
Neuralnetflix and chill: A tour of Keras, TensorFlow, and PyTorch
Programming foundations for ML


There is something magical about neural networks. You feed them a bunch of numbers, they do some matrix acrobatics behind the curtain, and suddenly they are classifying cats, predicting stock prices, and sometimes (accidentally) telling you that a blueberry muffin is a Chihuahua.
But the real question is - how do you build one?
And more importantly - with which framework?
In this post, we are going to explore three of the biggest names in deep learning - TensorFlow, Keras, and PyTorch - by doing what most tutorials never get around to: actually building and comparing models.

You will not just learn what these frameworks are. You will understand why they matter, when to use them, and how they operate under the hood.
Spoiler: One of them is basically the nervous system, another is the brain, and the third is the charming face that smiles at you and says, “let me handle this.”
Neural Networks: The ultimate shape-shifters
First, the nerdy but necessary part.
Neural networks are called universal function approximators. Which is just a fancy way of saying: give them enough neurons and they can imitate any function you want. Kind of like that friend who can mimic any professor’s voice in college.
Here is the idea in simple terms:
A neural network is just a bunch of layers stacked together. Each layer has neurons, and each neuron performs a linear transformation of the input (basically, multiplying by weights and adding biases). But linear transformations alone cannot do much. That is where activation functions come in.
Think of activation functions as the caffeine shot that turns bland matrix multiplication into actual decision-making.
Popular ones:
ReLU: Unbounded, and works well
Sigmoid: Used in binary classification, has a nice "S" shape.
Tanh: Always centered around zero.

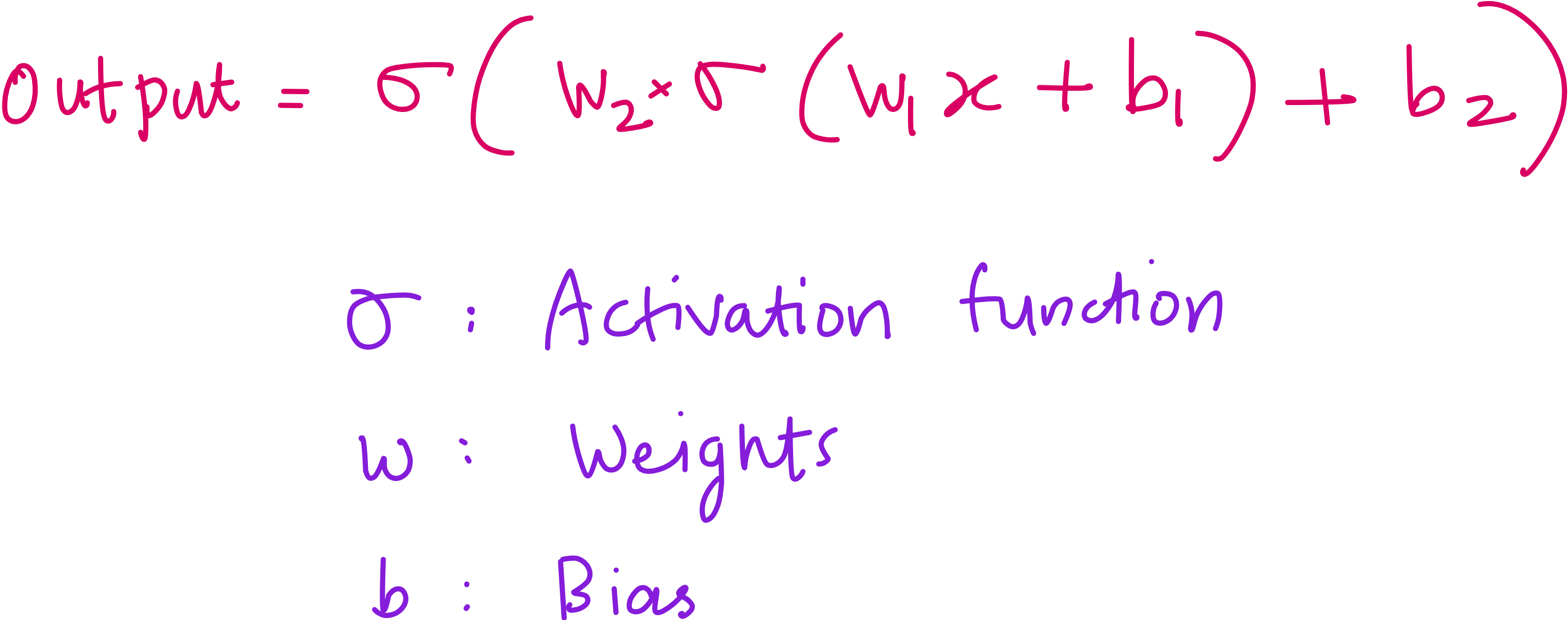
Deep vs shallow - size does matter
A neural network with a single hidden layer is technically “deep,” but in practice, depth = power.
Models like ResNet-101 have 101 layers and perform better because they can learn hierarchical features. You know, like how your brain first notices edges, then shapes, then the fact that you are looking at your ex in a group photo.
ML vs DL: What tool for what job?
Let us settle this once and for all.
If your data looks like a table, and your features are nice and clean (like square footage, number of bedrooms, year built), then classical machine learning is more than enough.
Run a regression. Build a random forest. Go make tea.
But if your data looks like this:
Pixels (images)
Words (text)
Sound waves (audio)
...then welcome to the deep learning.
Why? Because in such cases, the features are not obvious. A deep neural network is needed to learn those features during training.
You cannot give pixel values of a cat image to linear regression and expect it to scream “meow.”
The big three: Keras, TensorFlow, PyTorch
TensorFlow: The muscle
Built by Google Brain. Supports GPU acceleration. Huge ecosystem. Handles large-scale training.


But... writing raw TensorFlow code can feel like programming in Morse code. Powerful but verbose.
Keras: The charm
Keras is your clean, no-mess, intuitive API built on top of TensorFlow. It is like talking to the manager instead of navigating corporate bureaucracy.

Want to build a model? Sequential, Dense, fit, and done.
In short, Keras is a frontend with TensorFlow as the backend.
PyTorch: The craftsman
Developed by Facebook AI Research. Loved by researchers. More flexible, more transparent.


If Keras is like ordering a sandwich, PyTorch is like baking your own bread. You get control over every step. You also get to debug more, so bring coffee.
Key concepts in PyTorch

Hands-On: Building a Model in Keras
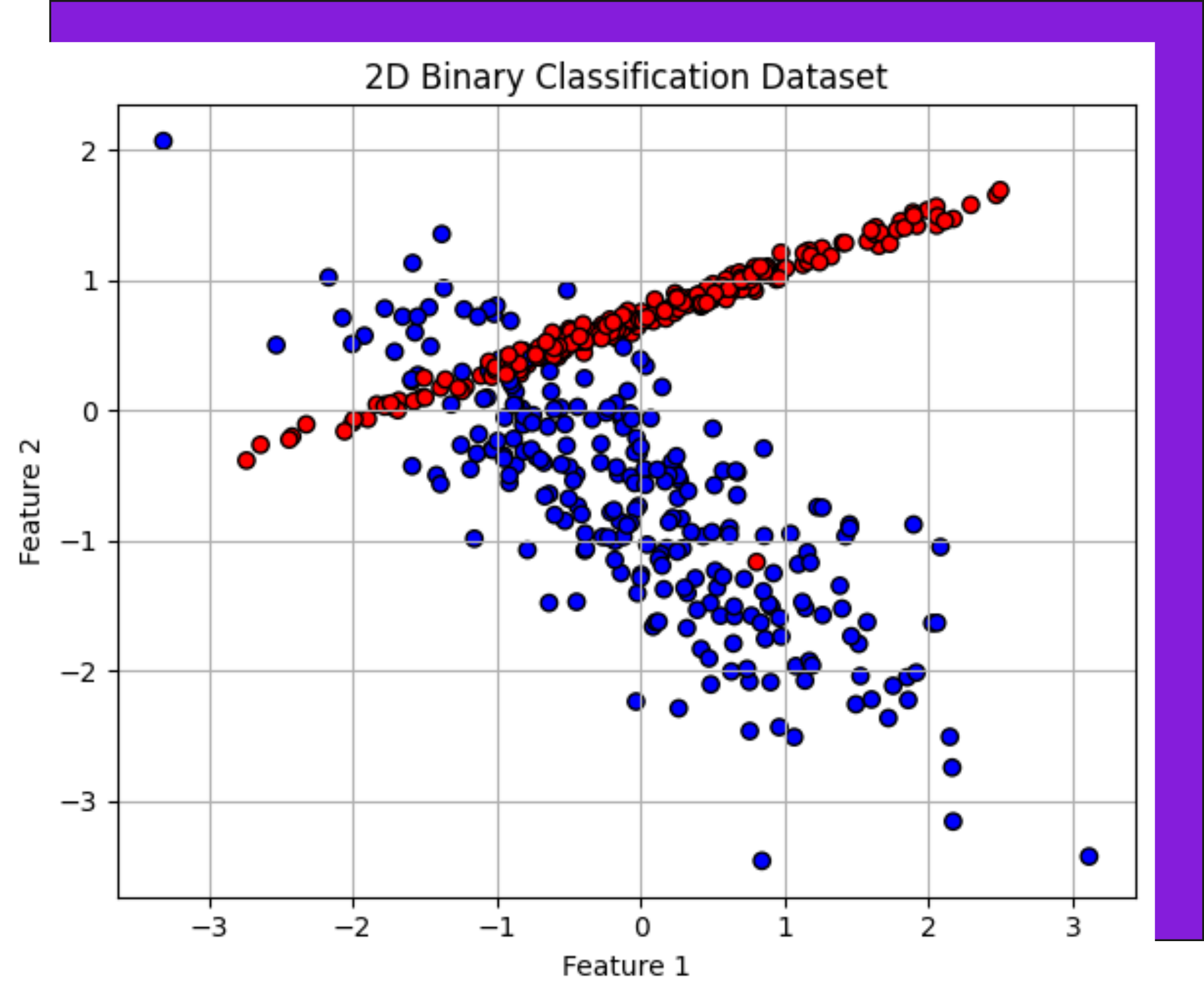
We use a 2D dataset with two features and binary labels. Think of it like dots on a graph - red vs blue.
We build a neural network with one hidden layer using tf.keras.Sequential. We use ReLU for the hidden layer and Sigmoid for the output. The optimizer? Adam (because who wants to deal with vanilla gradient descent anymore?).
model = tf.keras.Sequential([ tf.keras.layers.Dense(10, activation='relu', input_shape=(2,)), tf.keras.layers.Dense(1, activation='sigmoid') ])The results?
Training accuracy ~90%. Validation accuracy ~94%. Not bad for a model with two layers and zero drama.




The Same Model in PyTorch
Now we flip the switch. Same data. Same architecture. Different mindset.
In PyTorch, we define a custom class that extends nn.Module. We define a forward function. We write a manual training loop. Yes, manual. No model.fit.
class SimpleNN(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(2, 10) self.fc2 = nn.Linear(10, 1) def forward(self, x): x = F.relu(self.fc1(x)) return torch.sigmoid(self.fc2(x))You get to see everything - the optimizer steps, the loss computation, the gradient updates.
It is like cooking from scratch instead of using a meal kit.





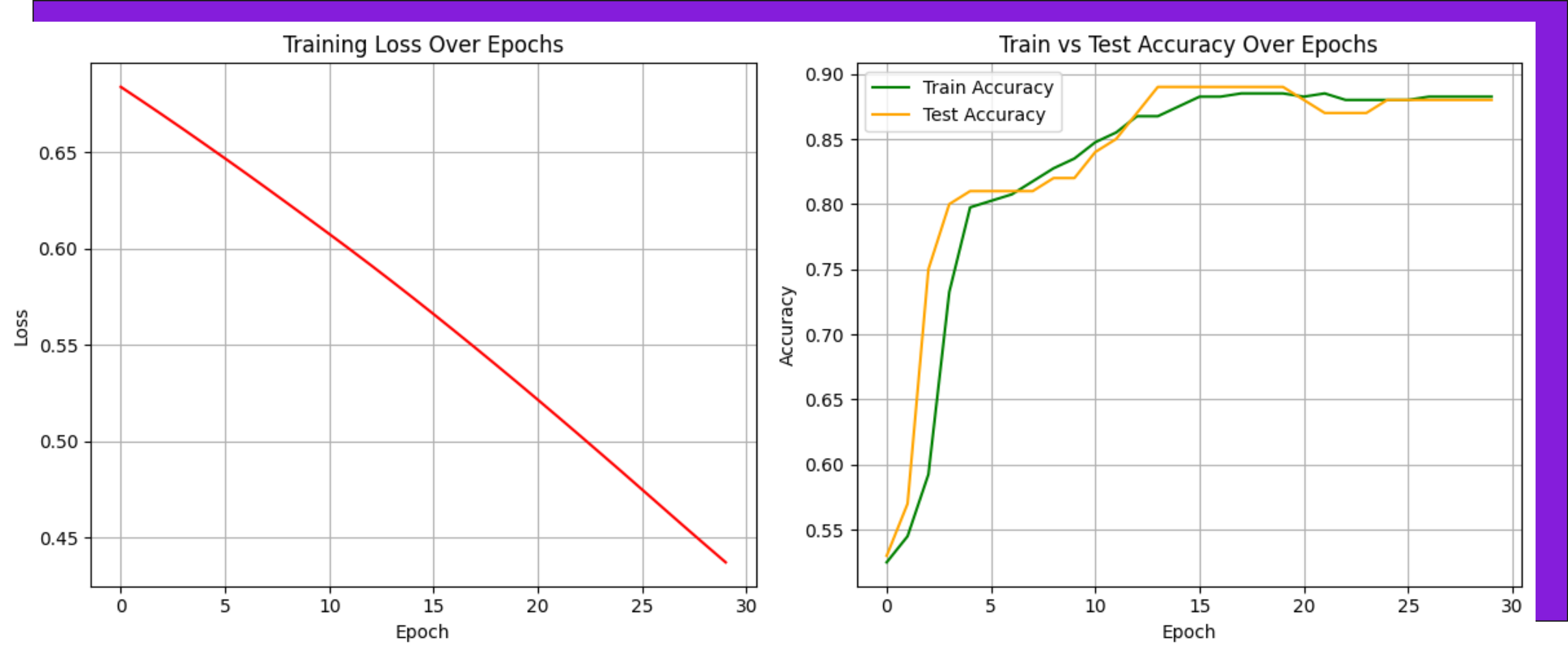
So... Which one should you use?

If you are just starting out - Keras is the best place to begin.
If you want to build custom models, write your own loss functions, or cry late at night because your gradients are exploding - PyTorch is your companion.
Final thoughts
There is no magic in machine learning - just a lot of matrix multiplication, activation functions, and clever abstractions.
This post showed you:
How to think about neural networks
When to use ML vs DL
How TensorFlow, Keras, and PyTorch differ
How to implement and compare both Keras and PyTorch models
You can now hold your own in a deep learning conversation without awkwardly smiling and nodding every time someone says "autograd."
Go ahead - open Google Colab, copy the code, and start experimenting.
Make mistakes. Read the errors. Train the model again. That is how you learn.
Until then - happy modeling.
Full lecture (YouTube)
Wish to learn ML foundations?
Check this out: https://vizuara.ai/self-paced-courses
Nice way of teaching 👍
I really loved the way it is written… very easy to understand, very relatable especially the crying at night debugging 😂 A piece of unique writing 👍🏻