
The Story of SqueezeNet: Why Smaller Can Be Smarter
The Deep Learning arms race between 2012-2016


Between 2012 and 2016, deep learning was having its big bang moment. In just four years, we witnessed AlexNet, VGG, Inception (aka GoogleNet), and finally, a model that asked a radical question:
What if we did not need 100+ million parameters to get state-of-the-art accuracy?
That model was SqueezeNet.
In this lecture from the Computer Vision from Scratch course, we explored how SqueezeNet came into existence, why it matters, and how it performed on our classic five-flowers dataset.
Here is the story behind the architecture that proved small models can punch way above their size.
The Deep Learning arms race
Post-AlexNet, the research community got obsessed with one thing - depth. More layers, more parameters, more compute.
AlexNet (2012) had around 60 million parameters. It changed the game by using ReLU, dropout, and GPU-based training.
VGG16 (2014) doubled down with 138 million parameters and a purist architecture: only 3x3 convolutions stacked deeply.
Inception V1 (2014) went a different route — instead of going deeper, it went wider, with parallel 1x1, 3x3, and 5x5 convolutions capturing features at multiple scales. It won the ImageNet challenge that year.

But with great size came a huge problem - you cannot deploy these beasts on phones or IoT devices. So in 2016, a group of researchers asked a different question:
Can we get AlexNet-level accuracy with 50x fewer parameters and less than 0.5 MB model size?
That paper was titled SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. A bold claim. But it delivered.

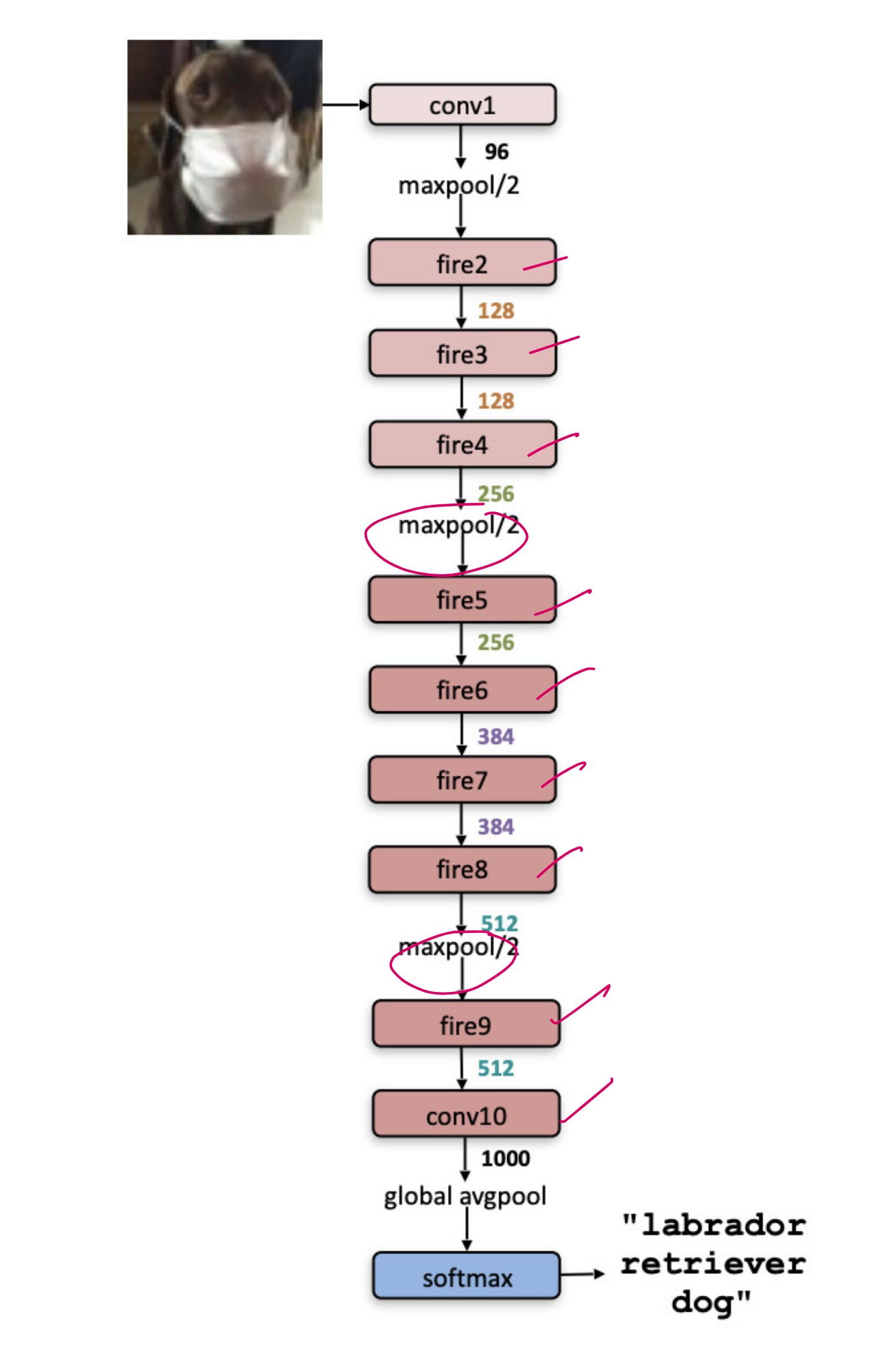
The architecture: What is a Fire Module?
If Inception used multi-scale parallelism, SqueezeNet introduced squeeze-and-expand via a component called the Fire Module.

Here is the idea:
Use a 1x1 convolution to squeeze the input channels.
Then expand them using a mix of 1x1 and 3x3 convolutions in parallel.
Concatenate the outputs.
Repeat this architecture in series across the network.

This seemingly simple structure leads to dramatic parameter reduction without killing the accuracy.
Let us get a bit more concrete.
If you were to apply a 3x3 convolution over 256 input channels, you would use 2,304 parameters.
Now, if you first squeeze it to 16 channels using a 1x1 convolution (256 weights), then apply a 3x3 over just those 16 channels (144 weights), the total is 400 parameters - an 80 percent reduction.
Multiply this saving over an entire network, and you get why SqueezeNet has only 1.2 million parameters in total.
Okay, but does it work?
On our five-flowers dataset (daisy, rose, tulip, sunflower, dandelion), we tested AlexNet, VGG, Inception, and now SqueezeNet using transfer learning.
Let us look at the numbers:

Yes - SqueezeNet outperformed every other model in both training and validation accuracy, while being the smallest and fastest to train.
Sure, we used 50 epochs here vs. 10 epochs for AlexNet. But even accounting for that, the efficiency is too impressive to ignore.


Lessons from SqueezeNet
Parameter count is not everything. Smart architecture design can reduce weights without hurting accuracy.
1x1 convolutions are powerful. They help reduce dimensionality and bring in non-linearity at low computational cost.
Multi-scale + channel squeeze is a powerful combo. Inception and SqueezeNet both use it, albeit differently.
Edge deployment needs more SqueezeNets, not more VGGs.
And maybe the biggest insight - brute force is not innovation. VGG showed us that going deeper is easy. SqueezeNet showed us that being smarter is harder - and far more rewarding.

SqueezeNet entire architecture
Code [relevant parts]
You can find the full code Colab notebook link at the bottom of this article.


Results [for 5-flowers dataset]


Final Thought
The magic of deep learning has always been in its ability to scale. But the future will not be won by the biggest models. It will be won by the most efficient ones.
SqueezeNet proved that. And as you will see in future lectures - with MobileNet, EfficientNet, and TinyML - this philosophy is just getting started.
If you are still stuck training 100M+ parameter models for tasks solvable by much smaller nets - maybe it is time to squeeze a little.
Learn more
Lecture Video:
Colab Notebook: https://colab.research.google.com/drive/11GERunnzlzqgN_5Fi2YpIr39gLNcul23?usp=sharing
Miro Notes: https://miro.com/app/board/uXjVIo0AJQY=/?share_link_id=855263573673
Interested in learning AI/ML LIVE from us?
Check this: https://vizuara.ai/live-ai-courses/