
How exactly is RL used in reasoning models?
The revival of Reinforcement Learning in 2025 [2-minute read]


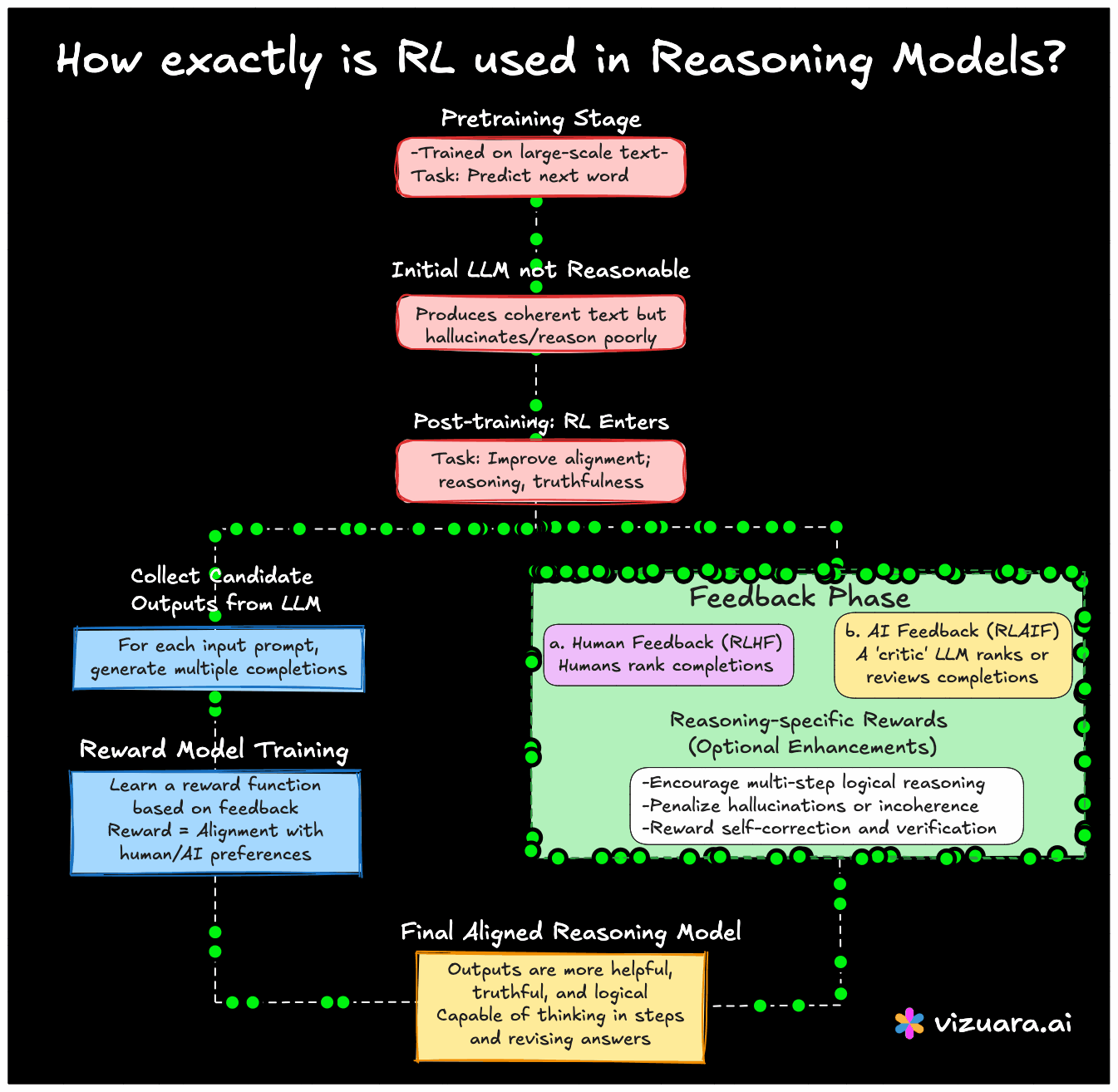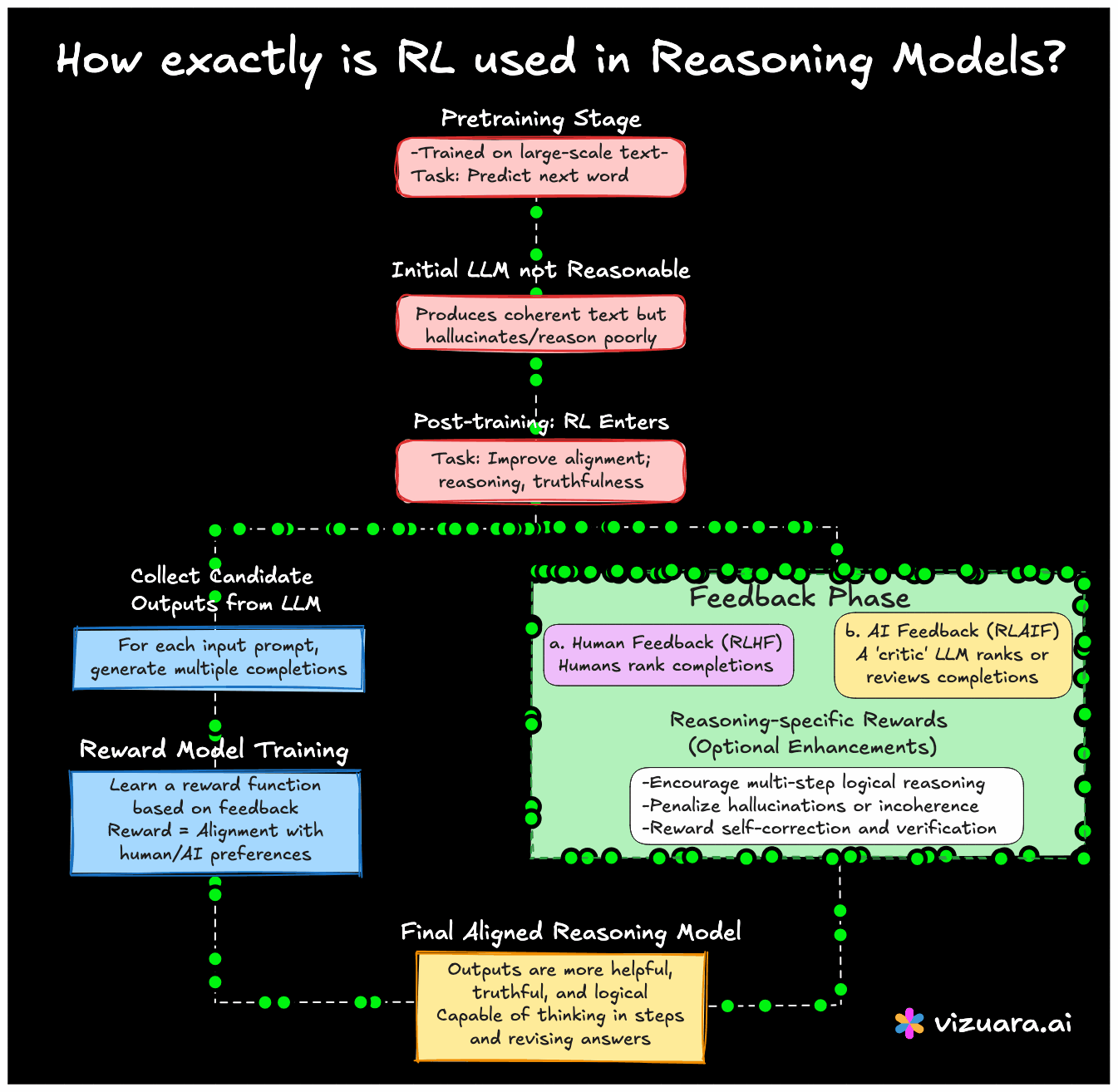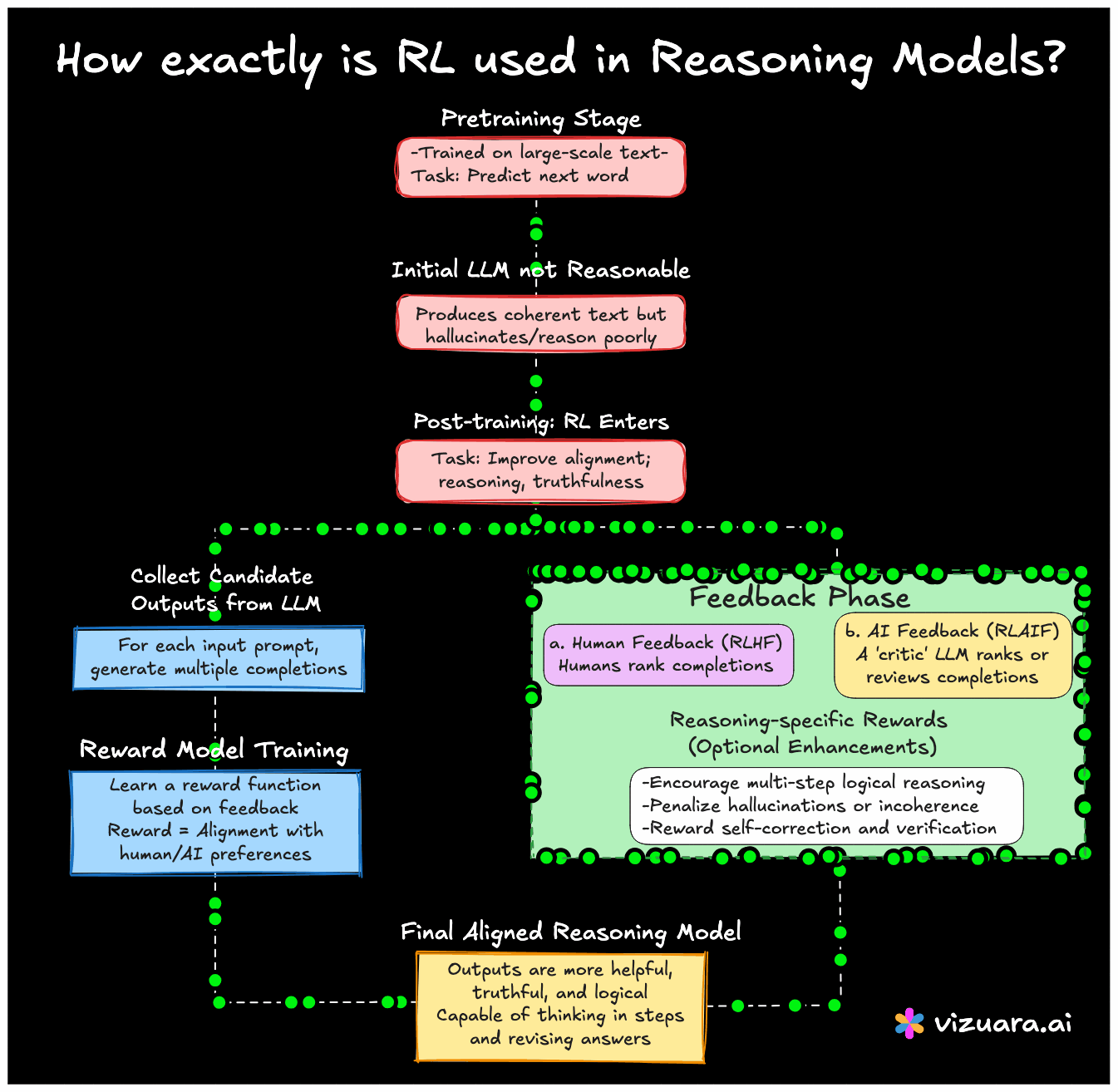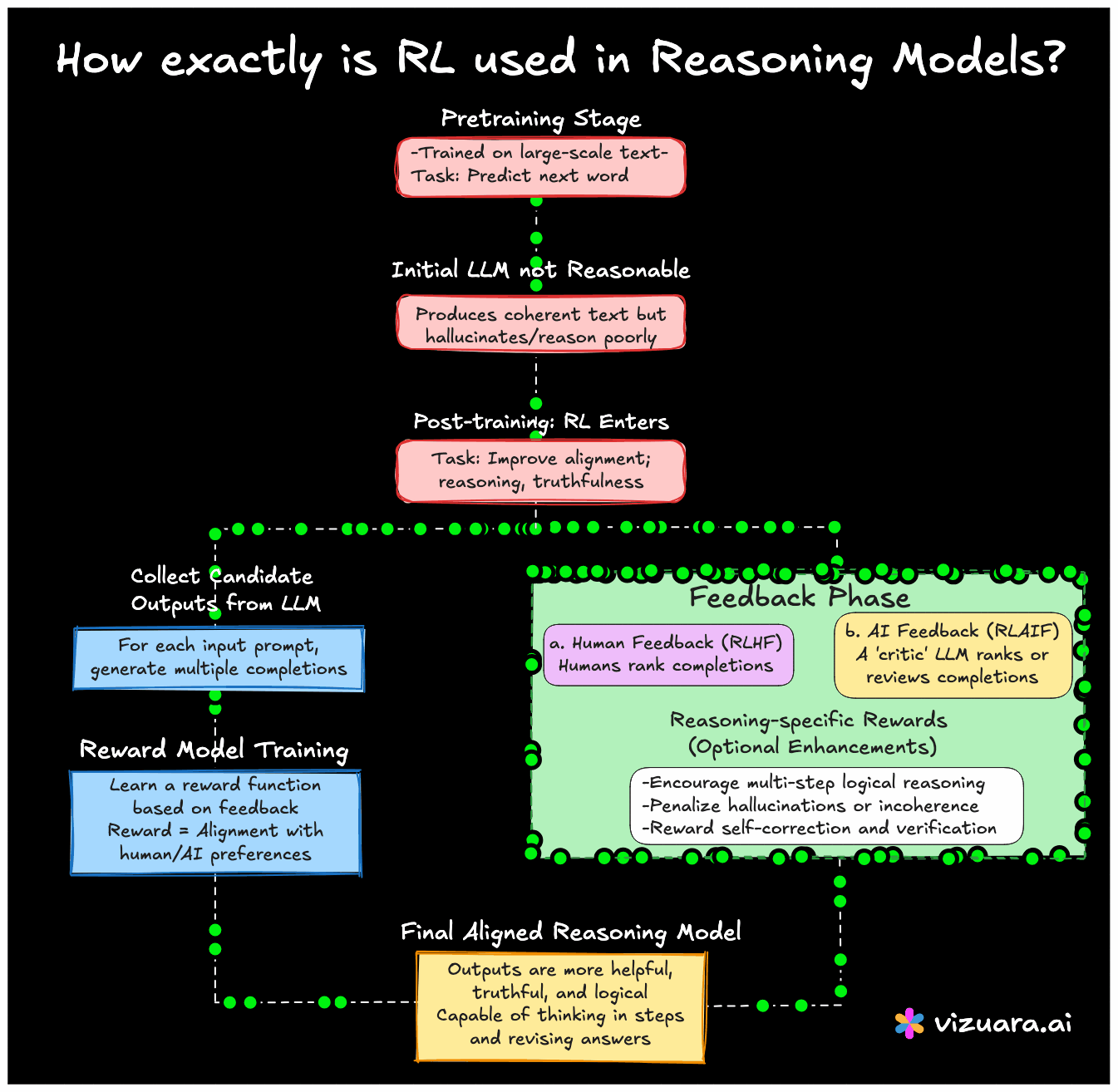
Let me explain how this works. First, we must understand that language models are initially trained in a standard way, using supervised learning on massive datasets of text. This is called "pre-training". The model learns to predict the next word given previous words. But this phase alone does not teach the model how to reason well.
So, after pretraining, models like ChatGPT, Claude, Gemini, or any reasoning-oriented model go through a post-training phase. This is where RL enters the picture. Unlike supervised learning there are no fixed labels. Instead, models are refined by giving them feedback. This feedback might come from humans or from other models.
One popular approach is Reinforcement Learning from Human Feedback (RLHF). Here, the model generates multiple completions for a given prompt. Humans then rank these completions. The model learns a reward function that tries to mimic human preferences. Once this reward function is ready, RL is applied using a variant of Proximal Policy Optimization (PPO) which helps the model learn a policy that is more aligned with human expectations.
Now here comes the interesting part. In reasoning models, we do not just want fluent language. We want the model to think in steps, verify answers, and revise its reasoning. Some research teams have used reward functions that explicitly favor multi-step reasoning chains, or penalize hallucinations. For example, f a model solves a math problem correctly in multiple steps, it is given a higher reward than just giving the final answer. In others, if the model catches its own mistake, it is rewarded for that.
Instead of physical environments like a robot would use, these models interact with textual or symbolic environments. For instance, a reasoning model may be asked to solve puzzles, play logic games, or operate in a text-based world where each move is a logical inference.
And it is not just human feedback anymore. Many recent models use AI feedback to scale things up. Here, an assistant model critiques the response of a student model. This whole pipeline can also be framed as a reinforcement learning loop.
In short, RL is being repurposed in a very powerful way to shape the behavior and reasoning style of language models. It helps move the models away from just parroting data, and towards becoming more helpful, truthful, and safe. It does not replace the need for massive pre-training, but it adds a critical outer loop that helps align the model with goals that are harder to define using fixed labels.
If you find this area as fascinating as I do, especially the role of RL in aligning and improving reasoning LLMs, then you will enjoy our upcoming bootcamp on RL at Vizuara, led by Dr. Rajat Dandekar. The lectures start tomorrow [Aug 1st]: https://hands-on-rl.vizuara.ai/
We have a 3-in-1 bundled bootcamp set too for you to check out: https://3-in-1.vizuara.ai/