects

Analogy:
Learning the alphabet and vocabulary from scratch vs using an already educated dictionary.


Transfer learning without fine-tuning: Freezing the pre-trained embeddings






Fine-tuning: When you give your employee a promotion
But sometimes, the base model is not perfectly aligned with your task. Maybe your flowers look different from ImageNet flowers. Maybe your data has slightly different statistics.
In that case, you need to fine-tune the base model. That means unfreezing a few top layers and letting them adjust slightly to your new dataset.
It is like giving your experienced employee some onboarding training - they are not learning everything from scratch, but you are letting them adapt to your company.
When we did this, validation accuracy shot up to 87 percent. Training accuracy hit 100 percent. We were ecstatic, even though part of us knew we might be overfitting a little. Still, much better than the scratch-built model stuck at 50 percent.





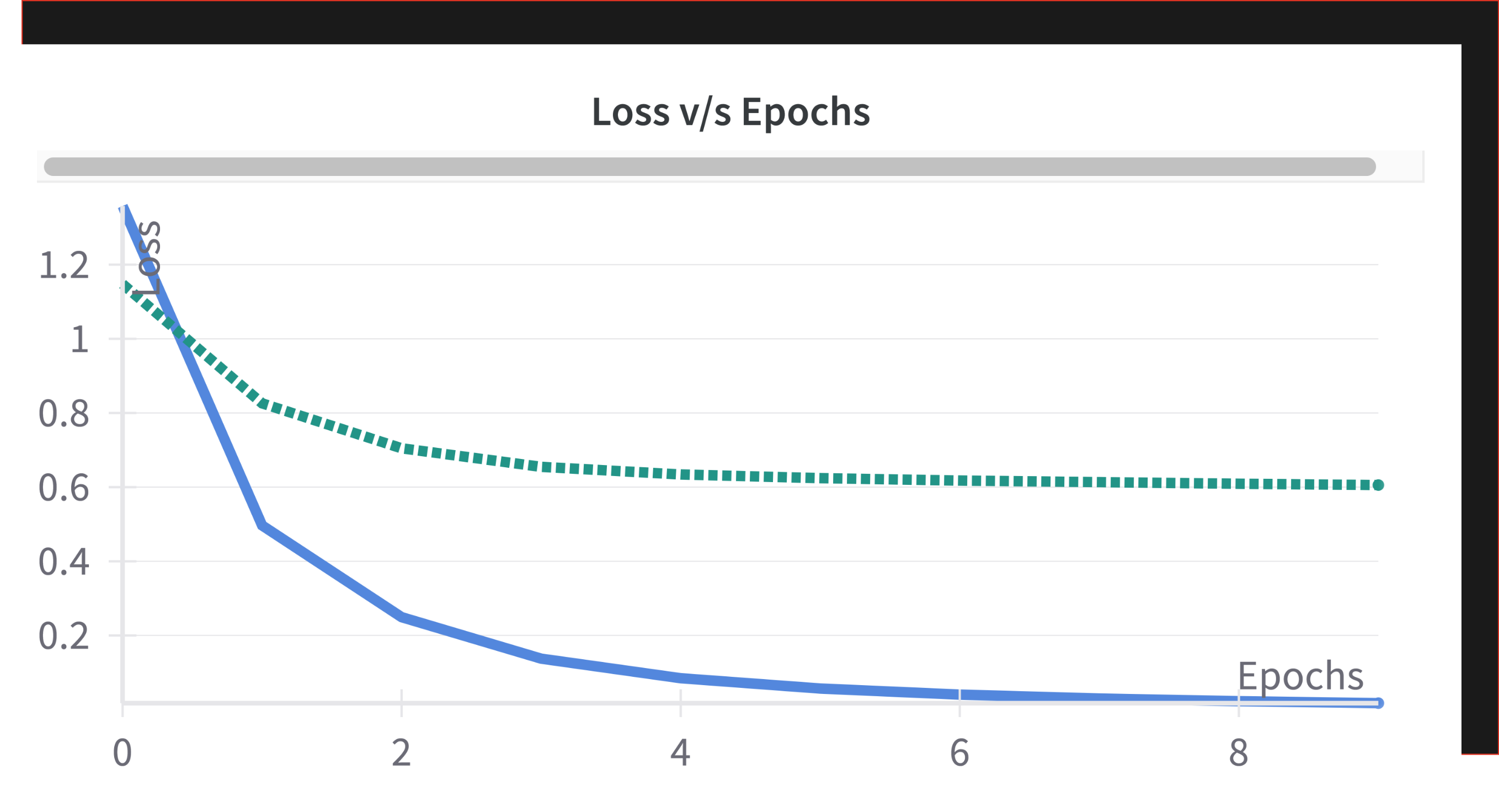
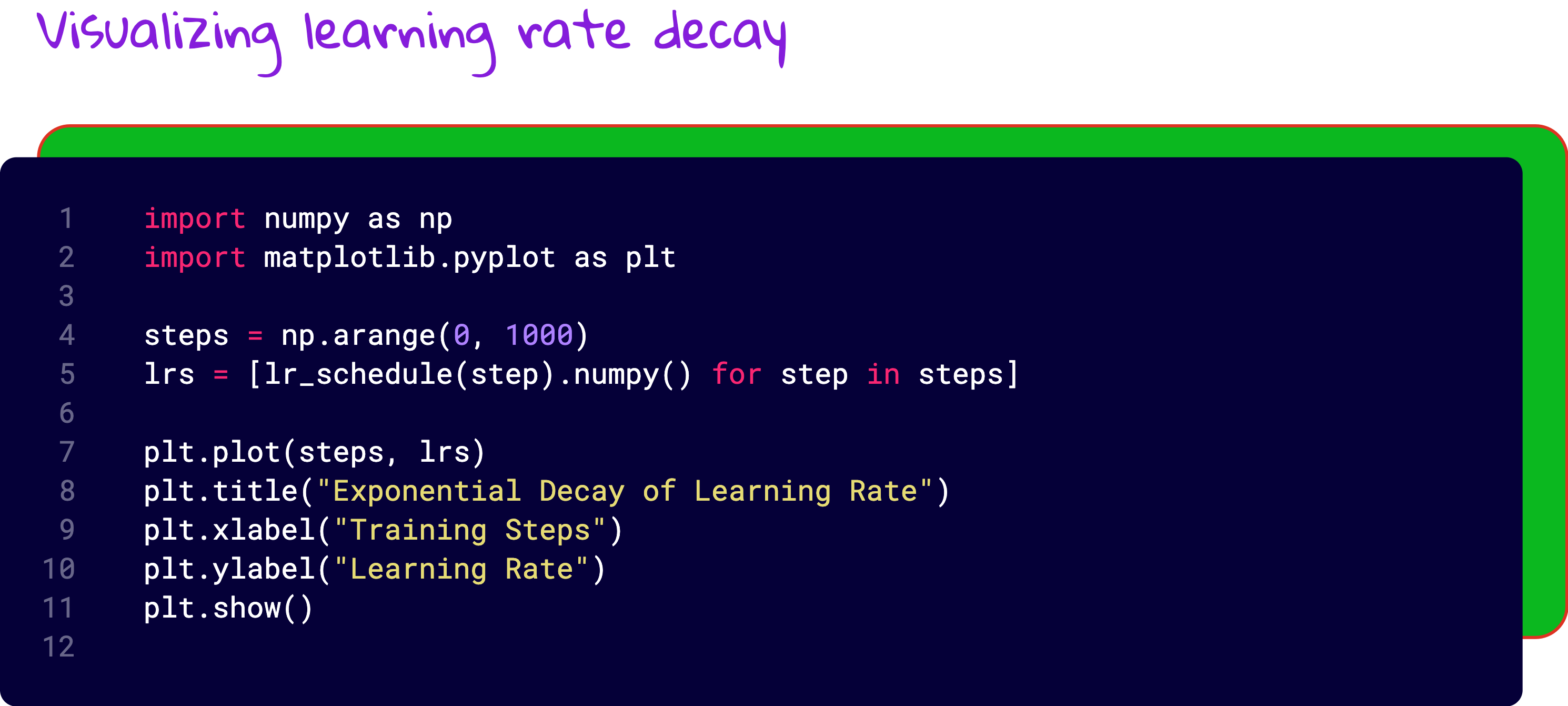
Learning rate schedules: Because brains learn fast, then slow
Once you start fine-tuning, another question emerges: should the learning rate stay constant?
No.
Early on, you want your model to learn fast. Later, you want it to settle down and refine what it has learned.
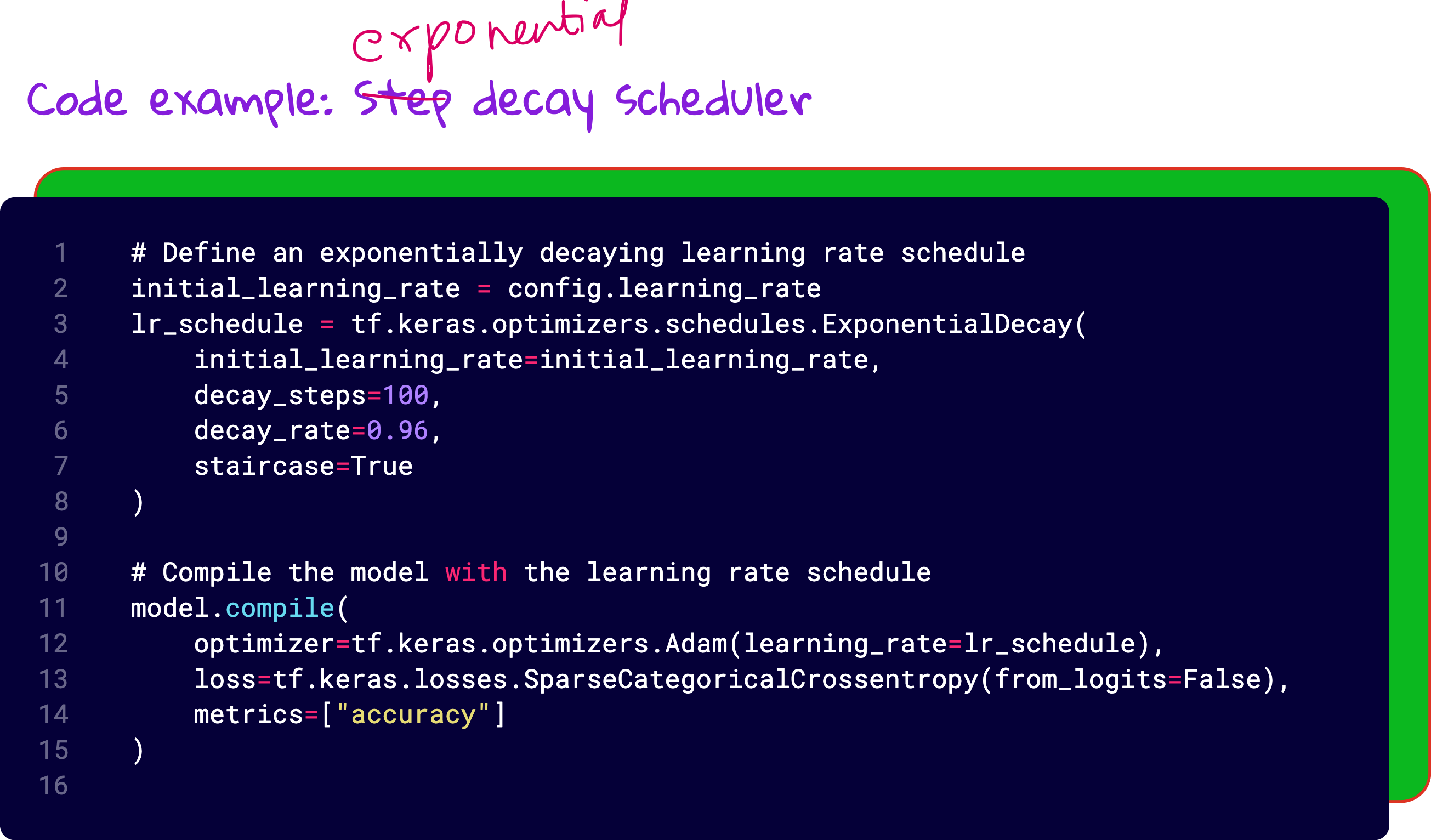
We tried exponential decay, where the learning rate keeps dropping by a fixed percentage every few epochs. Just like how people get less impulsive with age, your model becomes more conservative with updates as training progresses.
And it worked. The loss dropped below 0.5, validation accuracy reached 87 percent, and training felt smoother than ever.


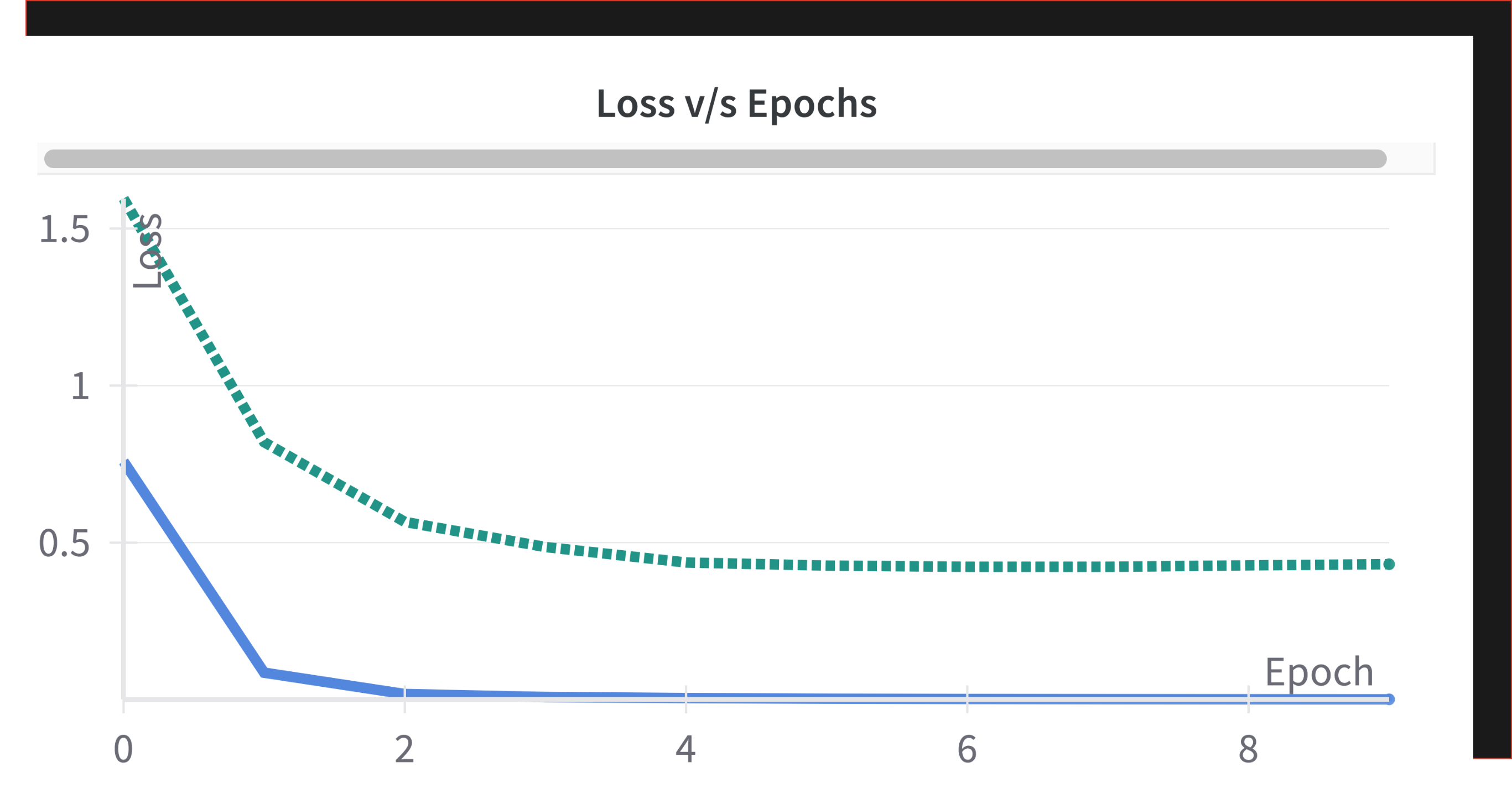
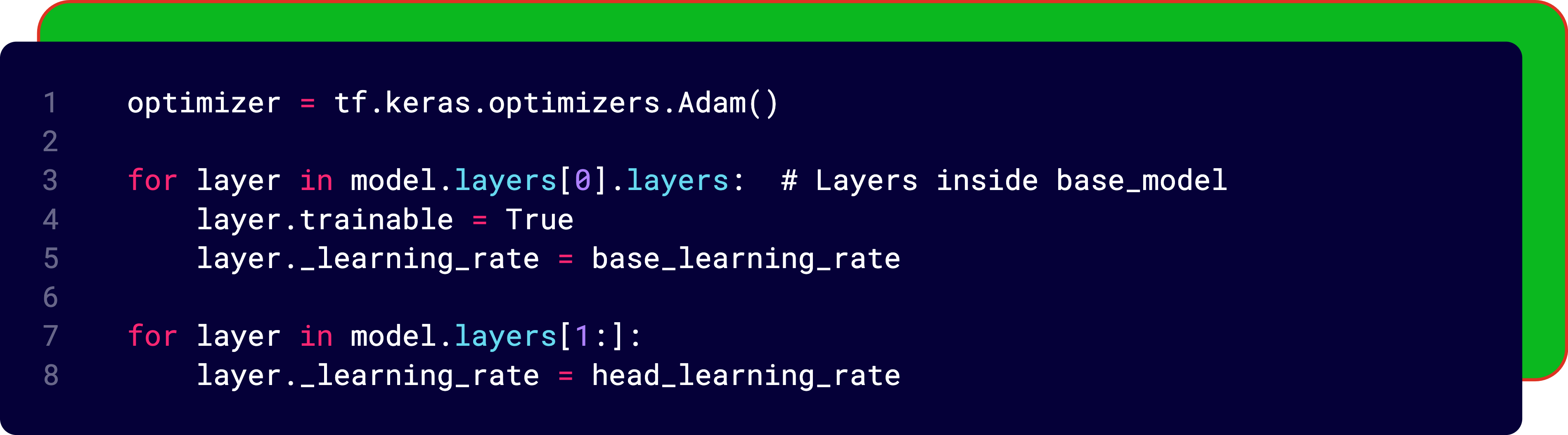
Differential learning rates: Because your head learns faster than your backbone
Then came the final tweak: using different learning rates for different parts of the model.
The base model already knows a lot - we want it to learn slowly (small learning rate). The newly added classifier is dumb - it needs to learn fast (bigger learning rate).
This is called differential learning rates.
While the results were not drastically better out of the gate (validation accuracy hovered around 65-70 percent), it made intuitive sense. And with proper tuning, we know this can work wonders.



So what did we learn?
Do not train from scratch unless you have to. Life is too short to waste on 50 percent accuracy.
Transfer learning is your best friend when data is limited and time is tight.
Feature extraction is great for small datasets. Just plug-and-play.
Fine-tuning is useful when your dataset is medium-sized and slightly different.
Use smart learning rate strategies. Decay over time. Split learning rates between layers.
Always monitor validation loss and accuracy. Do not be fooled by 100 percent training accuracy. That is often a trap.
Final thoughts
Transfer learning is not just a trick. It is a philosophy. It is a reminder that in deep learning, as in life, you do not have to start from zero. You can build on the work of those who came before you.
We are now entering the part of our course where models work well, graphs look clean, and experiments give us joy. But this joy is earned. We tried, failed, tuned, regularized, and finally saw the light.
If you have been following the series this far, you have done something remarkable. You went from naïve networks to pre-trained powerhouses. And the best is yet to come.
Keep learning. Keep building.
And remember, if your model is stuck at 45 percent, it might just be screaming:
“Please give me some transfer learning.”
YouTube lecture - full video
Interested in learning ML foundations?
Check out this link: http://vizuara.ai/self-paced-courses
Code files
1) Transfer learning without fine-tuning: https://colab.research.google.com/drive/1cn3FaWKGlxvogX-98PTaOodjoDQ6cfCr?usp=sharing
2) Transfer learning with fine-tuning: https://colab.research.google.com/drive/1-IR2YTu2hVACZ-stMgtg6jQmDQFMlHlb?usp=sharing
3) Transfer learning with fine-tuning + learning rate rescheduling: https://colab.research.google.com/drive/1kjzc6kBjOBasJntjUQTJIto0HjPcDME_?usp=sharing
4) Transfer learning with fine-tuning + differential learning rate: https://colab.research.google.com/drive/1QTbyfi9YnV1cjYHcUtbIQt2ymtCBBuya?usp=sharing