
From Vibes to W&B: How to escape the chaos of caveman ML workflows
Or: How I stopped worrying and learned to track my experiments like a grown-up.


First, some context: The course
Right now, I am teaching a course called Computer Vision From Scratch - a gentle but deep dive into the world of image classification, feature extraction, and neural network construction. No Keras. No PyTorch. Just raw NumPy, intuition, and pixels.
We're currently working on a classic problem: building a neural network to classify images from the 5-Flowers dataset - five classes, five folders, and plenty of room to mess things up beautifully.
We started by:
Implementing our own forward and backward passes
Manually tracking accuracy and loss
Writing spaghetti code that grew with every new test
It was fun. It was educational. It was also chaotic as heck.
The Hyperparameter Jungle
Once we had a working neural net, we wanted to answer a natural question:
"What architecture and settings actually perform best on this dataset?"
Which led us straight into the wild west of hyperparameter tuning.
Learning rates, layer sizes, batch sizes, regularization values... we were tweaking everything. And with every change came:
New Colab tabs
More copy-pasted code
And a growing Excel sheet of logs that looked like an accountant’s fever dream
We were running experiments like cavemen discovering fire - just vibes, no structure.

The evolution: Enter Weights & Biases (W&B)
That’s when I introduced the class to Weights & Biases (W&B) - an online experiment tracking tool built exactly for this.
We’re not talking about weights and biases inside your neural net (though we have those too). This is a full platform that helps you log, visualize, compare, and manage your machine learning experiments.
Suddenly, everything clicked:
Each training run was tracked automatically
Metrics were updated in real-time
Sweep configurations let us run dozens of experiments automatically
Dashboards helped us instantly spot which hyperparameters actually mattered
The best part? My students could see the change in their workflow. From frantically copy-pasting into different tabs, we now had a single interface to run, review, and reflect.
Weights and Biases AI developer platform: https://wandb.ai/site/

Why does W&B matter?
Training a model to classify five types of flowers? That sounds simple.
But finding the best-performing model? That’s where things get messy.
You need:
✅ A place to log every training run
✅ A way to compare hyperparameters across experiments
✅ A dashboard that actually tells you what’s working
✅ Automation to run sweeps while you get coffee (or cry into it)
W&B does all of that - and does it with ✨ style ✨.
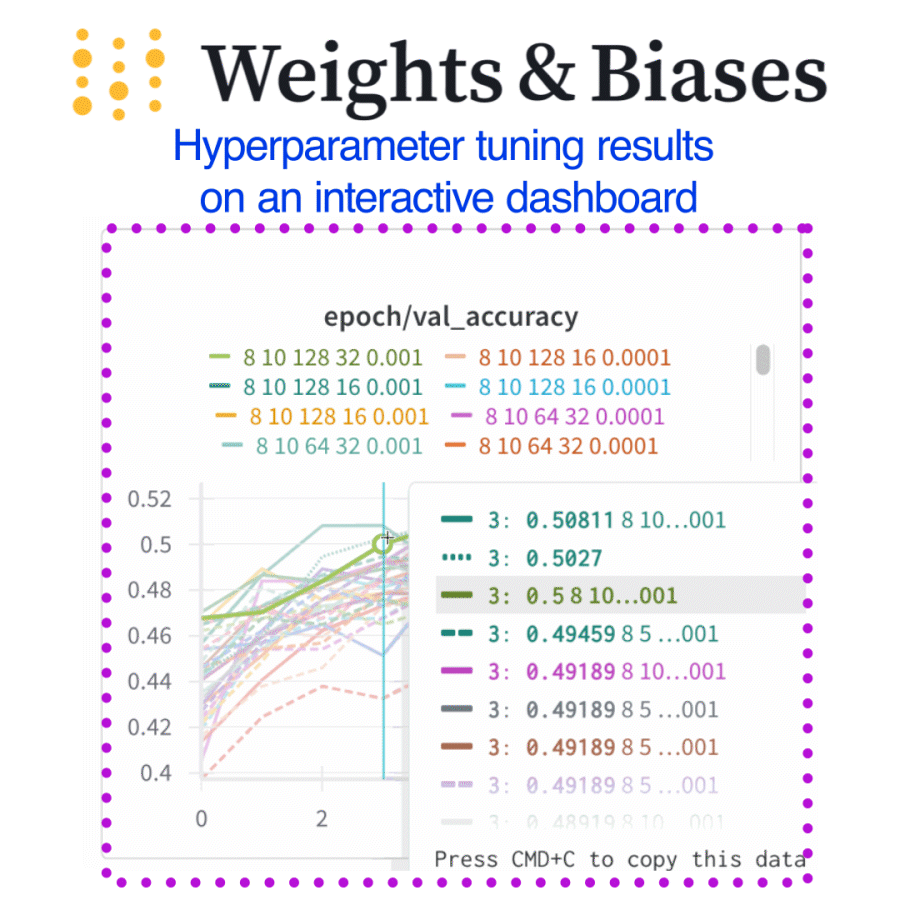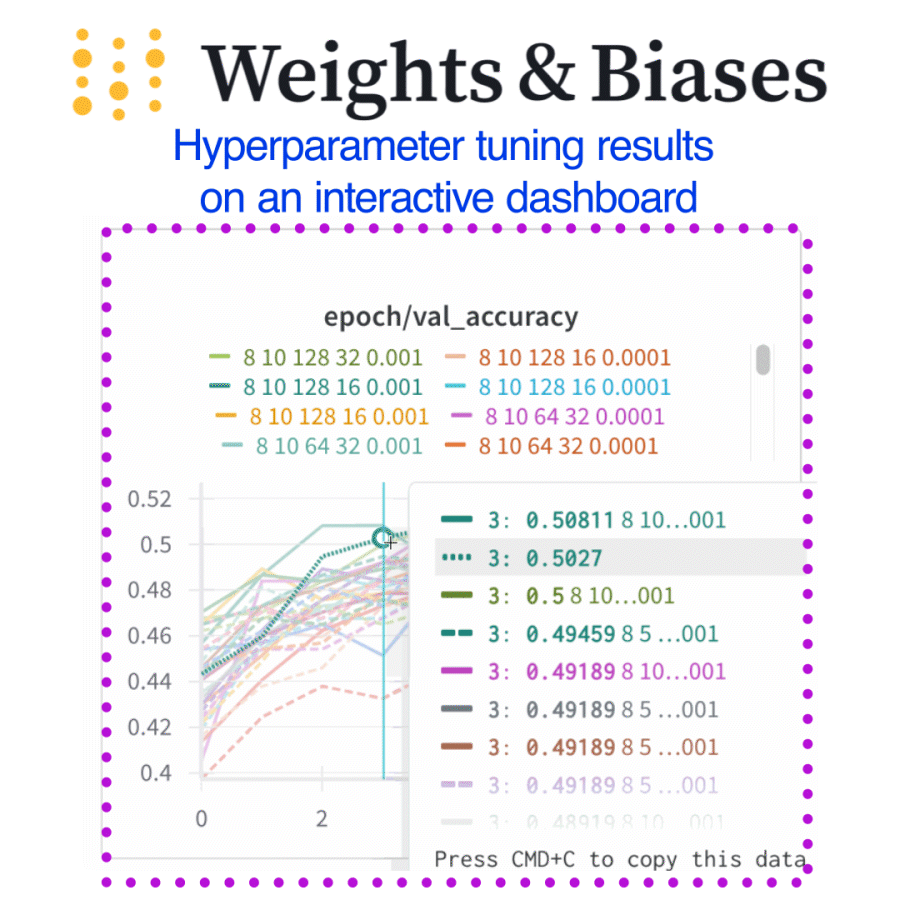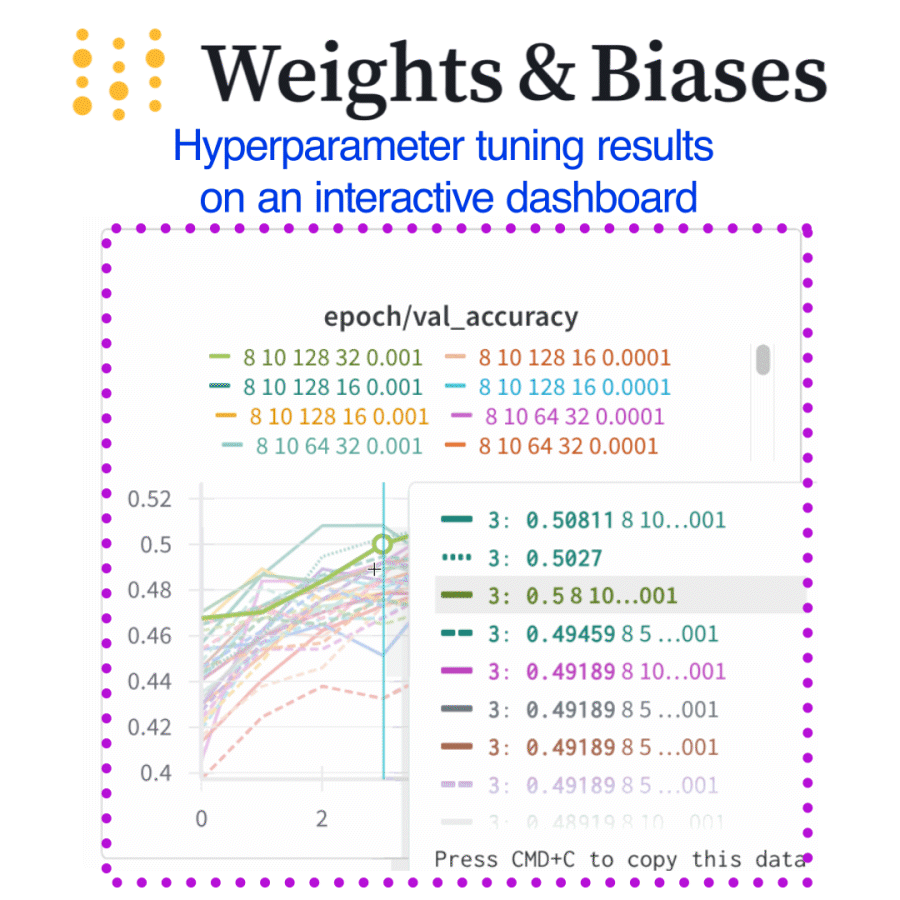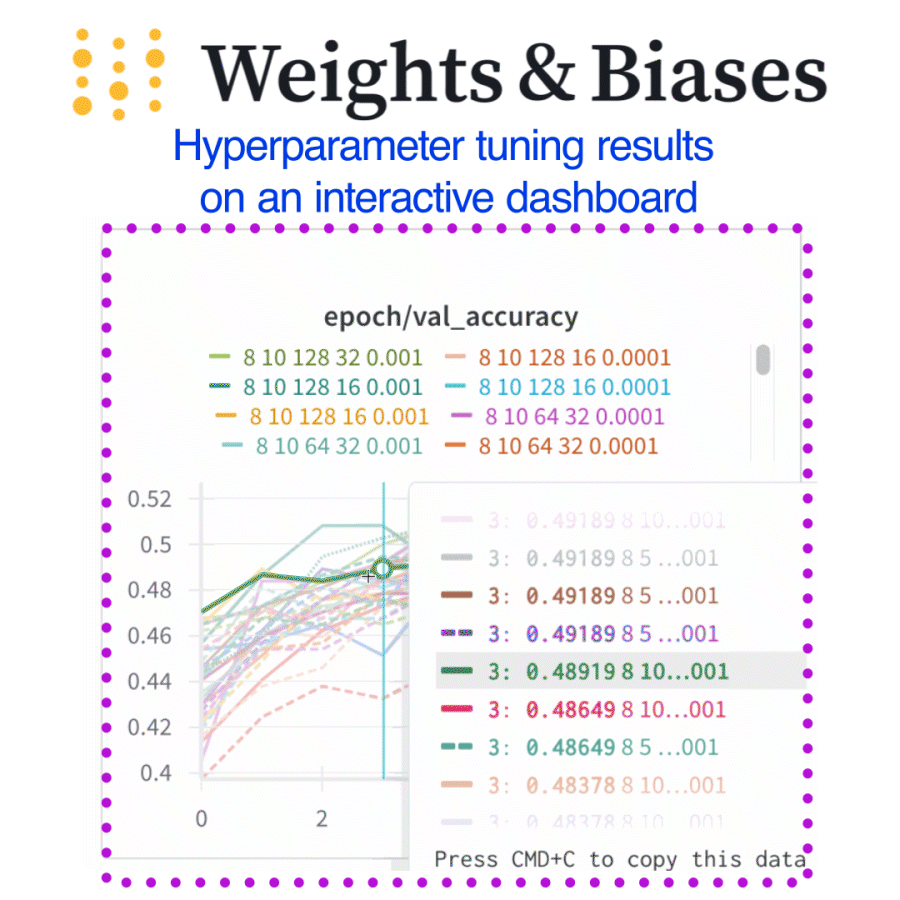
What I did (and you can too)
In this week’s hands-on walkthrough, we covered:
1) How to integrate W&B into your Colab notebook
2) How to set up a sweep config file to automate hyperparameter tuning
3) How to visualize your training metrics live and identify what actually matters
Whether you are working with small flower datasets or scaling up to large CV projects, this changes how you think about experimentation.
Full walkthrough (YouTube)
📓 Colab Notebook (Code + W&B Setup)
💻 Open it here
🧠 Miro Board (Visual Summary)
📌 https://miro.com/app/board/uXjVICgM8TA=/?share_link_id=142770200927
Interested in learning ML foundations?
Check this out: https://vizuara.ai/self-paced-courses