
Modular Code is Like LEGO: Build, Break, Rebuild-Piece by Piece
Just like LEGO lets you build complex models from simple blocks, modular ML code empowers you to scale, debug, and upgrade without starting from scratch.

Table of Contents
Understanding Monolithic Scripts and Why They’re Bad
Debugging Walls of Text
Designing Modular ML Code
Recommended Folder Structure
YAML Configuration Files
Test-Driven Development (TDD) for ML
Summary
1. Understanding Monolithic Scripts and Why They’re Bad
Monolithic scripts are single, dense Python files or Jupyter notebooks that attempt to handle every aspect of an ML project in one go. This includes data loading, preprocessing, model training, evaluation, and sometimes even deployment. While this approach may appear convenient for small experiments or quick demos, it quickly becomes an obstacle in real-world ML development.
Why Are They Problematic?
Lack of scalability: When everything is embedded in one file, scaling your solution or integrating new features requires significant rewrites.
Hard to collaborate: Multiple developers working on a monolithic script inevitably step on each other’s toes.
Difficult to test and debug: When something breaks, it’s unclear where the error originates.
Impedes reuse: Useful functions or components cannot be easily reused in other projects.
Real-World Project Example

At Netflix, machine learning plays a crucial role in powering recommendations, personalizing thumbnails, detecting fraud, and optimizing video streaming. Now imagine if all these systems were built into a single, monolithic Python script, every data pipeline, model training step, and UI integration written in one file. If the recommendation model needed retraining or if the fraud detection pipeline needed debugging, engineers would have to risk breaking the entire system. That’s clearly not scalable, especially with hundreds of millions of users and constant A/B testing. Instead, each ML system is modularized into independent services with reusable components like a FeatureStore for managing input features, separate model serving APIs, and distinct retraining pipelines that can be monitored, upgraded, and tested in isolation.
Even in smaller companies or early-stage startups, teams now follow a modular architecture to build ML-powered features. For instance, a team building a churn prediction model for a SaaS product would separate out data extraction (ETL pipelines), feature engineering scripts, model training code, and deployment logic into different modules or folders. This separation allows data engineers, ML scientists, and DevOps to work concurrently without stepping on each other’s toes. If the model needs improvement, they don’t touch the deployment logic. If new data sources are added, the training pipeline doesn’t have to be rewritten. Whether you’re Netflix or a startup, modularity keeps things agile, maintainable, and ready for scale.
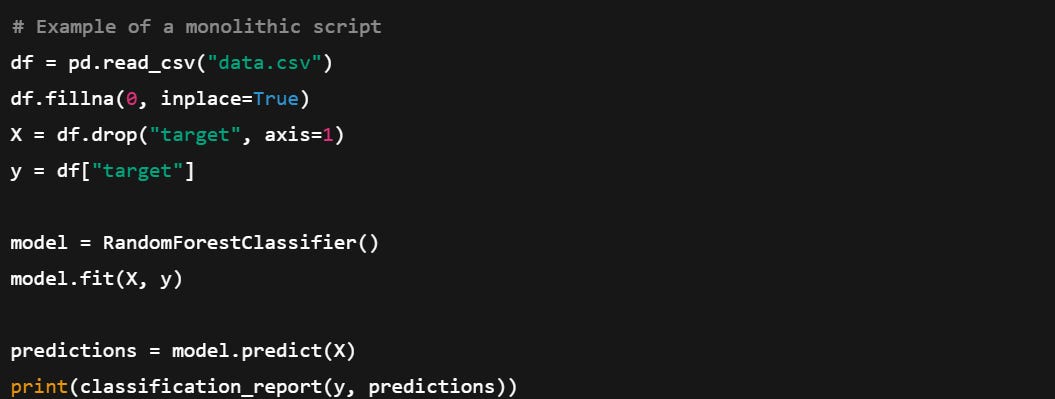
This is readable at first glance but tightly coupled, fragile, and unsuitable for team environments.
2. Debugging Walls of Text
As ML projects evolve, early notebooks or scripts tend to grow into long, linear blocks of code with minimal structure. These so-called "walls of text" bundle together unrelated concerns, data processing, model logic, visualizations, and metrics into a single, unreadable file.
The Core Issue
Such scripts are almost impossible to debug. A change in the data cleaning logic might silently affect model accuracy 300 lines later. Without modular checkpoints or logging, tracking down issues becomes frustrating and time-consuming.
Best Practices for Debugging
Use functions: Break the code into discrete tasks e.g.,
clean_data(),split_data(),train_model(),evaluate_model().Leverage assertions and validations: Check the shapes, types, and ranges of data at key points.
Adopt logging: Print statements are limited. Logging provides a structured and timestamped way to trace problems.
Insert checkpoints: Save intermediate files or metrics so you can trace outputs without rerunning the entire pipeline.
Real-World Project Example
Consider a team at Uber working on its ETA prediction system (Estimated Time of Arrival). This system ingests real-time traffic data, rider and driver locations, historical trends, and even weather conditions to give accurate arrival estimates. Now imagine if all of that logic, data ingestion, preprocessing, model inference, map updates, and notifications, was bundled into a single, massive script. If the ETA suddenly became inaccurate, the debugging process would be chaotic: the engineer would have to scroll through thousands of lines of code, unsure where things went wrong or which component was responsible.
In reality, Uber engineers split each part into clean, testable modules: there's a service for traffic ingestion, one for feature engineering, another for model scoring, and a different one for pushing updates to the UI. This modular setup means if the predictions go off, they can quickly isolate and test the feature extraction or the model service without touching unrelated systems like UI rendering. It’s like flipping to a bookmarked section of a technical manual instead of flipping through random pages of a handwritten scroll. Clean module boundaries help teams debug faster, test better, and iterate confidently.
3. Designing Modular ML Code
Modular design refers to organizing code into small, self-contained units that handle specific tasks. This approach is the cornerstone of writing maintainable, scalable ML systems.
What Does Modular Code Look Like?
Functions: Small, testable blocks of logic like
def normalize(X): ...Modules: Separate files for each stage, such as
data_loader.py,model.py,metrics.pyPipelines: Composed of functions strung together in a logical sequence
Why It Matters
Improved readability: Clear boundaries help new developers understand your code quickly.
Maintainability: Changes in one module don't ripple across the entire project.
Testability: Functions and classes can be unit tested independently.
Reusability: Modular components can be reused in other projects with minimal change.
Real-World Project Example

Zebra Medical Vision, a health technology company specializing in radiology diagnostics, employs modular machine learning pipelines in its product architecture. The system is divided into distinct components such as image preprocessing, anomaly detection, report generation, and integration with PACS (Picture Archiving and Communication System). Each of these components is designed, developed, and maintained independently by dedicated teams.
For instance, if the chest X-ray model begins misclassifying certain anomalies, the engineering team can isolate and update only the anomaly detection module without affecting other parts of the system. The remaining modules, including preprocessing and reporting, continue to operate as intended. This modular approach allows for rapid updates, efficient debugging, and compliance with strict healthcare standards. It reflects the principle of component-based design, where each unit functions independently and can be replaced or upgraded without requiring changes to the entire system.
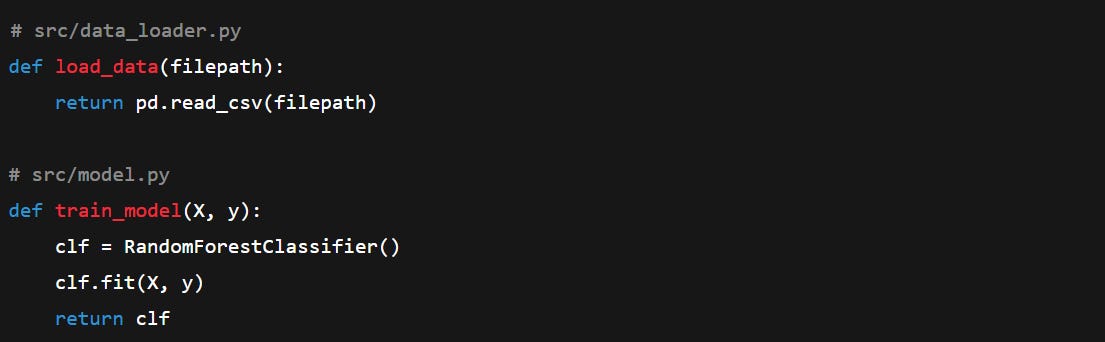
4. Recommended Folder Structure
The way your project is structured communicates a lot, both to your future self and to collaborators. A good folder structure separates concerns, enables easy navigation, and supports scaling.
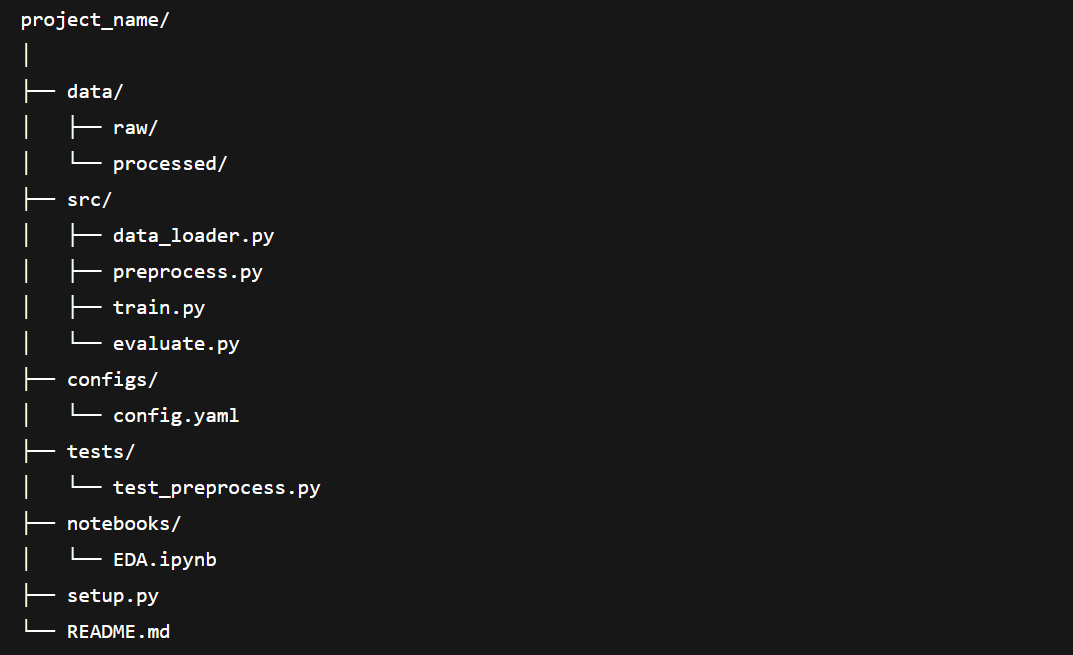
Explanation of Components
data/: Original and cleaned datasets
src/: Core project code (no Jupyter notebooks here)
configs/: YAML or JSON files with parameters
tests/: Unit tests for key components
notebooks/: For exploratory analysis, not production logic
setup.py: Allows local development and easy imports across modules
Real-World Project Example
Consider a team at NASA developing the flight software for a Mars rover. The software is composed of numerous components: navigation, sensor calibration, telemetry processing, fault detection, and communication protocols. Each module must be tested, verified, and updated independently. To manage this complexity, NASA engineers maintain a rigorously structured codebase, separating functionalities into distinct folders and submodules. For instance, if a bug is found in the rover’s orientation logic, engineers can directly navigate to the navigation module without sifting through unrelated files like thermal control or data compression. This organized layout ensures traceability, facilitates collaboration among distributed teams, and allows mission-critical fixes to be applied swiftly and safely.
5. YAML Configuration Files
Hardcoding parameters like learning rates, file paths, or batch sizes directly in your scripts limits flexibility and violates separation of concerns. This is where configuration files come in.
Why Use Configuration Files?
Easier experimentation: Swap models or hyperparameters without editing code
Improved reproducibility: Save and share config files to track experiment conditions
Better organization: Keep business logic separate from control variables
Preferred Formats
YAML (.yaml): Human-readable, supports comments
JSON (.json): Widely used, slightly more restrictive
Sample YAML File
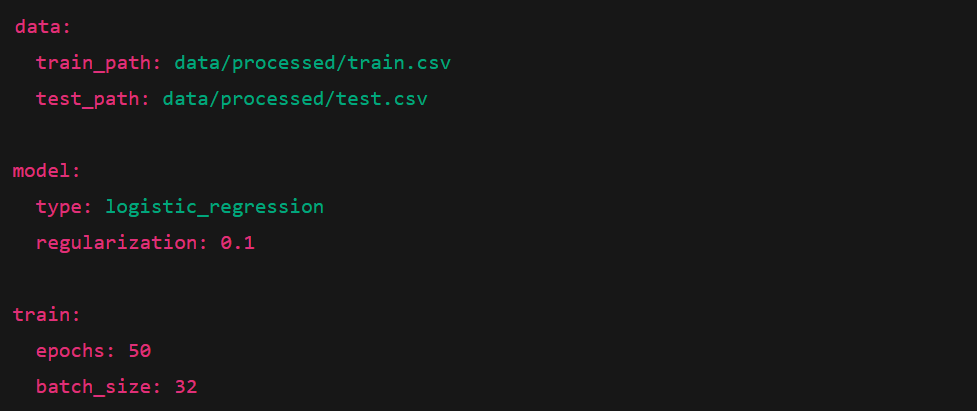
How to Load YAML in Python

6. Test-Driven Development (TDD) for ML
Test-driven development involves writing tests before you write the actual code. While it’s common in software engineering, it's still rare in machine learning but the benefits are enormous when building production systems.
Why TDD Matters in ML
Defines correctness: You clarify what the function should do before implementing it
Catches bugs early: Identify logical errors before running hours-long training jobs
Enables safe refactoring: Modify your code confidently knowing tests will flag breakage
What to Test in ML Projects
Data loaders: Are files loading with expected shape and types?
Preprocessors: Are missing values handled? Are encodings correct?
Model logic: Does training return a model? Does prediction output the right shape?
Metrics: Are your accuracy or loss functions implemented correctly?
Real-World Project Example

At Airbnb, the machine learning team works on dynamic pricing models that suggest optimal nightly rates for hosts based on seasonality, location, demand, and user preferences. To ensure the reliability of this complex pipeline, they adopted Test-Driven Development (TDD). For every new feature, like adjusting prices during local events or incorporating user reviews into the model, they first wrote tests to validate inputs, feature transformations, and output ranges. This approach made sure that when the model went live, there were no surprises like absurd price hikes or dips that could hurt host trust or platform revenue.
Think of TDD in this case like a checklist before launching a plane. You verify fuel, controls, radar, and weather conditions before takeoff. Similarly, Airbnb ensures all data streams, transformations, and business logic are functioning correctly before deploying the model. It’s not just about accuracy—it’s about safety, scale, and trust. Without those tests, one broken link in the pipeline could lead to massive pricing errors for thousands of listings overnight.
7. Summary
Avoid writing monolithic scripts by breaking workflows into modular functions and files for easier debugging and maintenance.
Use a well-defined folder structure and config files (YAML/JSON) to separate logic from parameters and improve reproducibility.
Apply Test-Driven Development (TDD) to validate components early, ensuring stability before full pipeline execution.
To understand these concepts with practical implementation please checkout the video