
I just built a Vision Transformer from Scratch
Starting with random weights


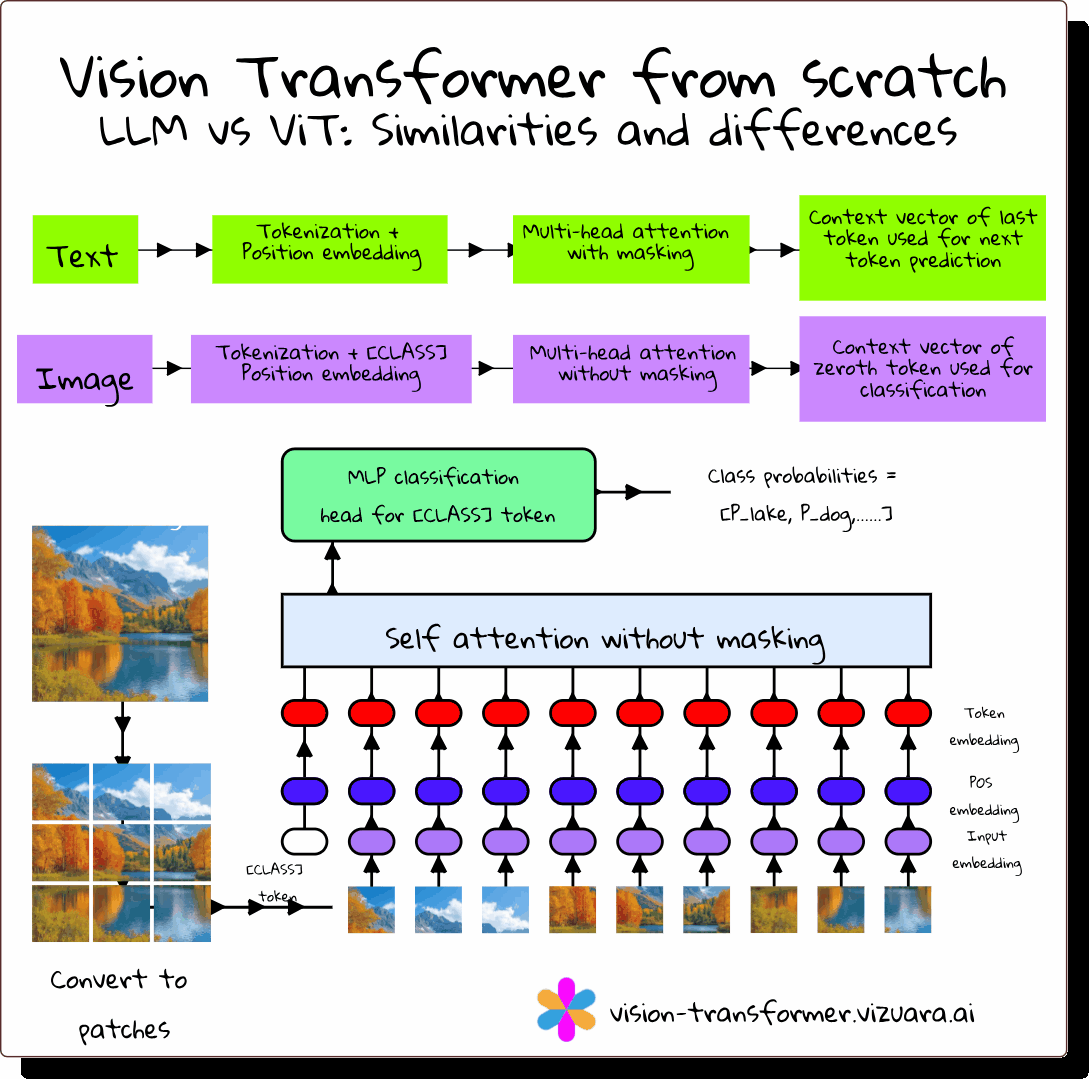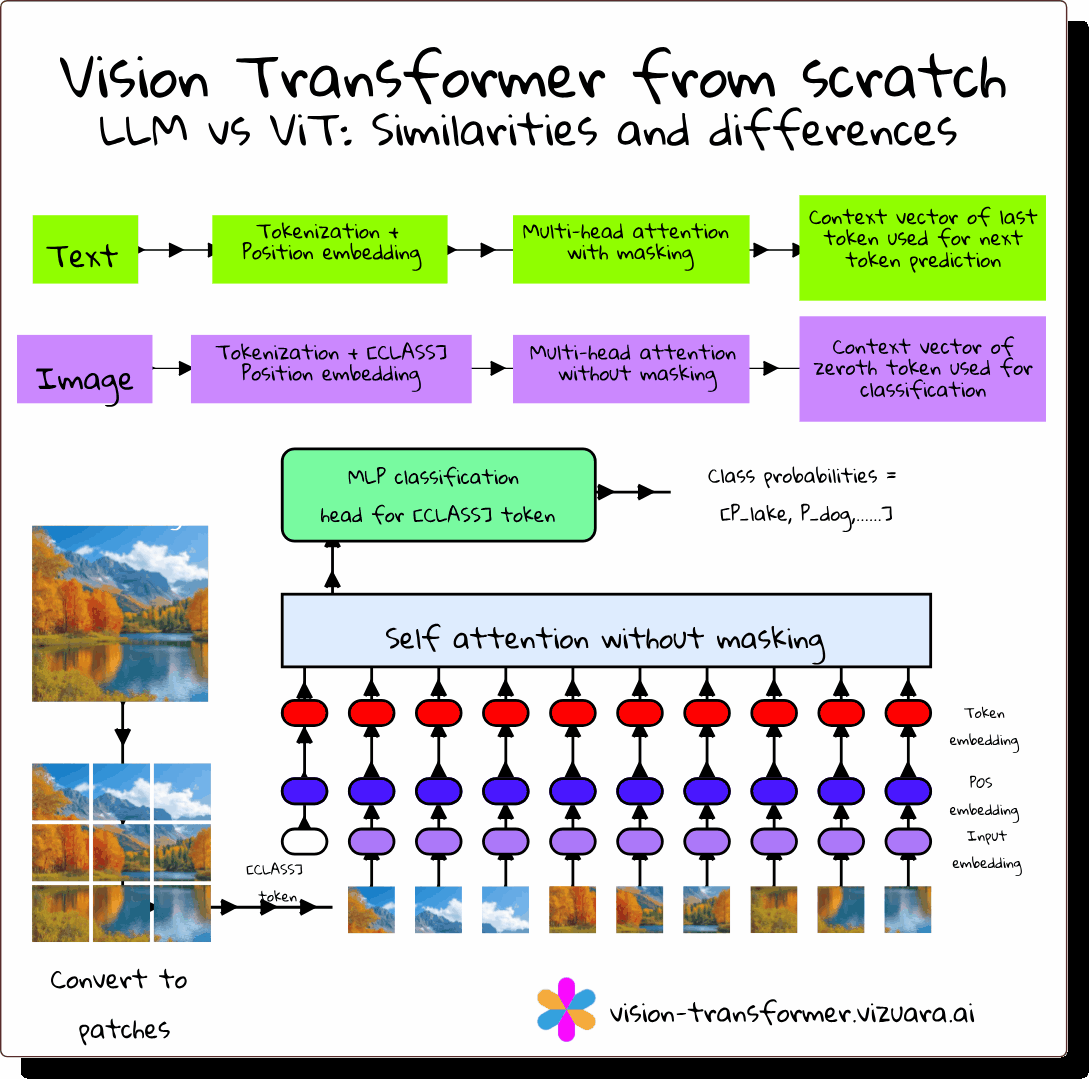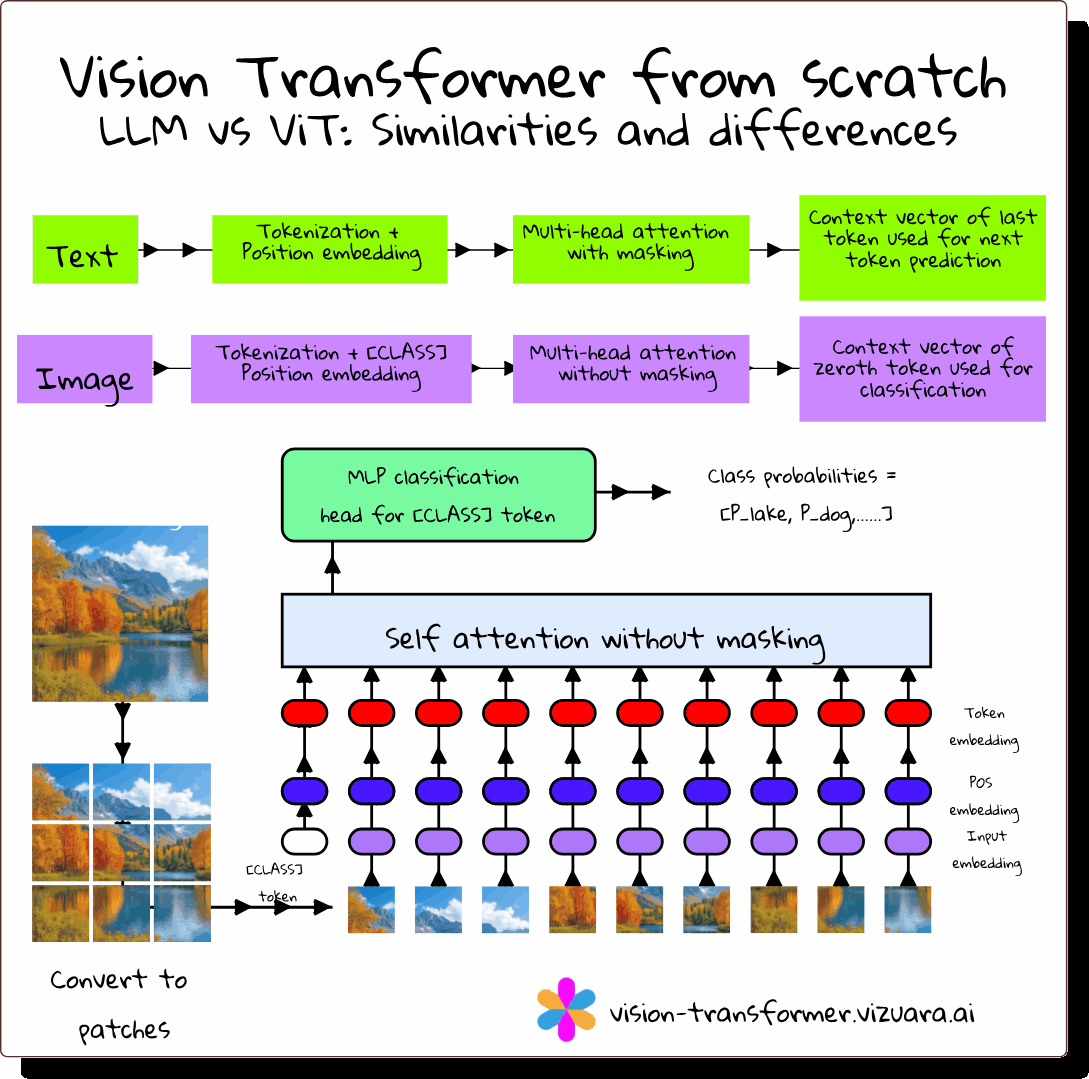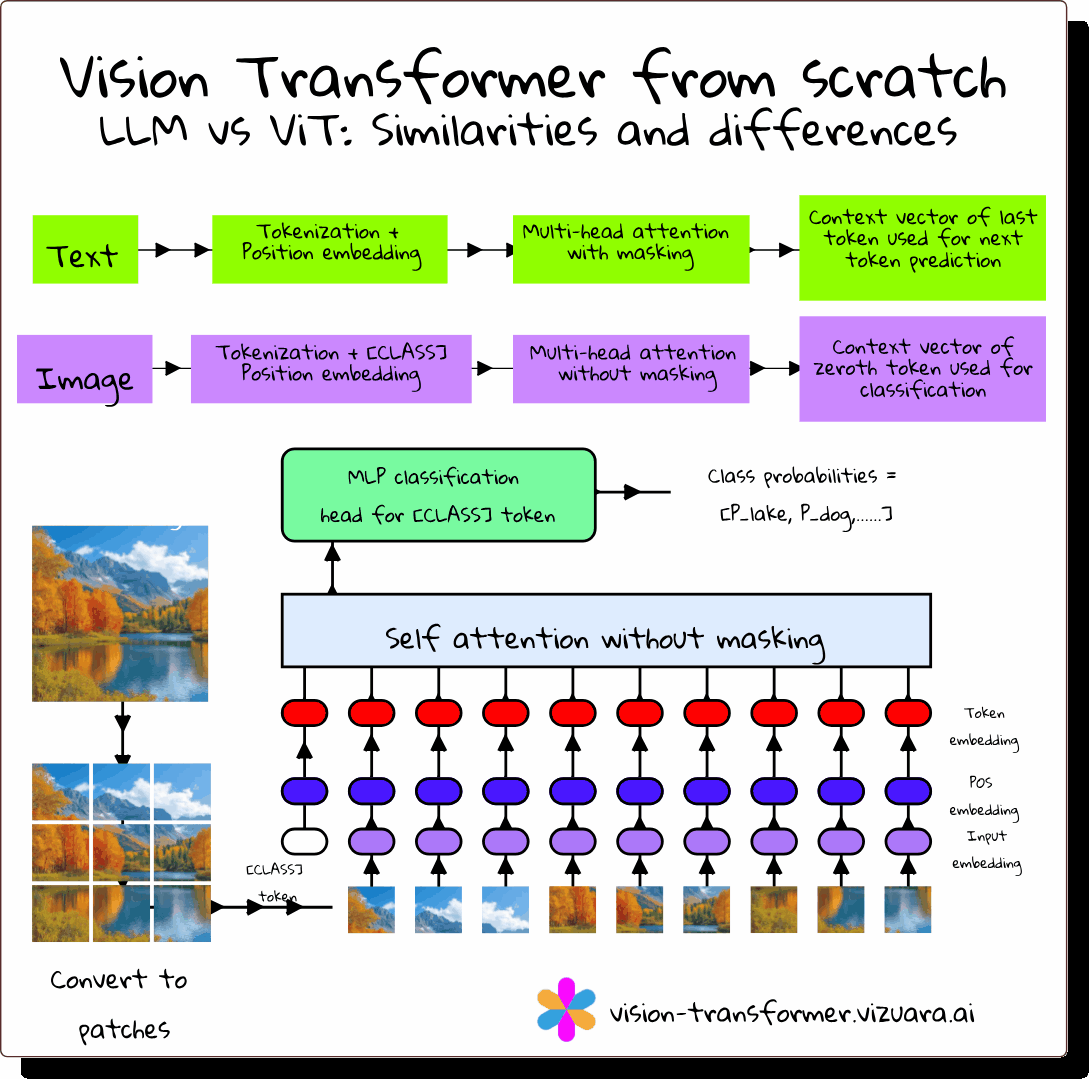

Why Vision Transformers Matter
For years, CNNs were the default for computer vision. They were excellent at detecting local features like edges and textures, but struggled to capture global relationships without stacking many layers. Vision Transformers (ViTs) solve this problem by applying the transformer architecture, originally built for language, directly to images.
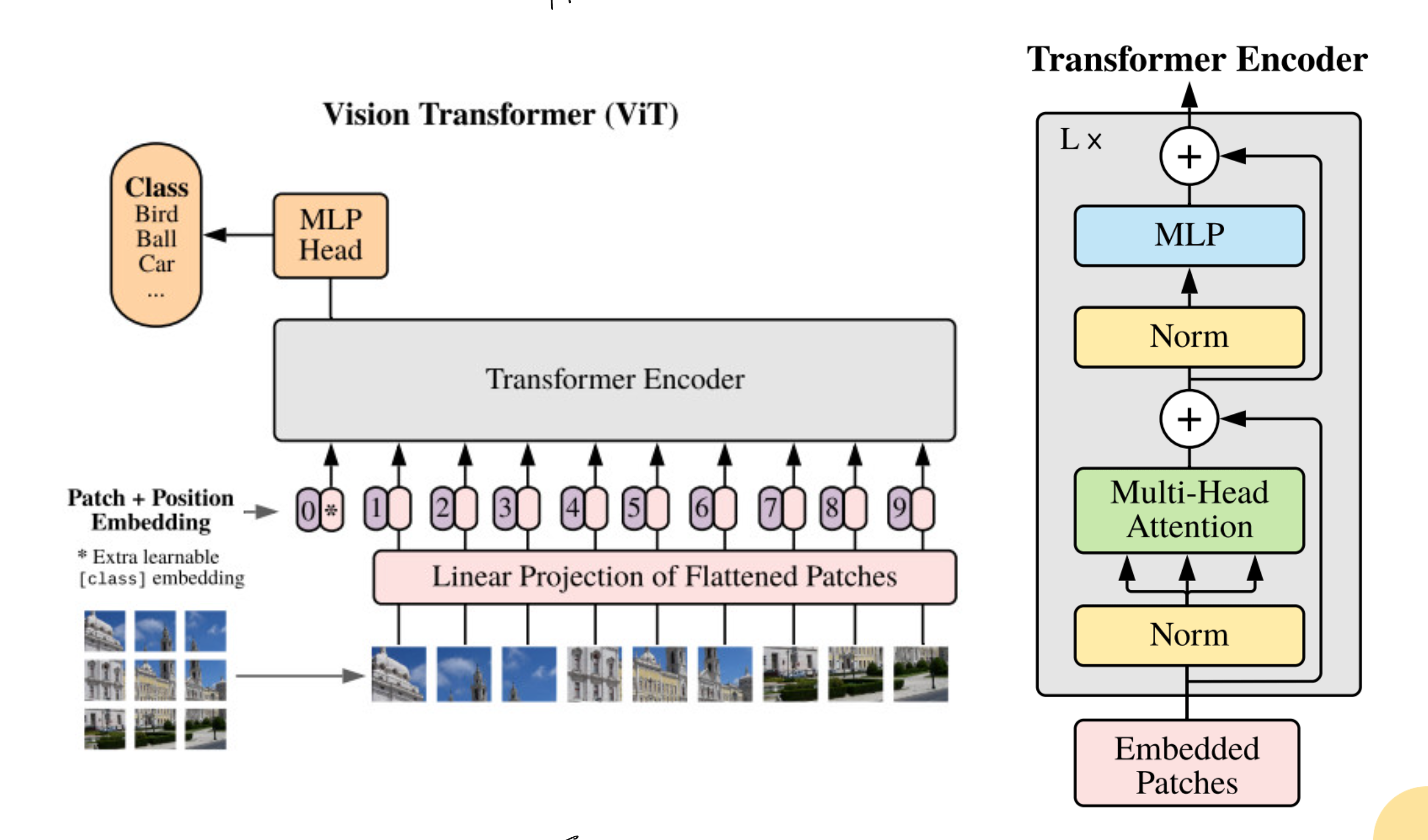
Step 1: Image to Patches
A 224×224 image is divided into fixed sized patches, for example 16×16
This gives 196 patches in total
Each patch is flattened into a vector
A linear layer converts this vector into an embedding
This is similar to converting words to embeddings in NLP.
Step 2: Adding Positional Information
Transformers do not understand spatial order. So we add positional embeddings to each patch embedding so the model knows where each patch came from in the original image. Without this step, all patches would look like an unordered list of vectors.
Step 3: Transformer Encoder
Every encoder block contains:
Multi head self attention
Feed forward network (MLP)
Layer Normalization and residual connections
A special [CLS] token that learns to collect information from all patches
After several such layers, the final [CLS] token is sent to a classification head to predict the image label.
How ViT Differs from CNNs

ViT v/s LLM
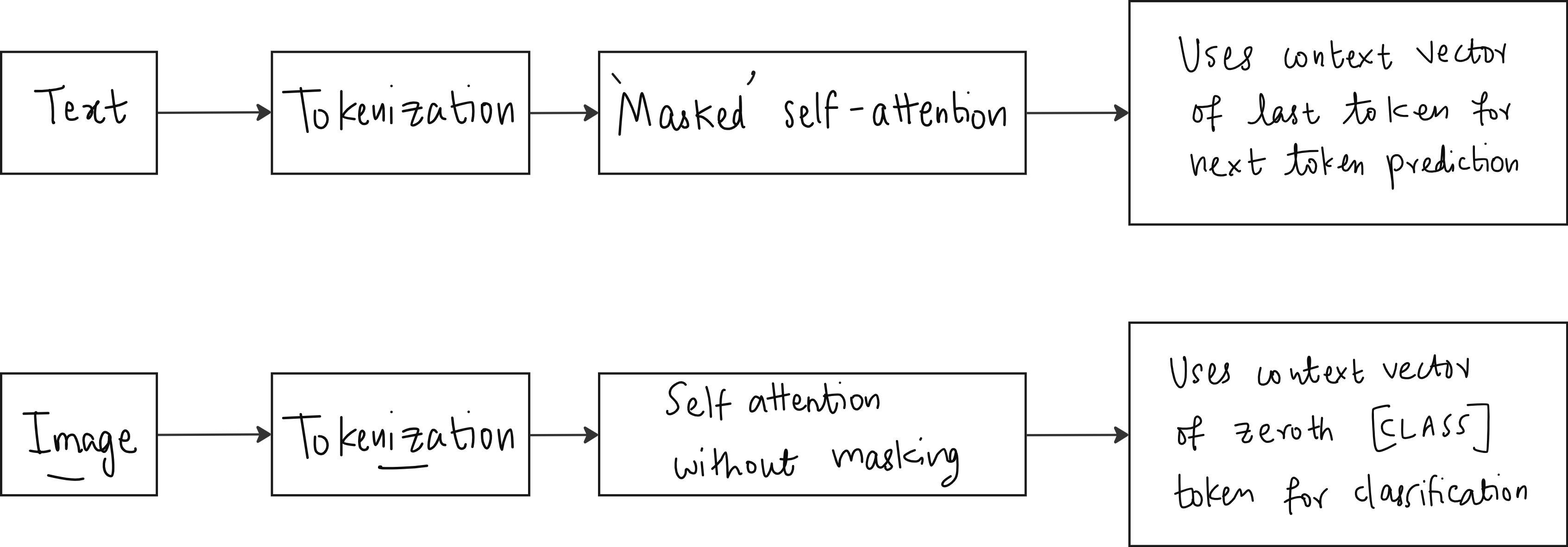
Why ViTs Need More Data
Vision Transformers do not assume anything about images. They have to learn spatial structure completely from training data. This is powerful but data hungry. Hence, ViTs are usually pretrained on very large datasets like ImageNet 21k or JFT 300M and later fine tuned.
Popular Variants
DeiT (Data efficient Image Transformer)
Uses knowledge distillation from a CNN teacher so ViTs can learn from smaller datasets.Swin Transformer
Introduces attention within small windows that shift across the image. Builds a hierarchical feature map similar to CNNs.Hybrid Models
Use convolution layers initially and transformers in later stages to balance efficiency and global attention.
Why This Architecture Works
It treats vision like language: image patches become words
Self attention allows any patch to connect with any other patch
It removes the dependency on convolutions
It creates a unified architecture for both text and images
What Comes Next
Vision Transformers have already become the backbone of multimodal models like CLIP and BLIP. Research now focuses on making attention faster, reducing computation and improving performance on smaller datasets.
YouTube lecture
Watch the full lecture here where I build a ViT from scratch and pre-train it fully.
Join pro
