
K-means: Pattern from chaos


K-means clustering is one of those marvels of data science that reminds you why you got into this field in the first place. It’s simple, powerful, and capable of transforming a chaotic pile of data points into neat, meaningful groupings. It’s like a digital Marie Kondo for your datasets, sparking joy with every well-defined cluster.
At its heart, K-means clustering is about finding natural groupings in data. Imagine plotting a bunch of points on a graph—say customer purchasing behaviors—and wondering, "Are there any patterns hiding in this mess?" K-means steps in to sort that out, grouping points into clusters based on their features. No labels, no instructions—just raw data revealing its secrets. That’s why it’s considered unsupervised learning.
What Makes K-Means Clustering Tick?
K-means doesn’t come in knowing the “correct” answer. It’s not like supervised learning, where you teach a model with labeled examples (like showing your email filter a collection of “spam” and “not spam” messages). Instead, K-means is the data detective—it analyzes the evidence, finds the patterns, and proposes a solution.
Here’s the K-means process in its essence:
Choose K Centroids
First, it picks K random points in the data to act as cluster centers, called centroids. Think of these as the gravitational hubs around which the clusters will form.Assign Points to Clusters
Every data point gets assigned to the nearest centroid. This is where the “means” part of K-means comes into play—it’s all about minimizing the distance between points and their assigned centroid.Recalculate Centroids
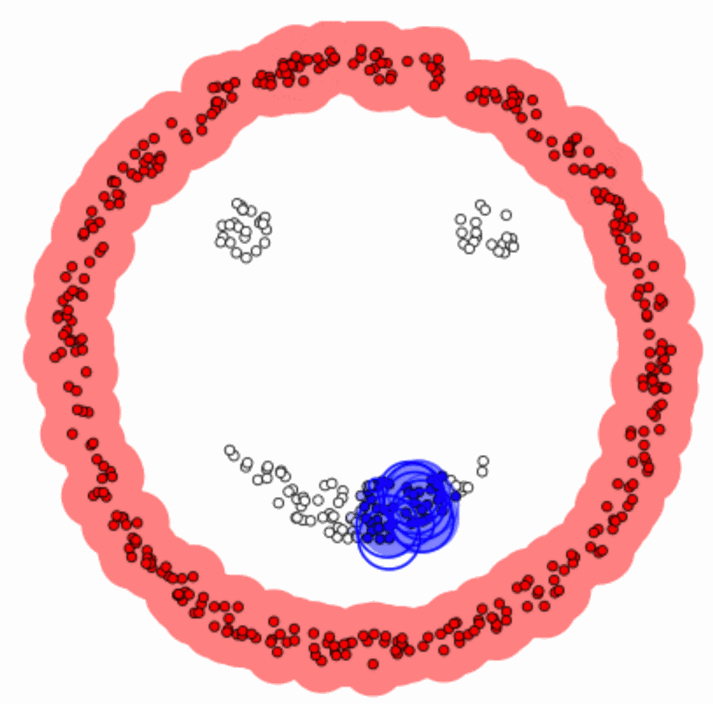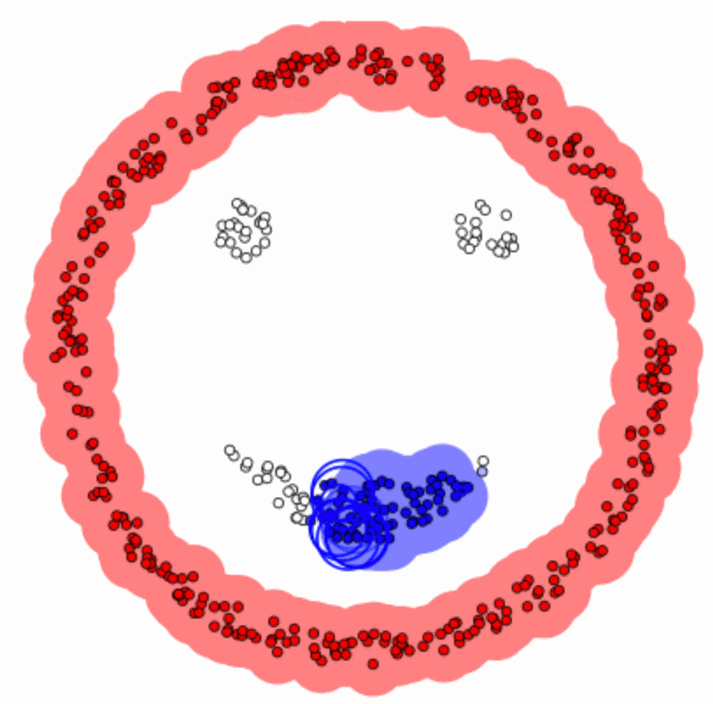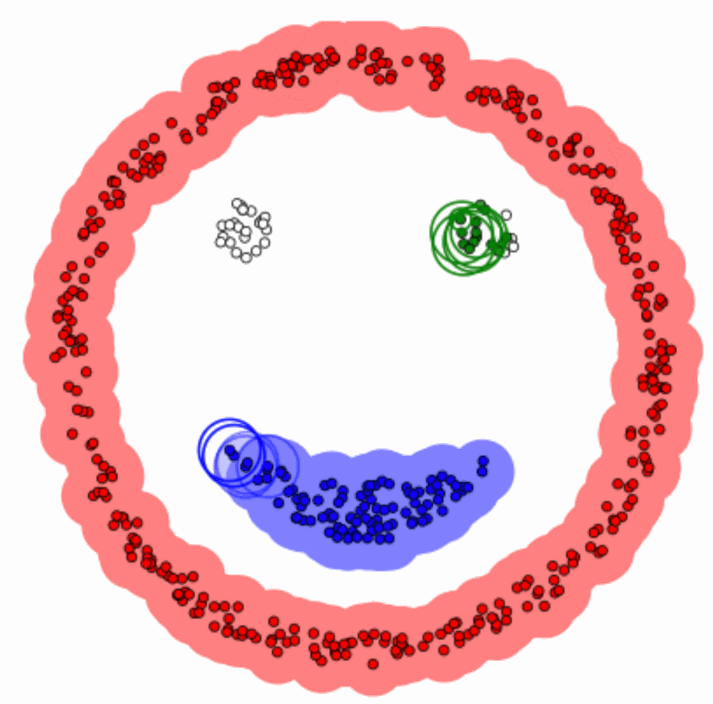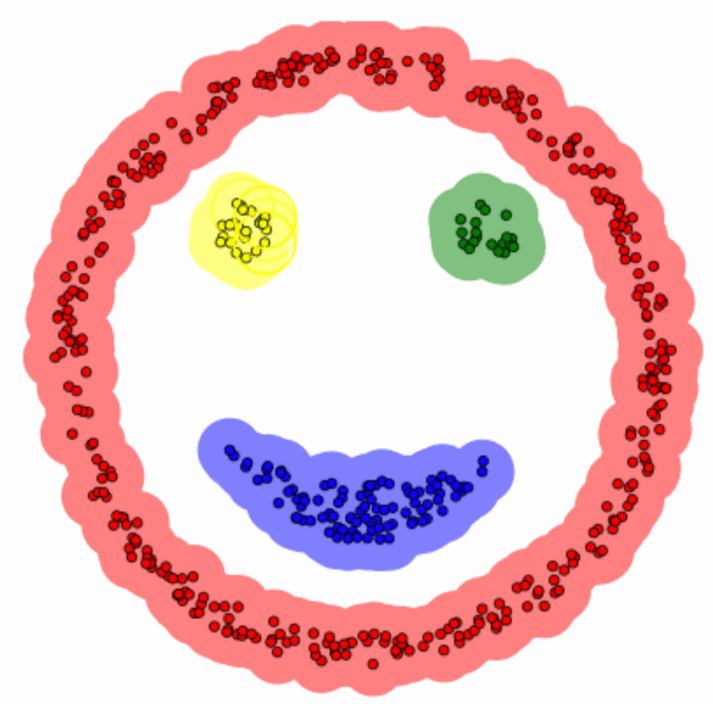
Once the points are grouped, K-means recalculates the centroids by taking the mean position of all the points in each cluster.Repeat Until Stability
This process continues—assign points, recalculate centroids—until the clusters stop shifting. Voilà, you’ve got your clusters!
The Magic and the Math
What makes K-means special is its combination of elegance and efficiency. The algorithm is quick to run and easy to implement, even if you’re just starting out in data science. And yet, despite its simplicity, it’s a workhorse for many practical applications:
Customer Segmentation: Grouping customers based on buying habits to tailor marketing strategies. (Ever wondered how Netflix knows exactly what kind of show you’ll binge next? Hint: clustering.)
Image Compression: Reducing the number of colors in an image while keeping it visually intact. Think of it as digital origami, folding complexity into something simple yet functional.
Anomaly Detection: Spotting outliers, whether they’re fraudulent transactions or manufacturing defects.
The Catch: Challenges of K-Means
K-means isn’t perfect, though. For one, it assumes clusters are spherical and evenly sized—great if your data fits that mold, but problematic if it doesn’t. Real-world data can be messy, and K-means isn’t always up for the chaos.
Another challenge? Choosing the right number of clusters (K). Pick too few, and you’ll miss important distinctions; pick too many, and your clusters lose meaning. Tools like the elbow method and silhouette analysis can help guide you, but sometimes it’s as much art as science.
Finally, K-means can struggle with large or diverse datasets. Outliers, overlapping clusters, and high-dimensional data can all trip it up. Yet, despite these challenges, it remains a go-to algorithm for many.
K-Means in Action
Want to see K-means in a practical setting? Picture a business trying to make sense of customer purchasing data. By running K-means, they could identify distinct customer segments—say, “frequent big spenders,” “occasional bargain hunters,” and “weekend browsers.” This segmentation allows for personalized marketing, targeted offers, and ultimately, happier customers.
Or consider an image compression task: K-means groups pixels with similar colors, reducing the overall number of colors while keeping the image’s essence intact. The result? A smaller file size without sacrificing quality. It’s like packing a suitcase for a weekend getaway—you only bring the essentials.
Learn More: From Theory to Code
If you’re ready to dive deeper, I recommend checking out a detailed lecture I’ve published on Vizuara’s YouTube channel. It walks you through the math behind K-means (solved by hand, for the brave souls who love equations) and its implementation from scratch in code. Watch it here:
.Final Thoughts
K-means clustering is a reminder of how simple ideas can lead to powerful insights. Whether you’re segmenting customers, compressing images, or just exploring data, it’s a tool worth having in your arsenal. Yes, it has its quirks—doesn’t everything?—but its ability to unlock hidden patterns in unlabeled data makes it indispensable.
So next time you’re staring at a messy dataset, give K-means a try. You might just uncover something extraordinary.