
Teaching Robots to Fold Clothes: SmolVLA for Bimanual Cloth Manipulation
How a 450M-parameter Vision-Language-Action model learns to coordinate two robot arms for fabric folding — from just 50 human demonstrations.

Try to fold a piece of cloth. Notice what your hands do — one grips an edge while the other lifts and folds over, then both press down to crease. Now imagine teaching a robot to do the same thing.
Cloth folding is one of those tasks that seems trivially easy for humans but is brutally hard for robots. Fabric has effectively infinite degrees of freedom. It crumples, slides, and deforms unpredictably. You can’t plan a rigid trajectory the way you would for picking up a block — the cloth reshapes itself with every touch.
In this post, I’ll walk through how I fine-tuned SmolVLA — a compact 450M-parameter Vision-Language-Action model — on 50 teleoperated demonstrations to teach two robot arms to fold a cloth. I’ll compare it head-to-head against ACT (Action Chunking with Transformers), a popular lightweight imitation learning baseline, and share what worked, what didn’t, and what surprised me.
SmolVLA successfully initiates the fold, completes it tightly, and pushes the cloth aside — scoring 2.80/3.00.*
The Setup: Two Arms, Three Cameras, One Cloth
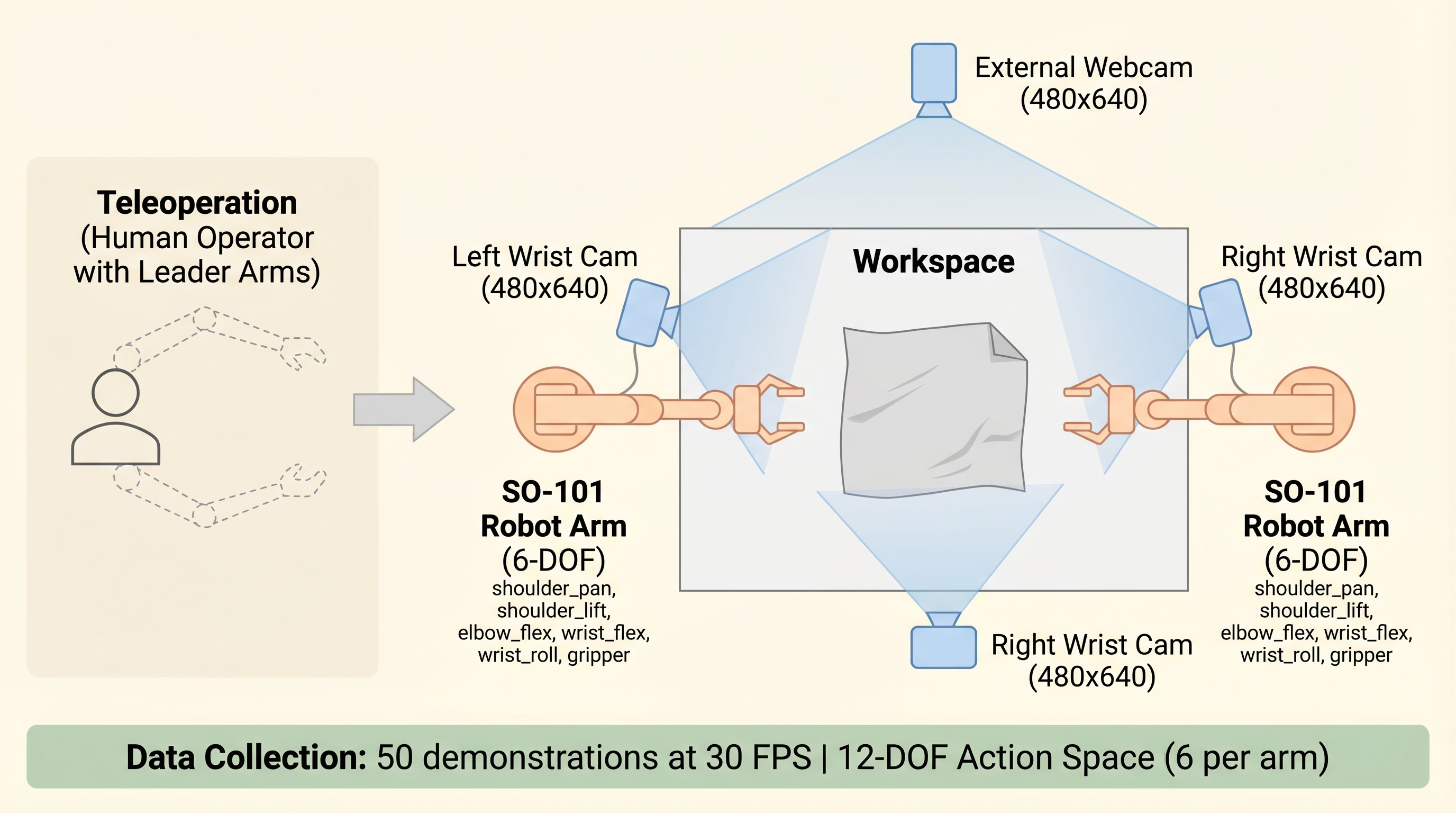
The bimanual SO-101 setup with three camera views
The hardware is deliberately simple and accessible:
-Two SO-101 robot arms — open-source, low-cost, 6-DOF manipulators (~$300 each)
- Three cameras— left wrist, right wrist, and an overhead webcam (all 480x640, synced at 30 FPS)
- Action space — 12 dimensions (6 joint positions per arm)
I collected 50 teleoperation demonstrations of myself folding a cloth, totaling ~48,000 synchronized frames stored in LeRobot v3.0 format. Each demonstration captures the full pipeline: reach for the cloth edge, fold it over, press down, push it aside.
Why 50? That’s enough to cover the natural variation in cloth placement and draping, while staying practical for a single-person data collection session (~2 hours).
How SmolVLA Works
SmolVLA is a Vision-Language-Action model — it takes in camera images and a language instruction, and directly outputs motor commands. Here’s what makes its architecture interesting:
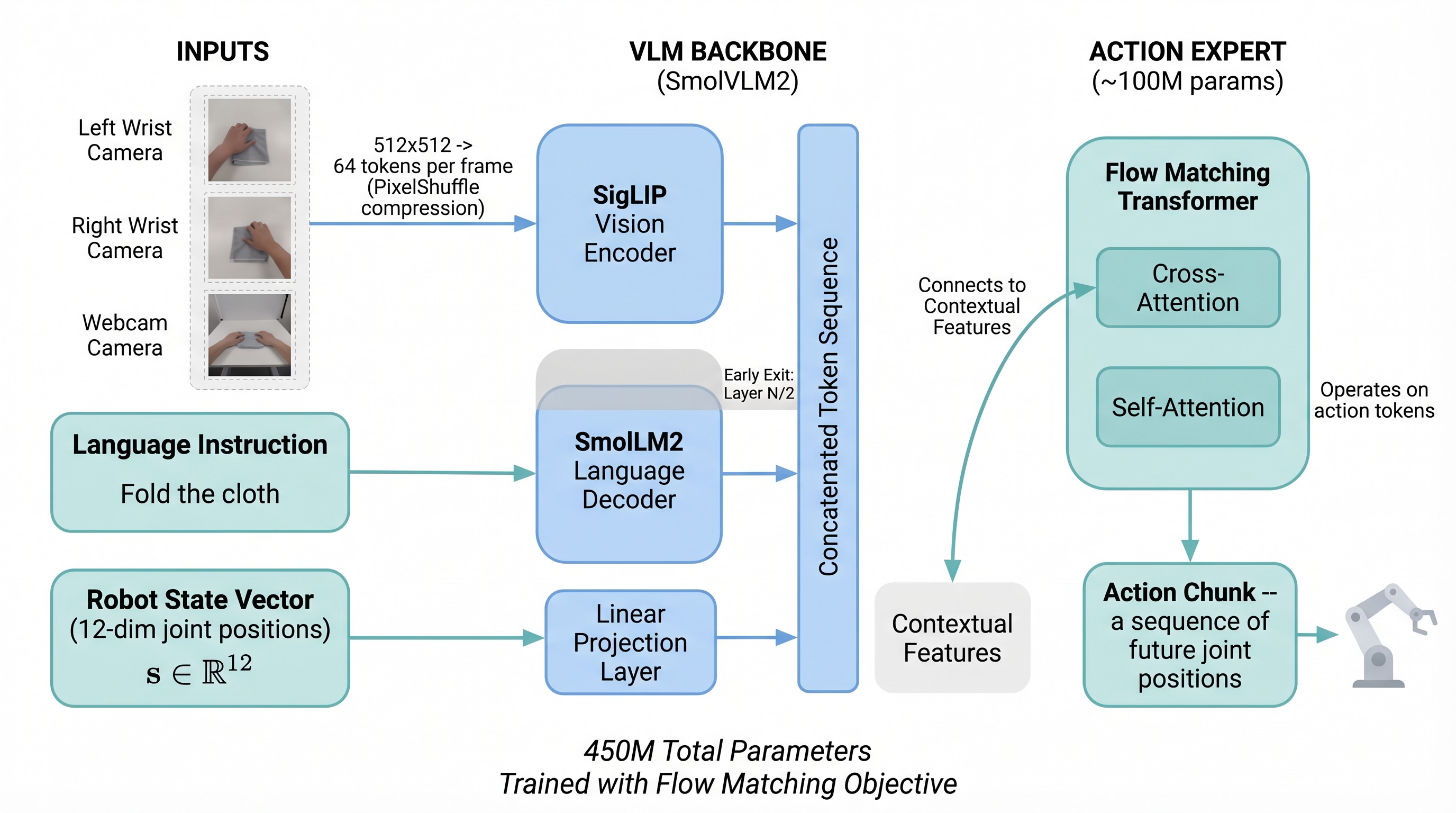
SmolVLA architecture: visual tokens from SigLIP are compressed via PixelShuffle and fused with language tokens in a VLM backbone. The action expert generates chunked trajectories via flow matching.
Vision: See the Cloth
A SigLIP vision encoder processes each camera frame into tokens. The key trick is PixelShuffle compression — 1,024 visual tokens per frame get compressed down to just 64, a 94% reduction. With three cameras, that’s 192 visual tokens instead of 3,072. This makes the model tractable to train and run in real-time.
Language: Understand the Task
The instruction “Fold the cloth” gets tokenized and processed alongside the visual tokens through a SmolVLM2 language backbone. In a single-task setting like ours, this might seem unnecessary — but it means the same model architecture could handle “Fold the cloth in half” vs. “Roll the cloth up” without retraining the vision pipeline.
Action: Move the Arms
This is where SmolVLA diverges from standard VLMs. Instead of predicting text tokens, it uses a dedicated action expert that generates “action chunks” — sequences of future joint positions — using flow matching.
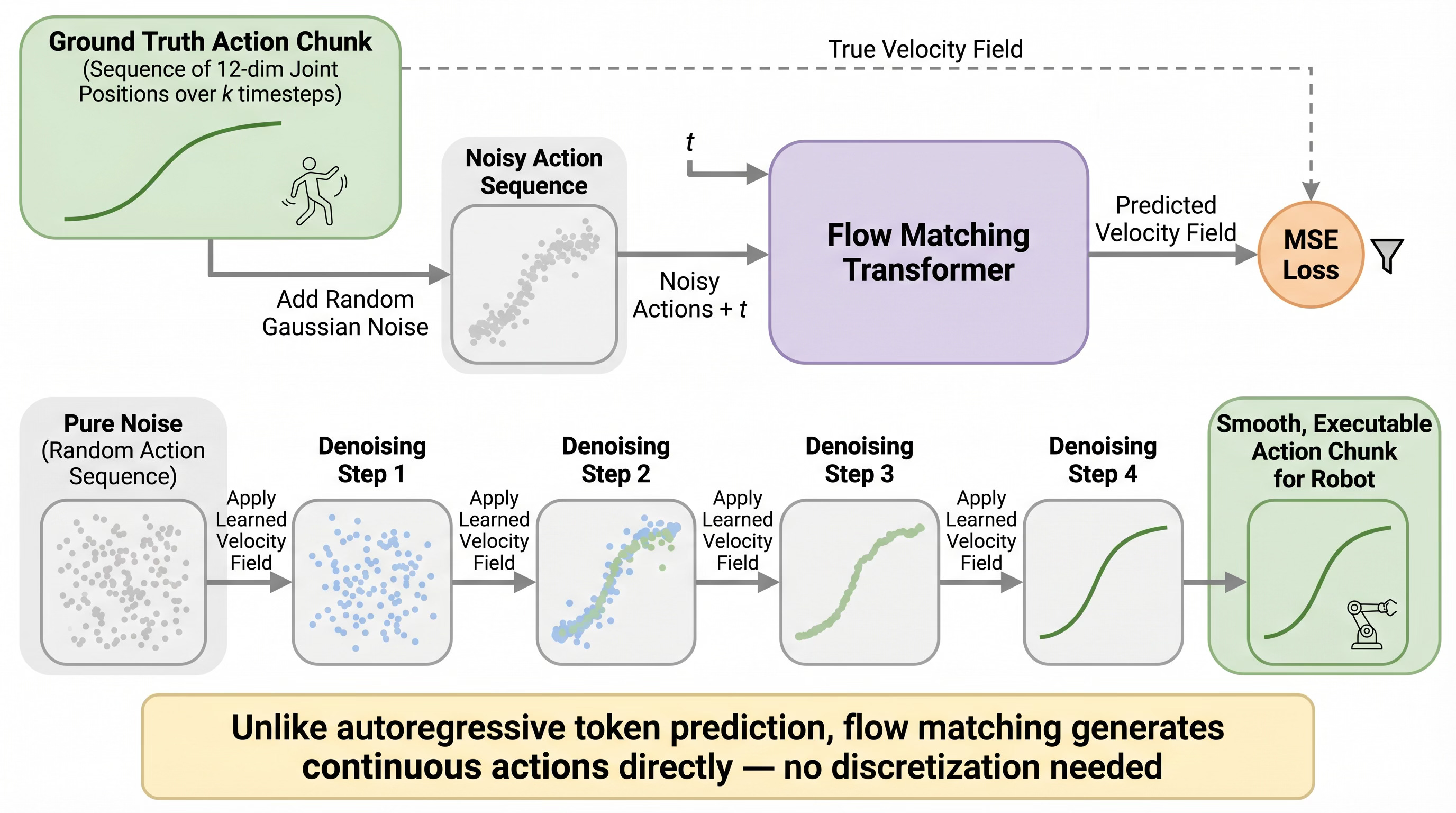
Flow matching training: noise is added to ground-truth trajectories, and the model learns to predict the velocity field that denoises back to the clean trajectory.
Think of flow matching like this: during training, you take a real trajectory and add noise to it. The model learns to predict the “velocity field” — the direction to push each noisy point to recover the clean trajectory. At inference, you start from pure noise and iteratively apply the learned velocity field to generate a smooth, coherent action sequence.
Why action chunks instead of single-step predictions? Because predicting one joint angle at a time compounds errors quickly — the robot drifts. By predicting a chunk of ~50 future timesteps at once, the motion stays coherent and smooth.
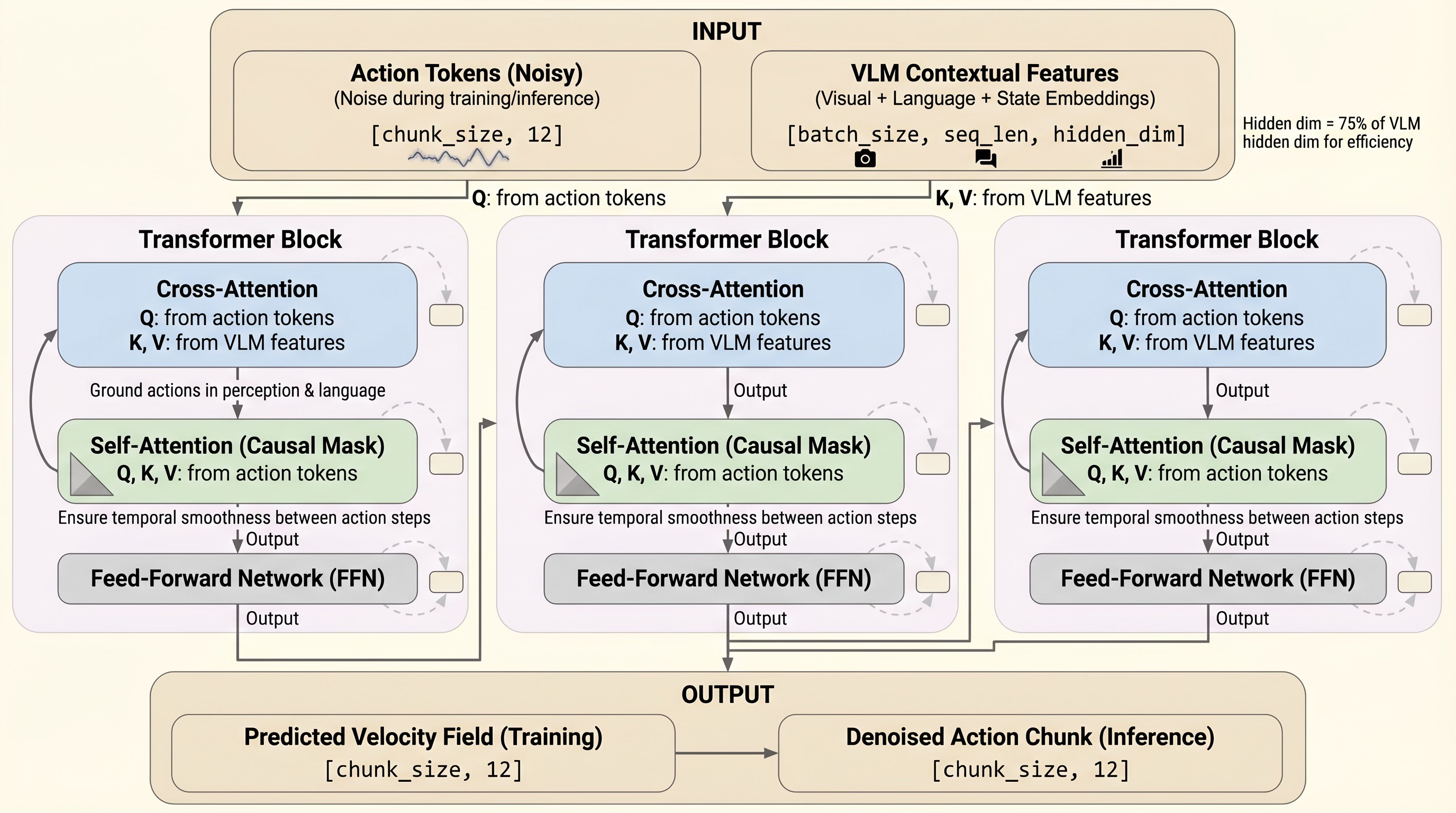
The action expert uses interleaved cross-attention (grounding in visual context) and self-attention (temporal coherence across the action chunk).
Training: Pretraining Is the Secret Weapon
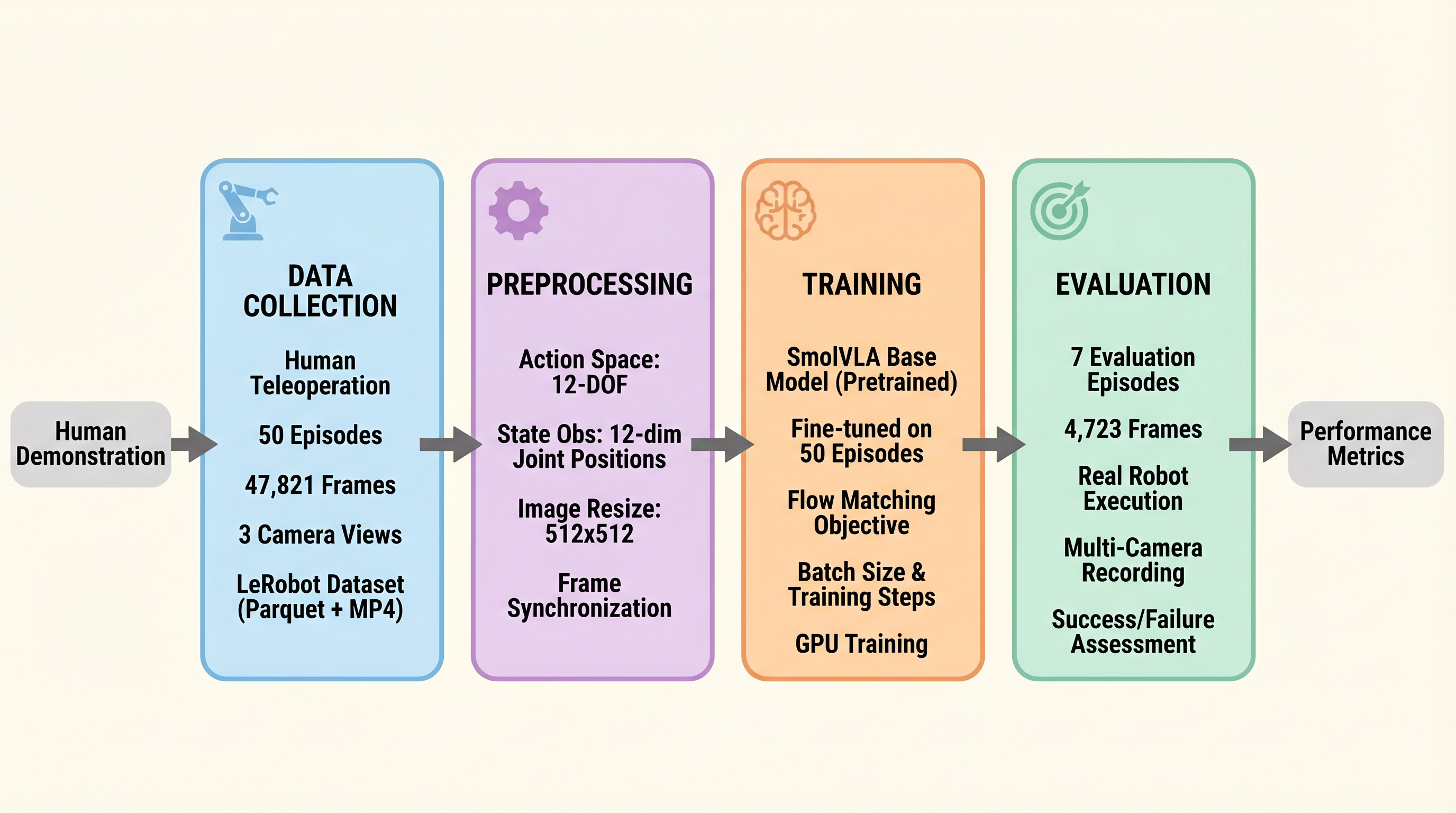
Training pipeline — pretrained on 30K community episodes, then fine-tuned on 50 cloth-folding demonstrations.
SmolVLA’s base model (`lerobot/smolvla_base`) was pretrained on ~30,000 episodes from LeRobot community datasets — various robots doing various manipulation tasks. This broad exposure gives the model prior knowledge about how objects move, how grippers interact with surfaces, and how to coordinate motor commands.
Fine-tuning on our 50 cloth-folding episodes took ~2 hours 49 minutes on a single A100 GPU** for 10,000 steps. The final training loss was 0.021.
How much does pretraining matter? According to the SmolVLA paper, the gap is dramatic:
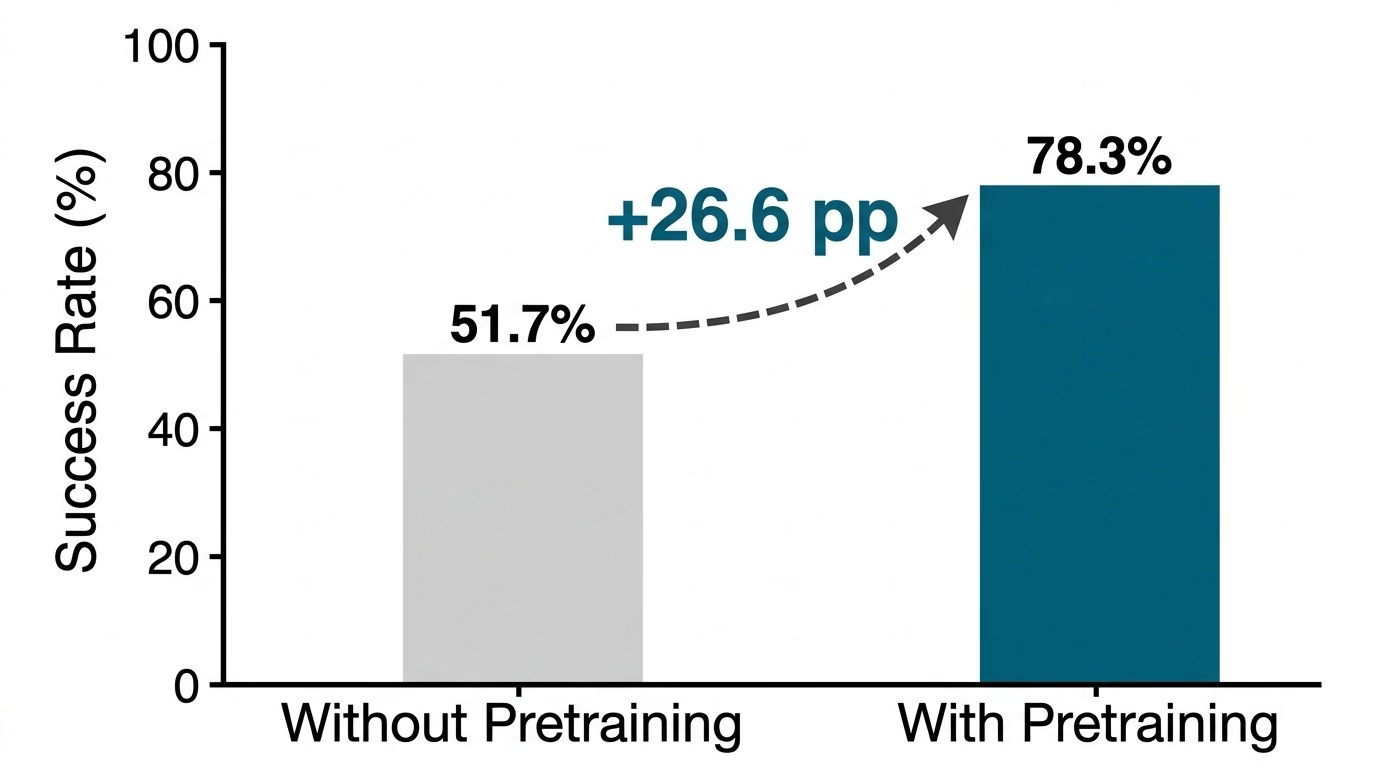
Without pretraining: 51.7% success. With pretraining: 78.3% success. A +26.6% absolute improvement from pretraining alone.
The model doesn’t just learn faster — it learns better, because it already has a foundation of sensorimotor knowledge to build on.
The Benchmark: SmolVLA vs. ACT
To put SmolVLA’s performance in context, I trained ACT (Action Chunking with Transformers) on the exact same 50 demonstrations and evaluated both models side-by-side.
ACT is a fundamentally different philosophy:

SmolVLA: the “Generalist adapted to a specialty” — 450M parameters, pretrained on 30K episodes, language-conditioned, flow matching. ACT: the “Specialist” — 52M parameters, trained from scratch, vision-only, Conditional VAE.
The question: does all that extra capacity and pretraining actually help on a single concrete task?
Results: The Numbers Tell a Clear Story
I evaluated SmolVLA on 7 episodes and ACT on 10 episodes, scoring each on three criteria (0-1 each, max 3.0 total):
- R1 — Fold Initiation: One arm clamps, the other folds over
- R2 — Fold Completion: Press down, tighten the fold
- R3 — Push Aside:** Move the folded cloth to clear the workspace
The Headline Numbers
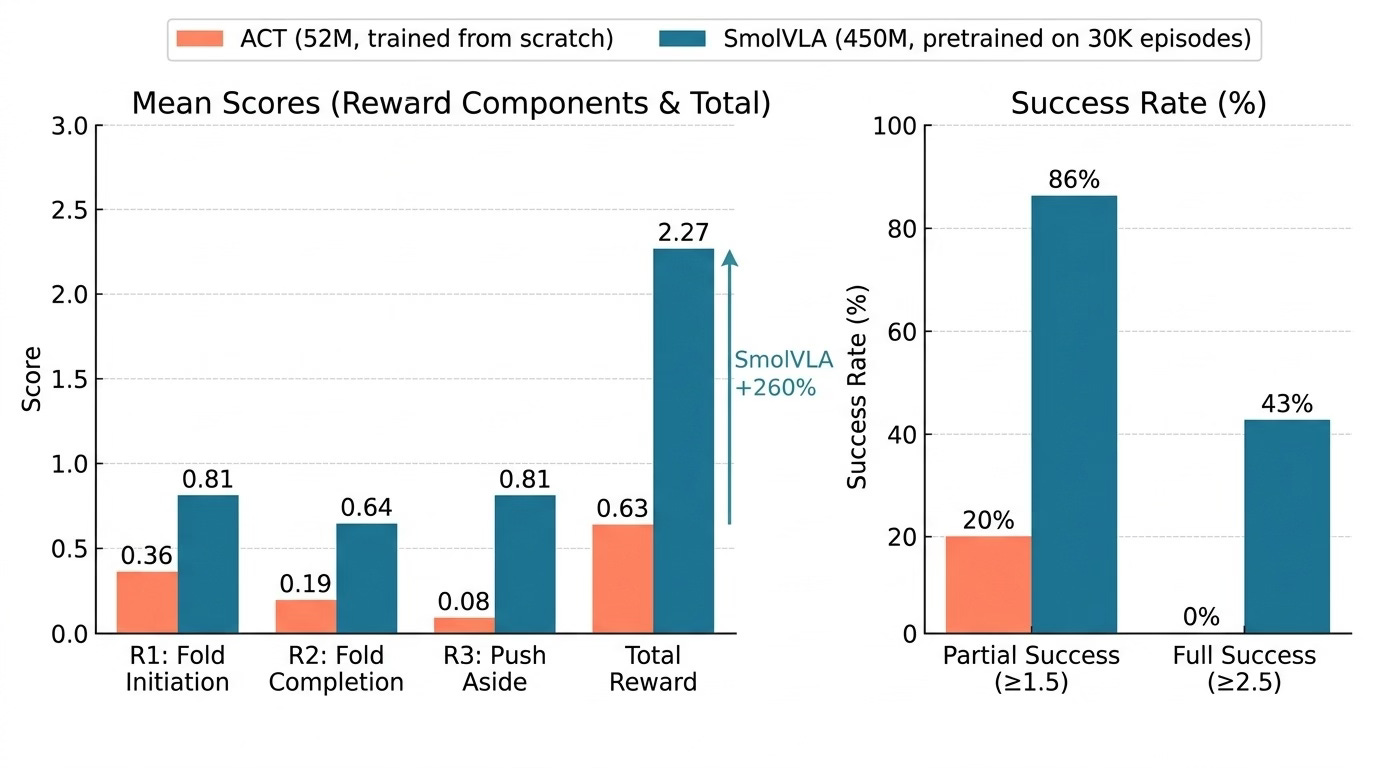
Head-to-head comparison: SmolVLA scores 2.27/3.0 mean total reward vs ACT’s 0.63/3.0 — a 260% improvement. SmolVLA achieves 86% partial success rate vs ACT’s 20%.
SmolVLA outperforms ACT by 260% on mean total reward.
ACT’s best episode (1.80/3.00) — it manages a fold and push, but this level of performance was the exception, not the norm.*
What ACT Gets Wrong
ACT’s biggest failure mode is inaction — in 5 out of 10 episodes, the robot simply didn’t move. The arms positioned near the cloth but never executed a folding motion. When ACT does act, the fold initiation is actually decent (R1 of 0.70-0.80), but it almost never completes the full pipeline.
What SmolVLA Gets Right
SmolVLA is remarkably consistent. 6 out of 7 episodes initiate the fold, complete it to a reasonable degree, and push the cloth aside. The scores cluster tightly between 1.80 and 2.80 — it’s not that SmolVLA occasionally nails it, it’s that it reliably executes the full task pipeline.
Per-Episode Breakdown
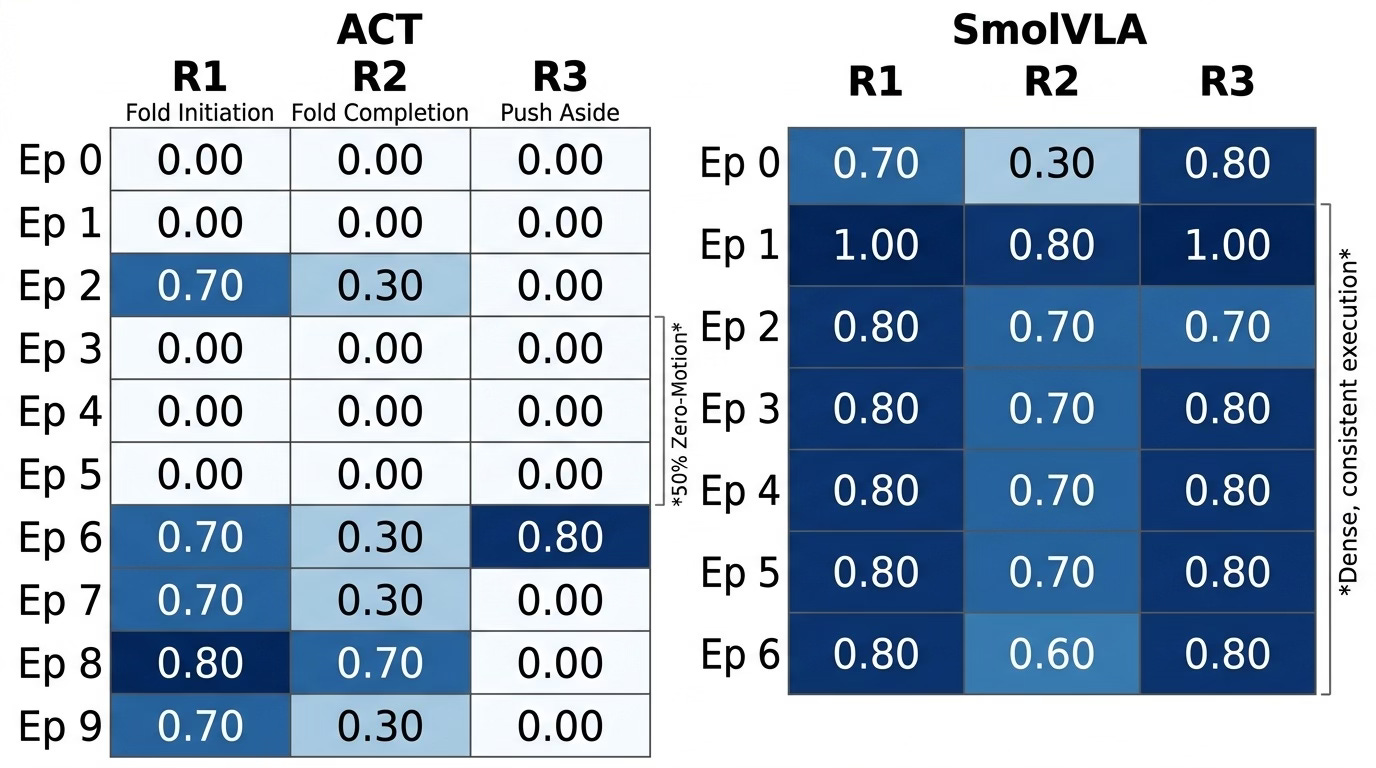
Per-episode performance heatmap. Left: ACT shows sparse activation — 50% of episodes had zero motion (white rows). Right: SmolVLA shows dense, consistent high scores across all episodes. The contrast visually captures SmolVLA’s reliability vs ACT’s bimodal behavior.
Consistency across episodes — SmolVLA follows the same fold-and-push strategy with minor variations.
Why the Gap Is So Large
Three factors explain the 260% performance difference:
1. Pretraining Provides Motor Priors
SmolVLA doesn’t learn bimanual coordination from scratch. Its base model has seen 30,000 episodes of various manipulation tasks. It already “knows” how to coordinate two end-effectors, how to approach objects, and how to execute smooth trajectories. Fine-tuning on 50 episodes refines this knowledge for cloth specifically.
ACT starts from random initialization. 50 episodes and 100,000 gradient steps simply aren’t enough for a from-scratch model to reliably learn when to move and when not to. Hence the 50% inaction rate.
2. Flow Matching Produces Smoother Trajectories
SmolVLA’s flow matching generates trajectories by iterative denoising — the output is inherently smooth and temporally coherent. ACT uses a Conditional VAE, which can produce jerkier, less coordinated motions, especially in the bimanual setting where both arms need to synchronize.
3. Multi-Camera Fusion
Both models use the same three cameras, but SmolVLA’s SigLIP encoder (pretrained on internet-scale image data) extracts richer features from each view. ACT’s ResNet-18 (trained from scratch) has to learn visual representations simultaneously with motor policies — a much harder optimization problem.
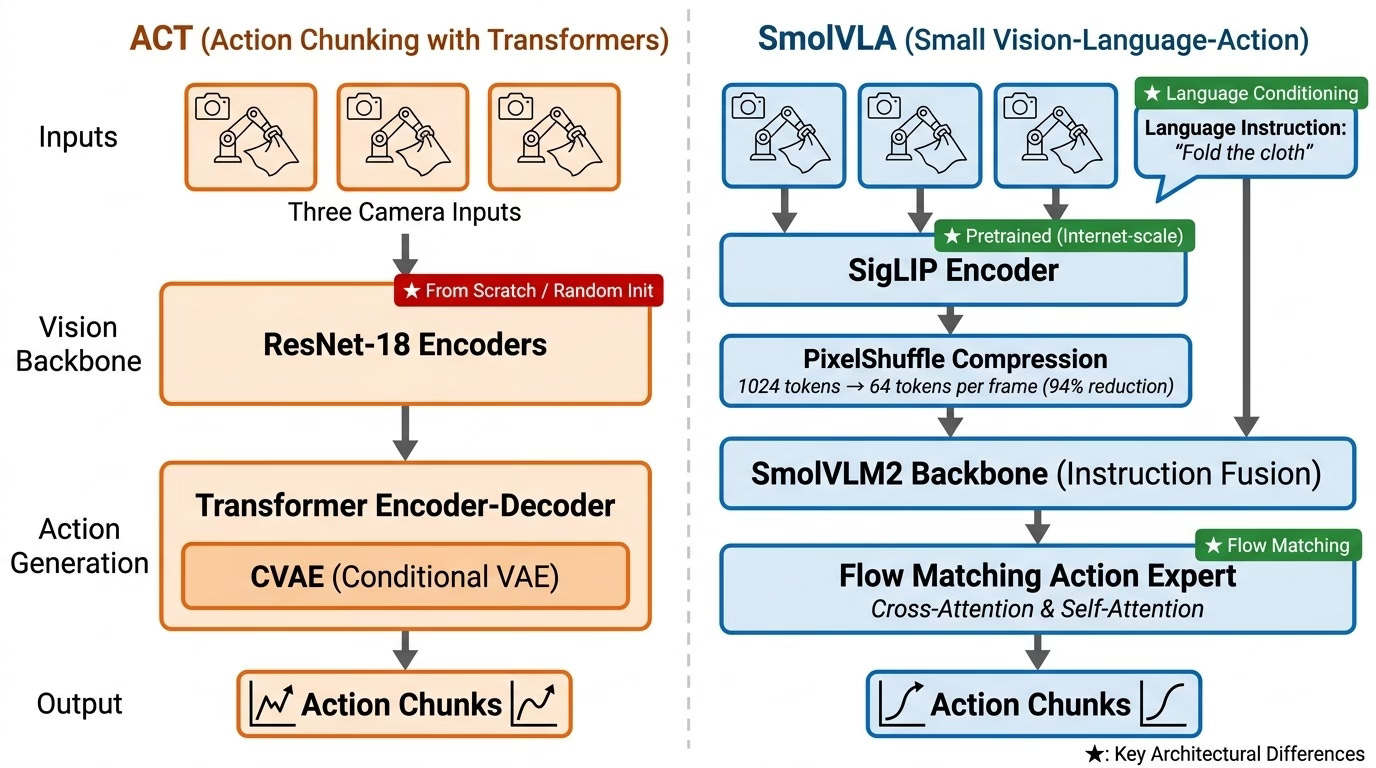
Architectural comparison: ACT’s simpler pipeline (ResNet-18 + CVAE) vs SmolVLA’s richer pipeline (SigLIP + VLM backbone + Flow Matching action expert). Key differences highlighted: pretrained vs from-scratch vision, language conditioning, and flow matching vs CVAE.
Evaluation Method: Using an LLM as a Judge
One practical contribution worth highlighting: I used Claude Sonnet 4 as an automated evaluation judge. For each episode, the judge received 8-12 sampled frames and scored R1, R2, R3 on the defined rubric.
This mostly worked well, with one systematic bias: the VLM judge underscored R3 (push aside). From the overhead webcam angle, lateral displacement of the cloth was hard for the vision model to detect. Manual frame-by-frame verification corrected this, bumping SmolVLA’s R3 from 0.30 to 0.81.
Lesson: VLM-based evaluation is a useful automation, but always validate on a sample, especially for spatial reasoning tasks where camera perspective matters.
What I’d Do Differently
More demonstrations. 50 episodes is the minimum viable dataset. The fold completion scores (R2) are the weakest link — the model struggles with the fine-grained pressing motion. More demos with variation in fold tightness would likely help.
Better fabric variety. All 50 demos used the same cloth. Thin, slippery fabrics would likely cause failures. Mixing fabric types during data collection would improve robustness.
Recovery behavior. Neither model recovers after a missed grasp. The training data contains only successful demonstrations, so the policy has no “what to do when things go wrong” knowledge. Adding a few recovery demonstrations or using RL fine-tuning could address this.
Episode-level evaluation at scale. 7 and 10 episodes give directional signal but not statistical significance. A proper evaluation would run 50+ episodes per model.
Key Takeaways
1. Pretraining dominates. The single biggest factor in SmolVLA’s success is its pretrained base. 30,000 episodes of prior experience make 50 task-specific demonstrations go much further.
2. Compact VLAs are practical. 450M parameters runs on consumer hardware. You don’t need billion-parameter models for tabletop manipulation.
3. 50 demonstrations is enough to get started. Not enough for production reliability, but enough to demonstrate clear task competence with a pretrained model.
4. ACT is not the right baseline for bimanual deformable manipulation. ACT shines on rigid-object tasks with clear visual cues. Bimanual cloth folding exposes its limitations — particularly the lack of pretraining and the weaker visual backbone.
5. The LeRobot ecosystem is a force multiplier. Standardized data formats, community pretrained models, and plug-and-play training scripts dramatically reduce the engineering burden. This entire project — data collection, training, evaluation — was done by one person.
Resources and Reproducibility
Everything needed to reproduce this work is open:
- Training dataset: Dataset Link (50 episodes)
- SmolVLA policy: Finetuned SmolVLA Model
- ACT policy: Trained ACT Model
- Evaluation data (SmolVLA) SmolVLA Evaluation Set
- Evaluation data (ACT): ACT Evaluation Set
- Base model: https://huggingface.co/lerobot/smolvla_base
- Framework: https://github.com/huggingface/lerobot
If you’re working on manipulation with open-source robots or experimenting with VLAs, I’d love to hear about it. Drop a comment or reach out — this space moves fast and I think we’re just getting started.
Our live bootcamp on VLA and World Models: https://robotlearningmastery.vizuara.ai
Minor in Robotics: