
How I built a license plate recognition system with YOLOv8 and EasyOCR
3-minute read


Computer vision has moved far beyond simple classification problems. Today, it is powering real-world applications like traffic monitoring, vehicle tracking, smart tolling, and law enforcement. One of the most practical and interesting projects you can build is license plate recognition. At first glance, it seems straightforward: take a video feed of cars, identify the number plates, and extract the alphanumeric characters. But in reality, this problem brings together several powerful techniques in deep learning.
In this article, I will walk you through how we can use YOLO (You Only Look Once) for localizing the number plate in an image, and then apply OCR (Optical Character Recognition) to read the characters. We will fine-tune a pretrained YOLO model, make use of annotated datasets from Roboflow, and finally combine everything into an end-to-end pipeline that outputs the vehicle registration number from raw traffic video frames.

Why YOLO?
YOLO has become the go-to family of models for object detection. Its ability to process an image in a single forward pass makes it fast and efficient. However, there is one catch: the default pre-trained YOLO models are trained on the COCO dataset, which has 80 object classes ranging from “dog” and “baseball” to “car” and “bottle”. Noticeably absent from this list is “license plate”.
This means if we want YOLO to recognize license plates, we cannot directly rely on the pretrained model. Instead, we must fine-tune YOLO on a dataset where the bounding boxes of license plates are annotated. By doing this, YOLO learns to detect the plates as a new object category while still retaining the general image features it picked up from COCO.
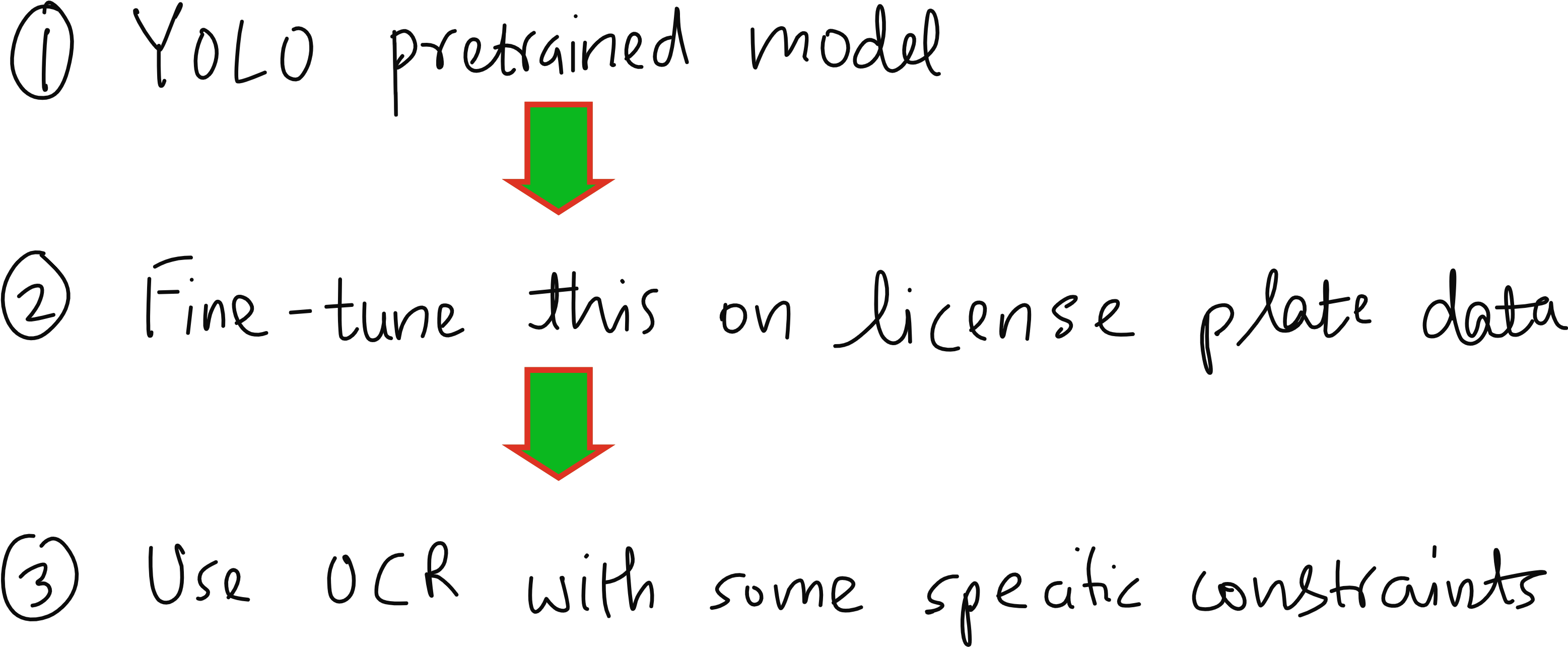


Workflow for finetuning

Getting the Dataset
Roboflow provides an excellent annotated dataset for license plate detection.
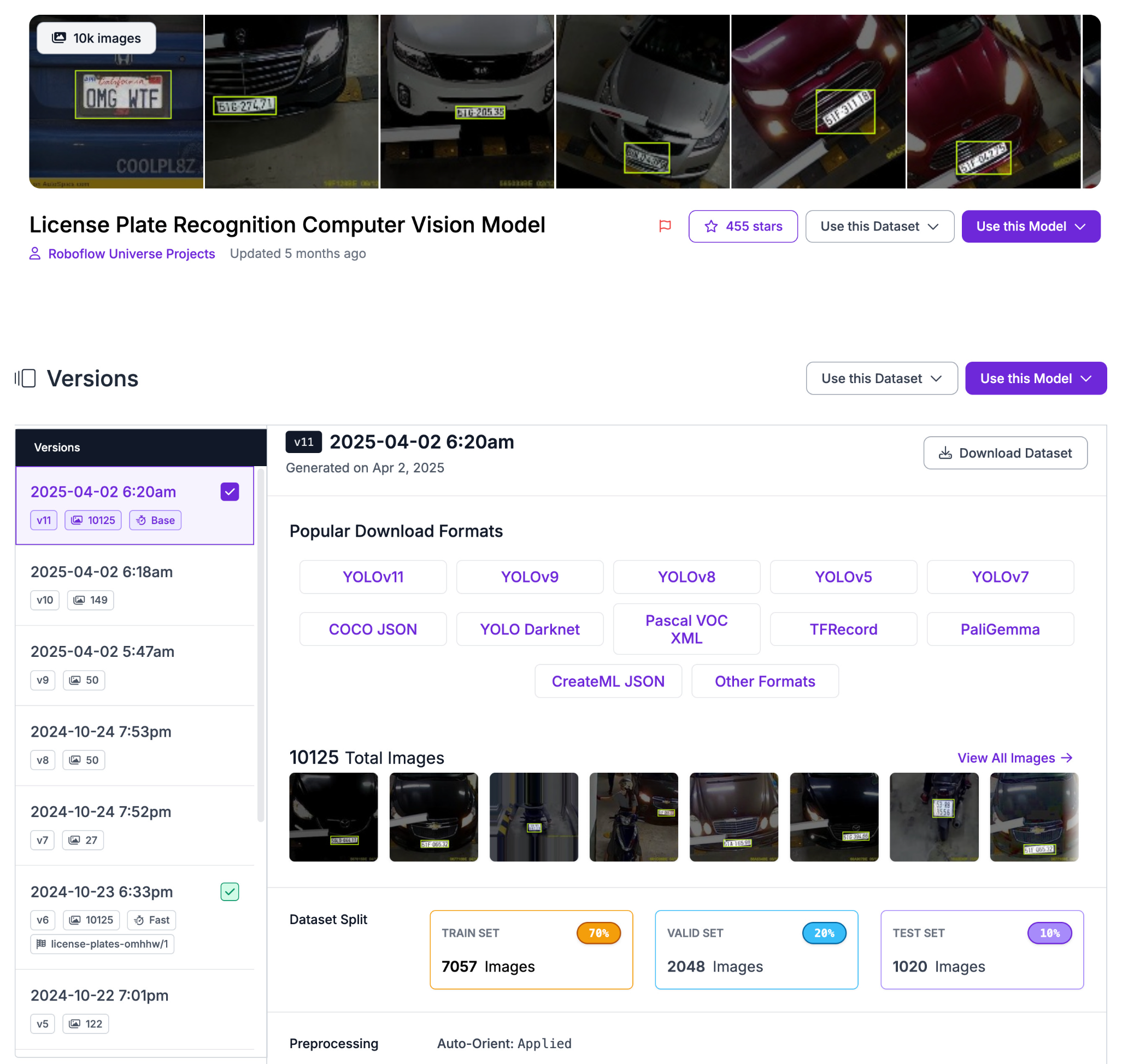
Here is the link: https://universe.roboflow.com/roboflow-universe-projects/license-plate-recognition-rxg4e/dataset/11
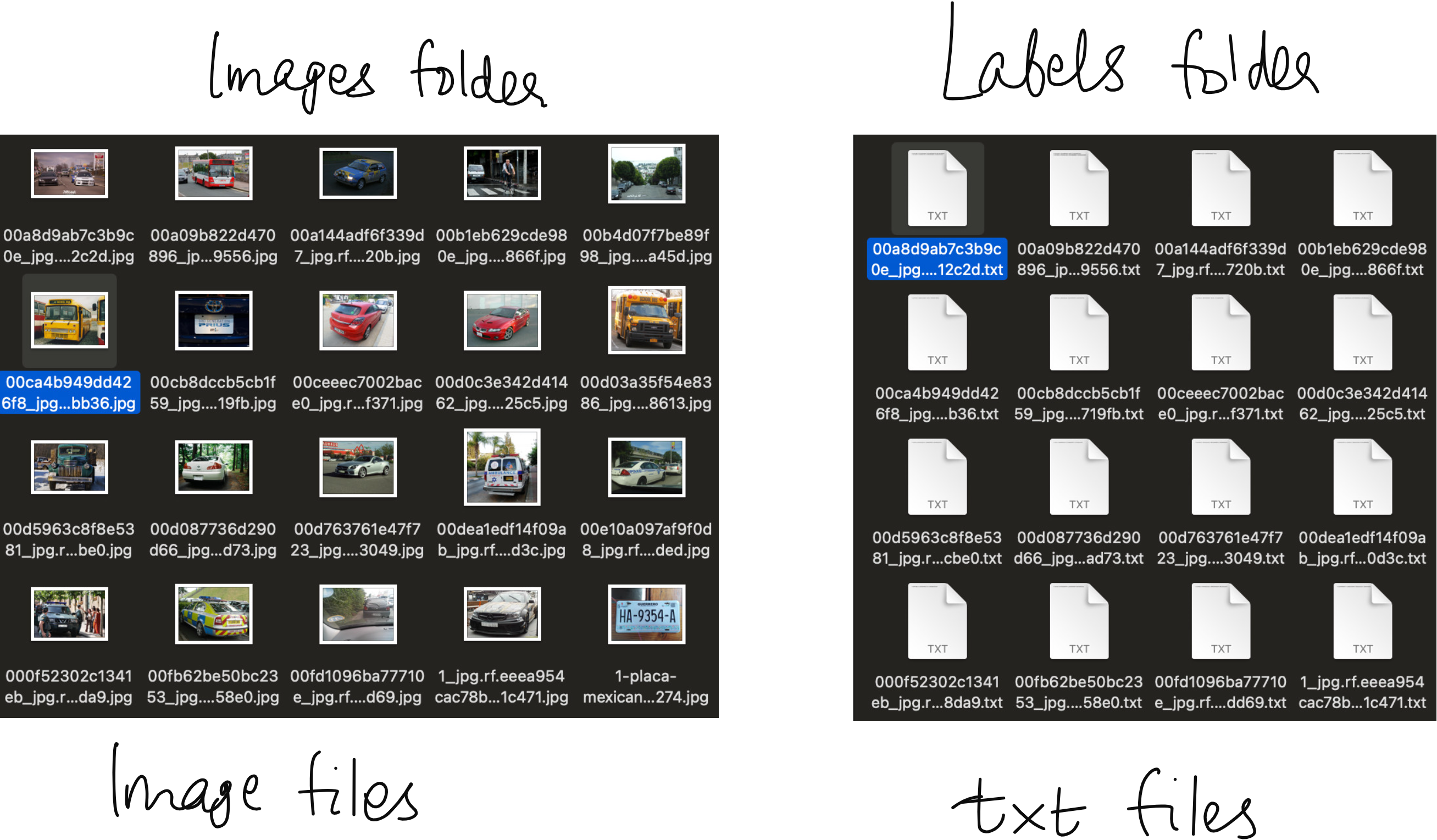
The dataset is already split into training, validation, and test sets, and comes with the standard YOLO-style folder structure:
license-plate-dataset/
├── train/
│ ├── images/
│ └── labels/
├── valid/
│ ├── images/
│ └── labels/
├── test/
│ ├── images/
│ └── labels/
└── data.yamlEach image file has a corresponding .txt label file where the bounding box is stored in YOLO format:
<class_id> <x_center> <y_center> <width> <height>For our problem, the class_id is always 0 because we only have one class: license plate.
Fine-tuning YOLO on License Plates
Once the dataset is ready, we fine-tune YOLO. The steps are:
Install Roboflow and Ultralytics libraries.
Download the dataset from Roboflow in YOLO format.
Load a pretrained YOLOv8 model (say
yolov8n.pt).Train for a few epochs on the license plate dataset.
Save the model weights.
The fine-tuning code is straightforward and runs comfortably on Google Colab with GPU support. After training, we get two sets of weights – best.pt (the model with the best validation accuracy) and last.pt (the final state of the model). For deployment, we usually prefer best.pt.
Isolating the Plate vs Reading the Text
Here is where we separate concerns. YOLO is excellent at object detection but not at reading text. Even if we zoom into the plate region, YOLO cannot interpret characters. That is where OCR comes in.
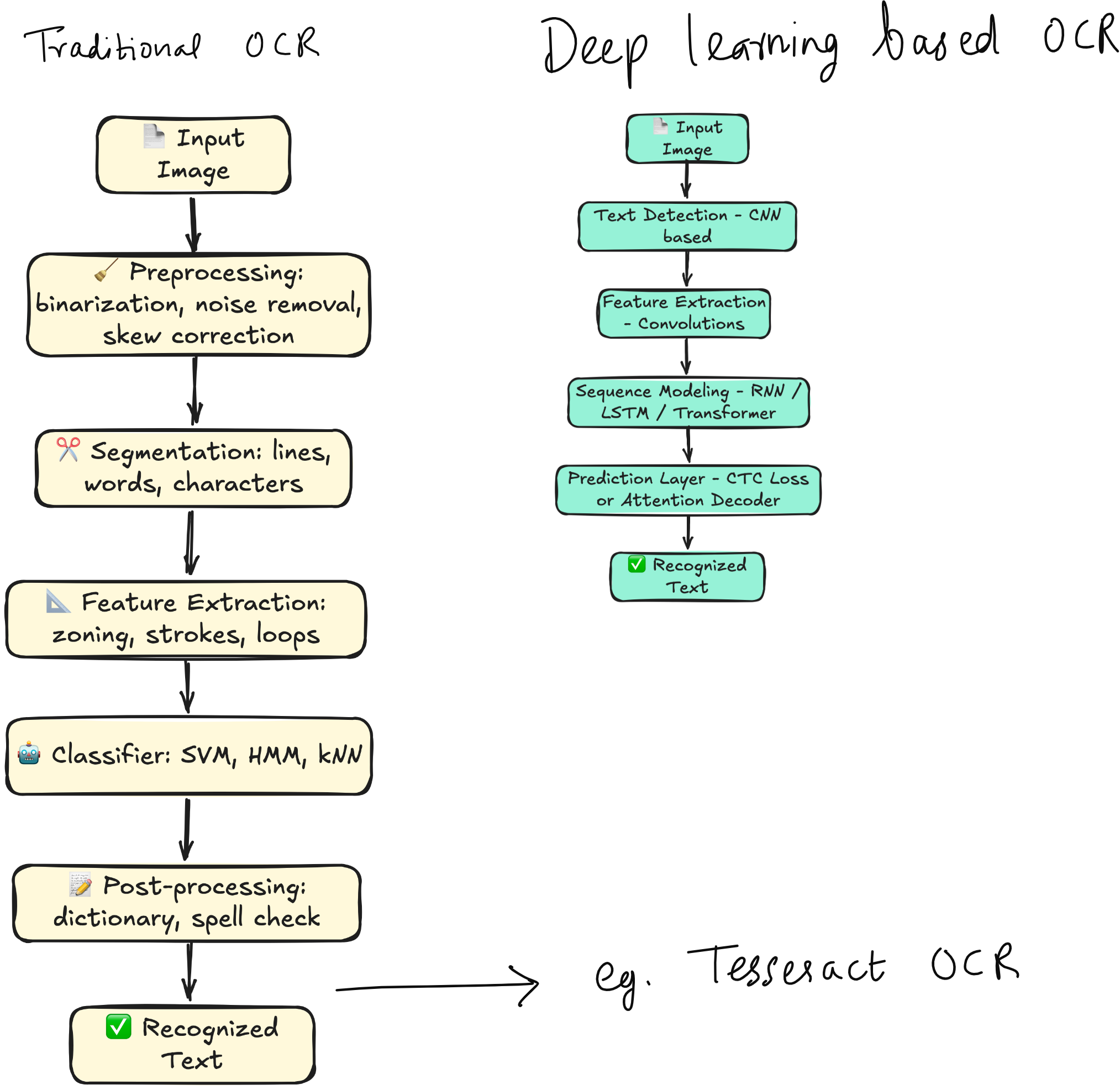
OCR has two main flavors:
Traditional OCR: Preprocessing, segmentation, feature extraction, classification, and post-processing. Tesseract OCR is a well-known example of this.
Deep Learning-based OCR: End-to-end models that directly process the input image and output recognized text. EasyOCR is a popular choice here.
For our project, we use EasyOCR since it is deep learning-based, supports multiple languages, and handles noisy or blurred license plates much better.
The Complete Pipeline
Now let us put the pieces together:
YOLO detects the bounding box of the license plate in the video frame.
The cropped plate region is passed to EasyOCR.
OCR extracts the alphanumeric text from the image.
Post-processing ensures the output fits the license plate format (for example, 2 letters + 2 digits + 2 or 3 letters).
This pipeline is robust because it divides the problem into two manageable steps: detection and recognition.
Implementation in VS Code
When deploying this in practice, you can run the fine-tuned YOLO model alongside EasyOCR in VS Code. The code imports YOLO, OpenCV, and EasyOCR. For every frame:
The YOLO model detects the plate.
The detected region is preprocessed (grayscale, thresholding, resizing).
OCR reads the characters.
A correction function maps visually similar characters to the right ones (for example, “0” to “O”, “5” to “S”).
By stabilizing the predictions across multiple frames, we ensure that the final license plate number is consistent and accurate.
Conclusion
License plate recognition is a great project because it combines object detection, fine-tuning, dataset preparation, and OCR into a single workflow. It is not just an academic exercise – this is the very technology deployed at toll booths, traffic monitoring systems, and smart parking solutions worldwide.
The beauty of this project lies in how different AI tools complement each other. YOLO brings speed and localization power. OCR adds text reading capability. Together, they solve a real-world problem elegantly.
If you are learning computer vision, this project gives you hands-on exposure to datasets, training pipelines, pretrained models, OCR engines, and practical deployment challenges. It is an ideal step forward once you are comfortable with the basics of CNNs and YOLO.
YouTube video
Computer Vision course
If you wish to learn Computer Vision hands-on from us, check this out: