
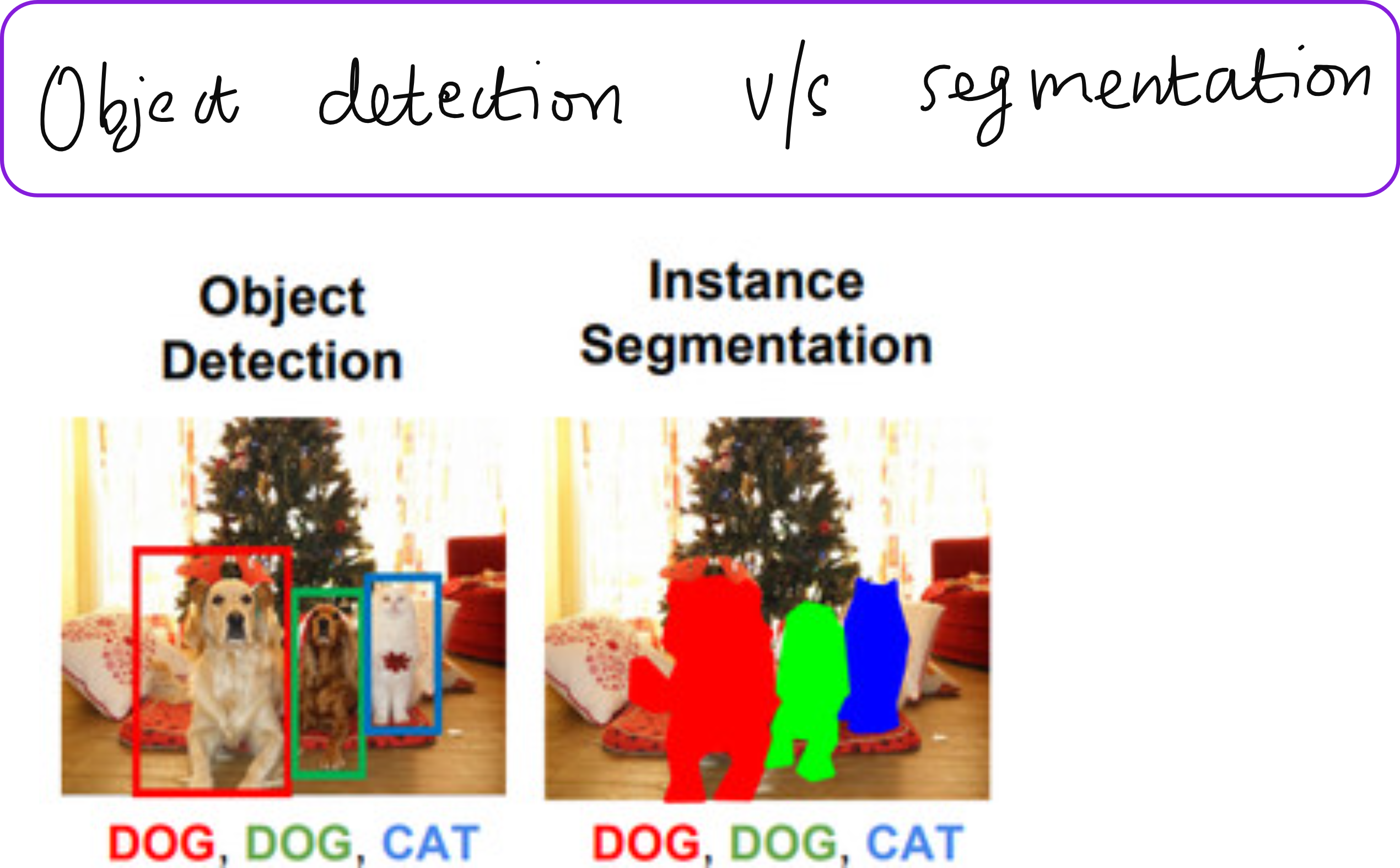
Introduction to image segmentation
And also learn how exactly does Mask RCNN works




Understanding Mask R-CNN – A Deep Dive
When we talk about object detection models in computer vision, there has been a clear progression from detecting objects using bounding boxes to segmenting them at the pixel level. This evolution has taken us from R-CNN and Fast R-CNN to Faster R-CNN, and finally to Mask R-CNN, which extends object detection into the domain of instance segmentation. In this article, we will explore the internal workings of Mask R-CNN, how it builds on Faster R-CNN, and the crucial role of its mask branch in generating pixel-accurate object predictions.
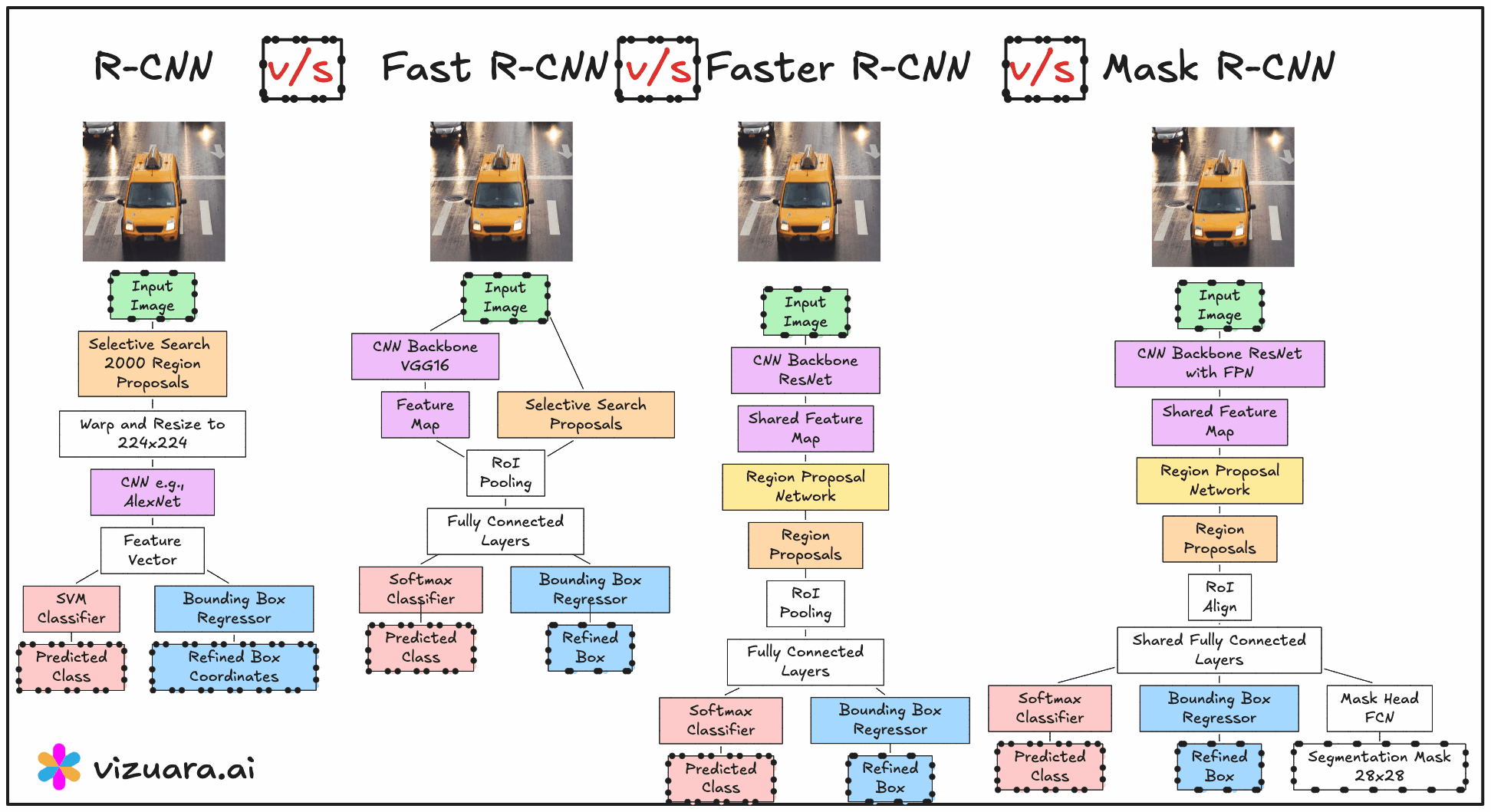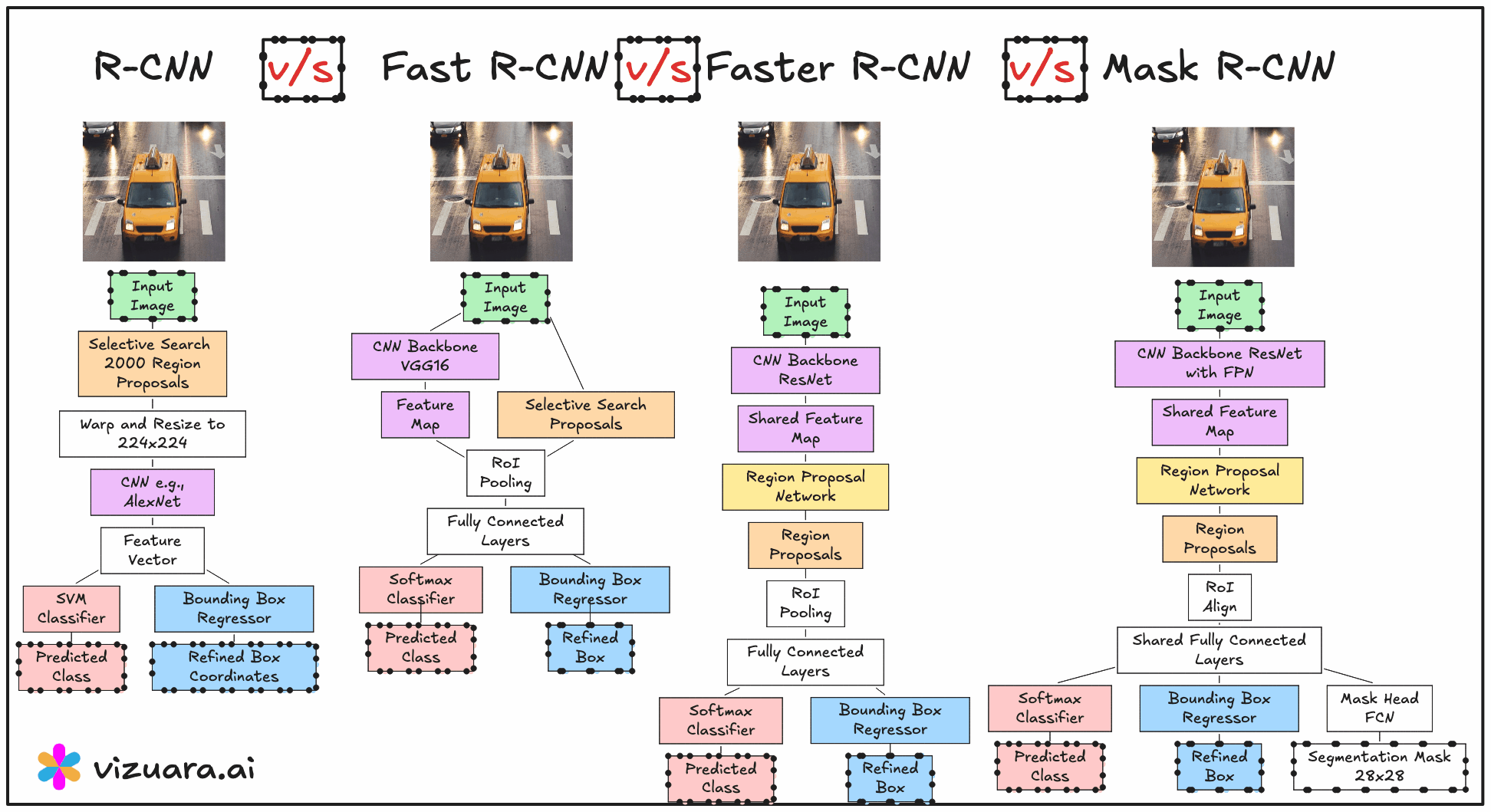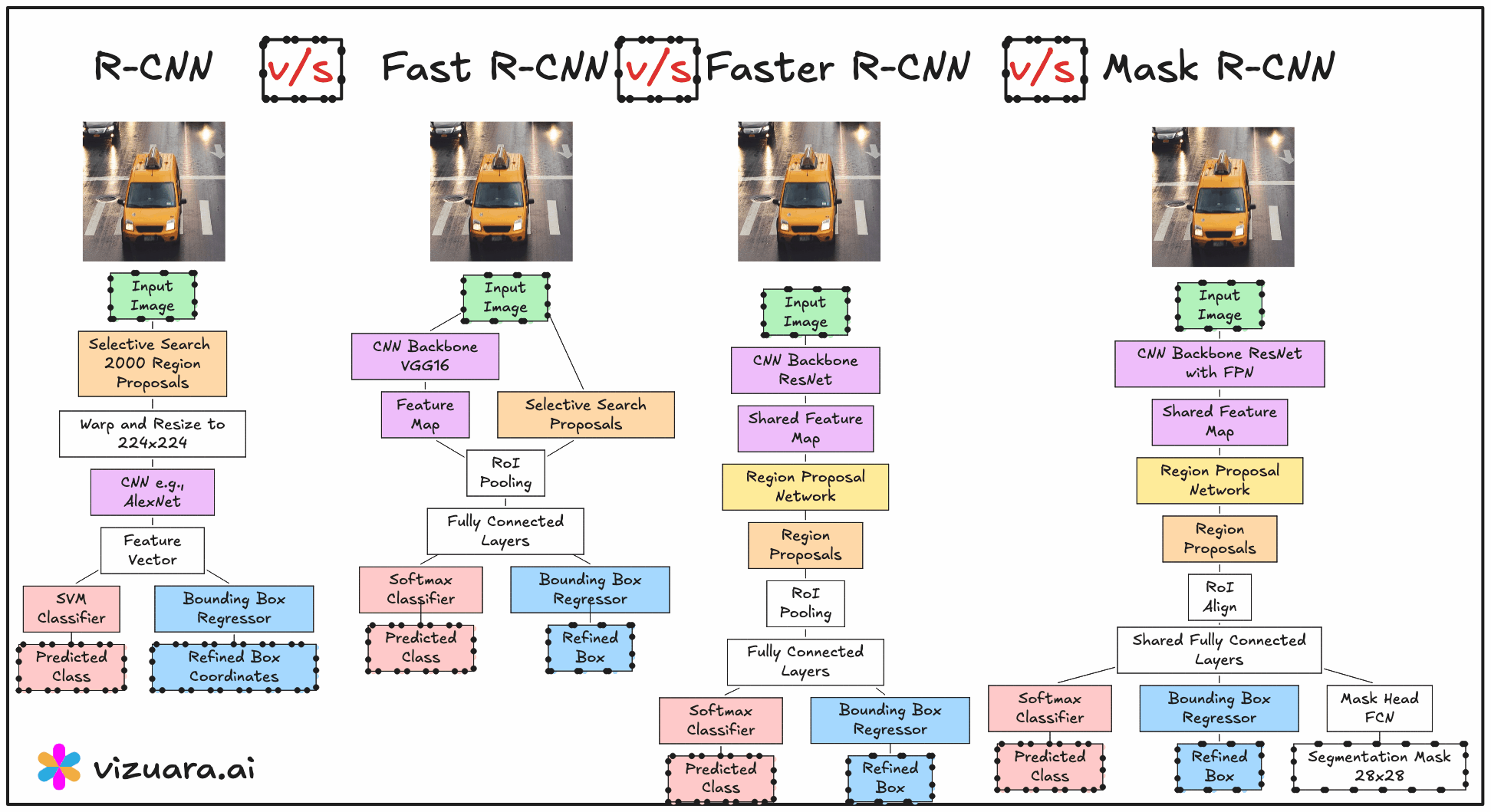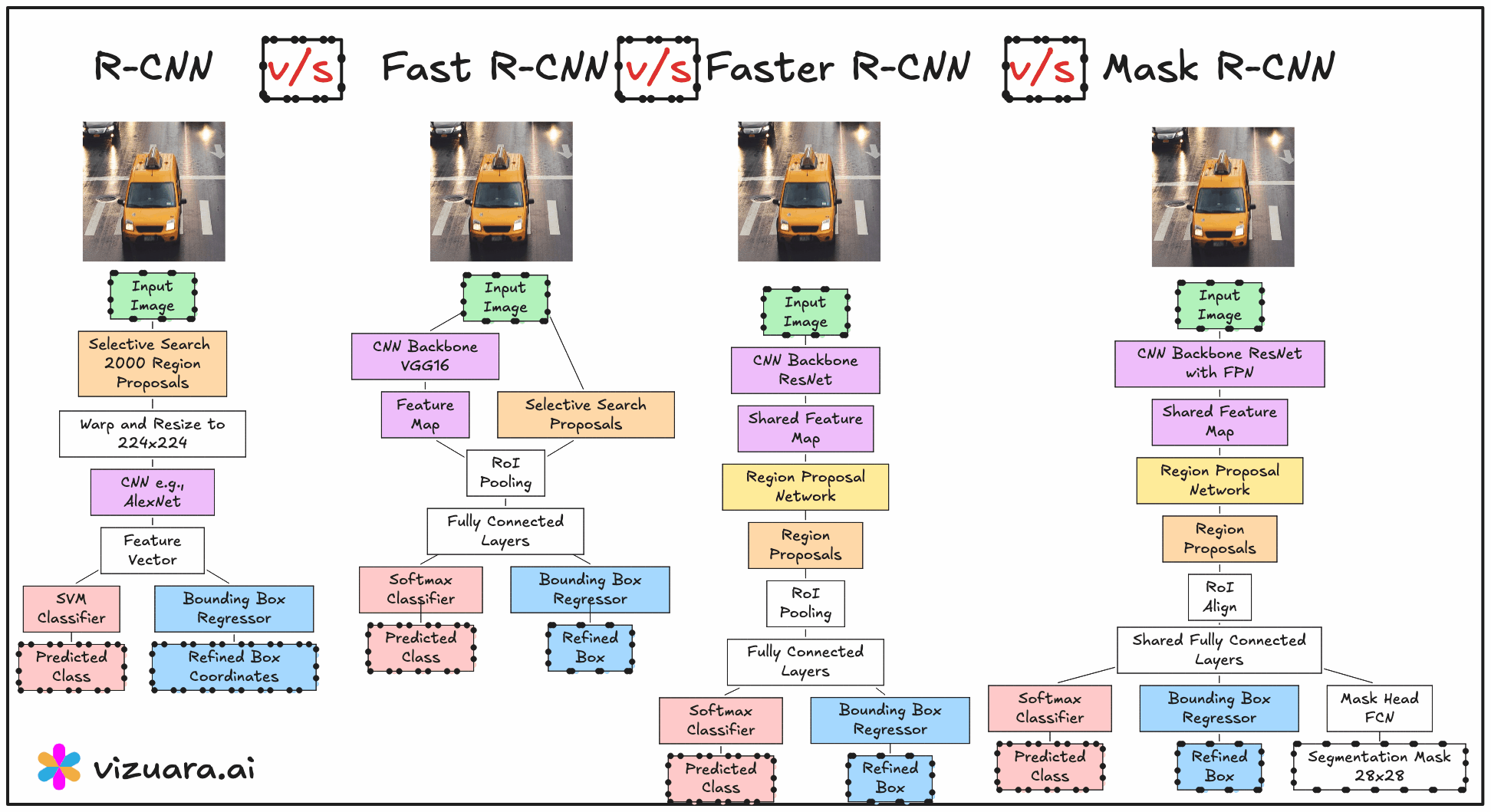
From Faster R-CNN to Mask R-CNN

Faster R-CNN was already a significant step forward because it introduced the Region Proposal Network (RPN) to generate bounding box proposals directly from the feature maps of a convolutional backbone. The RPN effectively removed the need for slow, external proposal methods like Selective Search, and allowed the model to learn region proposals in an end-to-end manner.
Mask R-CNN takes this exact architecture and enhances it with an additional branch, often referred to as the mask head. While Faster R-CNN outputs bounding boxes and class scores, Mask R-CNN simultaneously predicts a binary segmentation mask for each detected object. This transforms the problem from simple object detection into instance segmentation, where each object is delineated at the pixel level.
The Mask Head – The Third Parallel Branch
Inside Mask R-CNN, the mask head is implemented as a parallel branch alongside the classification and bounding box regression branches. All three branches receive input from the same Region of Interest (RoI) features extracted from the shared backbone feature maps.
The process begins with the Region Proposal Network generating candidate regions that might contain objects. These regions are mapped to the feature maps, and the corresponding subregions are extracted using RoI Align (more on this shortly). These RoI-specific feature tensors are then sent to the three branches:
Classification branch – predicts the class label for the object in the RoI.
Bounding box regression branch – refines the coordinates of the proposed box.
Mask branch (mask head) – predicts a binary mask for the object.
The mask head’s output is typically a 28×28 pixel binary mask for each class. It is called a binary mask because it marks object pixels with one value (for example, white) and background pixels with another value (black). Each pixel in this mask corresponds to a probability of belonging to the object rather than the background.
Per-Class Mask Prediction
One important detail is that the mask head predicts one mask per class for each RoI, instead of a single mask for all classes. Suppose the dataset contains cars and trucks as two classes. For each RoI, the mask branch will output two masks – one for “car” and one for “truck.” During inference, the mask corresponding to the predicted class from the classification branch is selected.
This design ensures that the mask predictions are class-specific, enabling the model to learn finer details for each category rather than a generic object mask.
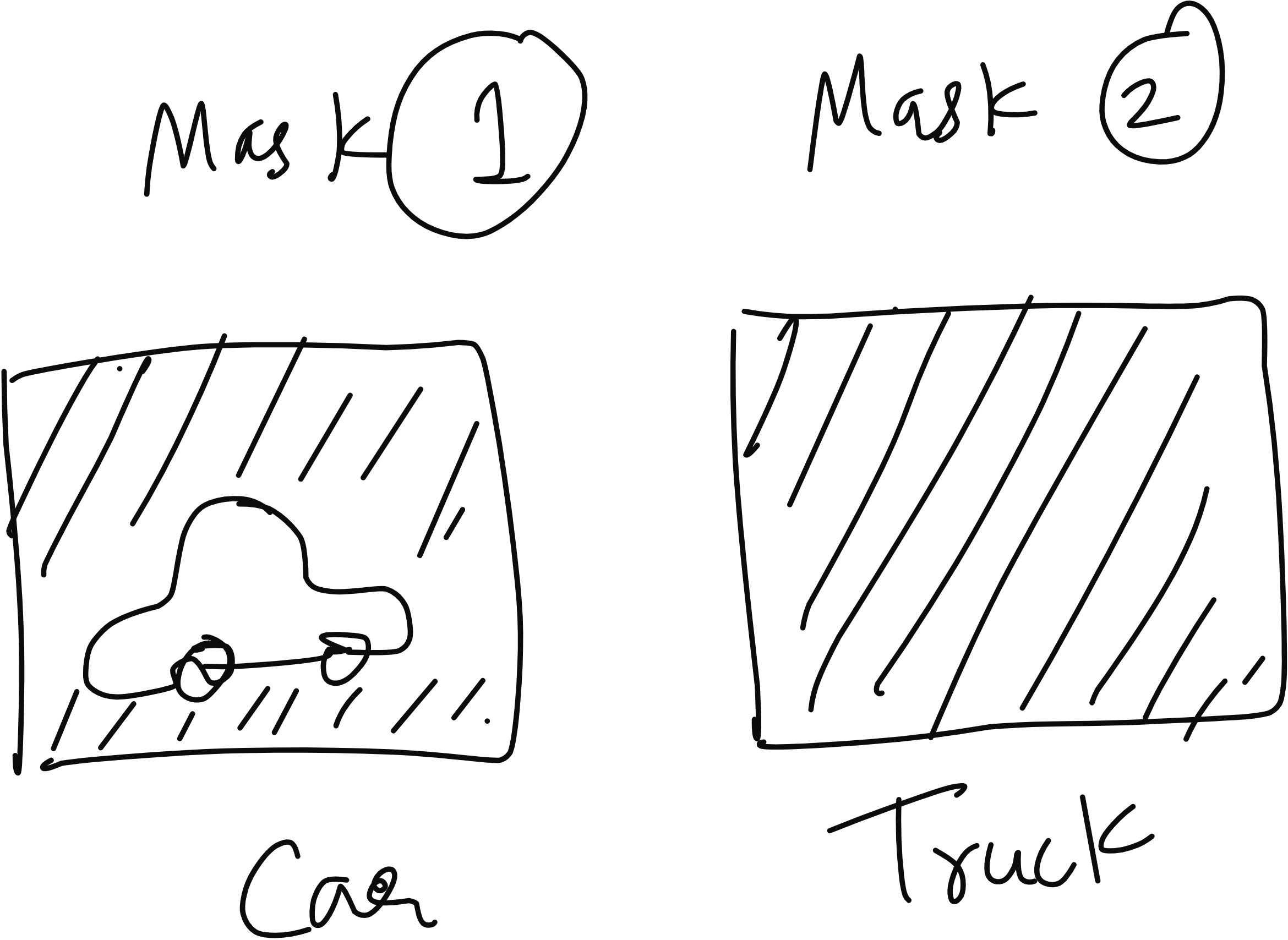



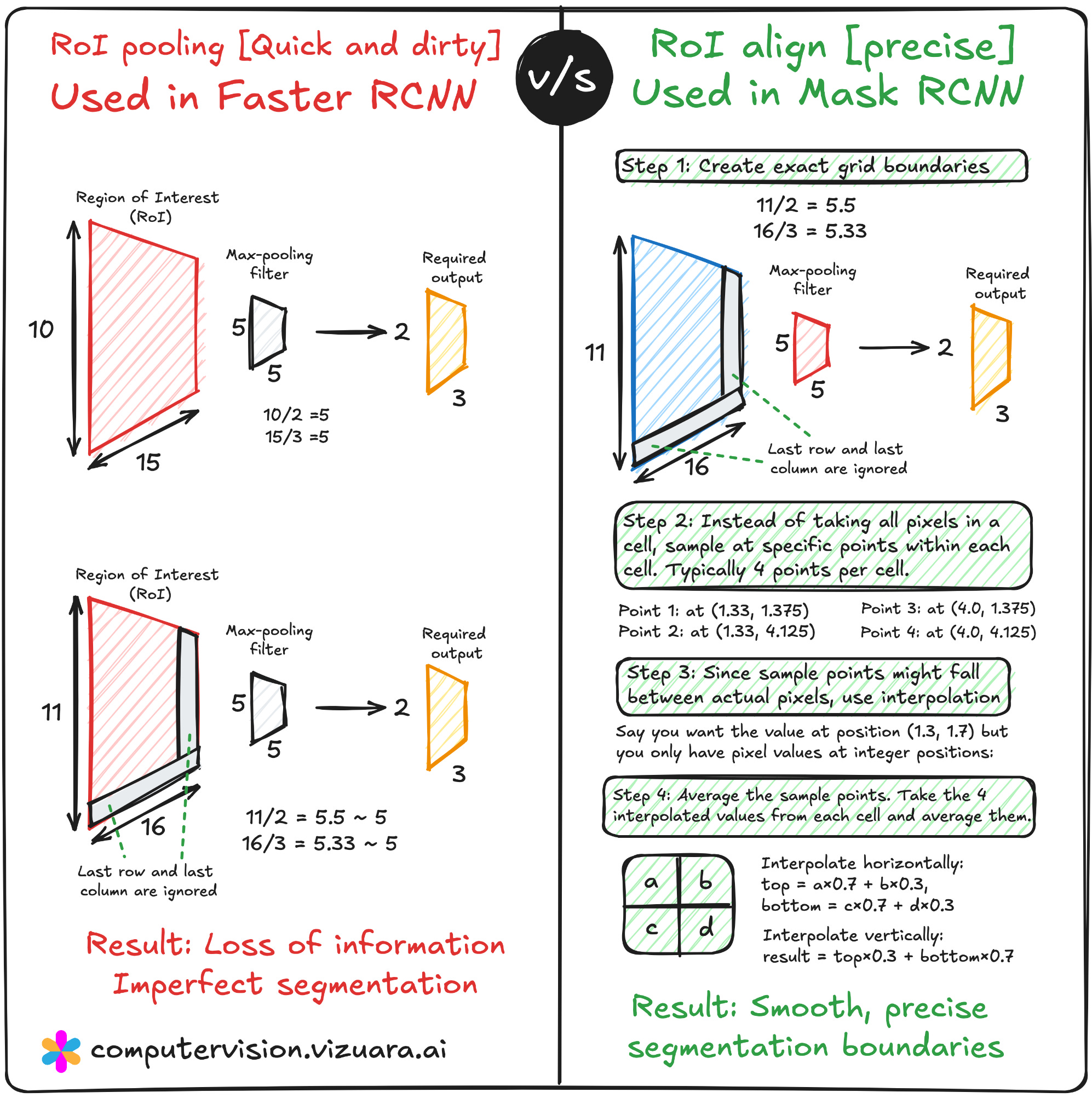
RoI Align – Precision in Feature Extraction
A key modification in Mask R-CNN compared to Faster R-CNN is replacing RoI Pooling with RoI Align. In Faster R-CNN, RoI Pooling quantizes the floating-point coordinates of the proposals into discrete bins, which can cause slight misalignments between the extracted features and the original image pixels. While this does not affect bounding boxes much, it becomes a serious limitation when generating pixel-accurate masks.

RoI Align eliminates quantization by using bilinear interpolation to compute exact feature values at sampled points. This results in masks that are much better aligned with the object boundaries, improving the overall segmentation accuracy.
So how exactly does Region Proposal Network work?

Training the Mask Head
During training, the mask branch is supervised using the ground truth segmentation masks for each object. The loss function for the mask branch is typically a pixel-wise binary cross-entropy loss, computed only for the mask corresponding to the ground truth class. This selective loss calculation ensures that the mask head learns class-specific segmentation patterns.
Importantly, the mask loss is independent of the classification and bounding box regression losses. This allows the network to learn object masks without being penalized for classification errors.
End-to-End Flow of Mask R-CNN
To summarise the entire operation:
Input image is passed through the convolutional backbone (ResNet, ResNeXt, etc.) to produce a feature map.
Region Proposal Network predicts candidate bounding boxes from the feature map.
RoI Align extracts fixed-size feature tensors for each proposed box.
The features are fed into three parallel branches:
Classification head for object category prediction.
Bounding box regression head for precise localization.
Mask head for per-class binary segmentation masks.
The predicted mask corresponding to the highest-scoring class is selected and resized to match the dimensions of the detected object in the original image.
Applications of Mask R-CNN
The ability of Mask R-CNN to provide pixel-level segmentation makes it suitable for a wide range of applications, such as:
Autonomous driving – detecting and segmenting pedestrians, vehicles, and road elements.
Medical imaging – segmenting tumors, organs, or cell structures in scans.
Robotics – object segmentation for precise manipulation.
Video surveillance – distinguishing individuals and objects in crowded scenes.
Augmented reality – overlaying digital content on exact object shapes.
Why Mask R-CNN Remains Popular
Despite the rise of newer segmentation architectures like DETR-based models, Mask R-CNN continues to be widely used because of its strong balance between detection accuracy and segmentation quality, its modular design, and the ease with which it can be adapted to new datasets. Its reliance on the proven Faster R-CNN framework makes it both stable and interpretable for research and production environments.
In essence, Mask R-CNN represents a clean and elegant extension of Faster R-CNN that enables both detection and instance segmentation in a single, end-to-end trainable framework. The introduction of the mask head and RoI Align solved two important challenges – generating precise object masks and preserving spatial alignment – making Mask R-CNN a foundational model for modern computer vision tasks.