
OpenCV: The framework that revolutionized computer vision
A comprehensive introduction to practical Computer Vision


Introduction: The Evolution of Computer Vision
Computer vision has undergone a remarkable transformation over the past decade, evolving from hand-engineered features to sophisticated deep learning approaches that power everything from self-driving cars to medical diagnostics. This comprehensive guide explores both classical and modern computer vision techniques, providing practical implementations that you can apply to real-world problems.
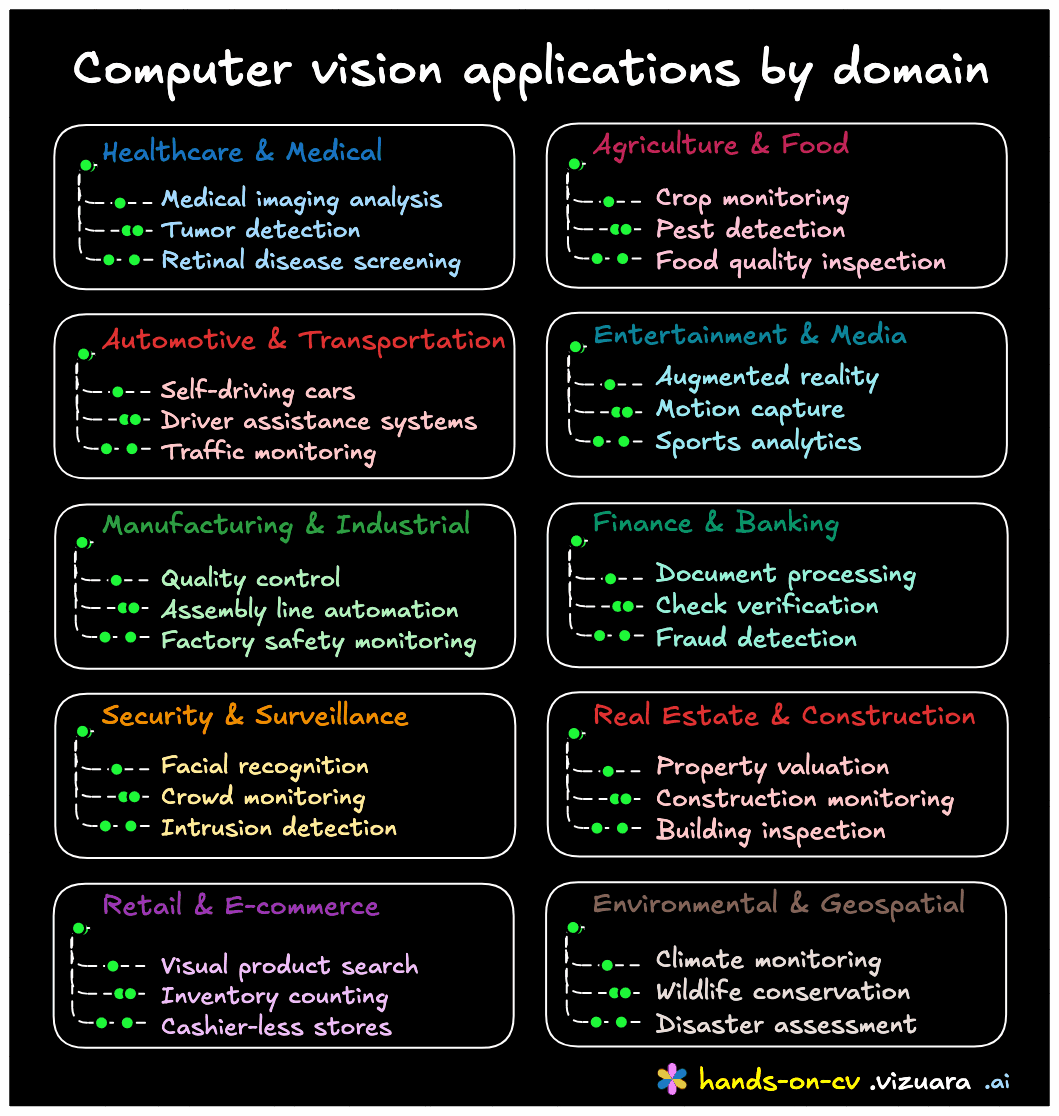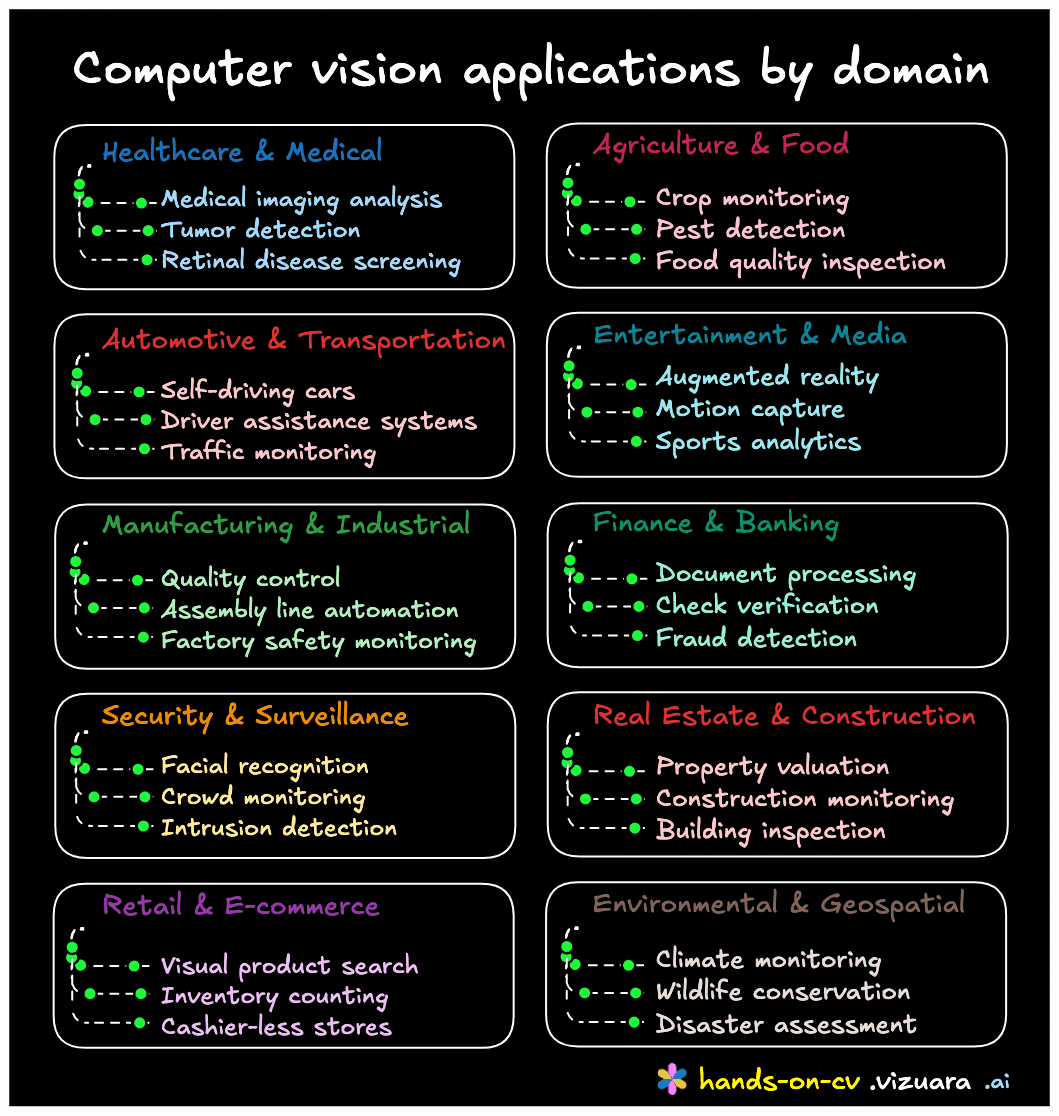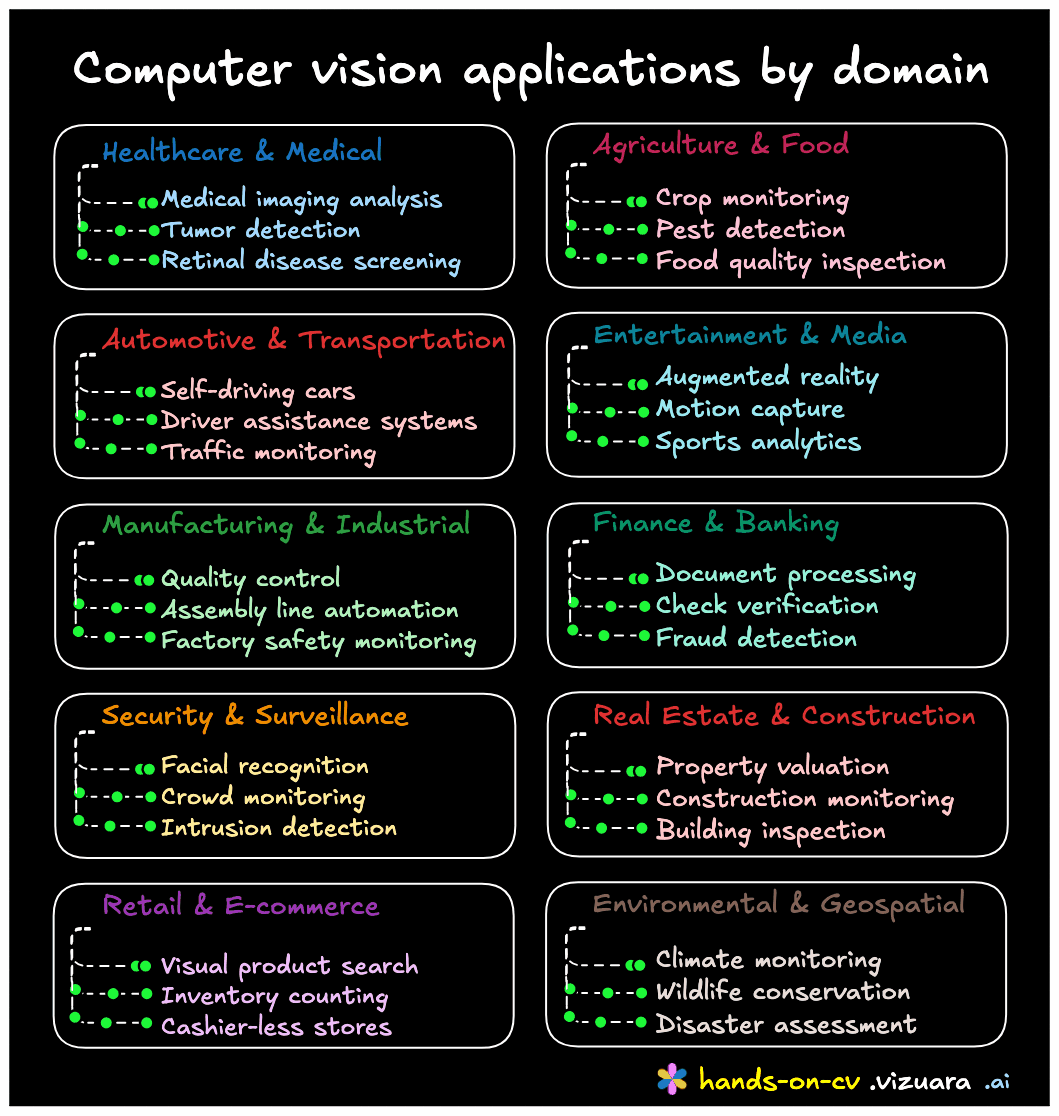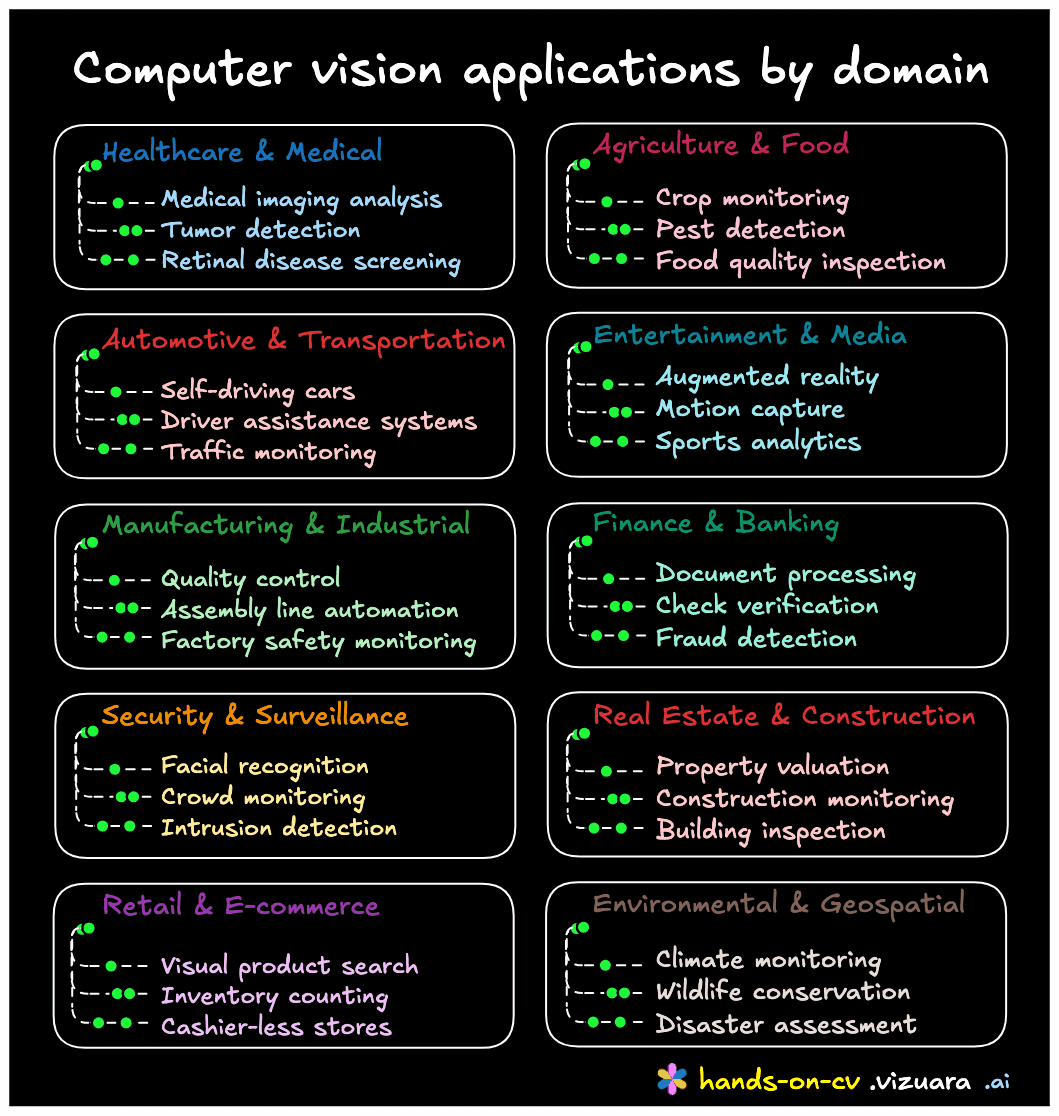
The field of computer vision has penetrated virtually every industry imaginable. While most people are familiar with consumer-facing applications like facial recognition for phone unlocking or KYC (Know Your Customer) verification at airports, these represent just the tip of the iceberg. The vast majority of computer vision applications operate behind the scenes in manufacturing, healthcare, agriculture, and countless other domains where automated visual inspection and analysis drive efficiency and innovation.
A Personal Journey: From Experimental Physics to Computer Vision
My journey into computer vision began somewhat unexpectedly during my PhD at MIT from 2017 to 2022.

While working on self-cleaning solar panels for desert regions, I encountered a fascinating challenge that required computer vision solutions. The project aimed to develop an electrostatic cleaning system that could remove dust from solar panels without using water, recovering 95-98% of lost power output.
The critical challenge was determining the appropriate dust removal voltage, which depended entirely on particle size. Since manually measuring particle sizes across solar panels was impractical, I turned to computer vision. Using an inexpensive camera with 50-100x magnification, I captured images containing thousands of dust particles. A convolutional neural network was then implemented to process these images in real-time, classifying dust particles into different size buckets (30 microns, 50 microns, etc.). This classification allowed the autonomous cleaning system to apply the optimal voltage for dust removal - whether 10, 12, or 15 kilovolts.
This experience demonstrated how computer vision seamlessly integrates with physical systems across diverse engineering domains. Whether you come from mechanical engineering, computer science, or even non-engineering backgrounds, computer vision has become increasingly relevant as the field continues to expand into new industries and applications.
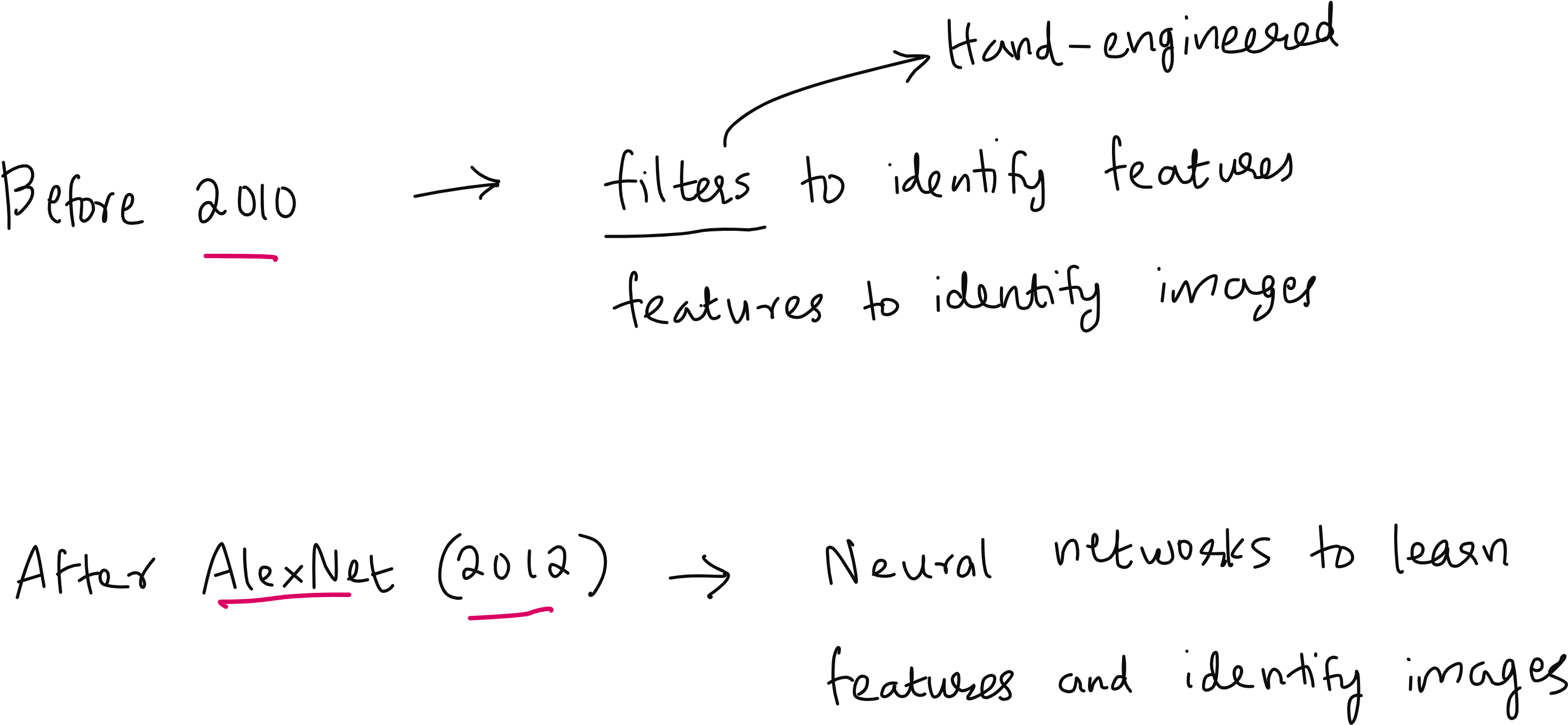
The Historical Context: From Hand-Engineered Features to Deep Learning
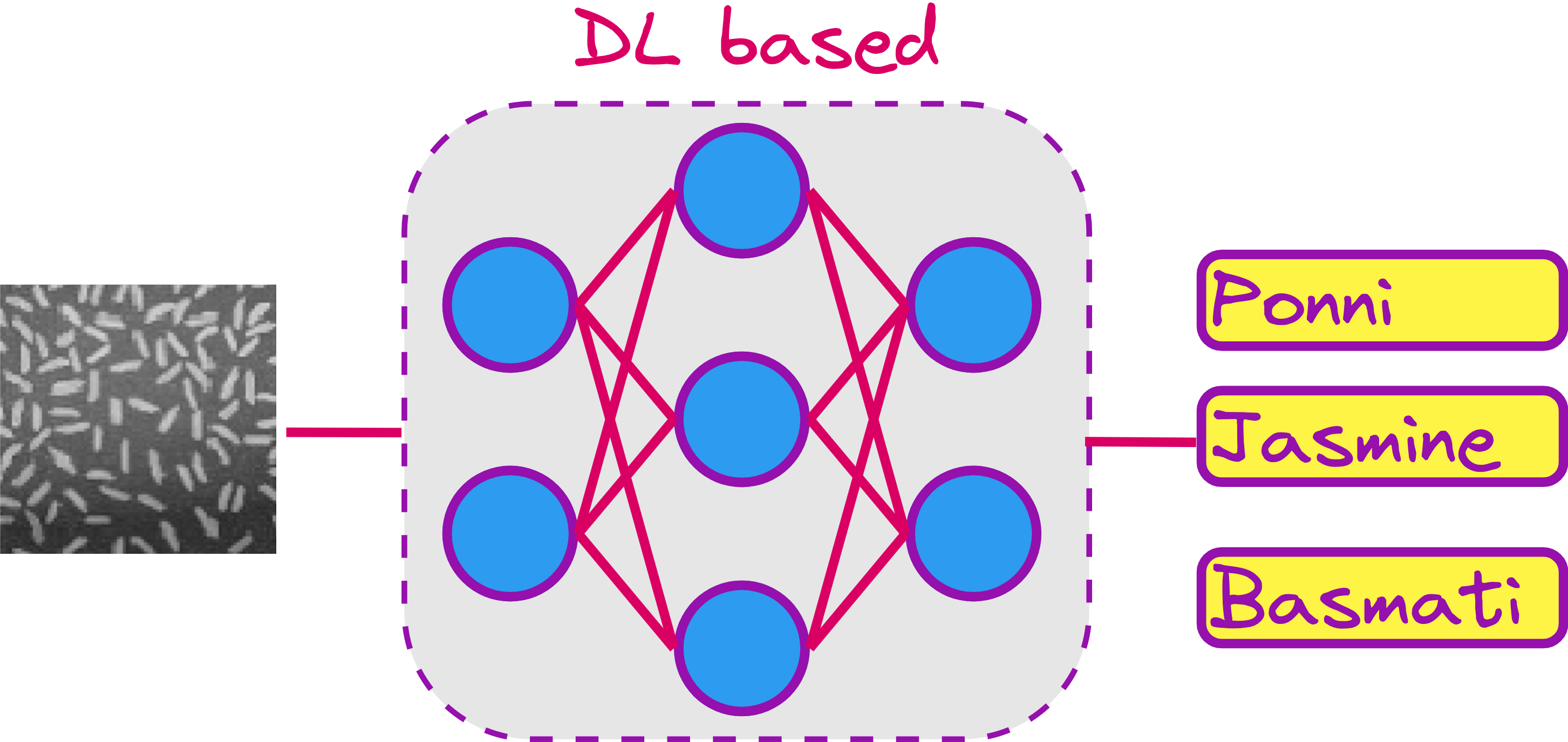
More than a decade ago, before the deep learning revolution, computer vision relied heavily on hand-engineered features. My early research experience with rice grain classification exemplifies this classical approach. The project aimed to classify different rice varieties (Basmati, Jasmine, Ponni, Idli rice) based on their physical characteristics. Rice grains could appear in various configurations – sparsely distributed or touching each other in heaps.

The traditional approach involved complex algorithms for detecting when grains were touching, splitting overlapping shapes, fitting ellipses to individual grains, and measuring their dimensions. We would plot size distributions with longer and shorter axes, expecting different rice varieties to cluster in distinct regions of this parameter space. This pure computer vision approach relied entirely on human-designed algorithms without any neural networks.

This work, presented at the 9th International Conference on Machine Vision in Nice, France, coincided with a pivotal moment in computer vision history. The research community was clearly shifting toward deep learning approaches, moving away from hand-engineered features. This transition was catalyzed by AlexNet in 2012, which demonstrated for the first time that deep neural networks could effectively train on large image datasets using GPU acceleration.

AlexNet's impact cannot be overstated. The paper, authored by Alex Krizhevsky, Geoffrey Hinton (who won the 2024 Nobel Prize in Physics for his work on neural networks), and Ilya Sutskever (co-founder of OpenAI), fundamentally changed how we approach computer vision problems. It marked the beginning of NVIDIA's meteoric rise and the widespread adoption of parallel computing for deep learning.
Understanding Image Filters: The Foundation of Vision Processing
Before diving into modern deep learning approaches, it's essential to understand how filters work in image processing. Filters are fundamental to both classical and deep learning-based computer vision, though their implementation differs significantly.
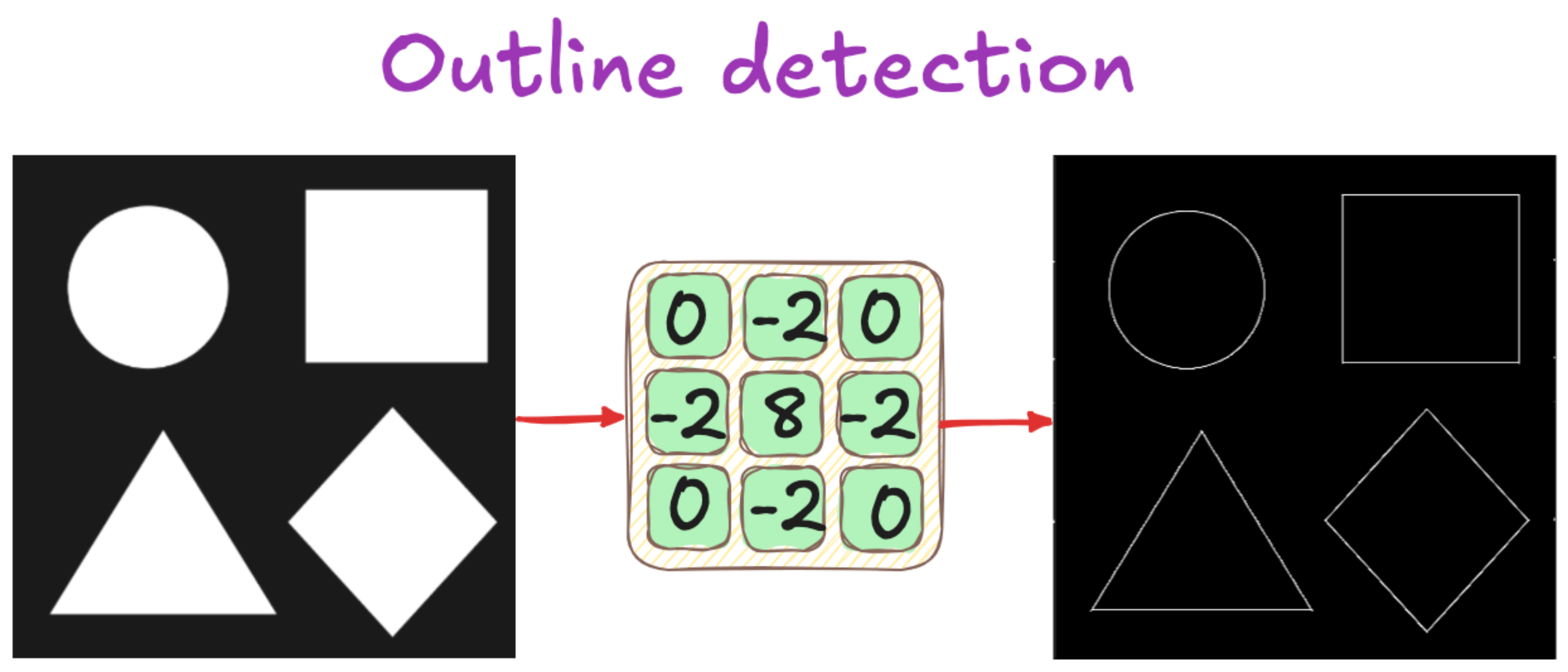
In classical computer vision, filters are hand-engineered matrices that perform convolution operations on images. Consider a simple 3x3 filter matrix with specific numerical values. When applied to an image, this filter extracts particular features based on its design. For instance, edge detection filters identify regions where pixel values change rapidly, highlighting boundaries and contours in images.

The convolution process works by sliding the filter across the image, performing element-wise multiplication and summation at each position. The result is assigned to the corresponding pixel in the output image. This operation can detect various features depending on the filter's values:
Edge detection filters highlight transitions between different regions
Blur filters smooth out image details
Sharpening filters enhance image edges and details
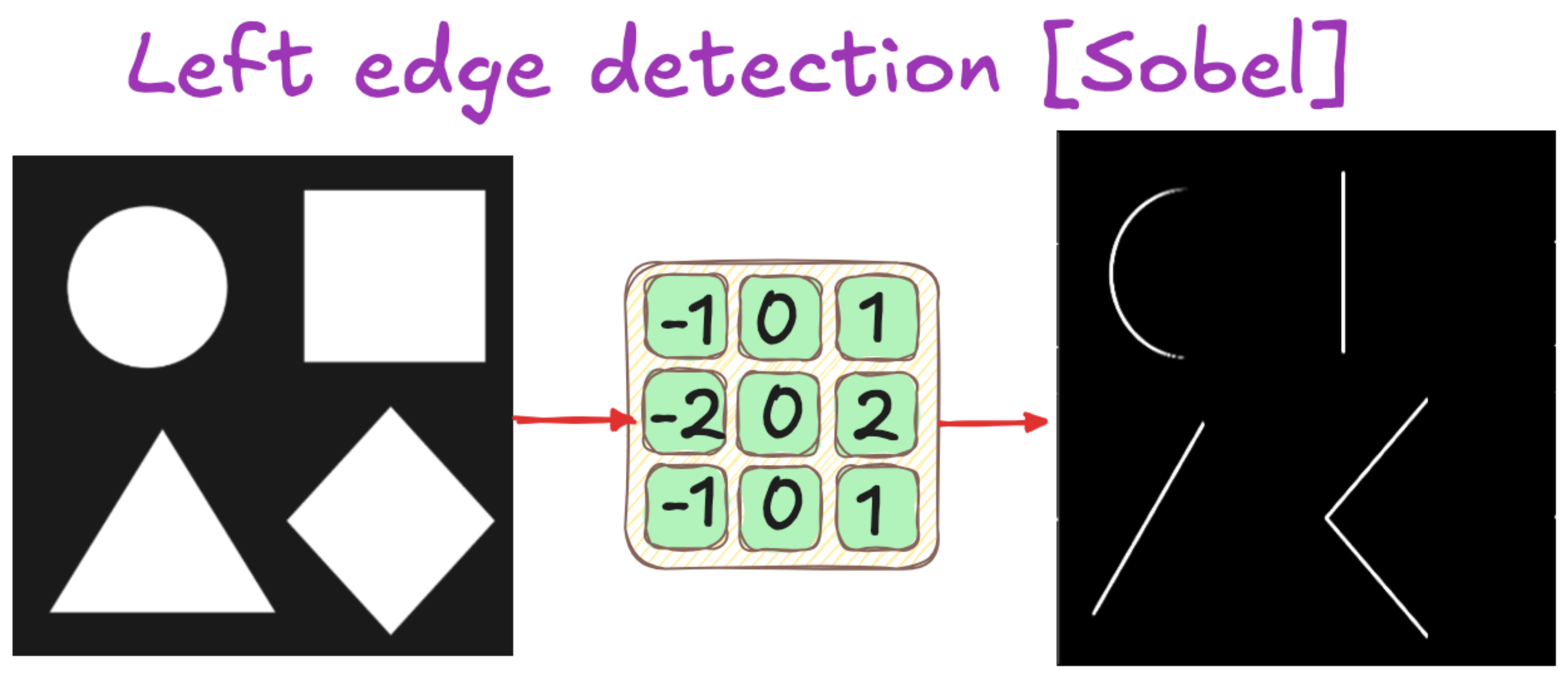
To understand this intuitively, imagine an image where shapes protrude from the screen like three-dimensional objects. If light rays travel from one direction to another, they would illuminate specific edges based on their angle. In filter design, negative numbers can be thought of as light sources, while positive numbers represent destinations. A filter with negative values at the top and positive values at the bottom would detect top edges, as if light were traveling from top to bottom, illuminating the upper boundaries of objects.

https://setosa.io/ev/image-kernels/
Modern Computer Vision Tasks and Applications
Today's computer vision encompasses a wide range of tasks, each serving specific purposes across various industries:
Image Classification
The most fundamental task involves categorizing entire images into predefined classes. This might seem simple – distinguishing cats from dogs, for example – but it forms the foundation for more complex applications. Modern tools like Google's Teachable Machine have made it remarkably easy to build and train classification models without deep technical knowledge.

Object Detection
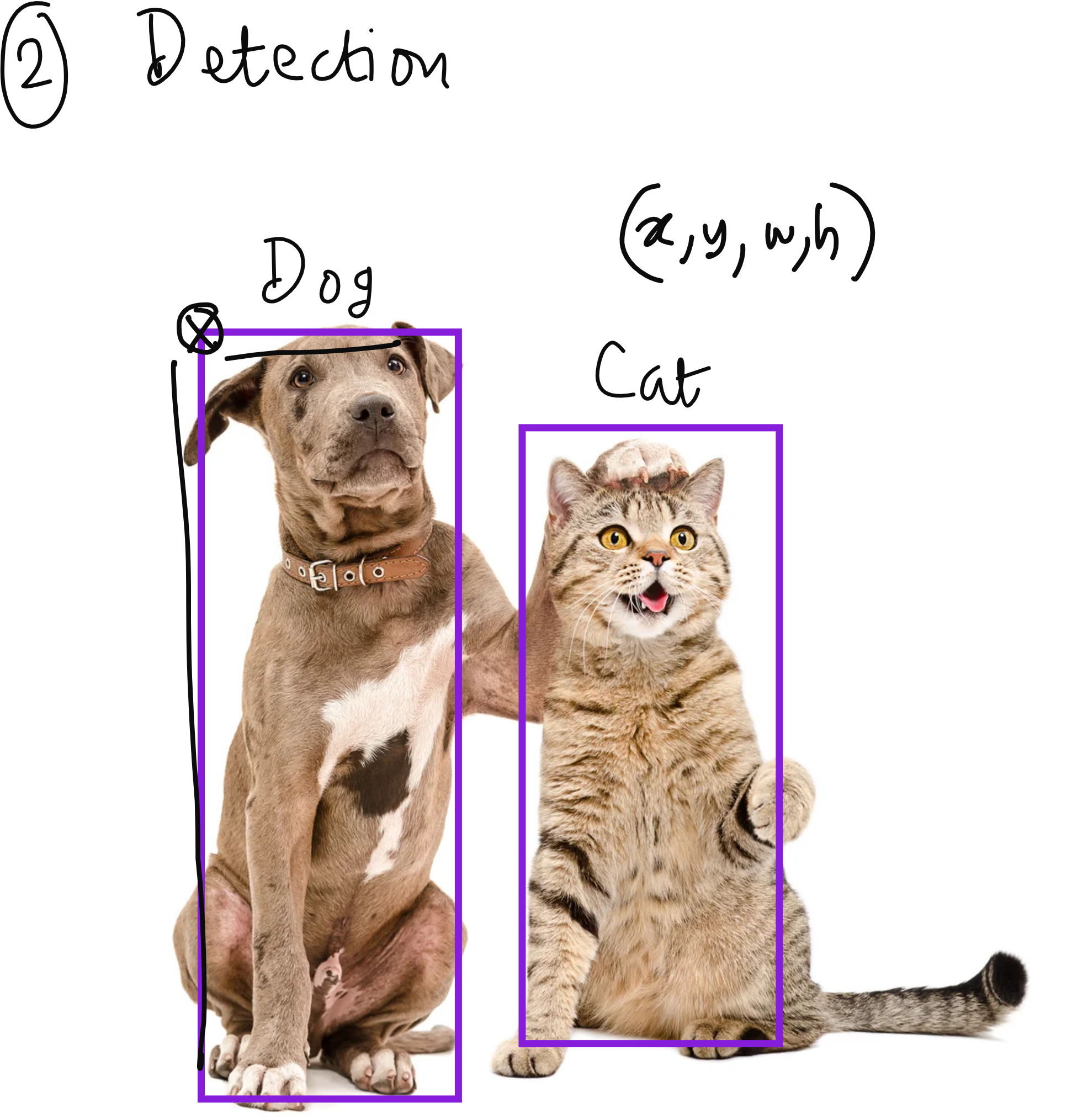
Unlike classification, object detection identifies and localizes multiple objects within an image using bounding rectangles. Each rectangle is characterized by four parameters: the x and y coordinates of a corner point, plus width and height. This enables systems to not only identify what objects are present but also where they're located in the image.
Semantic Segmentation
Going beyond bounding boxes, semantic segmentation captures the exact contours of objects. Techniques like U-Net, which we'll explore in detail, can precisely outline object boundaries rather than approximating them with rectangles. This precision is crucial for applications requiring detailed spatial understanding, such as medical image analysis or autonomous navigation.

Object Tracking
In video analysis, tracking maintains consistent identification of objects across frames. When a person walks through a CCTV feed, the system must recognize that it's the same individual moving from one location to another, assigning and maintaining a unique identifier throughout their journey. This capability is essential for surveillance, traffic analysis, and behavioral studies.

Object Counting
Quantification tasks involve counting objects passing through specific regions. This might include vehicles at traffic intersections, products on conveyor belts, or people entering buildings. Such data drives decisions like traffic signal timing optimization – determining that a busy road needs 120 seconds of green light while a quieter street only needs 30 seconds.

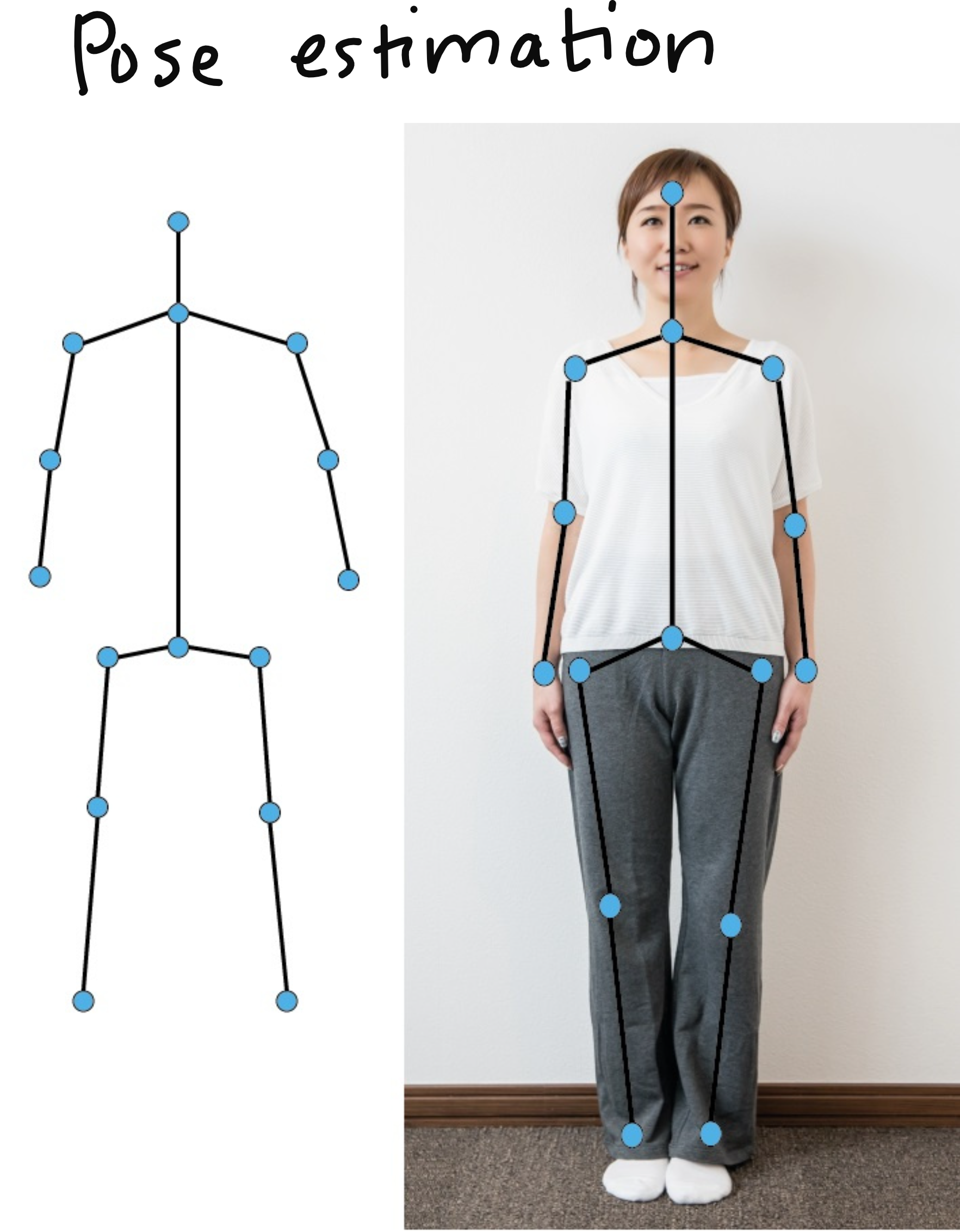
Pose Estimation
Human pose estimation fits skeletal models to people in images or videos, identifying key points like joints and tracking their movement. This technology powers applications in sports analysis, martial arts training, physical therapy, and any domain involving complex human motion analysis.

Industry Applications: Beyond Consumer Technology
Computer vision's impact extends far beyond consumer-facing applications. In healthcare, companies are developing robotic surgical systems where vision systems guide precise operations alongside other sensors. Manufacturing facilities employ computer vision for quality control, assembly line monitoring, and defect detection – processes invisible to end consumers who only see the final products.
Physical security represents another major application area. Companies specializing in CCTV surveillance for airports, public spaces, and private businesses use computer vision to detect security threats automatically. Industrial automation leverages these technologies for tasks ranging from inventory management to predictive maintenance.
Agriculture has embraced computer vision in surprising ways. One company quantifies pesticide application efficiency, determining how much actually reaches plants versus being wasted. Over-spraying not only wastes resources but introduces harmful chemicals into the environment and food chain. Computer vision enables precise measurement and optimization of these processes.
Blue River Technologies, acquired for approximately $300 million by John Deere, exemplifies agricultural innovation. Their system uses cameras to activate sprayers only when weeds are detected near crops, dramatically reducing chemical usage while maintaining effectiveness. This selective spraying technology, initially tested on lettuce and cabbage, demonstrates how computer vision can transform traditional farming practices.
The rise of autonomous vehicles represents perhaps the most visible application of computer vision. Companies like Waymo have deployed fully self-driving taxis in cities like Chicago and Los Angeles. These vehicles navigate complex urban environments without human drivers, relying heavily on computer vision systems to interpret their surroundings. While the specific models remain proprietary, these systems likely employ multiple specialized networks for different tasks – object detection, classification, path planning, and more.
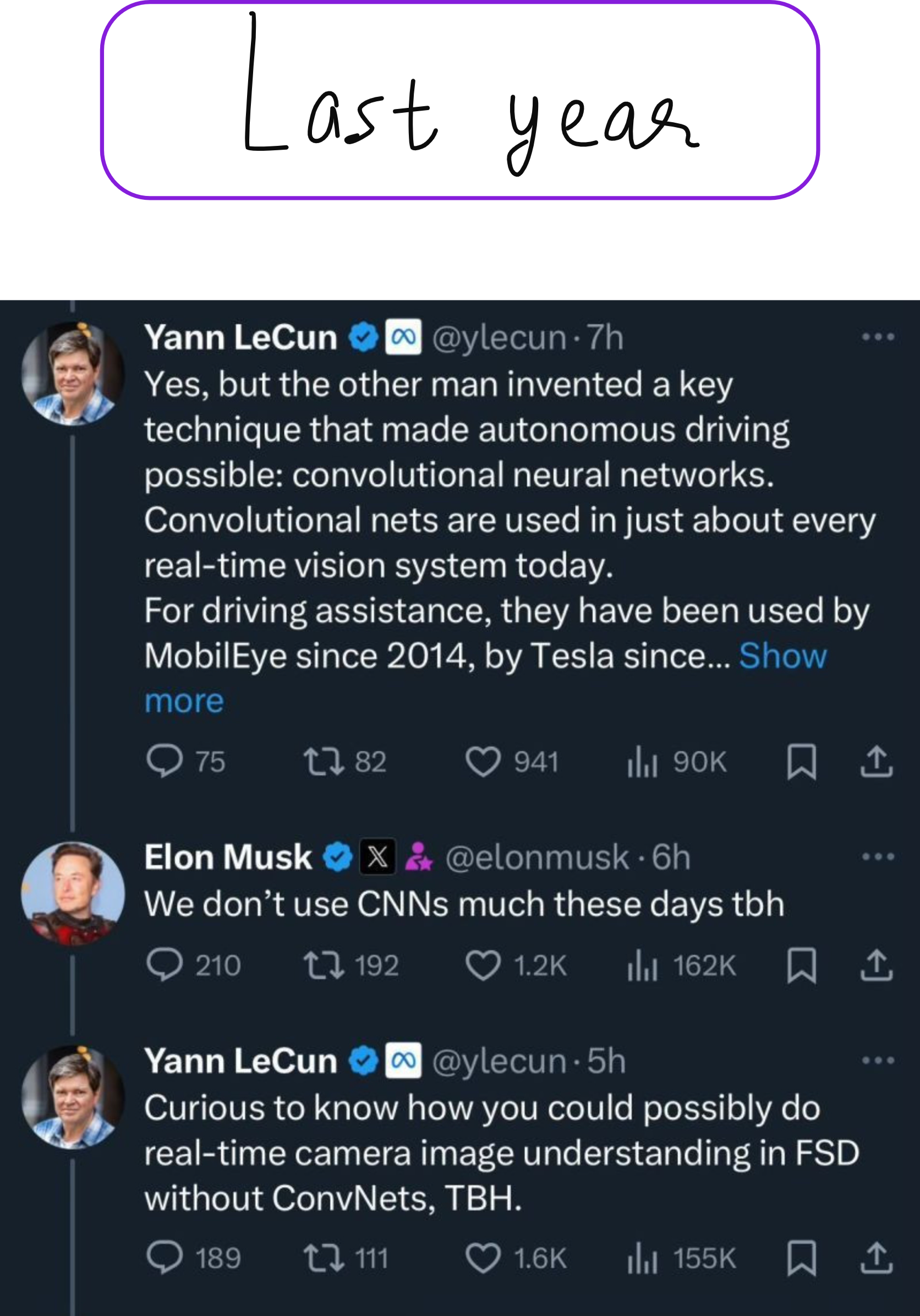
Recent discussions between Yann LeCun and Elon Musk about Tesla's Full Self-Driving (FSD) technology highlighted the evolution from convolutional neural networks to vision transformers. This shift represents the cutting edge of computer vision, where transformer architectures originally developed for natural language processing are being adapted for visual tasks.
Getting Started with OpenCV
OpenCV stands as the most popular computer vision library, with over 5 million downloads per week. This remarkable adoption rate reflects its versatility and power for image and video processing tasks. Whether you're reading images from files or cameras, annotating visualizations, or implementing complex algorithms, OpenCV provides the foundational tools.
Setting Up Your Development Environment
To begin working with OpenCV, you'll need a proper development environment. Visual Studio Code (VS Code) offers an excellent platform for Python development, though alternatives like Anaconda work well too. Google Colab presents limitations for camera access, making local development preferable for this type of work.
First, install Python from the official website, downloading the latest version appropriate for your operating system. Next, set up VS Code as your integrated development environment. Once installed, create a dedicated folder for your computer vision projects – organizing your work systematically from the start will pay dividends as your projects grow in complexity.

Creating a virtual environment represents a best practice in Python development. Virtual environments isolate project dependencies, preventing conflicts between different projects' requirements. In your terminal, navigate to your project folder and create a virtual environment with:
python -m venv hands_on_cvActivate the environment (the command varies by operating system), and you'll see the environment name appear in your terminal prompt, confirming activation. With your environment active, install OpenCV using pip:
pip install opencv-pythonBasic Image Operations
Let's begin with fundamental image operations. Reading and displaying images forms the foundation of any computer vision project:
import cv2
# Read an image
img = cv2.imread('image.jpg')
# Display the image
cv2.imshow('Original Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Save the image
cv2.imwrite('saved_image.jpg', img)This simple code demonstrates three essential operations: reading an image from disk, displaying it in a window, and saving it back to disk. The waitKey(0) function pauses execution until a key is pressed, while destroyAllWindows() ensures proper cleanup of display windows.

Image Processing Techniques
OpenCV provides numerous image processing functions that form the building blocks of more complex algorithms:
import cv2
# Read the image
img = cv2.imread('image.jpg')
# Resize the image
resized = cv2.resize(img, (640, 480))
# Convert to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Apply Gaussian blur
blurred = cv2.GaussianBlur(img, (15, 15), 0)
# Detect edges using Canny edge detector
edges = cv2.Canny(img, 100, 200)
# Display all processed images
cv2.imshow('Resized', resized)
cv2.imshow('Grayscale', gray)
cv2.imshow('Blurred', blurred)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()Each processing technique serves specific purposes. Resizing adjusts image dimensions for consistent processing or display. Grayscale conversion reduces computational complexity while preserving essential structural information. Gaussian blur reduces noise and fine details, with larger kernel sizes (like 15x15 versus 5x5) producing stronger smoothing effects.
The Canny edge detector deserves special attention. Its two threshold parameters (100 and 200 in our example) control sensitivity to gradients. Lower thresholds detect more edges but may include noise, while higher thresholds focus on stronger, more definitive edges. These parameters define the minimum and maximum gradient strengths considered as edges.
Drawing and Annotation
Annotation capabilities enable visualization of detection results and analysis outcomes:
import cv2
import numpy as np
# Create a blank canvas
canvas = np.zeros((512, 512, 3), dtype=np.uint8)
# Draw a line
cv2.line(canvas, (0, 0), (511, 511), (0, 255, 0), 15)
# Draw a rectangle
cv2.rectangle(canvas, (100, 100), (400, 400), (255, 0, 0), 3)
# Add text
cv2.putText(canvas, 'OpenCV Text Edition', (10, 500),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
# Display the annotated canvas
cv2.imshow('Canvas with Shapes', canvas)
cv2.waitKey(0)
cv2.destroyAllWindows()These drawing functions prove invaluable when visualizing detection results. Bounding boxes around detected objects, labels identifying classifications, and overlays highlighting regions of interest all rely on these fundamental annotation capabilities.
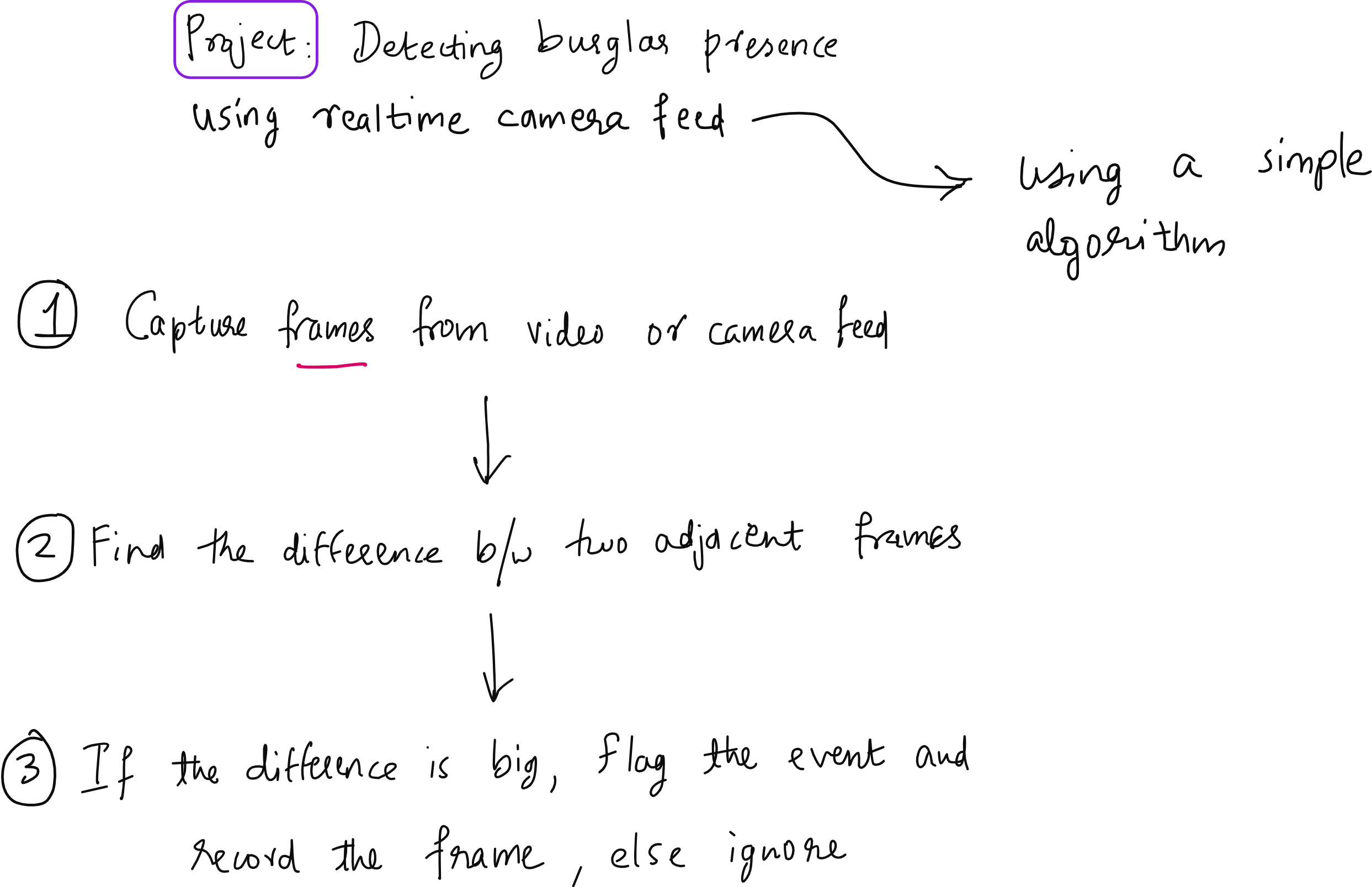
Building a Motion Detection System
Let's implement a practical application: a burglar alarm system using classical computer vision techniques. This system detects motion in video feeds without any deep learning, demonstrating the power of algorithmic approaches.
The core principle is elegantly simple: detect changes between video frames. In a static indoor environment monitored by CCTV, any significant change suggests movement – whether from an intruder, pet, or falling object. By comparing consecutive frames, we can identify and localize these changes.
import cv2
# Initialize video capture (0 for webcam, or provide video file path)
cap = cv2.VideoCapture(0) # or cap = cv2.VideoCapture('video.mp4')
# Initialize variables
frames = []
gap = 5 # Compare frames with this gap
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
# Convert to grayscale for simpler processing
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frames.append(gray)
# Maintain a sliding window of frames
if len(frames) > gap + 1:
frames.pop(0)
# Add frame counter overlay
cv2.putText(frame, f'Frame: {count}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Detect motion when enough frames are available
if len(frames) > gap:
# Calculate difference between frames
diff = cv2.absdiff(frames[0], frames[-1])
# Apply threshold to isolate significant changes
_, thresh = cv2.threshold(diff, 30, 255, cv2.THRESH_BINARY)
# Find contours of changed regions
contours, _ = cv2.findContours(thresh,
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
# Check if any contour is large enough to be significant
motion = any(cv2.contourArea(c) > 500 for c in contours)
# Process significant contours
for c in contours:
if cv2.contourArea(c) < 500:
continue
# Draw bounding box around motion
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# If motion detected, save frame and alert
if motion:
cv2.putText(frame, 'MOTION DETECTED!', (10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imwrite(f'motion_frame_{count}.jpg', frame)
print(f'Motion detected at frame {count}')
# Display the frame
cv2.imshow('Motion Detection', frame)
count += 1
# Exit on 'q' key press
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Cleanup
cap.release()
cv2.destroyAllWindows()Understanding the Algorithm
The motion detection algorithm operates through several key steps:
Frame Buffering: We maintain a sliding window of frames, comparing frames separated by a gap (e.g., 5 frames apart) rather than consecutive frames. This approach detects more significant movements while reducing sensitivity to minor fluctuations.
Difference Calculation: The absolute difference between frames highlights pixels that have changed. Static elements produce zero difference, while moving objects create non-zero values in their previous and current positions.
Thresholding: By applying a threshold (e.g., 30), we filter out minor changes from lighting variations or camera noise, focusing on significant movements. Pixels with difference values below the threshold become 0 (black), while those above become 255 (white).
Contour Detection: Connected components of white pixels form contours representing moving objects. Each contour corresponds to a region of detected motion.
Size Filtering: We filter contours by area, eliminating small movements that might come from shadows, reflections, or minor disturbances. The area threshold (e.g., 500 pixels) determines sensitivity – lower values detect smaller movements, higher values focus on larger objects.
Tuning System Sensitivity
The system's sensitivity can be adjusted through two primary parameters:
Contour Area Threshold: This parameter determines the minimum size of detected motion. A threshold of 250 pixels might detect eye movements and facial expressions, while 5000 pixels would only trigger for large body movements. This tunability allows adaptation to specific security needs – detecting any presence versus identifying significant intrusions.
Pixel Difference Threshold: The threshold applied to frame differences affects what constitutes "change." Lower thresholds (e.g., 10) detect subtle variations, potentially including lighting changes. Higher thresholds (e.g., 50) focus on more dramatic changes, reducing false positives from environmental factors.
Practical Considerations
While this classical approach works remarkably well for static camera setups, it has limitations. The algorithm assumes a fixed camera position – any camera movement appears as whole-frame motion, triggering false positives. Additionally, it cannot distinguish between different types of motion sources (humans, animals, or objects).
These limitations highlight why deep learning approaches have become prevalent. Modern systems can classify motion sources, track specific individuals, and operate robustly even with moving cameras. However, for many practical applications with static cameras – home security, warehouse monitoring, or equipment surveillance – this simple algorithm provides an effective, computationally efficient solution.
The Transition to Deep Learning
While classical computer vision techniques remain valuable, deep learning has revolutionized the field's capabilities. The key distinction lies in feature learning: classical methods require manual feature engineering, while deep learning automatically discovers optimal features through training.
In convolutional neural networks (CNNs), filters similar to our hand-engineered edge detectors are learned automatically. Instead of humans defining filter values, backpropagation optimizes these values to minimize prediction errors. The network might learn edge detectors in early layers, texture detectors in middle layers, and high-level object part detectors in deeper layers – all without explicit programming.
This automatic feature learning extends beyond simple edges and textures. Networks can learn to recognize complex patterns, handle variations in lighting and perspective, and generalize to new situations in ways that hand-engineered features struggle to match. If color matters for a classification task, the network learns color features. If texture is important, texture features emerge. The learning process discovers whatever features best solve the given problem.
Modern Architectures and Techniques
The computer vision landscape now includes sophisticated architectures addressing diverse challenges:
R-CNN (Region-based CNN): This family of models revolutionized object detection by combining region proposals with CNN classification. Rather than sliding a classifier across an entire image, R-CNN methods propose candidate regions likely to contain objects, then classify these regions.
U-Net: Originally developed for biomedical image segmentation, U-Net's encoder-decoder architecture with skip connections excels at pixel-level classification. Its ability to combine low-level detail with high-level context makes it ideal for precise boundary detection.
YOLO (You Only Look Once): Perhaps the most popular modern detection framework, YOLO achieves real-time performance by framing detection as a single regression problem. YOLO v8 and its variants power countless applications requiring fast, accurate object detection.
Vision Transformers: Adapting the transformer architecture from natural language processing, vision transformers have achieved state-of-the-art results on many benchmarks. Their ability to model long-range dependencies in images offers advantages over traditional convolutional approaches.
Deployment and Production Considerations
Moving from prototype to production requires careful consideration of deployment pipelines. Platforms like Roboflow streamline this process, providing tools for dataset management, model training, and deployment. A typical pipeline encompasses:
Data Collection and Annotation: Gathering representative training data and labeling it accurately
Model Selection and Training: Choosing appropriate architectures and training procedures
Validation and Testing: Ensuring model performance on unseen data
Deployment: Integrating models into applications or edge devices
Monitoring and Updating: Tracking performance and retraining as needed
Future Directions and Opportunities
Computer vision continues evolving rapidly, with several exciting trends:
Multimodal Learning: Combining vision with language, audio, and other modalities creates more capable and flexible systems. Models that understand both visual and textual information can tackle complex tasks like visual question answering or scene description.
Few-Shot and Zero-Shot Learning: Reducing dependence on large labeled datasets through techniques that learn from few examples or transfer knowledge from related tasks expands computer vision's applicability to specialized domains.
Edge Computing: Deploying models on resource-constrained devices enables real-time processing without cloud connectivity. Techniques like model quantization and pruning make sophisticated vision capabilities available on smartphones, embedded systems, and IoT devices.
Explainable AI: Understanding why models make specific predictions becomes crucial as computer vision systems influence important decisions. Research into interpretable models and visualization techniques helps build trust and identify potential biases.
A few thoughts
Computer vision has transformed from a specialized research area into an essential technology powering countless applications. While deep learning has revolutionized the field's capabilities, understanding classical techniques provides valuable intuition and practical tools for many real-world problems.
The motion detection system we implemented demonstrates that sophisticated deep learning isn't always necessary – simple algorithms can effectively solve specific problems with minimal computational resources. However, as requirements become more complex – distinguishing between people and animals, tracking specific individuals, or operating with moving cameras – deep learning approaches become invaluable.
Whether you're building security systems, automating quality control, analyzing medical images, or creating entirely new applications, computer vision provides powerful tools for extracting meaning from visual data. The combination of classical techniques for simple, efficient solutions and deep learning for complex, adaptive systems creates a comprehensive toolkit for modern computer vision practitioners.
As the field continues advancing, opportunities abound for applying computer vision to new domains and challenges. From improving agricultural efficiency to enabling autonomous vehicles, from revolutionizing healthcare to transforming manufacturing, computer vision remains at the forefront of technological innovation. Understanding both its classical foundations and modern developments positions you to contribute to this exciting and rapidly evolving field.
Full implementation video
Object Detection, Tracking & Segmentation with OpenCV and YOLO
Introduction
Computer vision has evolved dramatically from basic image processing to sophisticated real-time applications that can detect, track, and segment objects with remarkable accuracy. In this comprehensive exploration, we delve into building practical computer vision systems using OpenCV and pre-trained deep learning models, specifically focusing on YOLO (You Only Look Once) version 8 for various applications ranging from simple object detection to complex tracking and segmentation tasks.
The journey through modern computer vision begins with understanding the fundamental differences between various approaches and then implementing them in real-world scenarios. This article covers the complete spectrum from basic object detection to advanced segmentation techniques, providing practical code implementations and industry applications.
OpenCV + Deep Learning: Setting Up the Development Environment
Essential Dependencies and Installation
Building robust computer vision applications requires specific libraries and frameworks. The foundation begins with OpenCV for image processing operations, but the real power comes from integrating pre-trained deep learning models.
The ultralytics package provides access to YOLO models, which can be installed using pip install ultralytics. This package offers various YOLO versions, including the latest v11, though v8 remains the focus for most applications due to its proven reliability and extensive documentation.
YOLO models come in different sizes optimized for various use cases. The nano version (YOLOv8n.pt) provides a smaller, faster model suitable for real-time applications with limited computational resources, while larger versions offer higher accuracy at the cost of processing speed.

Understanding the COCO Dataset
Most pre-trained YOLO models utilize the COCO (Common Objects in Context) dataset, which contains 80 distinct object classes covering animals, vehicles, household items, and people. This standardization means that any object falling within these 80 categories can be detected and classified using pre-trained models without additional training.

The COCO dataset's comprehensive nature makes it ideal for general-purpose object detection applications. However, specialized applications may require custom-trained models using domain-specific datasets.
Implementing Basic Object Detection
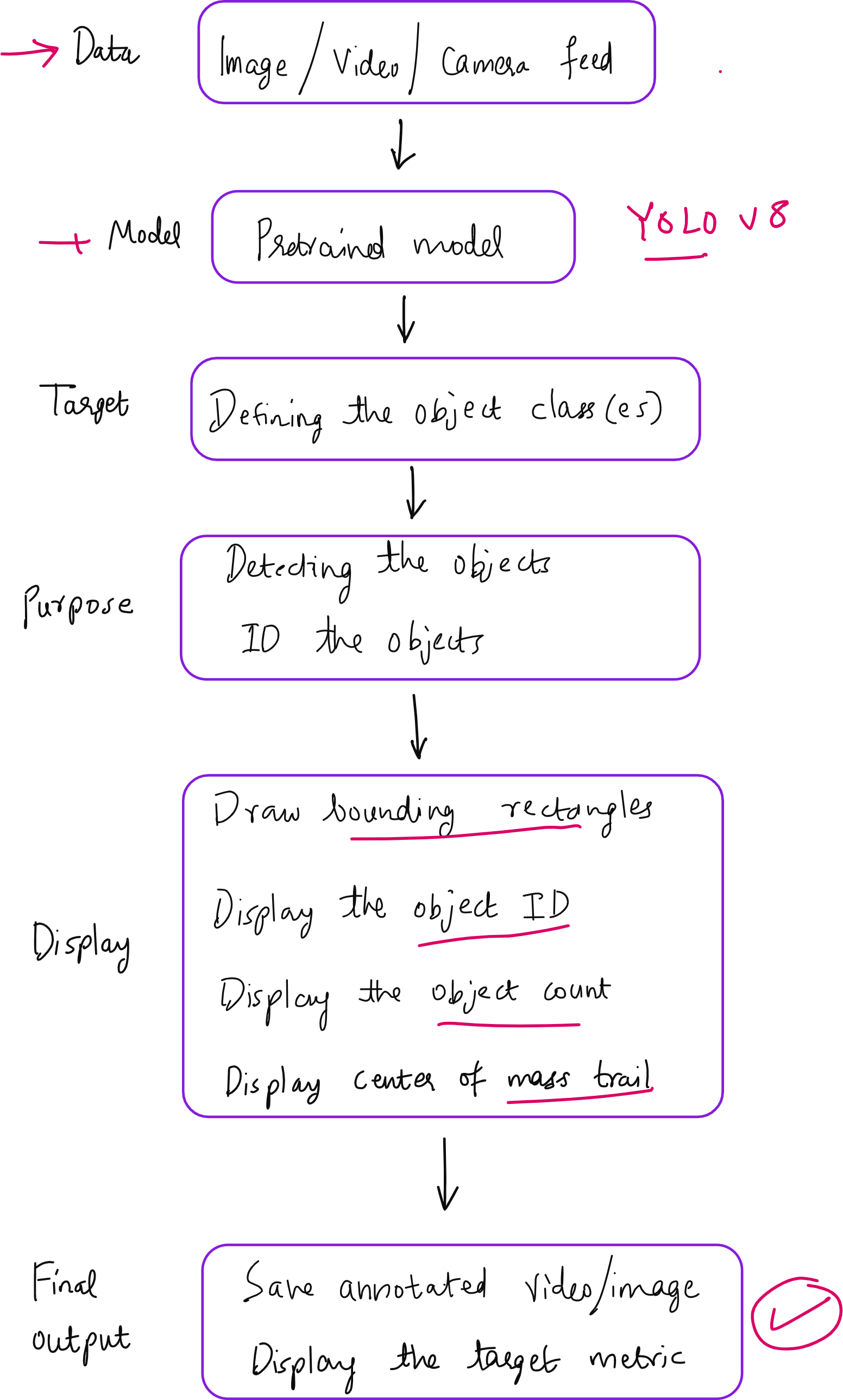
Single Image Object Detection
The simplest implementation involves processing individual images to identify and annotate objects. The process begins by loading a pre-trained YOLO model and reading an input image using OpenCV's imread function. The model processes the image and returns results containing detected objects with their corresponding confidence scores and bounding box coordinates.
import cv2
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
image = cv2.imread('sample_image.jpg')
results = model(image)
annotated_image = results[0].plot()
cv2.imshow('Annotated Image', annotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()This basic implementation demonstrates the power of pre-trained models. The system automatically identifies objects and overlays bounding boxes with confidence scores, such as detecting a person with 87% confidence.
Real-Time Camera Feed Processing
Extending object detection to live camera feeds requires implementing continuous frame processing. The system captures frames from the webcam using VideoCapture(0), where 0 indicates the default camera device. Each frame undergoes individual processing through the YOLO model, creating annotated results displayed in real-time.
The implementation uses a while loop for continuous processing, capturing frames, processing them through the model, and displaying annotated results. The process continues until the user presses a quit key, demonstrating the real-time capabilities of modern object detection systems.
Real-time processing reveals both the strengths and limitations of current models. While person detection typically achieves high accuracy, smaller objects or items outside the COCO dataset may be misclassified. For instance, a pen might be identified as a toothbrush, or a computer mouse might be labeled as a remote control.
Video File Processing
Processing pre-recorded videos follows similar principles but requires specifying the video file path instead of camera input. The system reads frames sequentially from the video file, processes each frame through the YOLO model, and displays annotated results. This approach enables batch processing of recorded content for analysis or archival purposes.
Advanced Object Detection and Tracking
Class-Specific Detection
Many applications require detecting specific object types rather than all possible objects. YOLO models support class-specific detection by specifying desired class indices. For example, class 0 corresponds to people, while class 39 represents bottles. This filtering capability enables focused applications like people counting or industrial quality control.
Specifying classes reduces computational overhead and eliminates irrelevant detections. A security system might only track people (class 0), while a manufacturing line might focus exclusively on products (specific class indices).
Object Tracking and ID Persistence
Object tracking introduces the concept of persistent identification across frames. The track method in YOLO models maintains object identities using intersection over union (IoU) calculations between consecutive frames. When the same object appears in adjacent frames, the system assigns consistent IDs based on bounding box overlap and object class matching.
The persist parameter ensures ID consistency across frames. Without persistence, the same object might receive different IDs in consecutive frames, making tracking impossible. With persistence enabled, objects maintain stable identities throughout their appearance in the video sequence.
IoU calculation forms the foundation of tracking algorithms. If two bounding boxes in consecutive frames have sufficient overlap (typically above 0.5 threshold) and contain the same object class, the system considers them the same object and maintains the ID. This approach works well for moderately paced videos but may fail with high-speed movement where objects move significantly between frames.
Implementing Object Counting Systems
Object counting builds upon tracking capabilities by maintaining sets of unique identifiers. The system tracks all unique IDs appearing throughout the video sequence, providing both instantaneous counts (objects in current frame) and cumulative counts (total unique objects seen).
Industrial applications benefit significantly from automated counting systems. Conveyor belt operations can count products without manual intervention, while traffic monitoring systems can tally vehicles passing through intersections. These applications demonstrate the practical value of computer vision in operational environments.
import cv2
from ultralytics import YOLO
import numpy as np
model = YOLO('yolov8n.pt')
cap = cv2.VideoCapture('bottles.mp4')
unique_ids = set()
while True:
ret, frame = cap.read()
results = model.track(frame, classes=[39], persist=True, verbose=False)
if results[0].boxes is not None and results[0].boxes.id is not None:
ids = results[0].boxes.id.numpy()
for oid in ids:
unique_ids.add(oid)
count = len(unique_ids)
cv2.putText(frame, f'Count: {count}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('Object Counting', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()Advanced Tracking with Trail Visualization
Center of Mass Tracking
Beyond basic bounding box tracking, advanced systems can visualize object movement patterns through center of mass tracking. This technique calculates the geometric center of each bounding box using simple coordinate arithmetic: center_x = (x1 + x2) / 2 and center_y = (y1 + y2) / 2.
Trail visualization creates moving traces that follow objects across frames, providing intuitive movement pattern recognition. These trails help identify traffic flow patterns, pedestrian movement, or any scenario requiring movement analysis.
Implementing Trail Systems
Trail implementation requires maintaining historical position data for each tracked object. The system stores recent centroid positions in memory and draws connecting lines or points to visualize movement patterns. Trail length typically limits to recent frames (such as 30 frames) to prevent visual clutter and maintain performance.
The implementation uses collections.defaultdict and deque structures to efficiently manage trail data. Each object ID maintains its own trail queue, automatically removing old positions while adding new ones. This approach ensures consistent memory usage regardless of video length.
from collections import defaultdict, deque
import cv2
from ultralytics import YOLO
import numpy as np
model = YOLO('yolov8n.pt')
cap = cv2.VideoCapture('walkers_high_res.mp4')
id_mapping = {}
next_id = 1
trail = defaultdict(lambda: deque(maxlen=30))
appear = defaultdict(int)
while True:
ret, frame = cap.read()
results = model.track(frame, classes=[0], persist=True, verbose=False)
annotated_frame = frame.copy()
if results[0].boxes is not None and results[0].boxes.id is not None:
boxes = results[0].boxes.xyxy.numpy()
ids = results[0].boxes.id.numpy()
for box, oid in zip(boxes, ids):
x1, y1, x2, y2 = box
center_x, center_y = int((x1 + x2) / 2), int((y1 + y2) / 2)
appear[oid] += 1
if appear[oid] >= 5 and oid not in id_mapping:
id_mapping[oid] = next_id
next_id += 1
if oid in id_mapping:
person_id = id_mapping[oid]
trail[oid].append((center_x, center_y))
# Draw trail
for i in range(1, len(trail[oid])):
cv2.line(annotated_frame, trail[oid][i-1], trail[oid][i],
(0, 255, 0), 2)
# Draw bounding box and ID
cv2.rectangle(annotated_frame, (int(x1), int(y1)),
(int(x2), int(y2)), (255, 0, 0), 2)
cv2.putText(annotated_frame, f'ID: {person_id}',
(int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX,
1.6, (0, 0, 255), 2)
cv2.circle(annotated_frame, (center_x, center_y), 5,
(0, 255, 0), -1)
cv2.imshow('Object Tracking with Trails', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()Vehicle Tracking and Traffic Analysis
Multi-Class Vehicle Detection
Traffic analysis requires detecting various vehicle types including cars, trucks, motorcycles, and buses. The COCO dataset includes multiple vehicle classes (indices 1, 2, 3, 5, 7, corresponding to bicycle, car, motorcycle, bus, and truck respectively). Specifying these classes enables comprehensive traffic monitoring.
Vehicle tracking presents unique challenges compared to pedestrian tracking. Vehicles move faster, change lanes, and may partially occlude each other. However, their larger size and distinct shapes often make them easier to detect consistently.
Speed Estimation from Tracking Data
Real-world applications often require speed estimation capabilities. This process involves calibrating the camera view using objects of known dimensions, converting pixel measurements to real-world distances, and calculating speed based on movement between frames.
Speed calculation requires knowing the relationship between pixels and real-world measurements. If a known object (such as a lane marking) spans 50 pixels and represents 3 meters, each pixel equals 0.06 meters. Combined with frame rate information, the system can calculate vehicle speeds by tracking center of mass movement.
Modern AI-based traffic cameras utilize these principles for automated speed enforcement. These systems detect vehicles, track their movement, calculate speeds, and can even identify license plates and safety violations like unbuckled seatbelts.
Semantic Segmentation Implementation
Understanding Segmentation vs. Detection
While object detection provides bounding boxes around objects, segmentation identifies exact pixel boundaries. This precision enables applications requiring detailed object analysis, such as medical imaging, autonomous vehicles, or precise manufacturing quality control.
Segmentation models output masks indicating which pixels belong to each detected object. These masks provide pixel-perfect object boundaries rather than rectangular approximations, enabling more sophisticated analysis and visualization.
Implementing Real-Time Segmentation
Segmentation implementation requires specialized YOLO models trained for pixel-level prediction. The YOLOv8n-seg.pt model provides segmentation capabilities while maintaining real-time performance. The process involves detecting objects, extracting pixel masks, and overlaying segmentation boundaries on the original image.
import cv2
from ultralytics import YOLO
import numpy as np
model = YOLO('yolov8n-seg.pt')
cap = cv2.VideoCapture('street.mp4')
while True:
ret, frame = cap.read()
results = model.track(source=frame, classes=[0], persist=True, verbose=False)
for r in results:
annotated_frame = frame.copy()
if r.masks is not None and r.boxes is not None and r.boxes.id is not None:
masks = r.masks.data.numpy()
boxes = r.boxes.xyxy.numpy()
ids = r.boxes.id.numpy()
for i, (mask, person_id) in enumerate(zip(masks, ids)):
x1, y1, x2, y2 = boxes[i]
# Resize mask to frame dimensions
mask_resized = cv2.resize(mask.astype(np.uint8) * 255,
(frame.shape[1], frame.shape[0]))
# Find and draw contours
contours, _ = cv2.findContours(mask_resized, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(annotated_frame, contours, -1, (0, 0, 255), 2)
# Add ID label
cv2.putText(annotated_frame, f'ID: {int(person_id)}',
(int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX,
0.6, (255, 255, 255), 2)
cv2.imshow('Segmentation', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()Mask Processing and Contour Extraction
Segmentation masks require preprocessing to match frame dimensions and extract meaningful contours. The system resizes masks to frame dimensions, converts them to appropriate data types, and uses OpenCV's contour detection algorithms to identify object boundaries.
Contour visualization provides intuitive understanding of object shapes and boundaries. These contours can be filled, outlined, or used for further geometric analysis depending on application requirements.
Industrial Applications and Challenges
Manufacturing and Quality Control
Computer vision finds extensive application in manufacturing environments. Conveyor belt systems benefit from automated counting and quality inspection, reducing human error and increasing throughput. Bottle counting, product sorting, and defect detection represent common industrial use cases.
However, industrial applications present unique challenges. Transparent or reflective objects may be difficult to detect consistently. Empty bottles against white backgrounds pose detection challenges due to low contrast. Environmental factors like lighting changes, vibrations, or dust can affect system performance.
Edge Cases and Limitations
Current object detection and tracking systems have notable limitations. High-speed movement can break tracking algorithms when objects move too far between consecutive frames. Overlapping objects may be counted as single entities, while partially occluded objects might not be detected at all.
Frame rate considerations significantly impact tracking accuracy. Systems designed for 30 fps videos may fail with higher frame rates where objects move greater distances between frames. Similarly, very slow frame rates might miss rapid movements or brief object appearances.
Aerial and Specialized Applications
Standard YOLO models trained on ground-level imagery may perform poorly with aerial footage. Drone-based applications for livestock counting, traffic monitoring from above, or agricultural analysis require specialized models trained on aerial datasets.
Infrastructure inspection represents another specialized application. Crack detection in pipelines, bridge inspection, or building maintenance can benefit from computer vision, though these applications often require domain-specific training data and specialized preprocessing techniques.
Performance Optimization and Real-World Deployment
Model Selection and Optimization
Choosing appropriate models involves balancing accuracy, speed, and computational requirements. Nano models provide fast inference suitable for real-time applications but may sacrifice accuracy. Larger models offer higher precision at increased computational cost.
Real-world deployment often requires optimization techniques like model quantization, pruning, or specialized hardware acceleration. Edge computing devices may benefit from lightweight models, while cloud-based systems can utilize more sophisticated models with higher accuracy.
Saving and Post-Processing
Production systems typically require saving processed videos for later analysis or archival purposes. OpenCV provides comprehensive video writing capabilities with configurable codecs, frame rates, and quality settings.
# Video saving configuration
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = 30
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter('output_annotated.mp4', fourcc, fps, (width, height))
# During processing loop
out.write(annotated_frame)
# Cleanup
out.release()System Integration and APIs
Production computer vision systems often integrate with larger software ecosystems through APIs, databases, or message queues. Real-time alerting, data logging, and integration with existing business systems require careful architectural planning.
Future Directions and Advanced Topics
Emerging Technologies
Computer vision continues evolving with new architectures and training techniques. Vision transformers, attention mechanisms, and multi-modal learning represent active research areas with practical implications for future applications.
Real-time processing capabilities continue improving with specialized hardware like neural processing units (NPUs) and optimized inference engines. These advances enable more sophisticated algorithms to run on edge devices.
Specialized Applications
Domain-specific applications continue expanding computer vision's reach. Medical imaging, autonomous vehicles, augmented reality, and robotics each present unique challenges and opportunities for computer vision applications.
The integration of computer vision with other AI technologies like natural language processing and robotics creates new possibilities for intelligent systems that can perceive, understand, and interact with their environments.
Full implementation video
Conclusion
This comprehensive exploration of computer vision applications demonstrates the practical implementation of modern detection, tracking, and segmentation systems. From basic object detection to sophisticated tracking algorithms with trail visualization, these techniques provide the foundation for numerous real-world applications.
The progression from simple detection to complex segmentation illustrates the hierarchical nature of computer vision capabilities. Each level builds upon previous concepts while introducing new challenges and possibilities. Understanding these relationships enables developers to choose appropriate techniques for specific applications.
Industrial applications showcase both the potential and limitations of current technology. While automated counting and tracking systems provide significant value in manufacturing and monitoring scenarios, edge cases and environmental factors require careful consideration during system design and deployment.
The combination of OpenCV for image processing operations and pre-trained deep learning models like YOLO provides a powerful framework for developing practical computer vision applications. This hybrid approach leverages the strengths of both traditional computer vision techniques and modern neural networks.
As computer vision technology continues advancing, these fundamental concepts and implementation patterns will remain relevant while enabling increasingly sophisticated applications. The key to successful computer vision deployment lies in understanding both the capabilities and limitations of current technology while designing systems that can adapt to changing requirements and improving algorithms.
The future of computer vision promises even more exciting developments as hardware capabilities increase, training datasets grow larger and more diverse, and new algorithmic approaches emerge. These advances will enable applications we can barely imagine today while making current sophisticated techniques accessible to broader audiences through improved tools and frameworks.
Computer Vision PRO Bootcamp
Get access to all material from my Computer Vision Hands-on Bootcamp [PRO] here:
Excellent Post and learn again something new here