
NumPy: A tale of for-loops, slow code, and how one library changed the course of ML forever
Programming foundations for ML and Data Science



Imagine this.
You are in 2003. Python is cool but still kind of niche.
Data scientists are rare mythical creatures.
You just want to multiply two lists.
You write:
a = [1, 2, 3]
b = [4, 5, 6]
result = [a[i]*b[i] for i in range(len(a))] # Not efficientYou smile. You are proud.
But somewhere, your CPU is silently weeping.
Because this code… is slow.
Like dial-up-internet slow.
Like-waiting-for-your-crush-to-text-back slow.
And then came NumPy
With the elegance of a mathematician and the power of C/C++,
NumPy strolled in and said: “You shall not loop!”
So what is NumPy? It is a library in Python. Introduced in early 2000s (based on Numeric and Numarray)
NumPy was built for speed, vectorization, and efficiency.
It was Python’s glow-up moment. Suddenly, Python could talk math like a native speaker.
Here is what NumPy brought to the scene:
✅ Multi-dimensional arrays (ndarray)
✅ Vectorized operations (bye-bye for-loops 👋)
✅ Linear algebra, stats, broadcasting
✅ The foundation for libraries like Pandas, Scikit-learn, and even early TensorFlow
And most of the heavy lifting?
Done by C and C++ under the hood.
Python stayed readable.
NumPy made it fast.

Python lists had the following issues

NumPy in action
Let us see the code snippets for some basic operations using NumPy arrays.
Array creation and operations? Easy
import numpy as np
a = np.array([1, 2, 3]) # Now we're talking
b = np.array([[1, 2], [3, 4]]) # 2D like your favorite matrix
a + 10 # [11 12 13] - broadcasting wizardry
a * 2 # [2 4 6] - strong
np.sqrt(a) # [1.0, 1.41, 1.73] - enlightenedIndexing? Smooth
a[0] # first element
b[0, 1] # row 0, column 1Reshaping? Done
c = np.arange(12).reshape(3, 4)Aggregation? Like a boss
c.sum(axis=0) # column-wise sum
c.mean(axis=1) # row-wise meanAll good. Can we quantify how much better is NumPy compared to Python lists?
Speed comparison: Python lists vs NumPy arrays
Let us say you want to multiply TWO ARRAYS of a 100 million numbers.
Just a simple, innocent element-wise multiplication.
Nothing fancy. Should take only a second, right?
Here is how to multiply two giant arrays
import time
# Define the number of elements
n = 100_000_000 # 100 million length
# Create two Python lists with values 0 to 999999
a = list(range(n))
b = list(range(n))
# Start timing
start_time = time.time()
# Perform element-wise multiplication using a for-loop
result = [a[i] * b[i] for i in range(len(a))]
# End timing
end_time = time.time()
# Display results
print(f"Total time taken with Python lists: {end_time - start_time:.4f} seconds")Time taken:
Enough to make a cup of tea, bake banana bread, finish a Netflix episode, and revisit your life decisions.
CPU status:
“Please… have mercy.”
You:
Watching your fan spin like a helicopter and wondering if it is morally wrong to still be using for-loops.
This code took only about 10.65 seconds in reality. But same operation using NumPy arrays took only 0.38 seconds.
Here is what NumPy does
import time
import numpy as np
# Define the number of elements
n = 100_000_000 # 10 million length
# Create two NumPy arrays with values 0 to 999999
a = np.arange(n)
b = np.arange(n)
# Start timing
start_time = time.time()
# Perform element-wise multiplication using NumPy
result = a * b
# End timing
end_time = time.time()
# Display results
print(f"Total time taken with NumPy arrays: {end_time - start_time:.4f} seconds")Boom! That is it.
Time taken:
Done before you even hit "Enter". (Just 0.38 seconds to be precise)
CPU status:
“Cool. What’s next?”
You:
Feeling like a wizard. Whispering "np.dot, my old friend…” into the terminal.

Let us compare Python lists v/s NumPy for matrix multiplication
Let us compare the speeds for multiplication of matrices of different sizes. We will try with matrices of dimensions 10x10, 100x100 and 1000x1000. Here is the code. I will show you the results below the code.
import time
import numpy as np
import matplotlib.pyplot as plt
# Define matrix sizes to test
sizes = [10, 100, 1000]
list_times = []
numpy_times = []
def multiply_lists(n):
# Create matrices A and B with random values using lists
A = [[1 for _ in range(n)] for _ in range(n)]
B = [[1 for _ in range(n)] for _ in range(n)]
C = [[0 for _ in range(n)] for _ in range(n)]
start = time.time()
for i in range(n):
for j in range(n):
for k in range(n):
C[i][j] += A[i][k] * B[k][j]
end = time.time()
return end - start
def multiply_numpy(n):
A = np.ones((n, n))
B = np.ones((n, n))
start = time.time()
C = A @ B # Matrix multiplication
end = time.time()
return end - start
# Run benchmarks
for n in sizes:
print(f"Running for size {n}x{n}...")
t_list = multiply_lists(n)
t_np = multiply_numpy(n)
list_times.append(t_list)
numpy_times.append(t_np)
# Plotting
plt.figure(figsize=(10,6))
plt.plot(sizes, list_times, marker='o', label='Python Lists', color='red')
plt.plot(sizes, numpy_times, marker='s', label='NumPy', color='green')
plt.xlabel('Matrix Size (n x n)')
plt.ylabel('Execution Time (seconds)')
plt.title('Matrix Multiplication: Python Lists vs NumPy')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()NumPy’s role in ML workflow
If you start working in ML/DS projects, you will inevitably use NumPy. Here is where you are most likely to encounter NumPy in the ML pipeline.
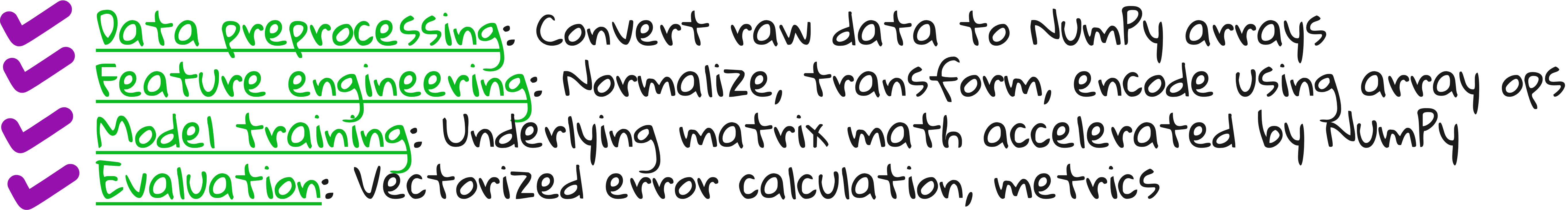
"If you know NumPy, you’re halfway to mastering machine learning in Python."
Limitations of NumPy
While NumPy is powerful, it also has some limitations:

NumPy mini challenge
Scenario:
You are given the marks of 5 students in 3 subjects as a 2D array.
Your task is to:
Calculate the average marks for each student.
Identify the top-performing student.
I recommend you to do this yourself. If you are struggling, you can refer to the code below.
import numpy as np
# Marks of 5 students in 3 subjects
marks = np.array([
[85, 90, 88], # Student 1
[70, 75, 80], # Student 2
[92, 88, 95], # Student 3
[60, 65, 70], # Student 4
[78, 85, 82] # Student 5
])
# 1. Calculate average marks for each student
average_marks = np.mean(marks, axis=1)
print("Average marks for each student:")
for i, avg in enumerate(average_marks, 1):
print(f"Student {i}: {avg:.2f}")
# 2. Identify the top-performing student
top_student_index = np.argmax(average_marks)
print(f"\n🏆 Top-performing student is Student {top_student_index + 1} with an average of {average_marks[top_student_index]:.2f}")Output:
Average marks for each student:
Student 1: 87.67
Student 2: 75.00
Student 3: 91.67
Student 4: 65.00
Student 5: 81.67
🏆 Top-performing student is Student 3 with an average of 91.67
Conclusion
NumPy didn’t just shape numerical computing. It raised a generation of powerful libraries.
Pandas, TensorFlow, PyTorch, JAX, CuPy they all owe their roots to NumPy’s simple idea:
"Make numerical computing in Python easy... and fast."
The viral image below says it all.

While the newer libraries have grown into strong, capable tools…
NumPy still walks quietly behind them — the master, the teacher, the origin.
So the next time you call .mean() or np.dot() without thinking, maybe whisper a little “thank you” to the OG.
NumPy didn’t just teach Python to compute.
It taught it how to grow.
Interested in learning ML from the foundations? Check this out
Lecture video
I have made a lecture video on this topic and hosted it on Vizuara’s YouTube channel. Do check this out. I hope you enjoy watching this lecture as much as I enjoyed making it.