
The 4 layers of defense against overfitting
A 95 percent training accuracy means nothing if your model collapses on validation


Overfitting is one of those terms that gets thrown around in every ML course, but few actually understand its nuance. Most treat it as a checkbox problem - throw in a dropout layer, maybe reduce model complexity, and hope the validation accuracy improves.
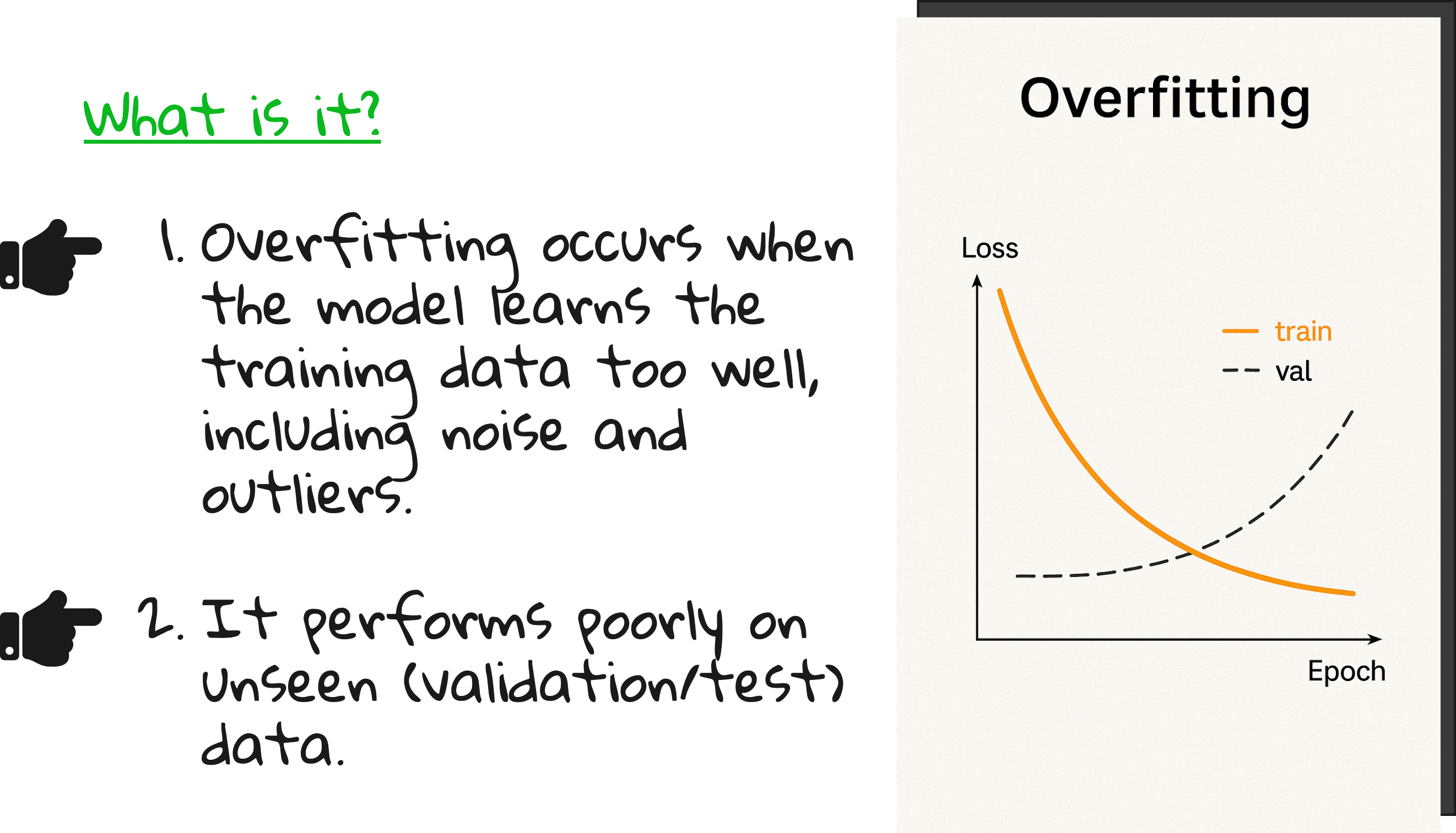
But what if I told you that overfitting is not just a technical issue? It is a reflection of how well you understand your data, your loss function, and the very structure of your model.
In this post, I will walk you through four battle-tested techniques to reduce overfitting in neural networks. This is not a surface-level overview. Each technique is broken down with code-level clarity, design decisions, and results from my own experiments on a 5-class flower classification problem.
By the end, you will know when and why to use regularization, dropout, early stopping, and batch normalization. Not just how.
The setup: A simple model, a complex problem
Our dataset consists of five flower categories - daisy, dandelion, rose, sunflower, and tulip. Each input is a color image.
We began with a baseline linear model. Flatten the RGB image, pass it through a dense layer to output five class probabilities using softmax. No convolution. No activation in hidden layers. The result?
Training Accuracy: ~40%
Validation Accuracy: ~35%
Adding a ReLU-activated hidden layer with 128 nodes improved the training loss, but validation accuracy remained stagnant. We increased the complexity, but not the generalization.
This is classic overfitting. And the solution is not just to make the model smaller. The solution is to make the model smarter.
The below image is another classic illustration of overfit, underfit and good fit.

Technique 1: Regularization - Penalize the excess
Regularization does not reduce error. It reduces confidence in weights that do not matter. In regularization we add a penalty term to the loss function that discourages large weights.
This is done because large weights make a model very sensitive to small changes in the input data, which often leads to overfitting.
There are two kinds:
L1 (Lasso): Adds absolute value of weights to the loss
L2 (Ridge): Adds squared value of weights

We used TensorFlow's tf.keras.regularizers.l1_l2(l1=0.0, l2=0.001) in our hidden layers.
Why it works:
When weights are large, the model becomes highly sensitive to small changes in input. This leads to brittle decision boundaries and poor generalization. Regularization prevents this by discouraging large weights, thereby smoothing the function.

Regularization implementation

Result:
Validation accuracy improved to 0.5+, with significantly reduced divergence from training accuracy.


Technique 2: Dropout - deliberate imperfection
Dropout is brutally simple. During training, it randomly deactivates a percentage of neurons in a layer. In our case, we used a 0.5 dropout rate on the hidden layer.
Each forward pass sees a slightly different network architecture. This forces the model to learn redundant, general patterns instead of relying on individual neurons.

Key Insight:
Dropout does not help during inference. It helps while learning. During inference, the full network is used, but outputs are scaled to reflect the absence of units during training.

Dropout implementation

Result:
Validation accuracy improved, and more importantly, stayed consistent across epochs. The gap between training and validation accuracy narrowed significantly.
Technique 3: Early stopping - know when to quit
A model that trains forever is not better. It is just memorizing.
We added EarlyStopping with a patience of 3 epochs - if the validation loss did not improve for 3 consecutive epochs, training was stopped.
Why it works:
Most overfitting happens late in training. Early stopping ensures that once the model starts to over-specialize on the training data, we cut it off.
Result:
While accuracy improvement was not dramatic, the consistency in validation performance across runs was noticeable. It is a safety net. You do not always need it, but when you do, it saves your experiment.
Early stopping implementation

Technique 4: Batch Normalization - Statistical Stability
Batch normalization normalizes the inputs to a layer such that the mean is close to zero and the variance is close to one - per batch.
It is not just about faster convergence. It reduces internal covariate shift, makes the model less sensitive to initialization, and can even act as a form of regularization.
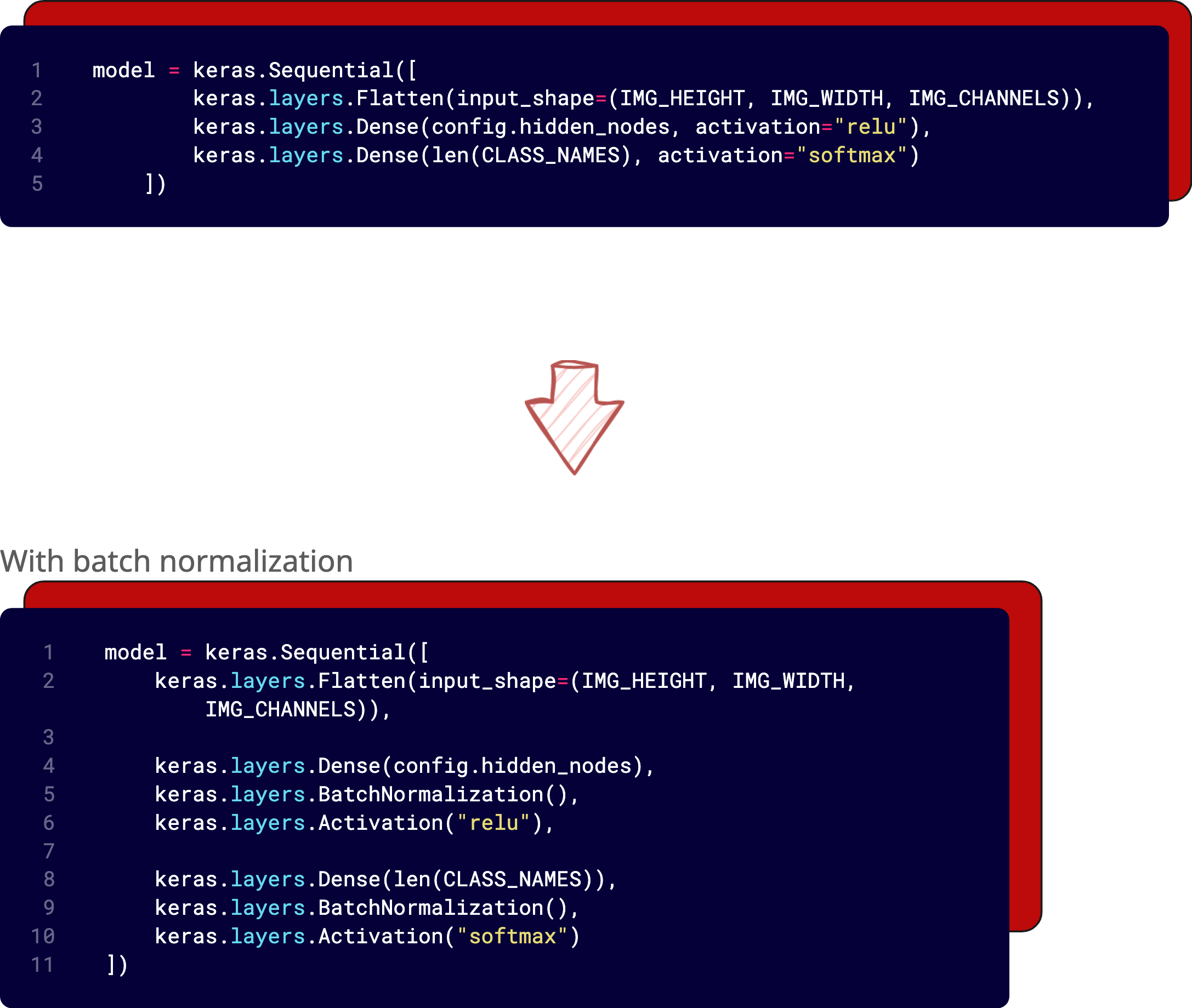
We used batch normalization just before ReLU in our hidden layer and before softmax in the output layer.

Batch normalization implementation
Result:
This was the most effective technique. Training accuracy jumped to 0.8, the highest we achieved on this dataset without CNNs or transfer learning. Validation accuracy held firm at 0.5+, showing no early signs of overfitting.

Putting it all together: The full stack anti-overfitting model
Finally, we built a model with all four techniques:
L2 regularization
Dropout (0.5)
Batch normalization
Early stopping

Result:
The model performed better in terms of training accuracy and showed the most stable validation accuracy across epochs. There was no steep drop-off. No sudden plateau. Just steady, confident learning.

The real takeaway
Everyone wants a magic bullet for overfitting. Most are looking in the wrong direction.
Regularization, dropout, early stopping, and batch normalization are not silver bullets. They are systems. Together, they create a model that is harder to overfit, easier to train, and more likely to generalize.
This is not the end of the road. We are still working with flattened RGB inputs. No convolutions. No pre-trained networks. In the next few lectures, we will step into the world of CNNs and transfer learning.
But remember this - if your model cannot handle 224x224x3 data without overfitting, it will not scale with ResNet.
Overfitting is not a problem to be patched. It is a signal. Learn to read it, and you will build better models.
Full walkthrough (YouTube)
Interested in learning ML foundations?
Check this out: https://vizuara.ai/self-paced-courses