
MobileNet is awesome and you should respect it
The overlooked genius behind CNNs that fit in your pocket


In 2017, deep learning had already taken the world by storm.
-AlexNet had kicked off the revolution.
-VGG had shown that stacking simple 3x3 convolutions could beat complex architectures.
-ResNet solved the vanishing gradient problem with a beautifully simple skip connection.
-Inception models pushed parallelism and efficiency.
But there was still one massive blind spot.
None of these architectures worked well on edge devices.
You couldn’t really run VGG16 on a Raspberry Pi. You couldn’t deploy ResNet-50 inference in real-time on a mobile phone without draining the battery. And you definitely couldn’t imagine using these models inside IoT sensors.
This is where MobileNet enters the story.

Setting the stage: Why a lightweight model was necessary
Let’s rewind for a moment.
In our Computer Vision from Scratch course, we started by training a linear model on the five-flowers dataset: daisy, dandelion, rose, sunflower, and tulip. We saw disappointing results - 40 to 45% training accuracy and 35 to 40% validation accuracy.
Adding hidden layers didn't help much. We tried ReLU activations, batch normalization, dropout, and even early stopping. It brought us up to around 50-60% accuracy, but that was still far from what we needed.
Then we turned to transfer learning. We brought in ResNet-50 with pretrained weights and jumped straight to 80% validation accuracy and 100% training accuracy. But that came at a cost - the model was huge.
So we asked ourselves:
“Is there a way to get decent performance without burning memory and compute?”
Turns out, there is.
What is MobileNet?
MobileNet was proposed by Google in 2017 in a paper titled “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” It currently has over 32,000 citations.
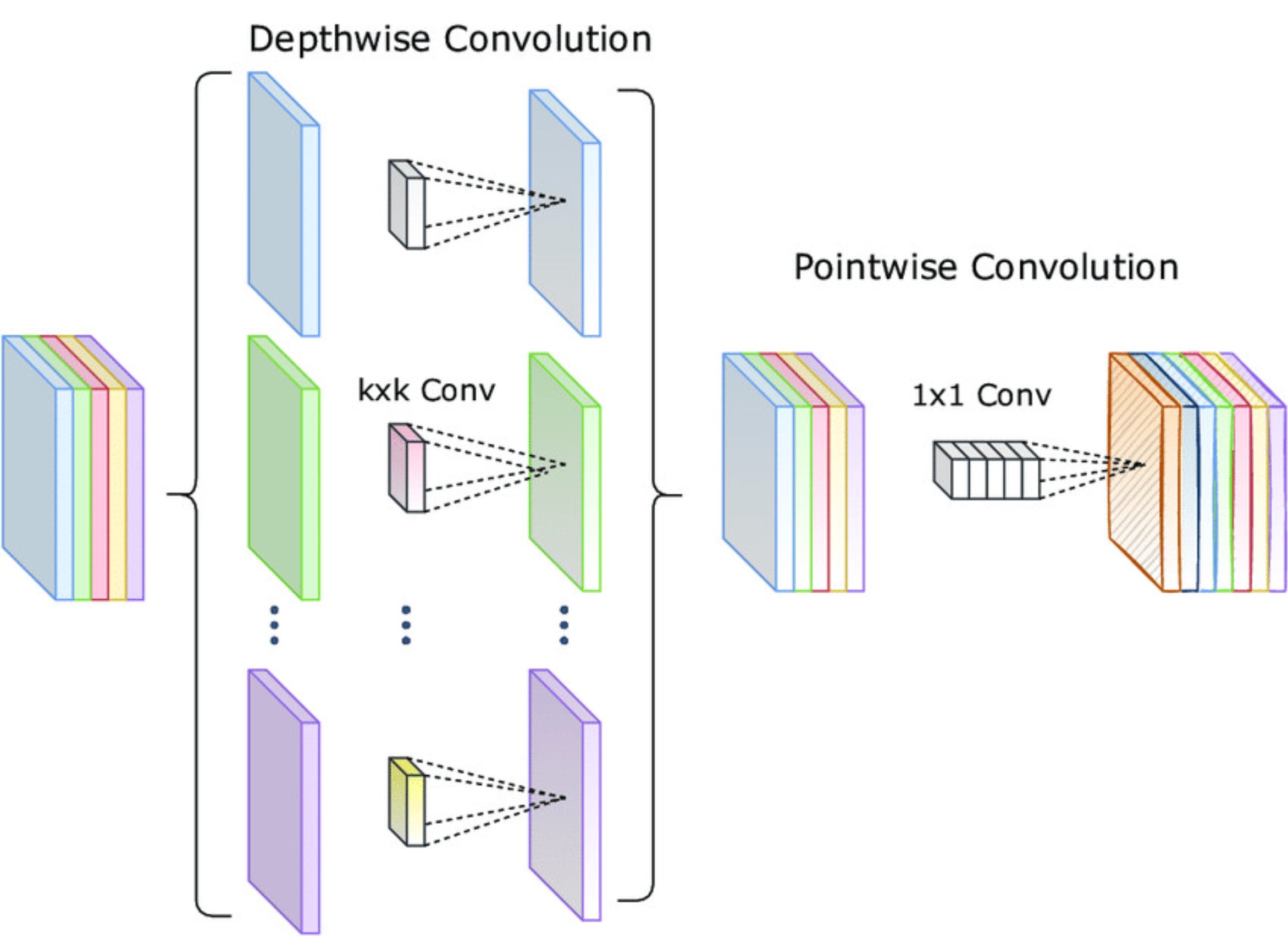
Its core idea is beautifully elegant and simple:
Instead of doing one big convolution over the entire input volume, split it into two cheaper operations:
Depthwise convolution
Applies a 3×3 filter to each input channel separately.Pointwise convolution
Applies a 1×1 filter to combine features across channels.
This two-step process is called a depthwise separable convolution.
How much does MobileNet shrink the parameters? Let’s do the math
Take a standard convolution:
Input: 32 channels
Filter size: 3×3
Output: 64 channels
Total parameters = 3×3×32×64 = 18,432
Now, use depthwise separable convolutions:
Depthwise: 32 filters of 3×3 = 288 parameters
Pointwise: 1×1×32×64 = 2,048 parameters
Total = 2,336 parameters
That’s nearly an 8x reduction in parameter count - just in one layer.
And this pattern repeats across the entire network.
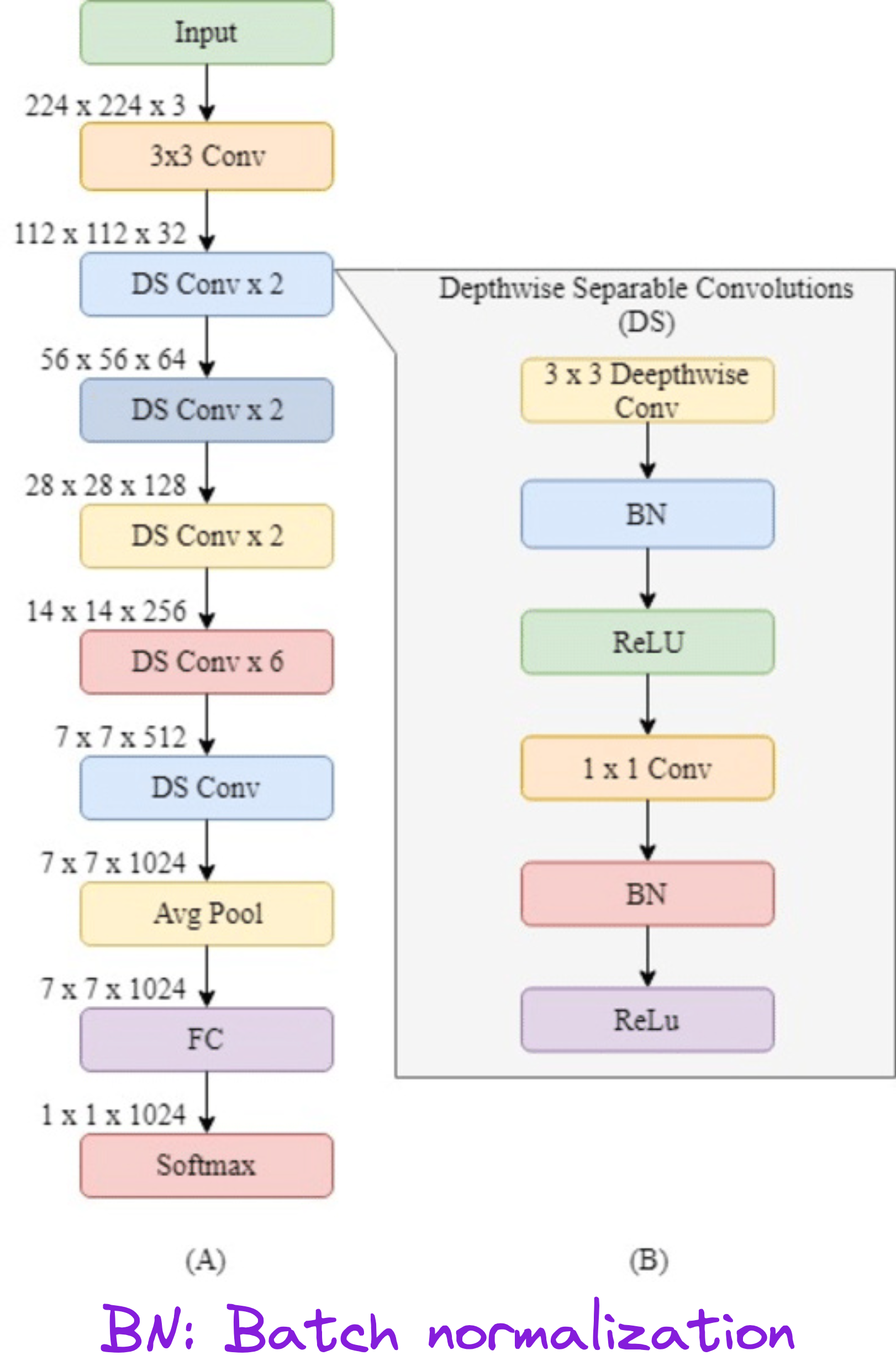
The whole architecture
The input to MobileNet is usually 224×224×3.
Each block in the network consists of:
A depthwise convolution
Followed by batch norm
Followed by ReLU
Then a pointwise convolution
Another batch norm
Another ReLU
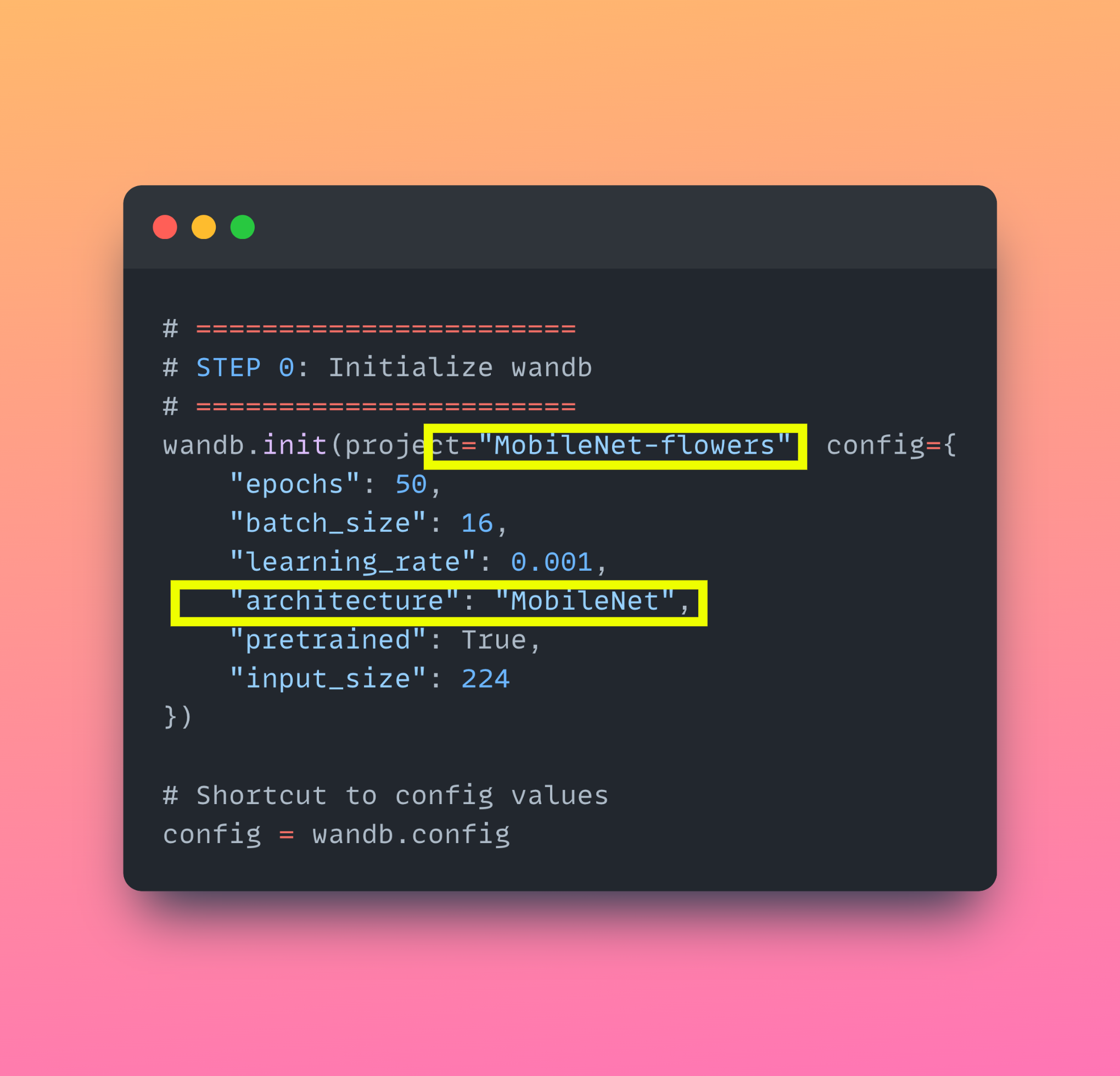
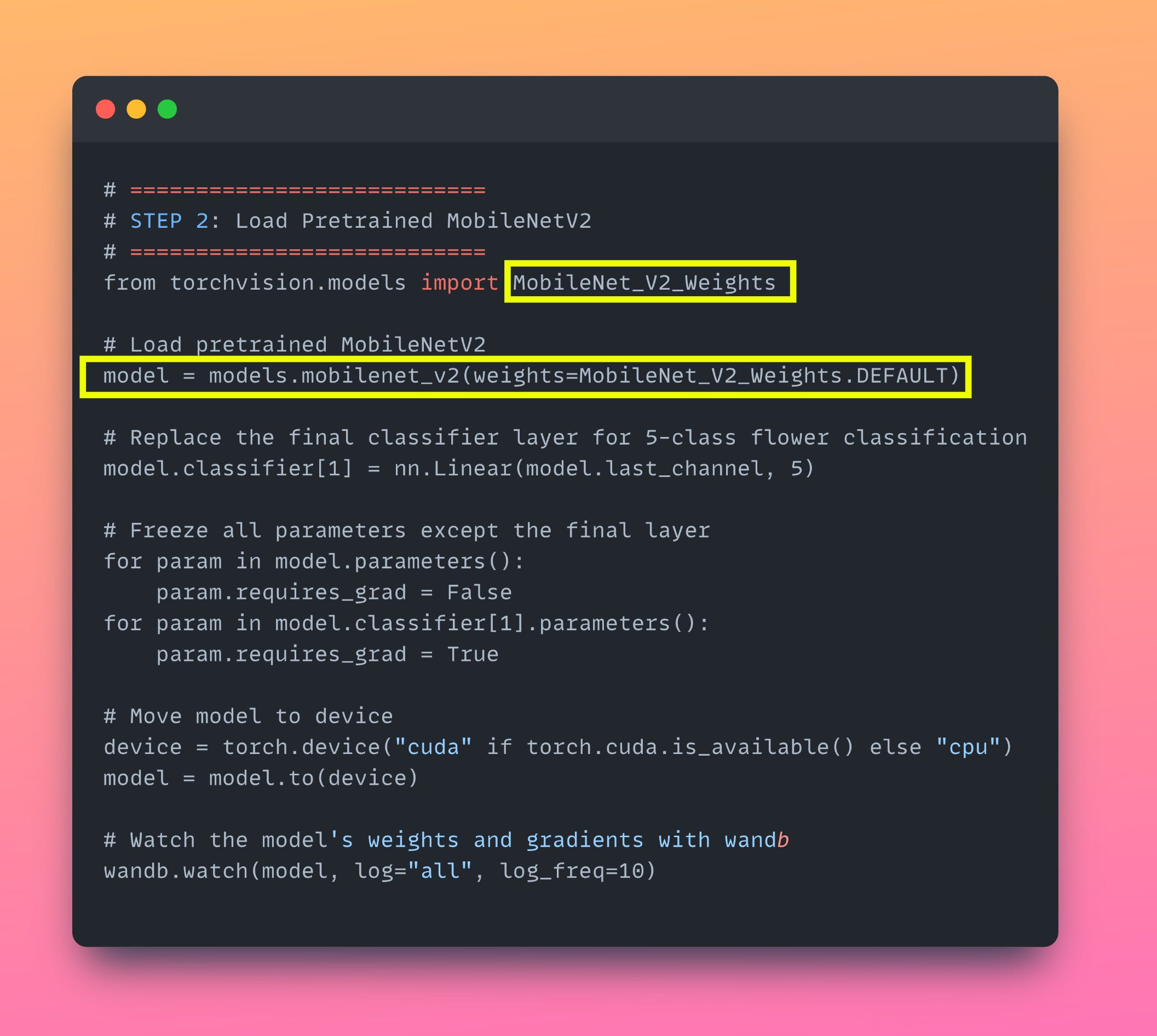
This module is repeated several times to construct the full MobileNetV1. The final layer is a fully connected softmax classifier. For ImageNet, it's a 1000-class output. In our case, we modified it to 5 classes for the flower dataset.
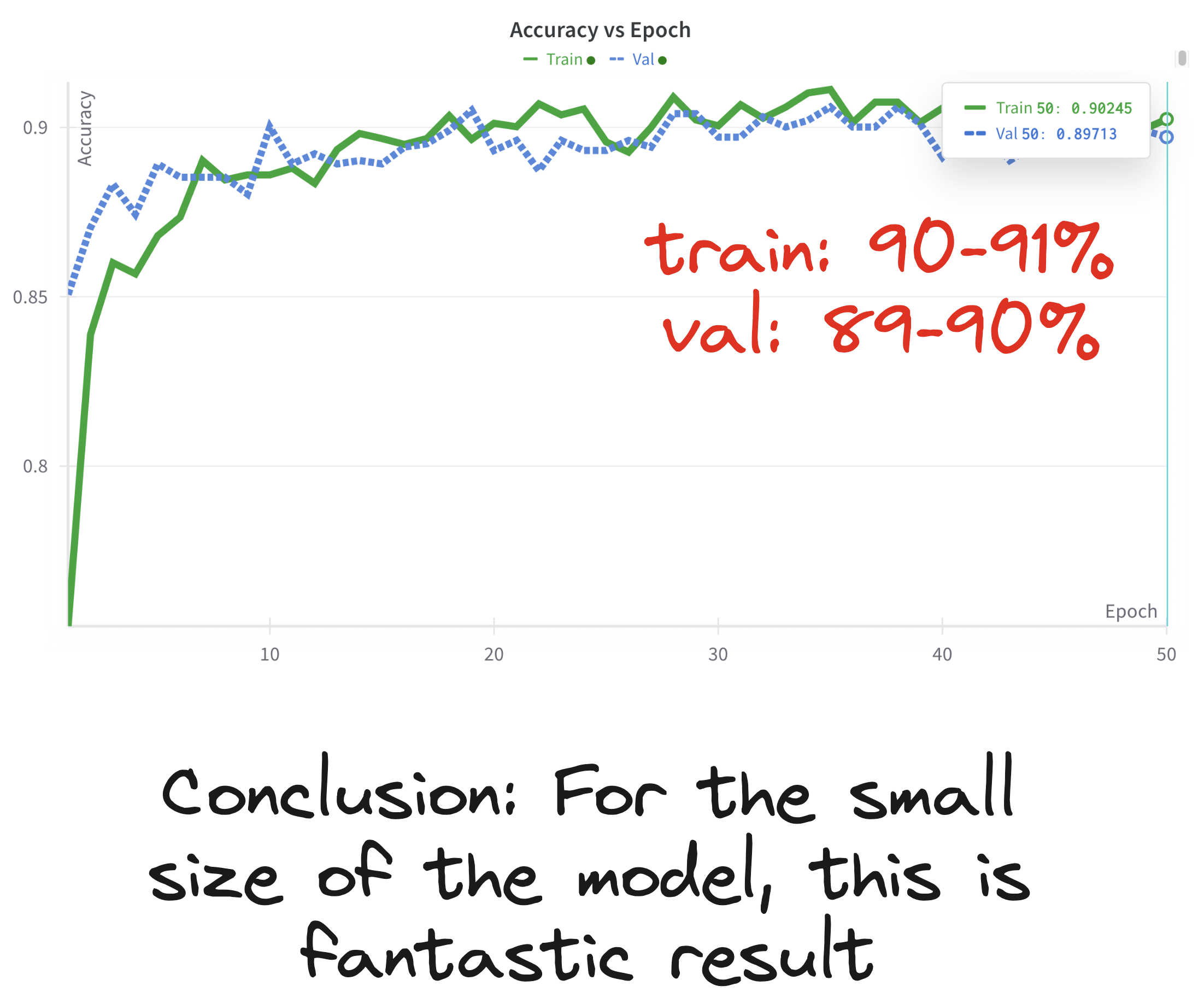
Results on our dataset
Here’s what we saw with MobileNetV2 (we loaded V2 weights by mistake, but the architecture and idea are the same):
Training Accuracy: ~91%
Validation Accuracy: ~89-90%
Model Size: ~16 MB
Parameters: ~4.2 million
MobileNet hits a sweet spot.
You get near-ResNet performance at less than 1/6th the size.
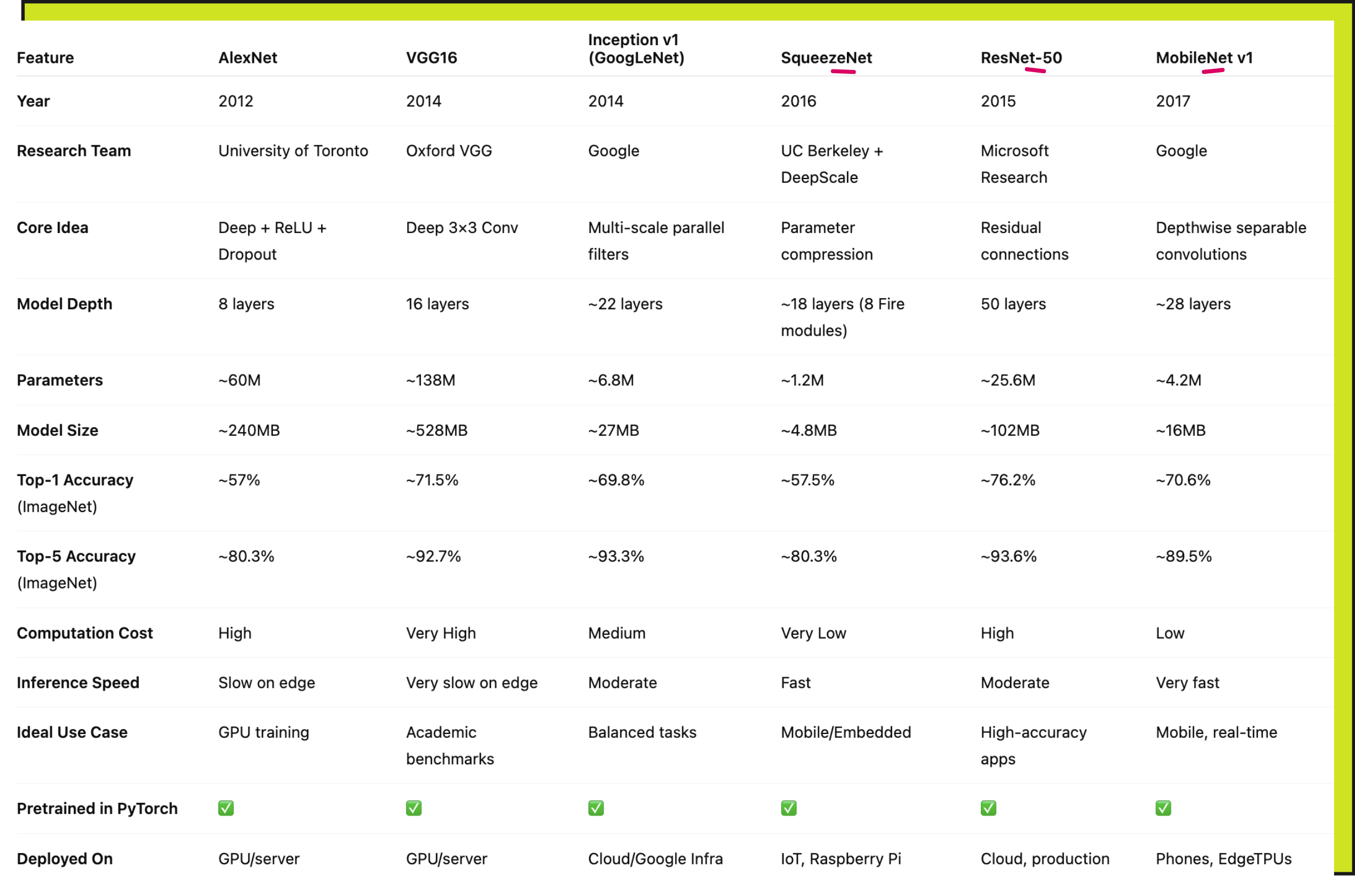
Here is a detailed comparison of models
Code [The relevant parts]
Result
Why this matters
We often get excited about the newest, flashiest models.
ViTs. ConvNeXt. EfficientNet.
All amazing models - no doubt.
But here’s the thing:
MobileNet solved a problem that was very real and very painful - efficient inference on constrained hardware.
That makes it incredibly relevant even today, especially if you're:
Building AI apps on smartphones
Running models on IoT sensors
Working with edge computing pipelines
Trying to compress models for deployment
So what is the takeaway?
MobileNet teaches us that architecture isn't just about accuracy.
It’s about tradeoffs.
It’s about engineering constraints.
It’s about designing models that solve real-world problems, not just beat benchmarks.
When you care about memory, latency, and deployment, MobileNet is still a rockstar.
If you're in AI and haven’t explored MobileNet yet, give it some love.
If you're teaching computer vision, include it in your curriculum.
And if you’re working on edge AI - start here.
P.S. We implemented MobileNetV2 on the 5-class flower dataset using PyTorch. Pretrained weights, Weights & Biases logging, Google Colab notebook - everything is available here: https://colab.research.google.com/drive/14mKeAoxXfmmYa1lfz3YB9kcnRPZH0_d4?usp=sharing
And as always, if you're serious about learning AI deeply - keep going.
We're just getting started.
YouTube lecture on MobileNet
Interested in learning AI/ML LIVE from us?
Check this out: https://vizuara.ai/live-ai-courses