
Engineering CI/CD Pipelines for Machine Learning Systems
This article delves into the concept of CI/CD, explaining its fundamentals and highlighting its importance in building reliable, scalable, and automated real-world systems.


Table of Contents
Introduction
The Pre-CI/CD Era
The CI/CD Revolution for ML Systems
Breaking Down the Concepts
4.1) Continuous Integration (CI)4.2) Continuous Delivery (CD)
4.3) Continuous Deployment
CI/CD Workflow
CI/CD Pipeline Architecture
Security in CI/CD (DevSecOps for ML)
Benefits of CI/CD in ML Production
Summary
1) Introduction
In classical software engineering, CI/CD pipelines are built to automate the build, test, and deploy cycles for deterministic codebases. The workflow is predictable code changes go in, tests run, binaries get built, and deployments roll out.
But in machine learning, CI/CD has a tougher job. It doesn’t just deal with code,it has to continuously integrate and validate data, models, and infrastructure, each evolving on its own timeline. A new dataset can shift performance, a retrained model can introduce bias, and a dependency update can break reproducibility.
That’s why a well-architected ML CI/CD pipeline does more than just automate releases — it enforces discipline across the entire lifecycle:
Ensures reproducible model training and validation, regardless of environment drift.
Maintains versioned, traceable deployments with safe rollback mechanisms.
Enables secure, automated promotion of models from experimentation → staging → production, with built-in compliance and auditability.
At its core, ML CI/CD reduces the “human surface area” in production workflows. It lets automation handle what humans shouldn’t , enforcing reliability, reproducibility, and speed in systems where both code and data are constantly in motion.
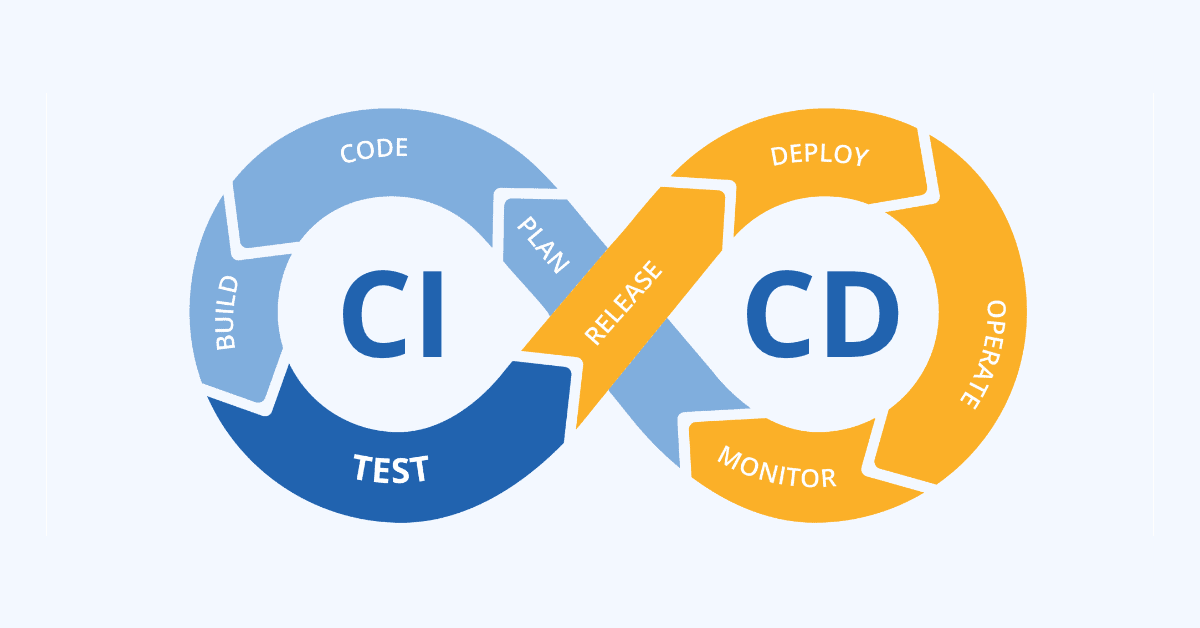
2) The Pre-CI/CD Era
Before automation, ML deployments looked like fragile science experiments:
Models were trained locally with inconsistent environments.
Integrations happened rarely , merge conflicts and broken dependencies were routine.
Data pipelines and model artifacts lacked version control.
Deployment scripts were ad hoc Bash files, run manually by ops engineers.
The result was low reproducibility and high friction. Debugging production failures was painful because no two environments were identical.
CI/CD solved this by codifying integration, testing, and delivery into repeatable automation units.

3) The CI/CD Revolution for ML Systems
Traditional CI/CD pipelines focus on deterministic software delivery automating the build, test, and deployment stages for application code. This workflow ensures that every code change passes through a consistent, repeatable integration process before being released to production.
In machine learning systems, however, the CI/CD scope expands significantly. The pipeline must manage not only code but also data, models, and infrastructure, each evolving asynchronously. A mature ML CI/CD pipeline typically includes:
Code + Data Versioning: Managed through tools like Git, DVC, or LakeFS to maintain lineage and ensure reproducibility.
Model Training Orchestration: Automated using MLflow, Kubeflow Pipelines, or Airflow, enabling consistent retraining and experiment tracking.
Model Validation & Drift Detection: Continuous evaluation pipelines to detect accuracy degradation and data distribution shifts.
Containerization: Packaging artifacts as Docker or OCI-compliant images for portable and consistent runtime environments.
Automated Deployment: Leveraging CI/CD engines such as GitHub Actions, GitLab CI, Jenkins, or ArgoCD to promote models from staging to production.
Monitoring & Rollback: Integration with Prometheus, Grafana, Seldon Core, or EvidentlyAI to track model performance, detect anomalies, and trigger safe rollbacks.
Each commit in this setup triggers an end-to-end validation cycle, verifying not just the correctness of the code but also the reproducibility, data integrity, and real-time performance stability of the deployed model.
Uber’s internal ML platform, Michelangelo, is a real-world example of CI/CD for ML at scale.

This system allows Uber to safely and continuously deploy ML models for services like ETA prediction, surge pricing, and fraud detection, all under a reproducible and automated CI/CD framework.
4) Breaking Down the Concepts
4.1) Continuous Integration (CI)
Goal: Keep the main branch always buildable and testable.
Each commit runs through:
Pre-commit hooks: code linting (
flake8,black), schema checksBuild stage: packaging with
setup.pyor containerizing with DockerUnit + Integration Tests: executed via
pytestorunittestStatic Analysis:
mypy,bandit,sonarqubefor code security and quality
Key CI YAML Example (GitHub Actions):
name: CI
on: [push]
jobs:
build-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Python
uses: actions/setup-python@v5
with:
python-version: “3.10”
- name: Install Dependencies
run: pip install -r requirements.txt
- name: Run Tests
run: pytest --maxfail=1 --disable-warnings -q
This ensures that every pushed commit triggers an automated sanity check before merging into main.
4.2) Continuous Delivery (CD)
Goal: Maintain a deployable state at all times.
In ML systems, CD also means that model artifacts, dependencies, and metadata are versioned and retrievable.
Typical CD pipeline:
Retrieve the validated model from Model Registry (e.g., MLflow).
Package it into a Docker container with runtime dependencies.
Deploy to staging using IaC (Terraform, Helm, or ArgoCD).
Run integration smoke tests against live services.
Await human approval → promote to production.
This guarantees that every artifact passing through the pipeline is reproducible, verifiable, and traceable to its source commit and data snapshot.
4.3) Continuous Deployment
In mature systems, even the approval step is automated.
Every successful build + validation run is automatically promoted to production.
This requires:
Canary or blue-green deployment architecture.
Real-time monitoring and automatic rollback triggers.
Feature flagging for progressive rollout (LaunchDarkly, Unleash).
Key principle: deploy small, deploy often, detect early.
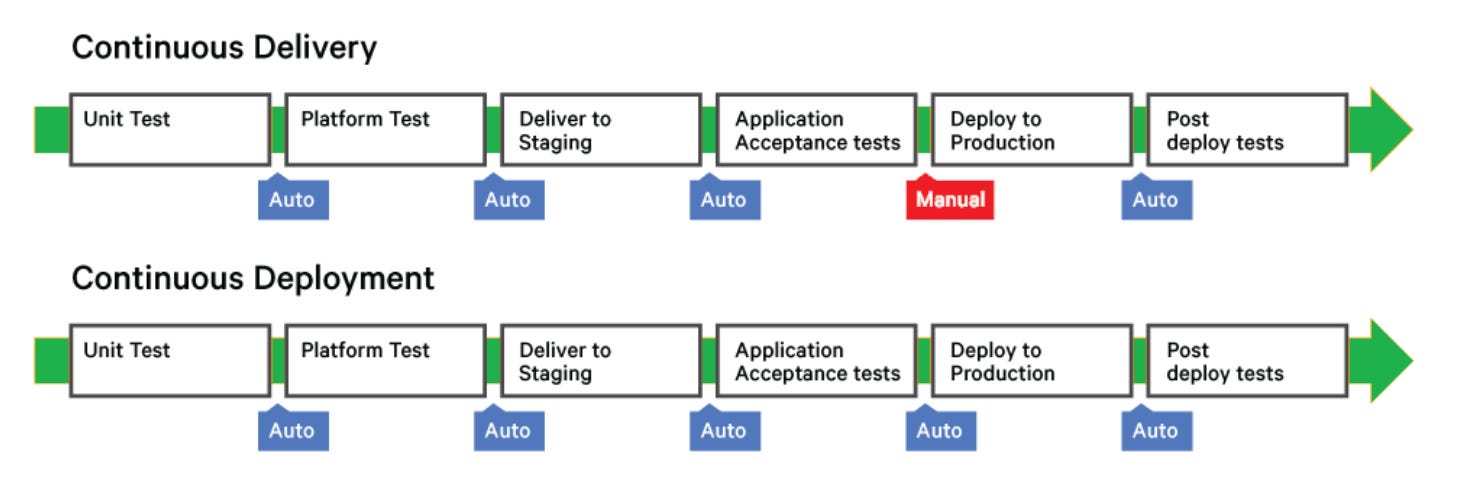
5) CI/CD Workflow
Below is the canonical ML CI/CD workflow:
Code Commit → Build → Test → Model Train & Validate → Containerize → Deploy → Monitor → Rollback (if needed)
Workflow Deep Dive
Commit & Trigger: Every push to the main or feature branch invokes an automated ML-aware pipeline via Git hooks or CI runners. Metadata such as commit hash, dataset version, and environment fingerprint are captured instantly.
Build Phase: The environment is containerized into immutable Docker/OCI images or versioned as reproducible Python wheels. Dependency locks and environment manifests (e.g., Conda, Poetry) ensure deterministic builds.
Validation Layer: Unit, integration, and model-centric tests run in parallel — including schema validation, data sanity checks, and offline evaluation against reference metrics.
Model Lifecycle Execution: The pipeline either triggers a retrain using the current data snapshot or promotes an existing model from the registry (MLflow, S3, or Weights & Biases). Each artifact is version-tagged and lineage-tracked.
Progressive Rollout: Deployment follows a controlled promotion path — shadow, staging, and production — often using blue-green or canary strategies to reduce downtime and risk.
Continuous Monitoring: Post-deployment observability tracks latency, prediction drift, feature skew, and accuracy decay. Real-time dashboards built on Prometheus, Grafana, or EvidentlyAI enable rapid anomaly detection.
Closed Feedback Loop: If performance or drift thresholds are breached, automated triggers initiate rollback or retraining workflows, maintaining a self-healing model ecosystem.
All pipeline events are streamed into centralized observability stacks like ELK, Loki, or CloudWatch, providing full traceability and compliance-ready audit trails.
6) CI/CD Pipeline Architecture
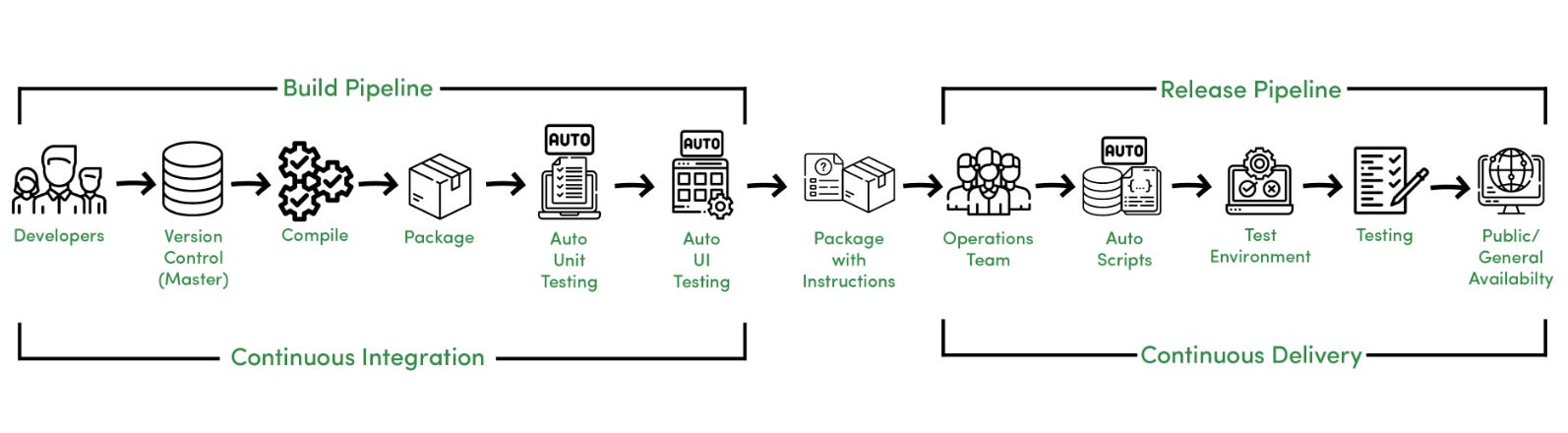
The image above illustrates the Continuous Integration and Continuous Delivery (CI/CD) Pipeline, which differs from the traditional Software Development Life Cycle (SDLC) in several key ways.
In a CI/CD setup, developers collaborate on a shared code repository, ensuring all updates are version-controlled and integrated frequently. Once the code is committed and compiled, automated unit and UI tests are executed to validate functionality. The operations team then leverages automated deployment scripts to push the build into the testing environment. After thorough testing and approval, the validated software is promoted to the production environment.
In this workflow, Continuous Integration corresponds to the Build Pipeline, encompassing code integration, compilation, and testing. Continuous Delivery, on the other hand, represents the Release Pipeline, where the tested artifacts are staged and made ready for deployment.
When this final promotion to production occurs automatically without any manual approval step, the process advances from Continuous Delivery to Continuous Deployment.
7) Security in CI/CD (DevSecOps for ML)
As pipelines automate everything, they also become a prime attack surface.
DevSecOps integrates security directly into build and deploy stages:
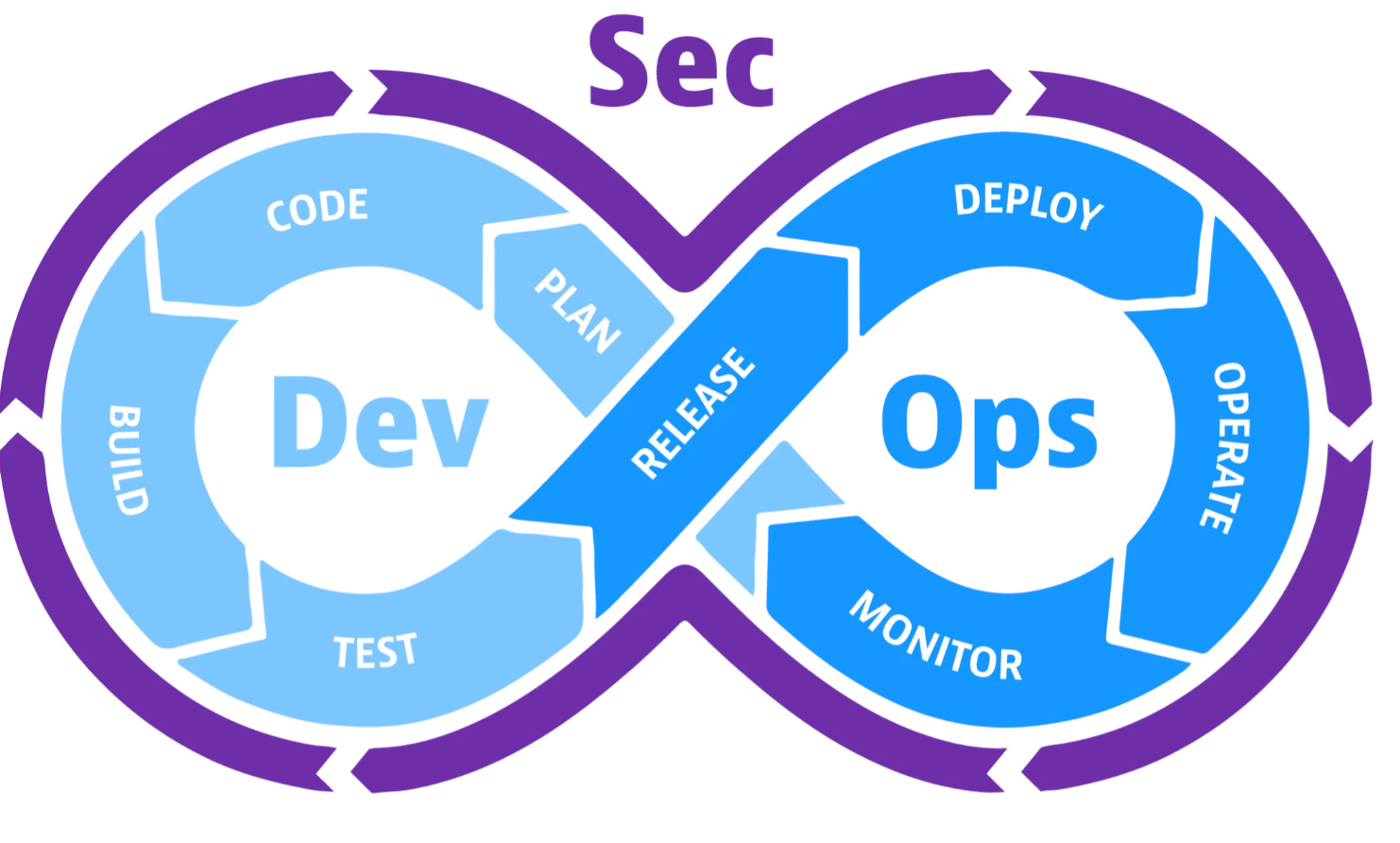
Key Security Measures:
SAST (
bandit,sonarqube) → Detect insecure code patternsDependency Scanning → Identify vulnerable Python packages
Container Scanning → Check base images for CVEs (
trivy,grype)Secrets Management → Vault or GitHub Actions secrets
Signed Artifacts → Use cosign / Notary for container signing
IAM Hardening → Restrict pipeline credentials to least privilege
Shift-left security philosophy ensures that vulnerabilities are eliminated before deployment, not after compromise.
8) Benefits of CI/CD in ML Production
End-to-End Reproducibility: Same commit, same container, same result.
Continuous Experimentation: Models retrain automatically on new data.
Reduced Downtime: Canary rollouts + health checks ensure safe deployment.
Auditable Lineage: Every artifact linked to data, code, and config versions.
Scalable Governance: Automated policy checks ensure compliance (GDPR, SOC2).
Faster Research to Production Cycle: Reduces time from notebook → live API.
Summary
CI/CD isn’t just a DevOps concept — it’s the infrastructure backbone of modern ML systems.
When combined with model registries, IaC, and automated monitoring, it transforms ML deployment from art to engineering.
In the next Article we’ll go beyond theory, implementing a real ML CI/CD pipeline using:
GitHub Actions for CI
MLflow for model registry
Docker + ArgoCD for deployment
Prometheus + Evidently for live monitoring
To know more about this please have a look at the video