
How 3×3 Filters Changed Everything? The VGGNet Story
How this legendary paper with 145k+ citations threatened the dominance of AlexNet


When the Oxford Visual Geometry Group (VGG) released their paper in 2014, it did not come with flashy new layers, exotic activation functions, or radical ideas.
What it offered instead was a revolution in restraint.
Replace large, complicated convolution filters with stacks of simple 3×3 filters.
Go deeper, not wider.
This small idea became a giant leap for computer vision.

What was happening before VGG
Between 2014 and 2016, the deep learning community faced a major question: "how can we improve CNN performance without exploding compute and parameter costs?"

Back then, CNNs were like handcrafted machines:
AlexNet used a mix of 11×11, 5×5, and 3×3 filters.
Researchers played with architecture like artists with brushes - but lacked structure.
Networks were shallow by today’s standards - 5 to 8 learnable layers.
The idea that going deeper and using only small 3×3 convolutions could outperform these handcrafted giants?
That was radical.
The VGG hypothesis
Karen Simonyan and Andrew Zisserman (authors of the VGG paper) asked:
Can we get better performance by stacking multiple 3×3 convolutions, instead of using bigger filters?
Turns out - you can. And it is elegant.
A quick recap on what we were doing in the Computer Vision course so far

Why was VGGNet such a big deal?
VGG was a major milestone in the evolution of deep learning for computer vision. Despite its simplicity, it had a lasting impact.

Simplicity with depth
Before VGG, architectures like AlexNet had a mix of kernel sizes (11×11, 5×5, etc.).
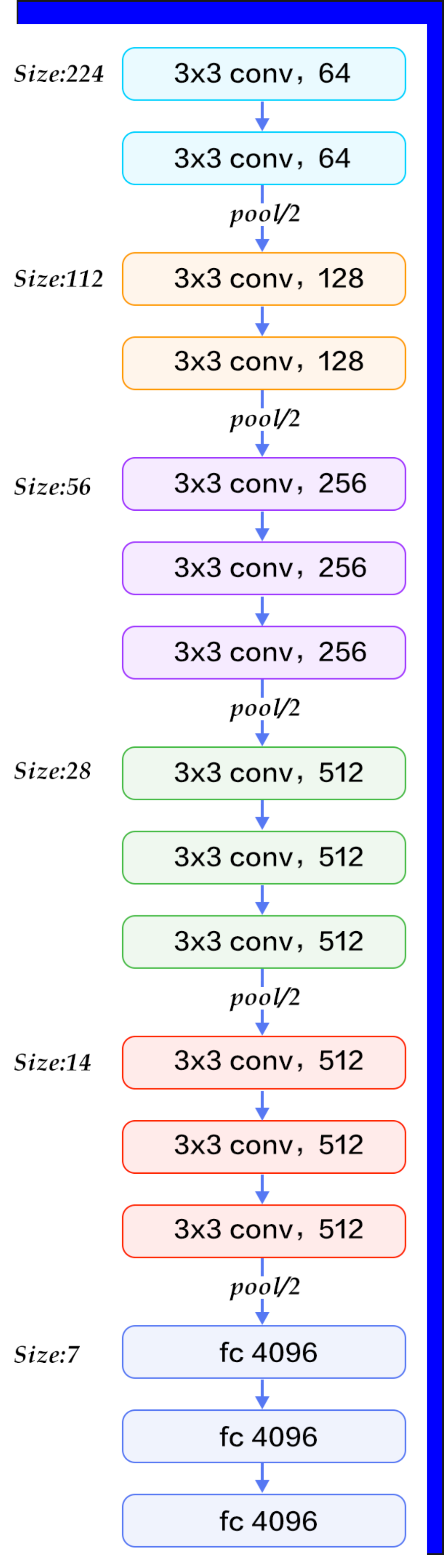
VGG used only 3×3 convolutions, stacked deeper:
This proved that depth alone could drastically improve accuracy.
It provided a clean, modular architecture that was easy to reason about.
Stacking small filters
VGG replaced larger kernels (like 5×5 or 7×7) with multiple 3×3 filters:
This gave the same effective receptive field.
But it introduced more non-linearity and fewer parameters.
This concept shaped how modern CNNs are designed (e.g., ResNet, DenseNet, etc.).
Pretrained backbone
VGG16 and VGG19 became the go-to pretrained models for transfer learning.
Even today, many models use VGG as a feature extractor in tasks like object detection, segmentation, and style transfer.
Benchmark performance
VGG16 placed 2nd in the 2014 ImageNet Challenge, just behind GoogLeNet (Inception).
It outperformed older models like AlexNet by a large margin.
Deeper networks generalize better when trained properly.
Blueprint for modern CNNs
Many subsequent architectures (e.g., ResNet, UNet, MobileNet) drew structural ideas from VGG’s block-wise design.
It popularized "block-based thinking" in CNN design.
VGG architecture


Code implementation
Here I am providing the main code snippets and have highlighted the key parts of the code. If you want the full code (Google Colab) go to the end of this article.
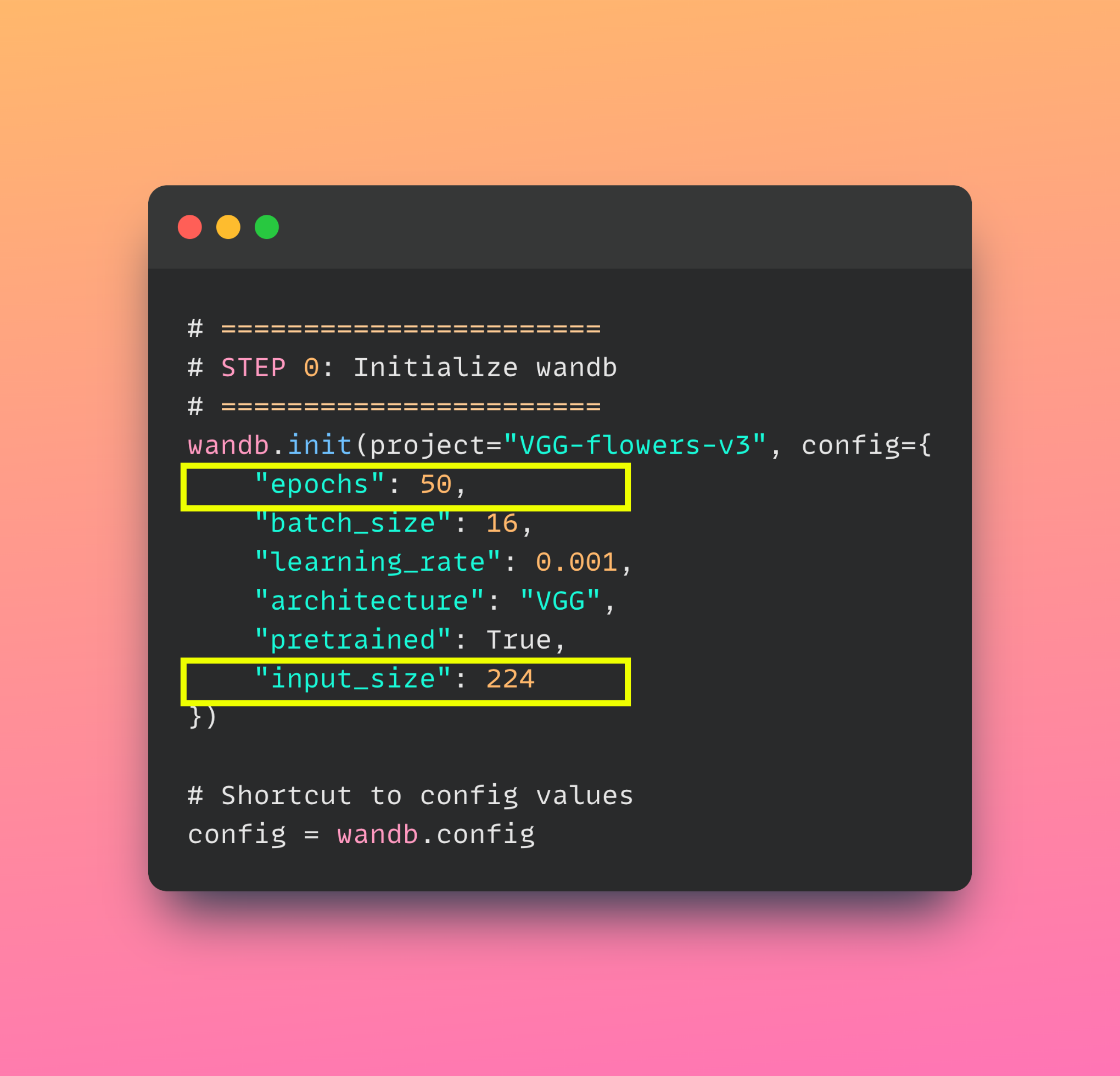

Surprising results (val_accuracy>train_accuracy )
Our results are very surprising. Training accuracy is ~75% and the validation accuracy is 85%. This is a new and interesting problem in our computer vision journey.
We froze most VGG layers and only trained the classifier.
The pretrained convolutional layers already work well on natural images (like flowers).
The classifier may not have fully adapted to the training set yet, but the validation set happens to align well with the ImageNet-style features.
📌 Conclusion: Higher validation accuracy in early epochs often indicates good generalization from pretrained features - not overfitting.

YouTube Lecture
Google Colab access for full code
Link: https://colab.research.google.com/drive/1a6tulaI78ssvcdCcijd8a9iJnUn0uE-m?usp=sharing
Interested in learning AI/ML LIVE from us?
Check this out: https://vizuara.ai/live-ai-courses