
DenseNet and EfficientNet are 1/20th the size of VGG16...
Yet they worked brilliantly for us. How?


Introduction
Today I want to take a moment to talk to you not just about two models and not just about two architectures with clever designs, but about two very different ways of thinking. These are two philosophies that quietly reshape how we approach the design of neural networks and they force us to think more deeply about connection, balance, and efficiency.
Because as we move forward in our journey of deep learning, it is no longer enough to simply add more layers to a problem or blindly increase parameters without understanding what we are building and why we are building it.
And that is what makes DenseNet and EfficientNet worth studying, not just because they are academically cited or practically useful (which they are), but because they each carry with them a certain clarity of thought that we often forget to look for.
The journey so far
Throughout our computer vision journey, we have traced the evolution of convolutional neural networks beginning with AlexNet and VGG, which were foundational but heavy and inflexible, and moving toward more efficient and modular designs like GoogleNet, ResNet, SqueezeNet, and MobileNet, each of which introduced critical improvements in structure, performance, or deployability.
Each model offered something different. Some reduced parameter count, some solved the vanishing gradient problem, some made models smaller and faster, while others focused on extracting richer features from the same data. What connected them all was the pursuit of progress, of building better tools to make sense of images and patterns.

And today, we add to that list DenseNet and EfficientNet, two architectures that do not just work well but also make us pause and reflect on what it means to design a good neural network.
DenseNet: The power of connection
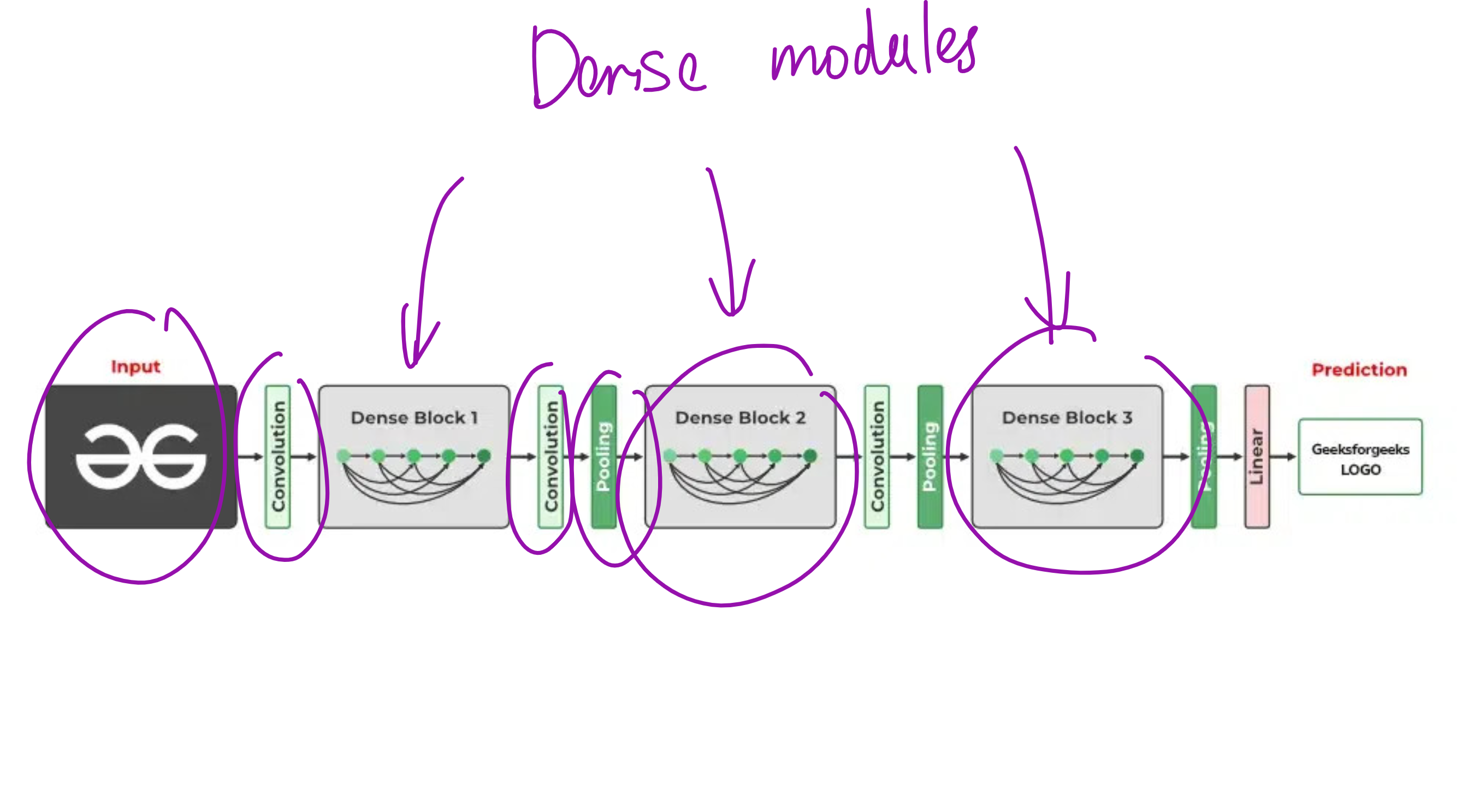
DenseNet, which stands for Densely Connected Convolutional Network, is built on a beautifully simple idea that challenges the convention of sequential layer design. Instead of passing information from one layer to the next in a straight line, DenseNet introduces the idea that every layer should be connected to every layer that comes after it.


This means that if you are at layer six, you are not just getting input from layer five. You are receiving inputs from layers zero, one, two, three, four, and five. Each layer inherits all the knowledge that has been built before it.

The impact of this is profound. DenseNet improves gradient flow, solves the vanishing gradient problem that plagued earlier deep models, encourages feature reuse instead of redundancy, and reduces the need to relearn the same representations over and over again.
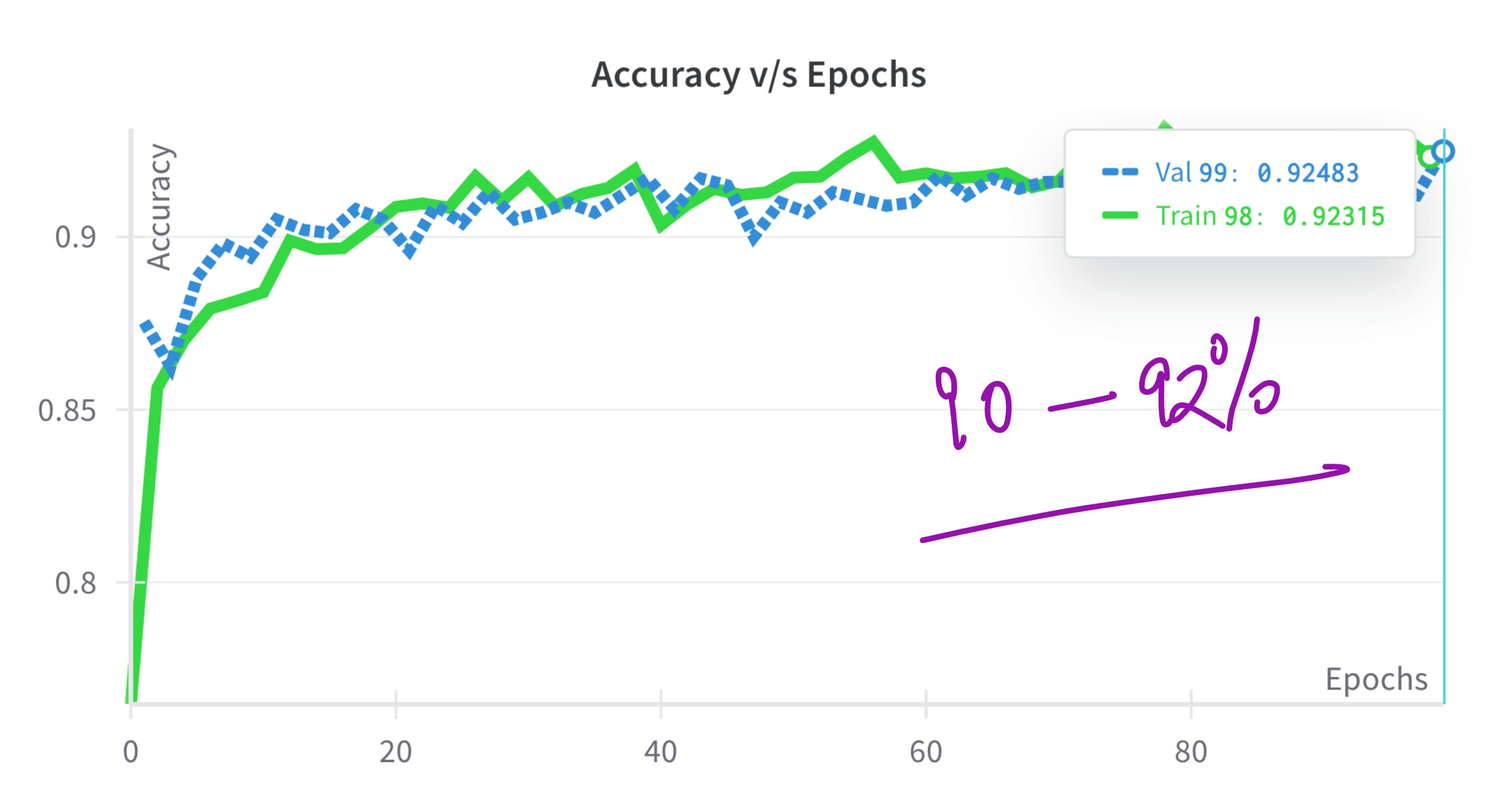
When we implemented DenseNet121 on our five class flower classification dataset, it performed with grace and efficiency. It delivered a validation accuracy between 90 and 92 percent using just 8 million parameters. For comparison, VGG has 138 million parameters and ResNet50 has over 23 million. DenseNet does more with much less.

And what is more remarkable is that because each layer has access to all previous feature maps, it can focus its energy on learning only what has not yet been learned. In a way, it learns what is left rather than what has already been discovered. This is not only efficient. It is also deeply intelligent.


DenseNet compared against other models

DenseNet applied on 5-flowers data

The below module is the dense module
On 5-flowers dataset, we are getting pretty good accuracy.
EfficientNet: Scaling with intelligence
If DenseNet is about connection, EfficientNet is about scaling. And not just scaling up randomly or intuitively but scaling correctly and systematically.
The question EfficientNet asks is very straightforward. If we want to improve a model by making it bigger, then how should we scale it? Should we increase the number of layers? Should we increase the number of channels in each layer? Should we feed the model larger images?

In the past, researchers chose one direction and hoped for the best. But what EfficientNet proposes is a way to scale all three dimensions together and in balance. It does this through a method called compound scaling. Instead of guessing how much to grow each part of the model, EfficientNet uses a mathematical formula where the depth, width, and input resolution are all increased together, based on a shared scaling factor.

Compound scaling in EfficientNet
Traditional CNNs are scaled up to improve accuracy - by adding more layers (depth), more channels (width), or using higher-resolution images. But this is often done manually and inconsistently, requiring extensive trial and error with only modest gains.
EfficientNet solves this by introducing compound scaling - a method that scales depth, width, and resolution together using a single factor. This leads to better accuracy and efficiency without increasing model size unnecessarily.

Here is the compound scaling formula used in EfficientNet.

What makes this possible is the fact that the base EfficientNet model was not designed by hand but discovered through Neural Architecture Search. This gives the network a highly optimized starting point which can then be expanded intelligently without compromising efficiency.

EfficientNet compared against other models

Experiments with 5-flowers data
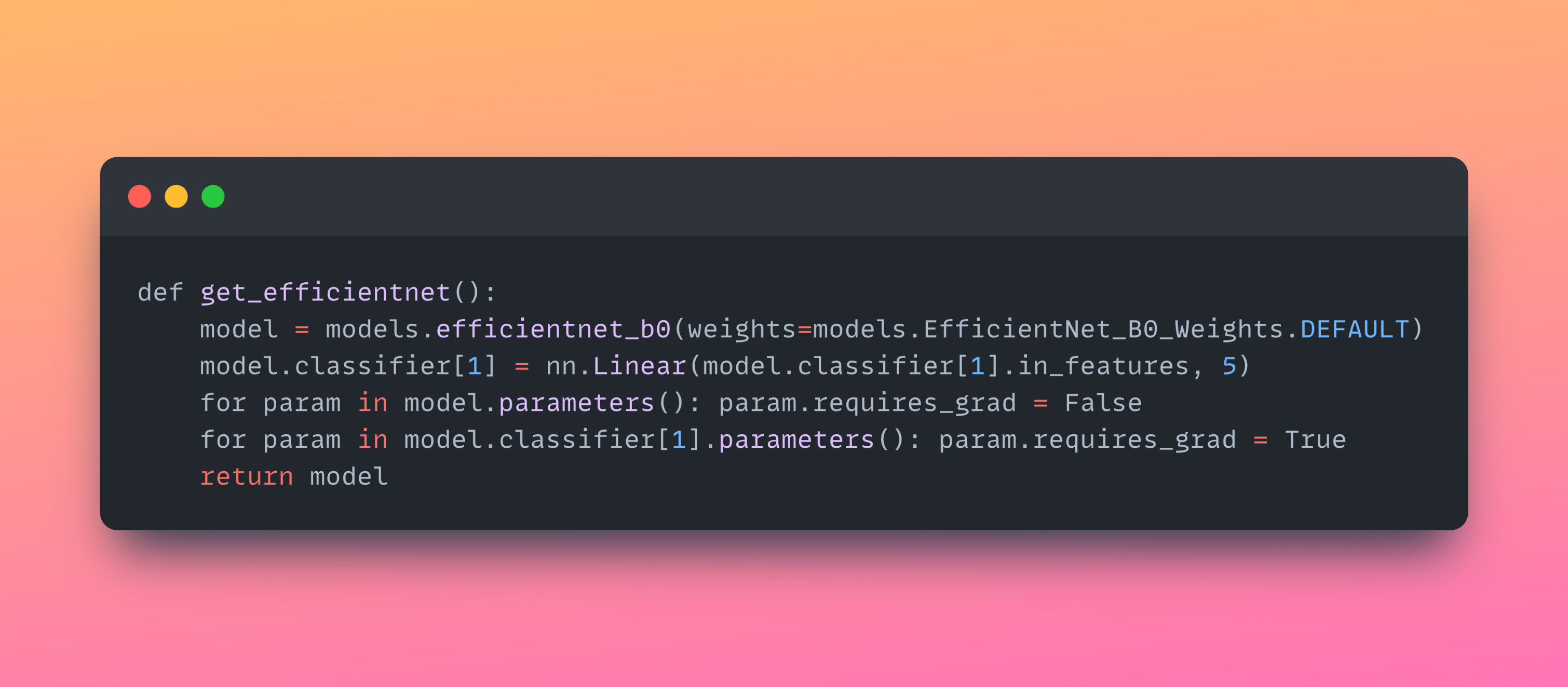
When we tested EfficientNetB0 on the same flower dataset using transfer learning, it gave us about 90 percent validation accuracy using only 5.3 million parameters and a model size of approximately 20 megabytes. It was compact, precise, and balanced in the way it grew and learned.
EfficientNet does not try to be clever with its internal wiring. Instead, it focuses on how to grow a model without losing its coherence. And in that, it succeeds.

YouTube lecture
Interested in learning AI/ML live from us?
Check this out: https://vizuara.ai/live-ai-courses