
Deep Networks Were Dying. Then ResNet Showed Up with a Bypass.
A story of how skip connections became deep learning's most effective life support system


Imagine this.
You are working with image data. You have learned about convolutional neural networks. You understand AlexNet, admire VGG, and feel kind of smart after skimming through Inception.
So naturally, you ask:
Why not just go deeper?
Deeper networks should be better, right?
That is what the deep learning community thought too.
Until reality slapped back.
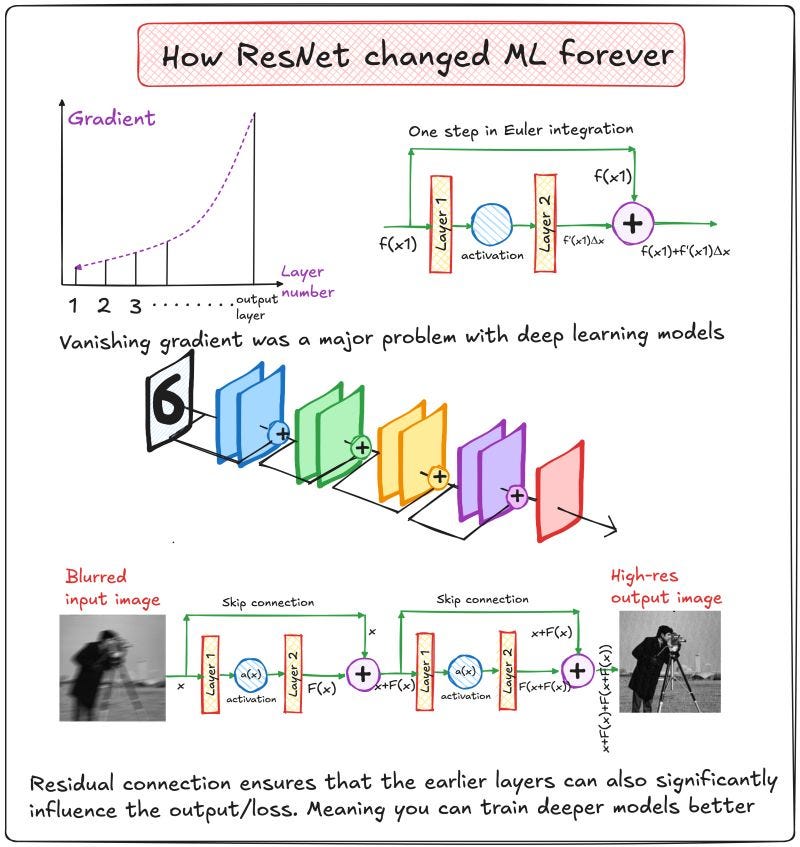
The myth of deeper is better
AlexNet (2012) showed the world what a deep-ish CNN (eight layers) could do. Then came VGG-16 (2014) with a whopping 138 million parameters and the beautiful idea that all you need is 3x3 convolutions repeated several times.

Then GoogleNet showed up with Inception modules that stacked convolutions of different sizes in parallel. It had 22 layers. Things were getting deep.
And then things broke.
People tried building 30-layer, 50-layer, and 100-layer networks. But here is what they found:
Performance got worse.

Not "plateaued" worse.
Actually worse.
Validation accuracy tanked. Training accuracy stayed low. Loss stagnated like a dead fish in a pond.
This was not overfitting. This was not a GPU issue.
This was undertraining. The models simply refused to learn.
Cue dramatic music.
The Curse of the vanishing gradient
In deep networks, the gradients get multiplied again and again as you backpropagate. If you are using activation functions like sigmoid or tanh, the derivative is always less than one (maximum 0.25 for sigmoid).

Now multiply 0.25 again and again and again across 30 layers.
You get numbers that are basically zero. Not mathematically zero, but practically useless.

The result?
Initial layers stop getting updated.
Early convolutional filters do not learn anything.
Your model becomes a fancy paperweight with 100 layers.
This is the vanishing gradient problem, and it was a major roadblock in deep learning.
Even batch normalization and careful initialization could not fully solve it.


The hero we needed - Residual Networks
In 2015, a group of researchers at Microsoft Research, led by Kaiming He, dropped a paper that would become one of the most cited deep learning papers in history.

The idea?
Let the network learn the difference, not the entire function.
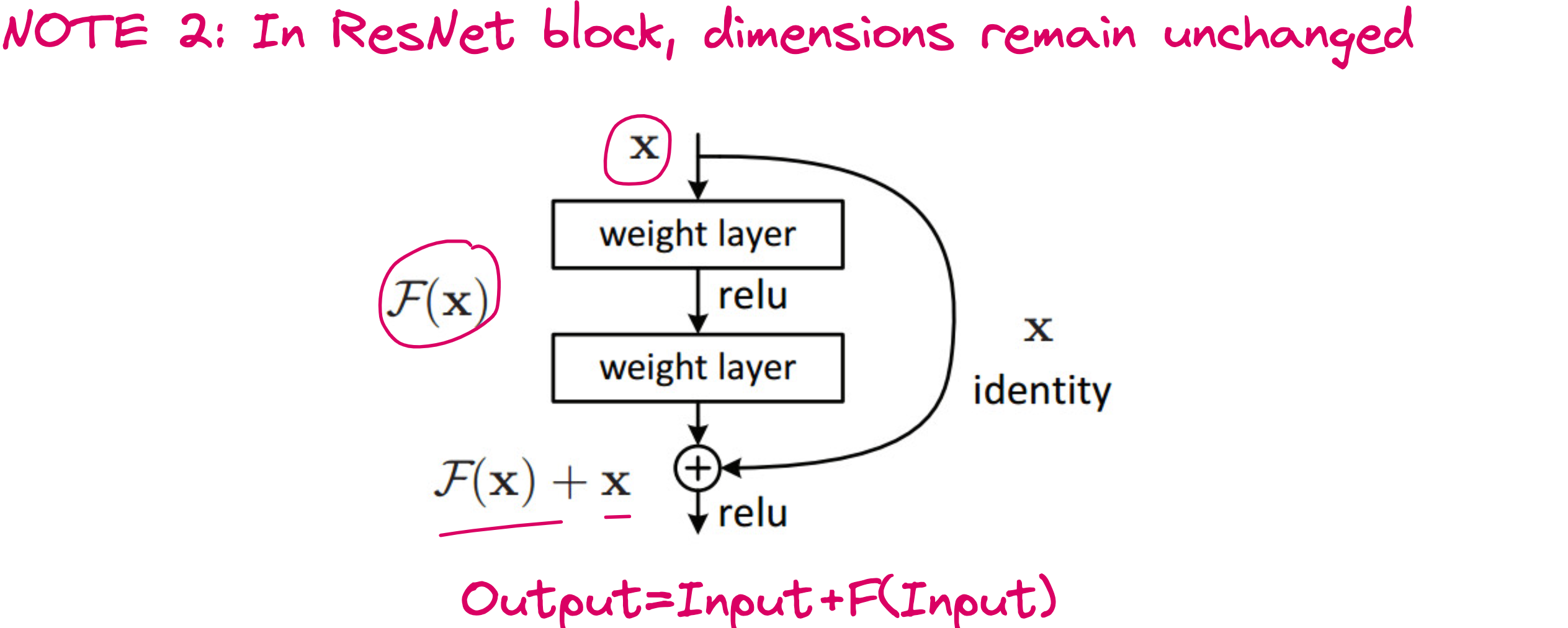
If x is the input and H(x) is the desired output, do not force the neural network to learn H(x) directly.
Instead, make it learn F(x) = H(x) - x, and then compute the final output as:
H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x
This is called a residual connection or skip connection.
The idea is so simple that you almost feel bad for not thinking of it yourself.

Here is why it works:
Gradients can flow through the skip connection directly from output back to input.
Early layers now influence the output more clearly.
Training a 100-layer network? No problem. The gradient will not vanish.
And it worked. It worked beautifully.

Why is residual link such a big deal?
Consider the task of improving the resolution of an image starting with a blurred image. You can train a neural network such that it directly predicts the final output, which is the high-resolution image.

The genius of residual learning is not just in preventing vanishing gradients.
Think of image enhancement.
Input: A blurry image
Output: A sharper image
Most of the content is already in the input. All you need is the difference — the "sharpening."
Train your network to learn just that residual and then add it to the input.
It is efficient. It is intuitive. It is scalable.

You know what else behaves like this?
Euler integration.
Yes, even numerical solvers for differential equations do something similar. Start from x, compute the small step delta, and move forward. ResNet, in a way, does this in neural network space.

Implementing ResNet on Flowers and Feeling Smart
I implemented ResNet-50 on a five-class flower dataset (daisy, dandelion, roses, sunflowers, tulips) and compared it with other models we had tried in this course.

This was the best performance so far. And the code changes were minimal:
Load
torchvision.models.resnet50with pretrained weights.Freeze all layers except the final one.
Replace the final layer with one that has 5 outputs (for 5 classes).
Train.
Watch your model crush it.
Final thoughts: A bypass that changed Deep Learning
ResNet was not about fancy architectures.
It was not about parallel convolutions, multi-scale filters, or compression.
It was about a simple skip. A shortcut. A bypass.
And that changed everything.
Today, ResNet variants like ResNet-101 and ResNet-152 are standard in classification, object detection, segmentation, and even generative tasks.
And to think it all started because someone asked,
"Why learn everything when you can just learn the change?"
If you have been struggling with training deep CNNs, go back to basics. Try ResNet.
And when you do, do not forget to thank the skip connection.
YouTube lecture
Code file
https://colab.research.google.com/drive/1siansyMyo_o3EhXnCr-Ru9PlpLb65Z25?usp=sharing
Interested in learning AI/ML live from us?
Check this: https://vizuara.ai/live-ai-courses