
Introduction to VLMs
Vision Language Models


Transformers changed how we process language. Vision Transformers changed how we process images. But the world does not speak in just pixels or just words. When you scroll through Instagram or open a scientific paper, you are not receiving a single modality of information. You are reading text while also seeing images, emotions, graphs, objects, and context. To teach machines to understand such multi-modal reality, we need a new class of models known as Vision Language Models.

In this article, I will explain what a Vision Language Model (VLM) is, how it works, why it is different from a simple Vision Transformer (ViT), what terms like early fusion, late fusion and joint embedding space really mean, and how models like CLIP became the foundation of modern multi-modal AI.
Why Vision Transformers Are Not Enough
In the previous lectures, we studied Vision Transformers. They divide an image into patches, embed those patches, and learn patterns using self-attention. This works beautifully for image classification tasks.
However, a Vision Transformer cannot understand a caption like “a happy dog running on the beach”. It can only see the image. It cannot process language. Similarly, a language model like BERT or GPT can understand the word “apple”, but it has never seen an image of an apple.
So we have two completely separate worlds:
Vision models that only understand images
Language models that only understand words
But in reality, both represent the same concept. If I show you the word “cat” or an image of a cat, your brain activates a similar idea. That is what VLMs try to achieve. They bring both images and text into the same meaning space.
The Core Idea – A Shared Embedding Space
The simplest way to understand a Vision Language Model is this:
Convert an image into a vector
Convert its matching caption into another vector
Make sure both vectors are close to each other in the embedding space
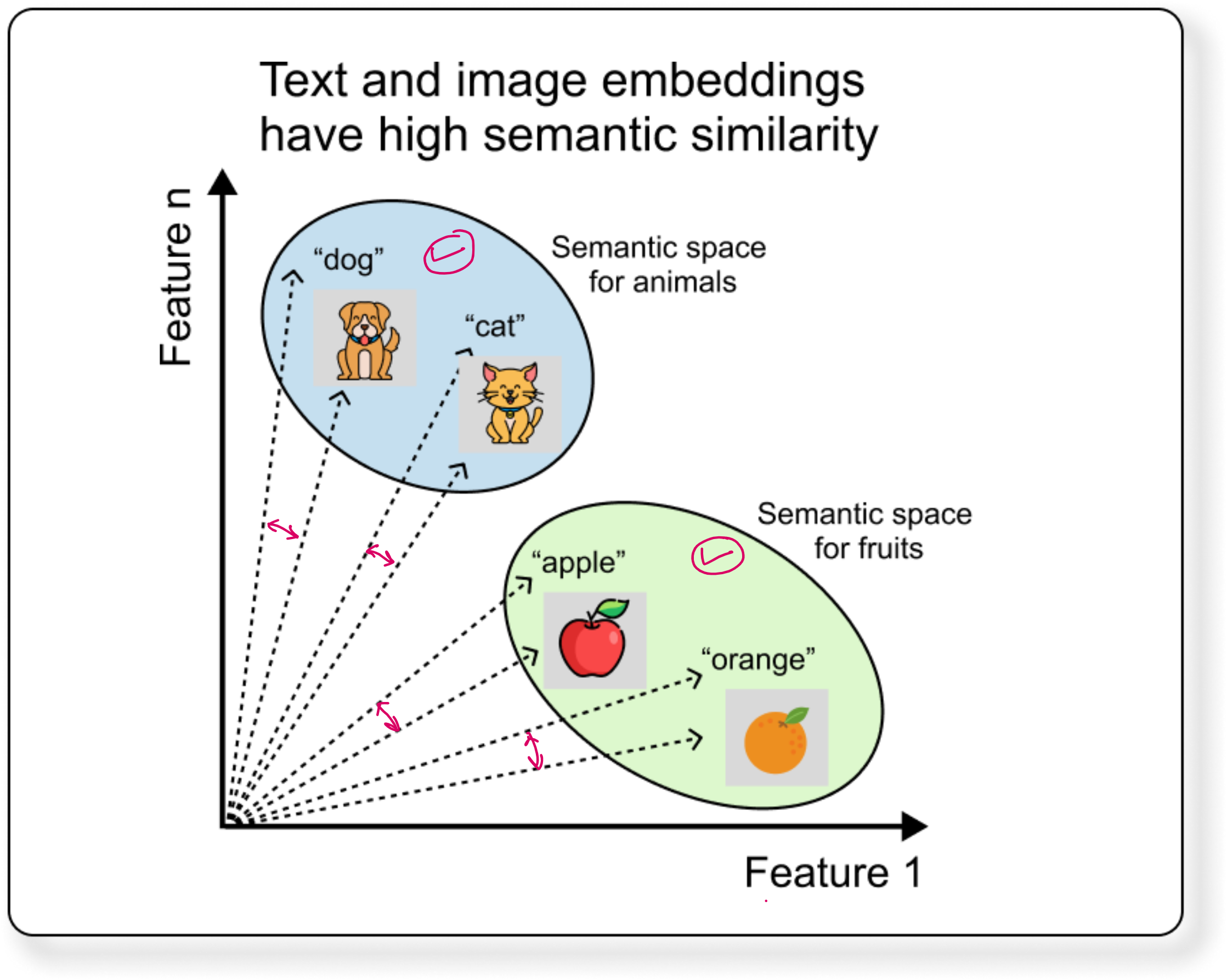
For example, the text “dog” and the image of a dog should have similar vector representations. The text “cat” and the image of a cat should also align. All such vectors are placed into a joint embedding space. In this space:
All animal-related vectors (dog, cat, lion) stay closer
All fruit-related vectors (apple, orange, mango) stay closer
This is exactly what CLIP, the famous model from OpenAI, does using a technique called contrastive learning.

How Does a VLM Work Internally?
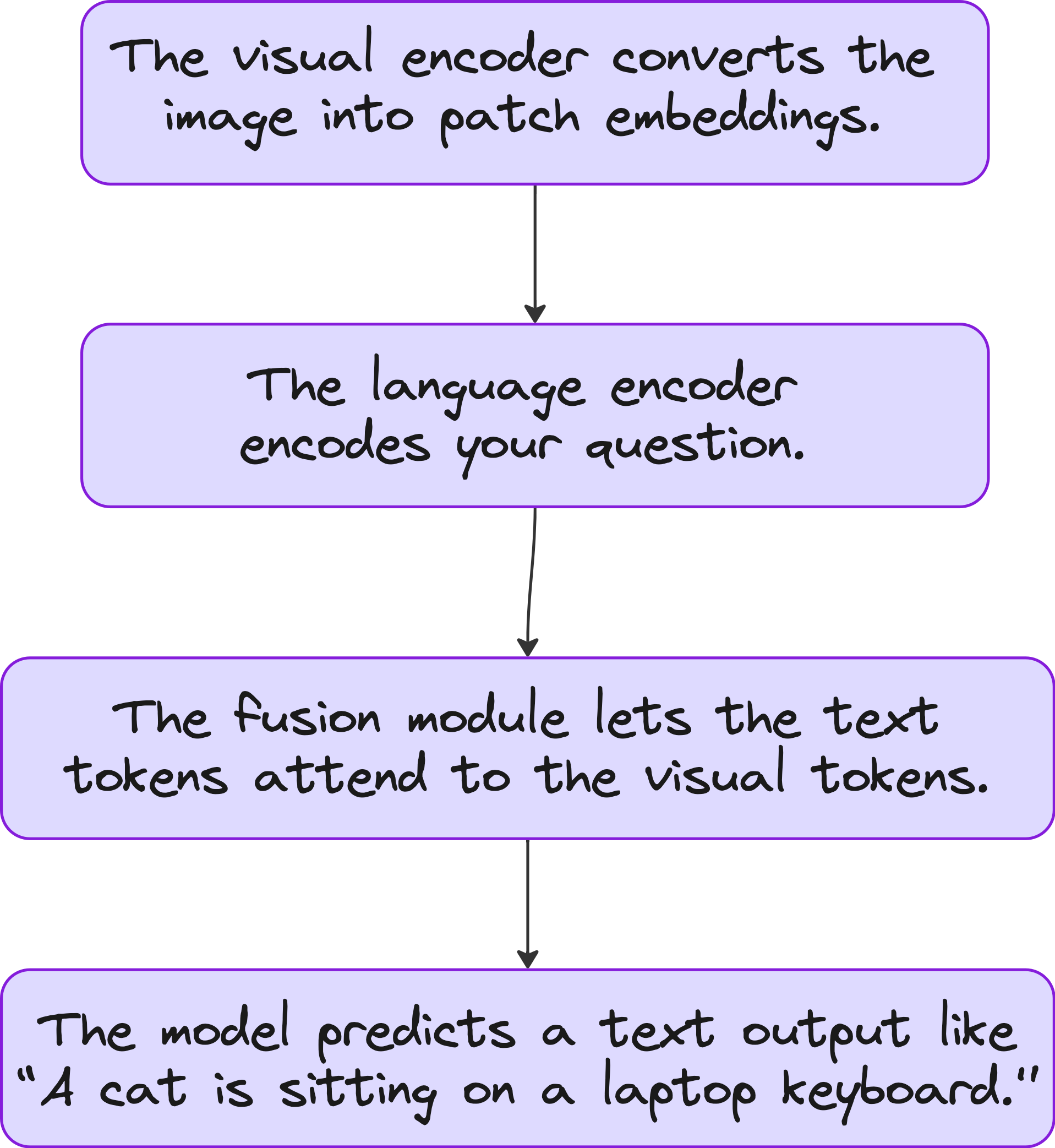
A vision language model has three major components:
1. Image Encoder
This converts the image into a vector. It can be:
A Vision Transformer (ViT) that uses image patches
A Convolutional Neural Network (CNN) that compresses the whole image into a single vector
2. Text Encoder
This converts the text or caption into a vector. It can be:
BERT like encoder without causal masking
GPT like decoder with causal attention
Any model that can map words into a meaningful embedding
3. Fusion or Alignment Module
This is where image and text features meet. There are three approaches:
Early Fusion: Concatenate image and text embeddings before sending them into a transformer
Late Fusion (used in CLIP): Image and text encoders work separately and are only compared at the loss level
Cross Attention Fusion (used in models like ViLBERT): Image attends to text tokens and text attends to image tokens
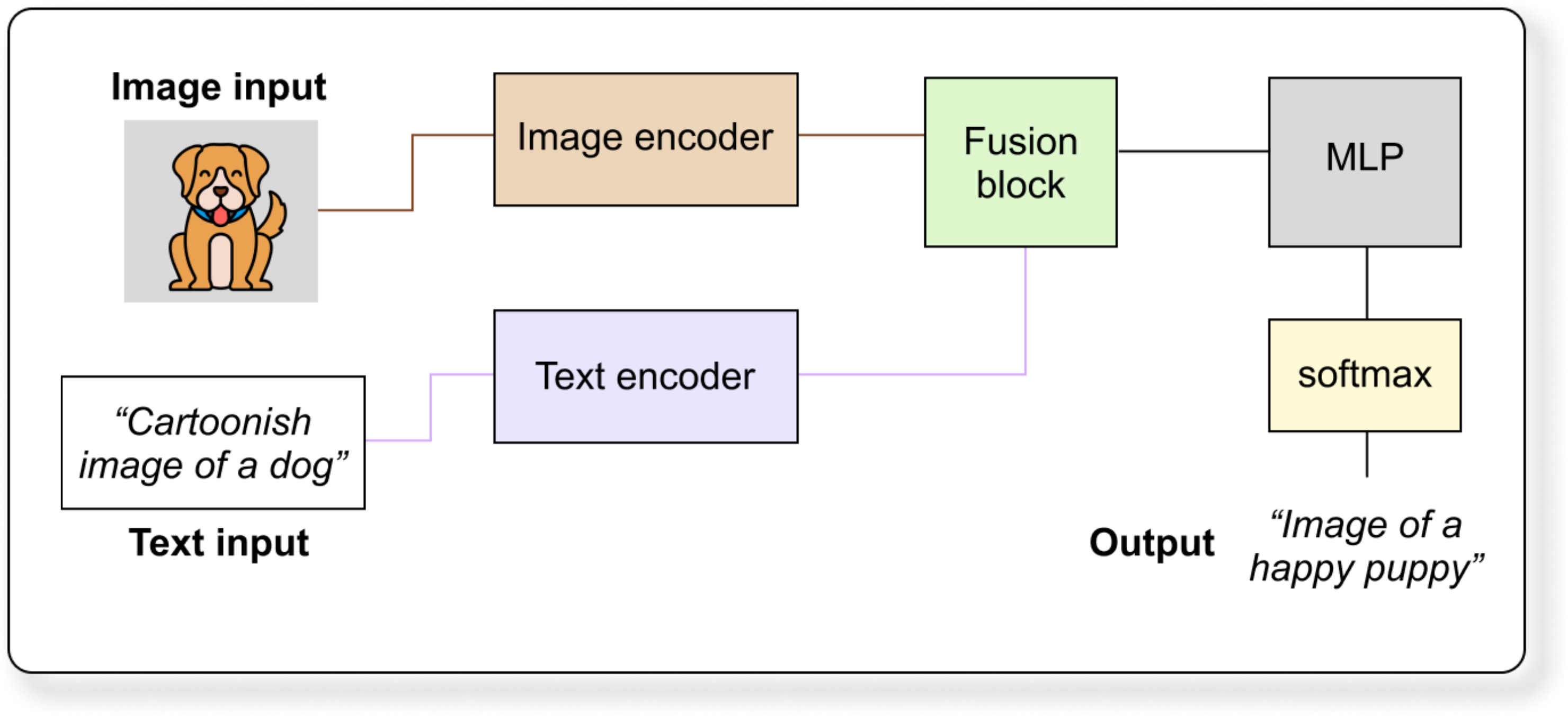
Early Fusion vs Late Fusion: What Is the Difference?

In early fusion, embeddings are merged (often concatenated) before sending into a transformer. In late fusion, the two encoders never interact until we calculate how similar the final embeddings are. Cross attention allows image tokens to attend to text tokens at each transformer block.
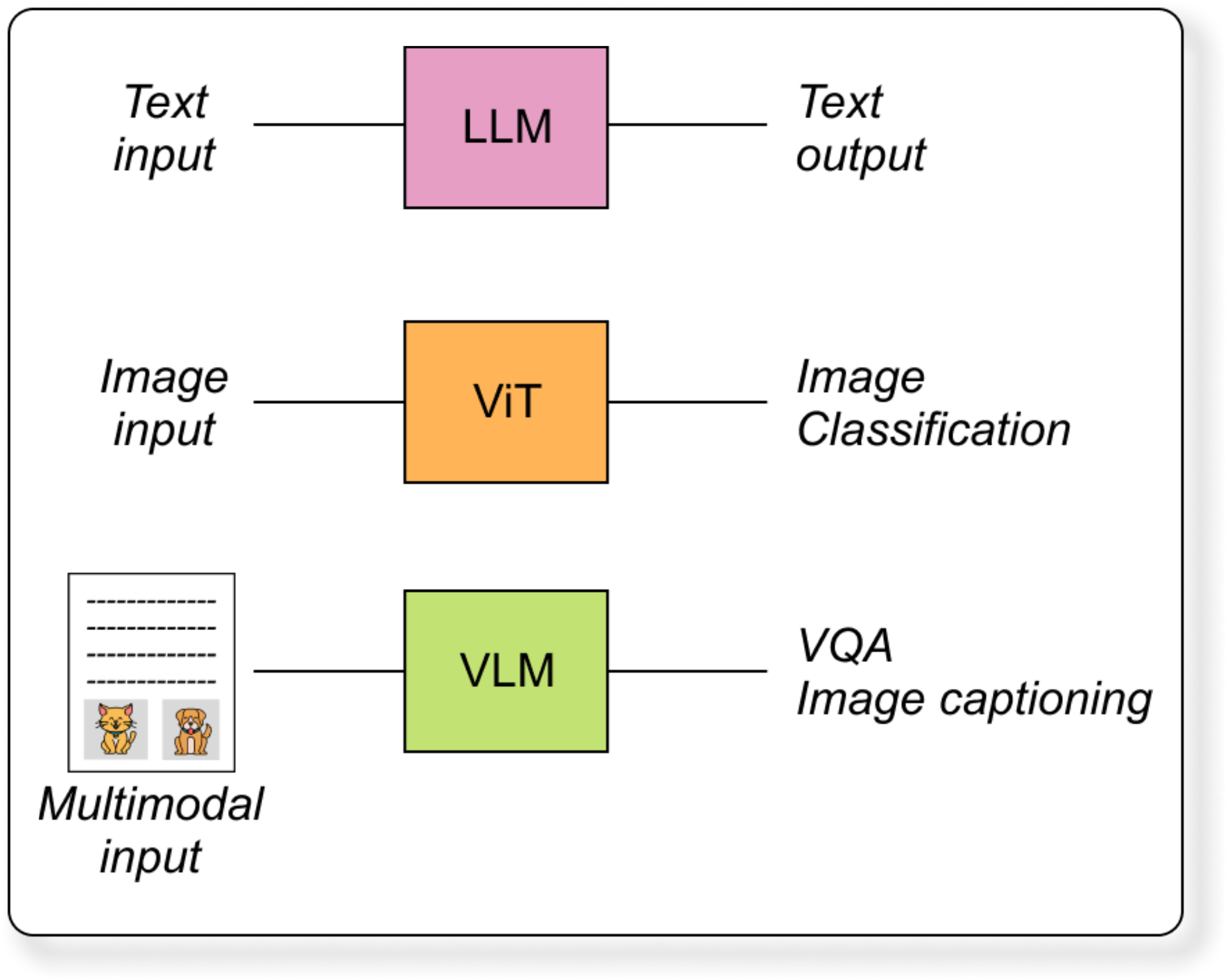
What Can Vision Language Models Do?
Once a VLM is trained to align image and text embeddings, it becomes incredibly powerful. It can perform tasks like:
Image Captioning: Input: image, Output: “A dog jumping into a lake”
Visual Question Answering (VQA): Input: image + question, Output: “Yes, it is a laptop”
Image Retrieval: Input: “red car in front of mountains”, Output: matching images
Vision Language Action (VLA): Used in robotics – see, read instructions, then act
Vision Language Planning (VLP): Used in self-driving cars to plan navigation based on scenes and textual instructions
Real Examples of VLM Architectures
Some popular models in this field are:
CLIP (OpenAI): Contrastive learning between image and text pairs
VisualBERT (Facebook AI): Early fusion between image region embeddings and text embeddings
ViLBERT: Cross attention between visual and textual streams
BLIP: Image captioning and image-text matching
Flamingo (DeepMind): Few-shot vision language model
LLaVA and MiniGPT-4: Add a visual adapter to LLMs like GPT
Where We Go Next
In the next lectures, we will:
Understand contrastive loss in detail
Implement a nano Vision-Language Model from scratch
Train both encoders so that image and caption vectors align in vector space
Visualize embeddings before and after training
Vision Language Models are the bridge between how we see and how we speak. And once a machine can understand both, it stops just recognizing pixels or words and starts understanding meaning.
YouTube lecture
Join Vision Transformer PRO
– Access to all lecture videos
– Hand-written notes
– Private GitHub repo
– Private Discord
– “Transformers for Vision” book by Team Vizuara (PDF)
– Email support
– Hands-on assignments
– Certificate