
Day 3: Object detection using RCNN- Theory and implementation
RCNN, Fast RCNN and Faster RCNN. What exactly is the difference?



In the history of deep learning for computer vision, object detection has been one of the most challenging yet rewarding problems to solve. Unlike image classification, where the task is simply to decide which class an image belongs to, object detection requires the model to not only decide what objects are present but also to localise them precisely with bounding boxes. This means the model needs to both classify and regress coordinates, which makes the problem more complex.
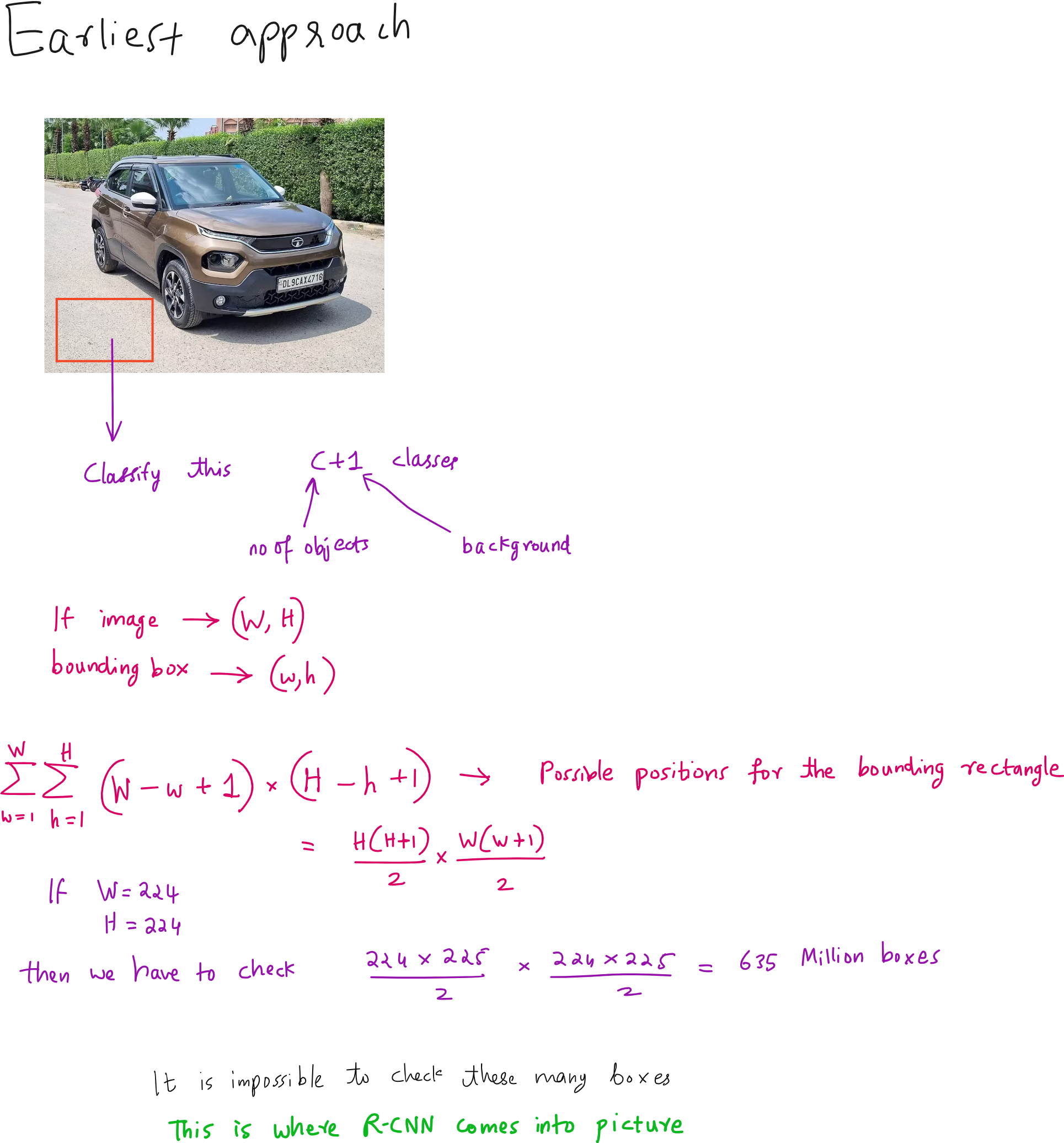
The turning point for object detection came in 2014 with the introduction of RCNN, or Region-based Convolutional Neural Networks. Before RCNN, most detection systems relied on sliding window approaches where a classifier was applied over thousands of possible windows across an image. This method was computationally expensive and inefficient because most windows contained no relevant objects. RCNN changed this approach entirely by introducing the idea of using region proposals - a small set of candidate regions that are likely to contain objects - and then running a convolutional neural network only on these regions.
RCNN - A Breakthrough in Accuracy

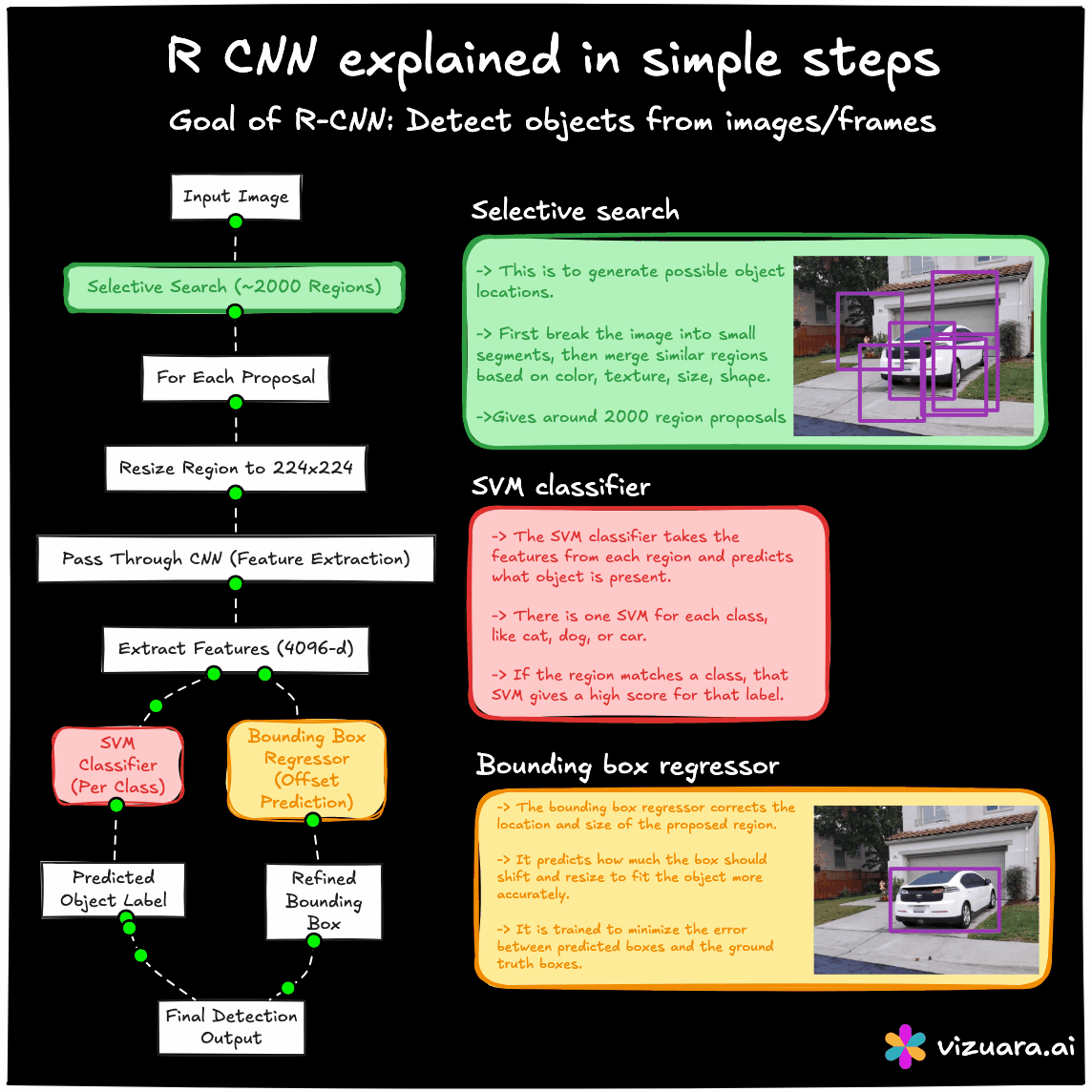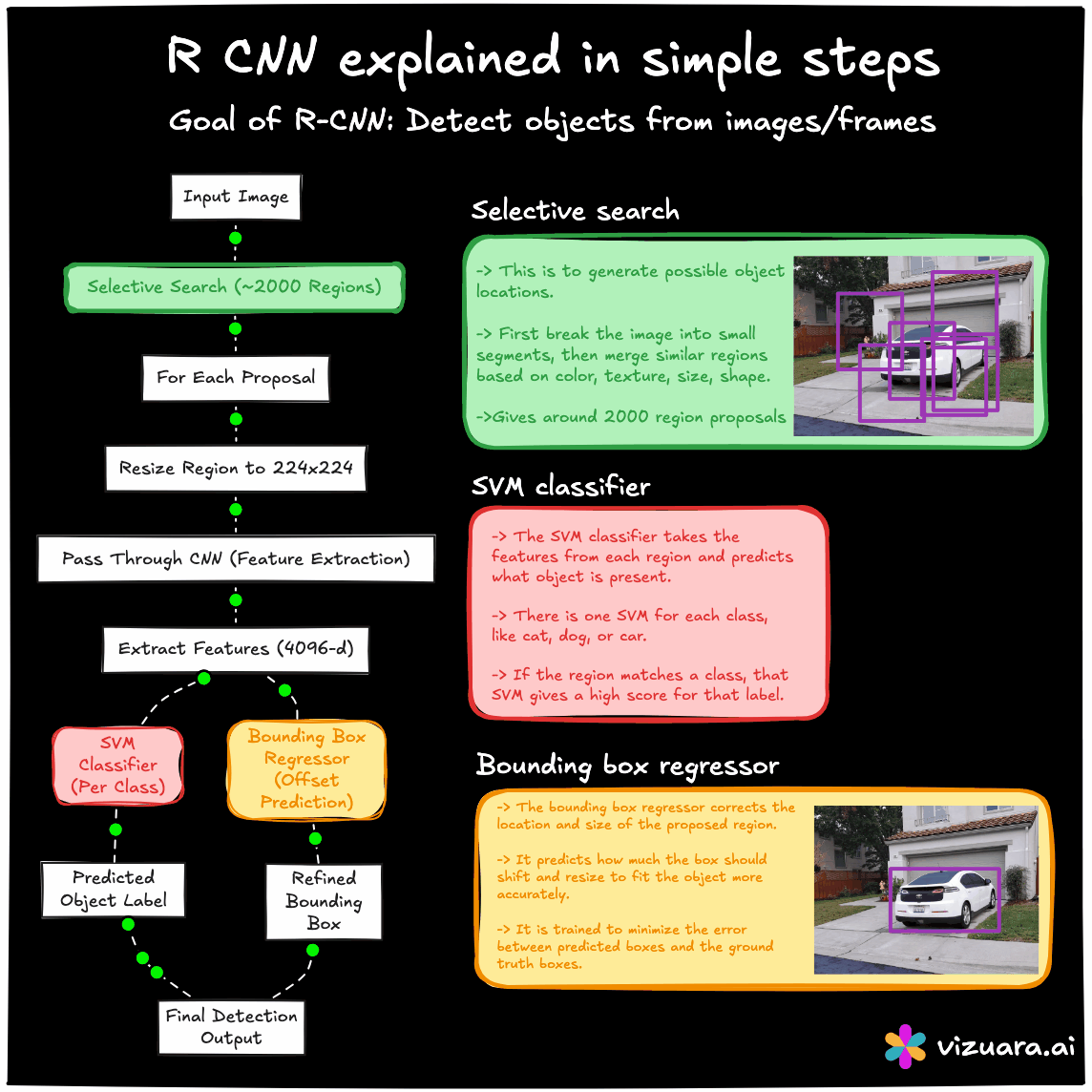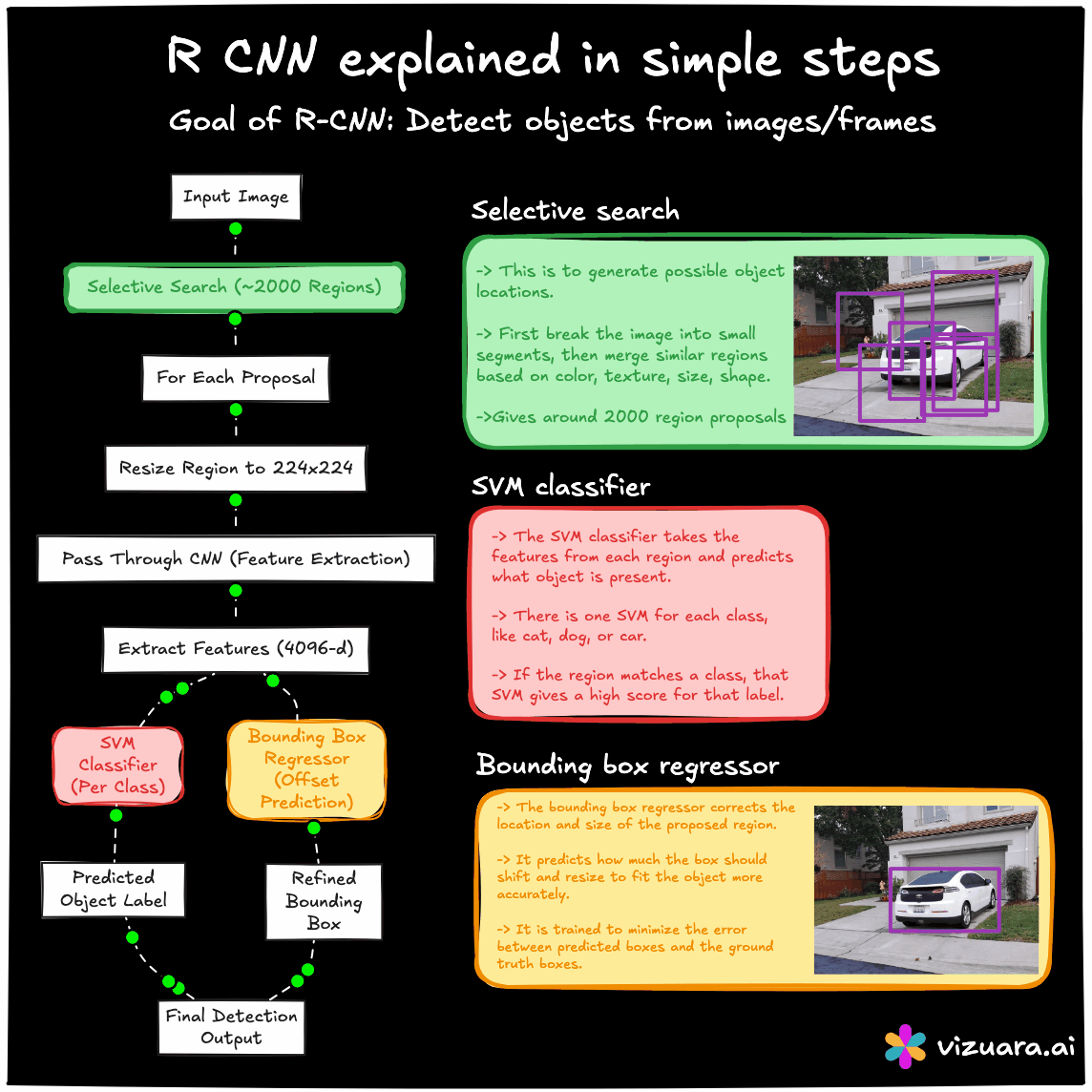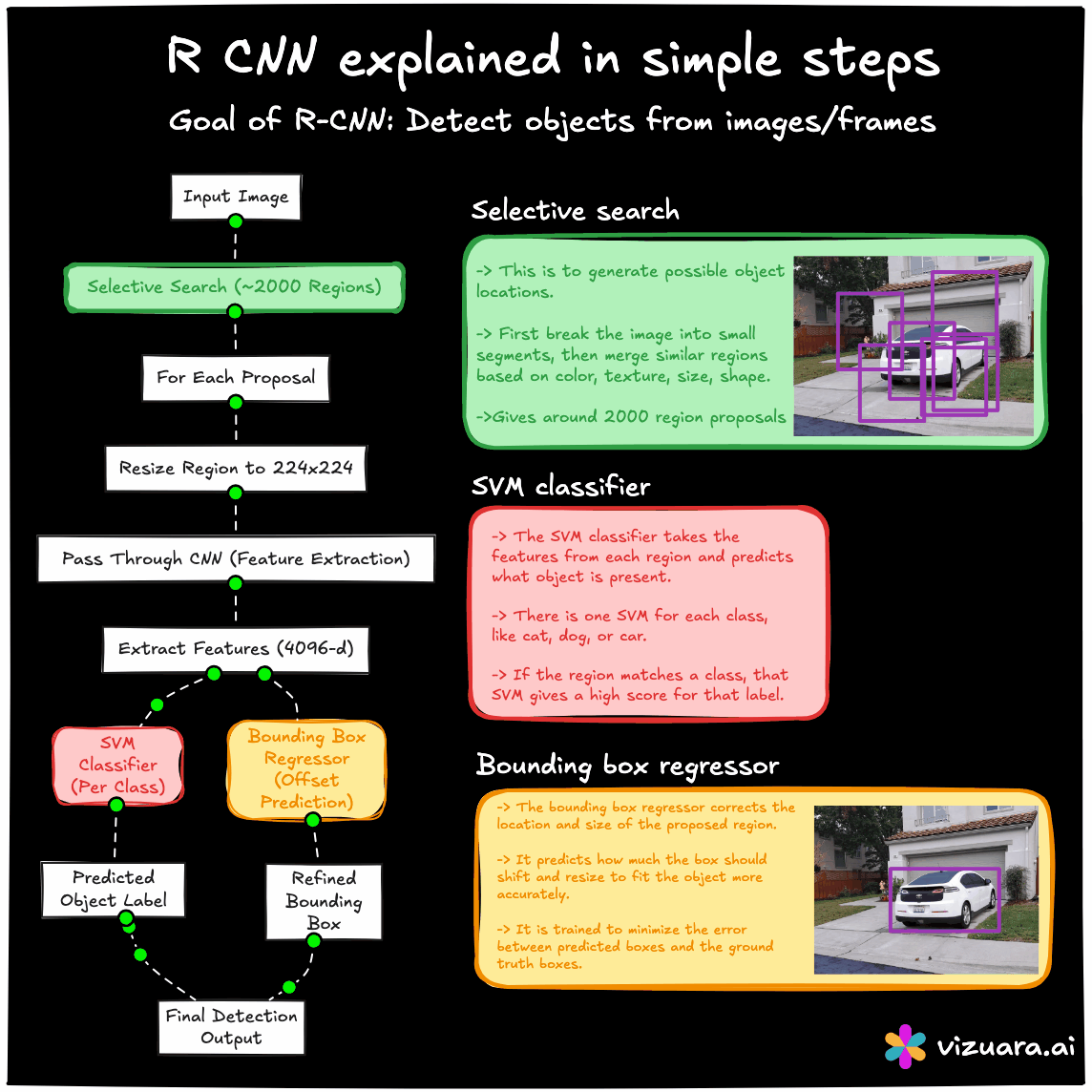
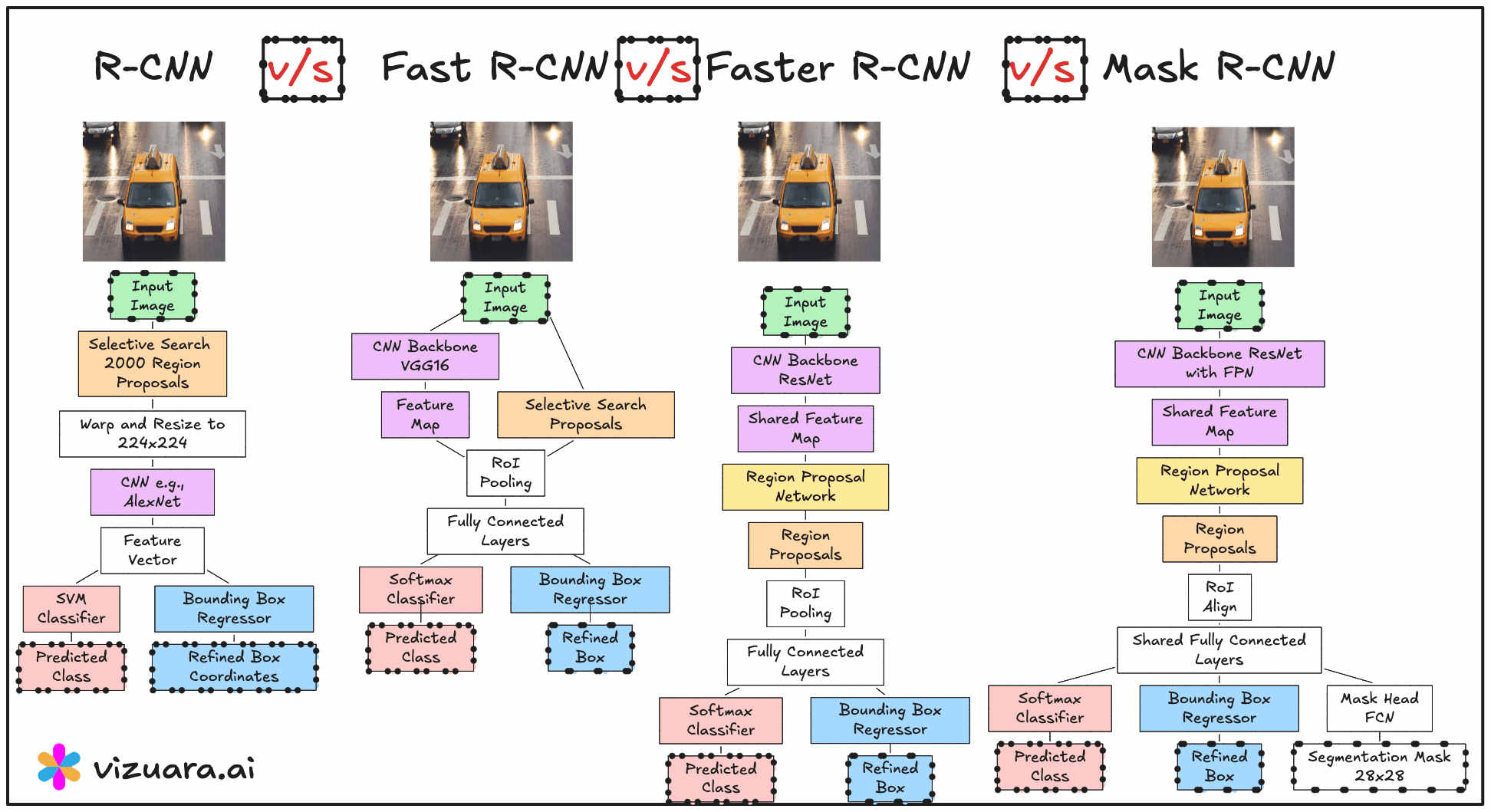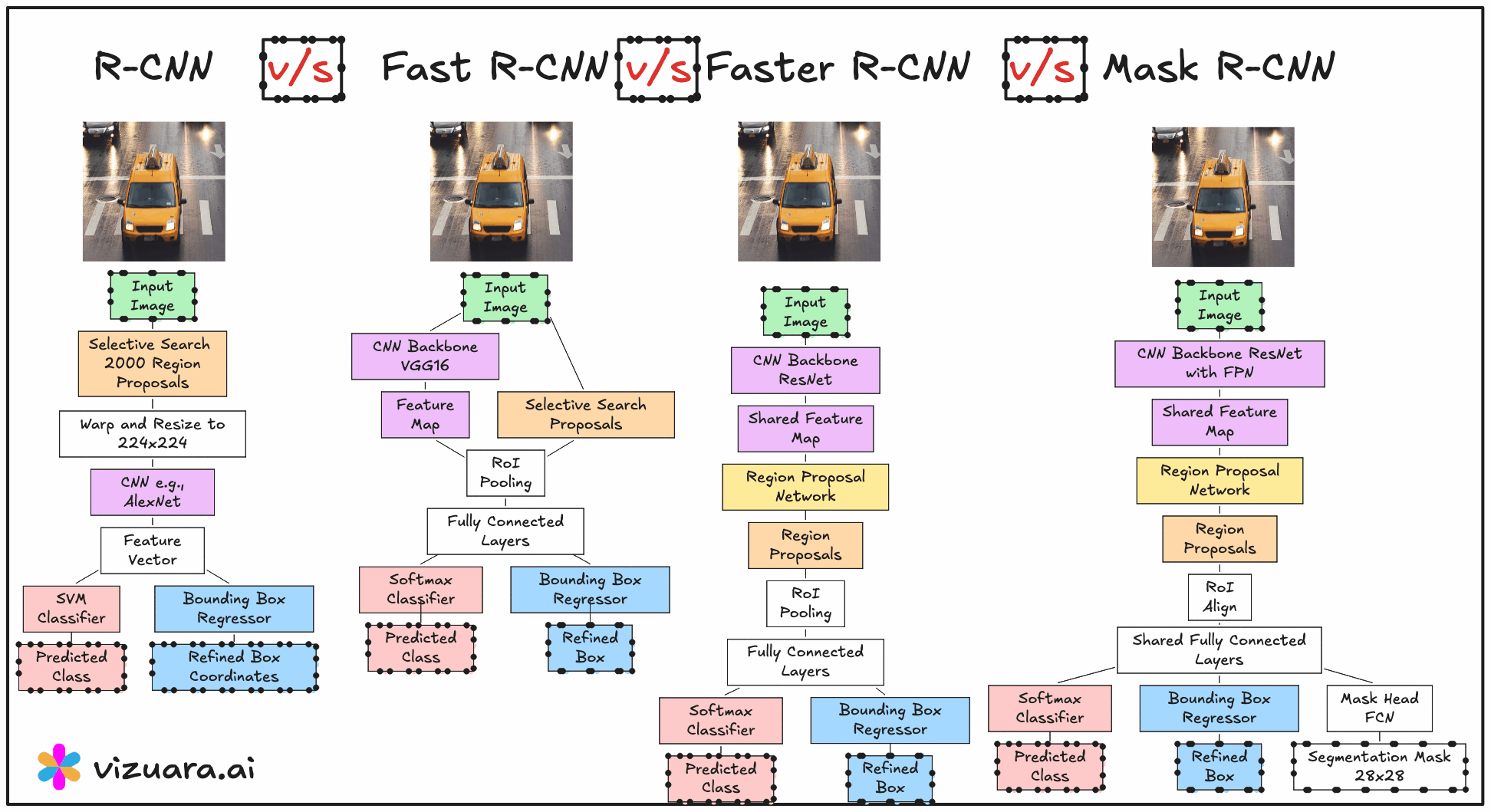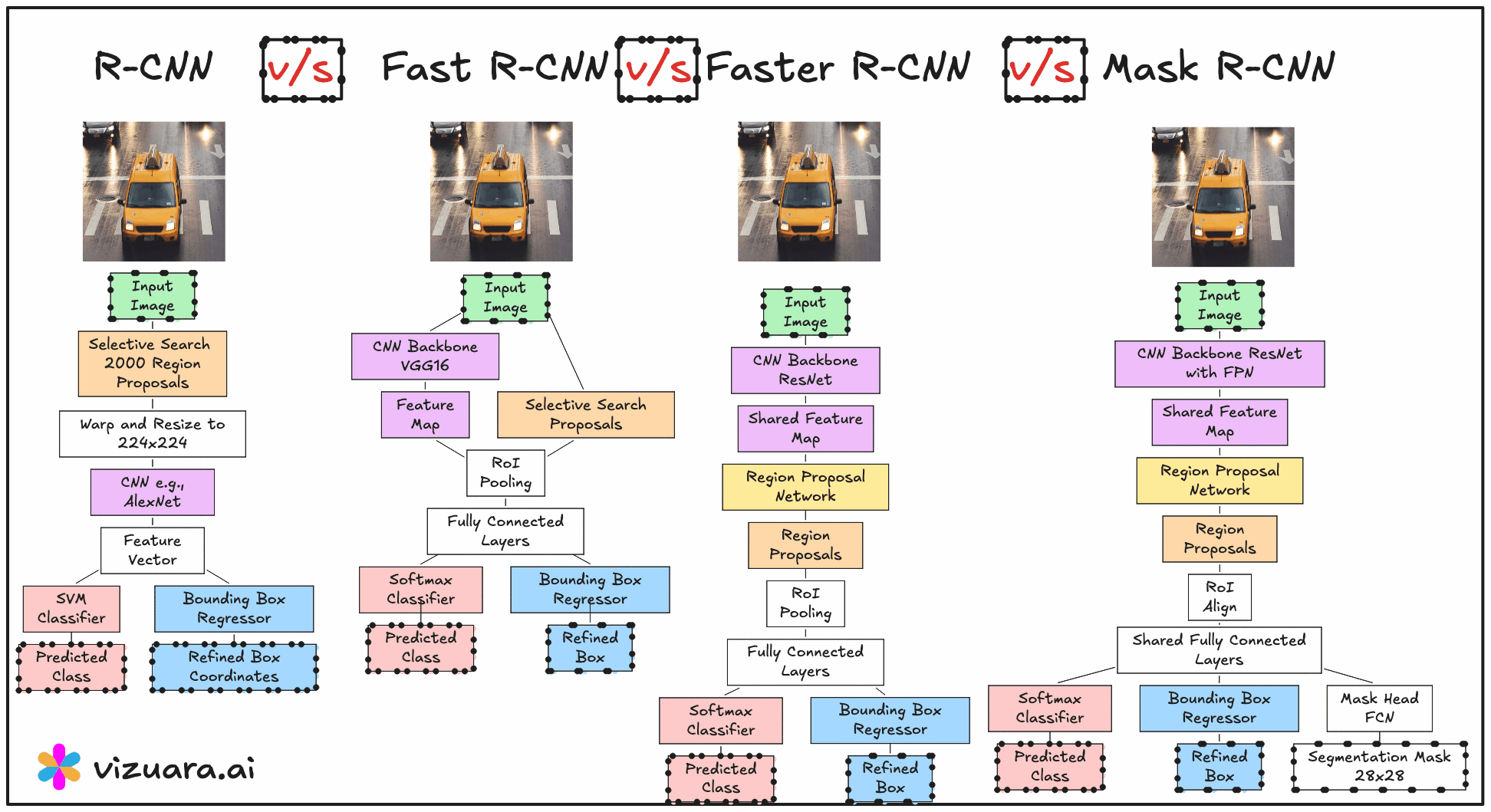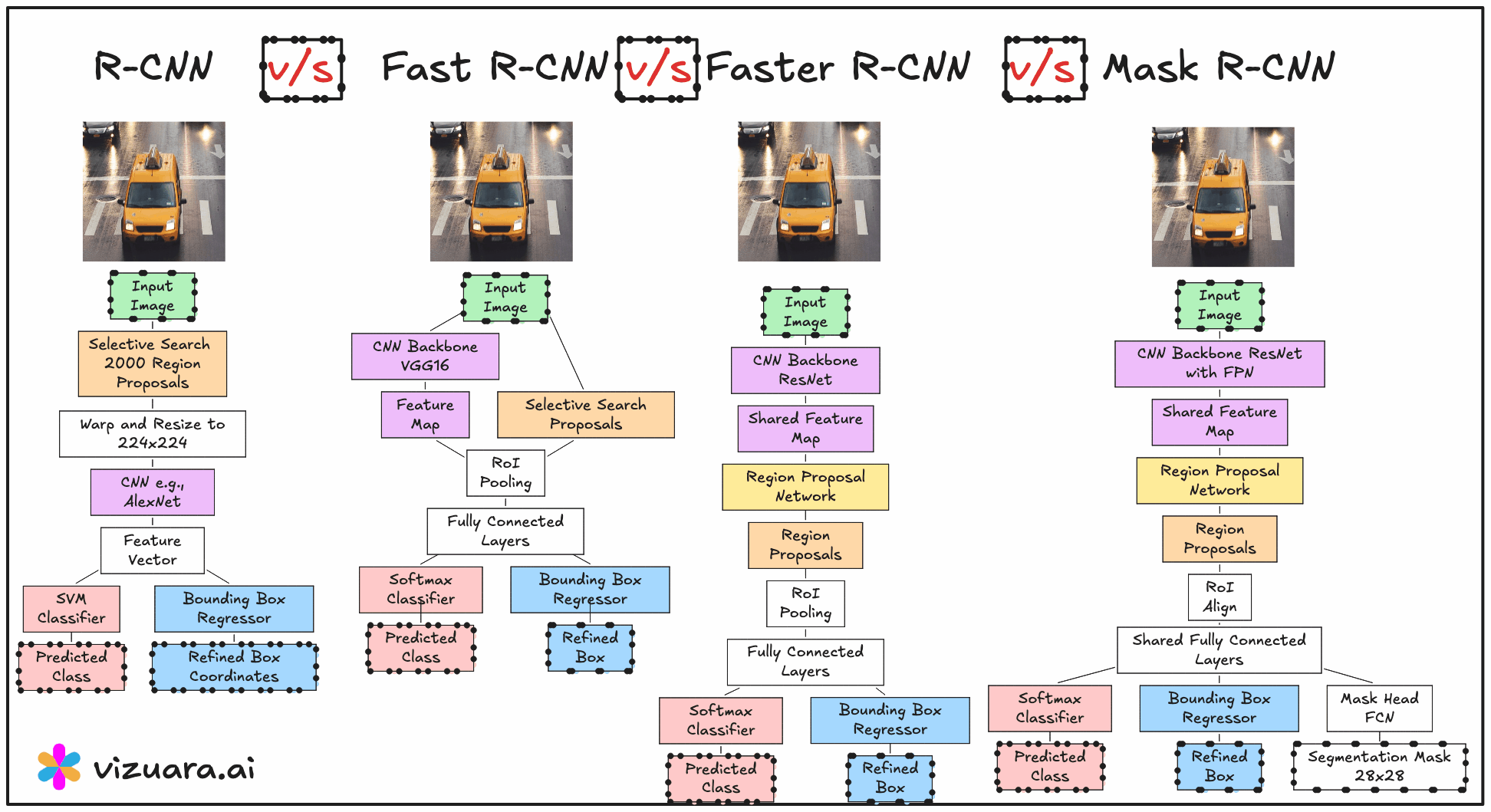
The RCNN pipeline follows three main steps. First, a region proposal algorithm such as Selective Search is applied to the image to generate about 2000 candidate bounding boxes. These proposals are intended to cover all potential objects with high recall. Second, each of these proposed regions is warped to a fixed size and passed through a CNN to extract features. Third, these features are fed into class-specific SVM classifiers to determine the object category, and a separate bounding box regression model refines the coordinates.
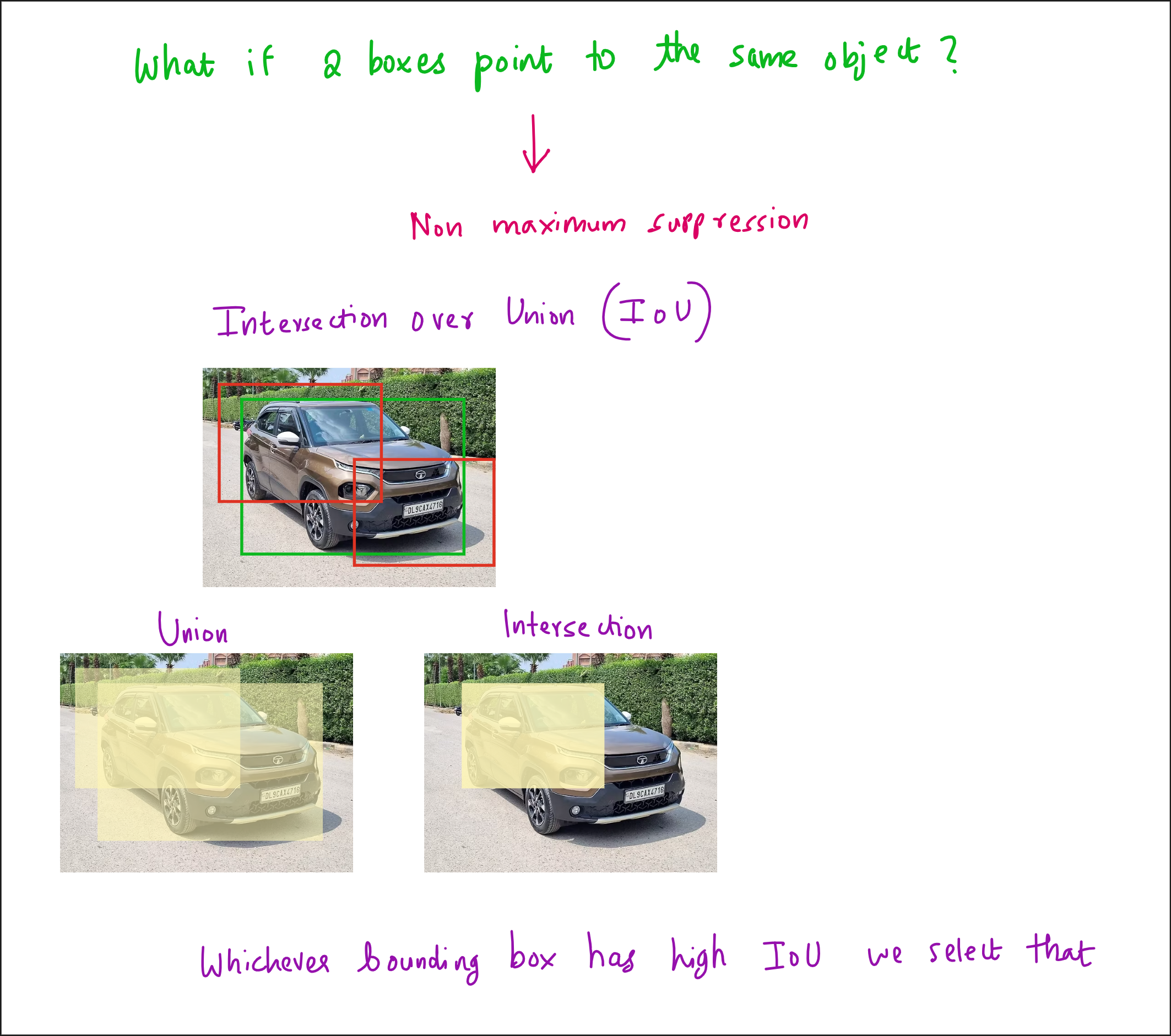
The main advantage of RCNN was that it significantly improved detection accuracy by combining traditional proposal generation with powerful CNN-based features. However, its main drawback was computational inefficiency. Running the CNN thousands of times per image was extremely slow, and the training process was fragmented into three separate stages - CNN fine-tuning, SVM training, and bounding box regression training.

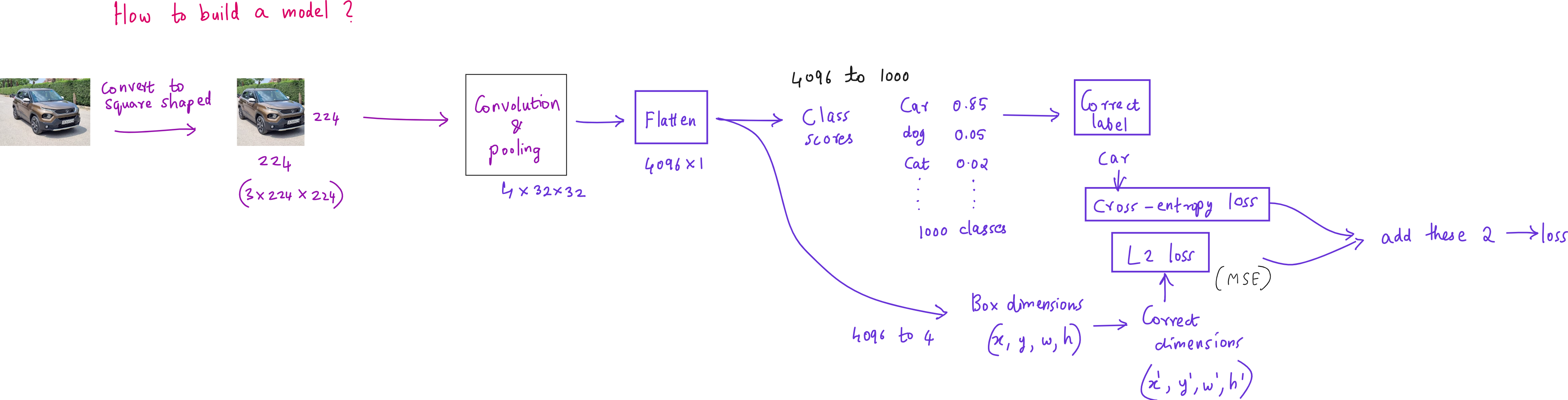

Fast RCNN - Eliminating Redundant Computation
In 2015, Fast RCNN was proposed to address the main bottleneck in RCNN - the repeated CNN computation for each region proposal. Instead of cropping and resizing each region at the image level, Fast RCNN runs the CNN just once on the entire image to produce a shared convolutional feature map. From this feature map, the region proposals are projected and passed through a layer called RoI (Region of Interest) pooling. RoI pooling extracts fixed-size feature maps for each proposal by pooling the corresponding feature map region into a standard grid size.
These pooled features are then sent through fully connected layers that simultaneously output both classification scores and bounding box refinements. This means classification and regression are performed in a single network, trained end-to-end. While this made the system much faster and easier to train compared to RCNN, the region proposals still came from Selective Search, which was slow and still not learnable.
Faster RCNN - Learning to Propose
The next advancement was Faster RCNN, introduced later in 2015, which completely removed the dependency on hand-crafted proposal algorithms. The innovation here was the Region Proposal Network (RPN), a small neural network that takes the convolutional feature map as input and outputs region proposals directly. This RPN is trained jointly with the detection network, allowing the entire object detection pipeline to become fully learnable and end-to-end trainable.
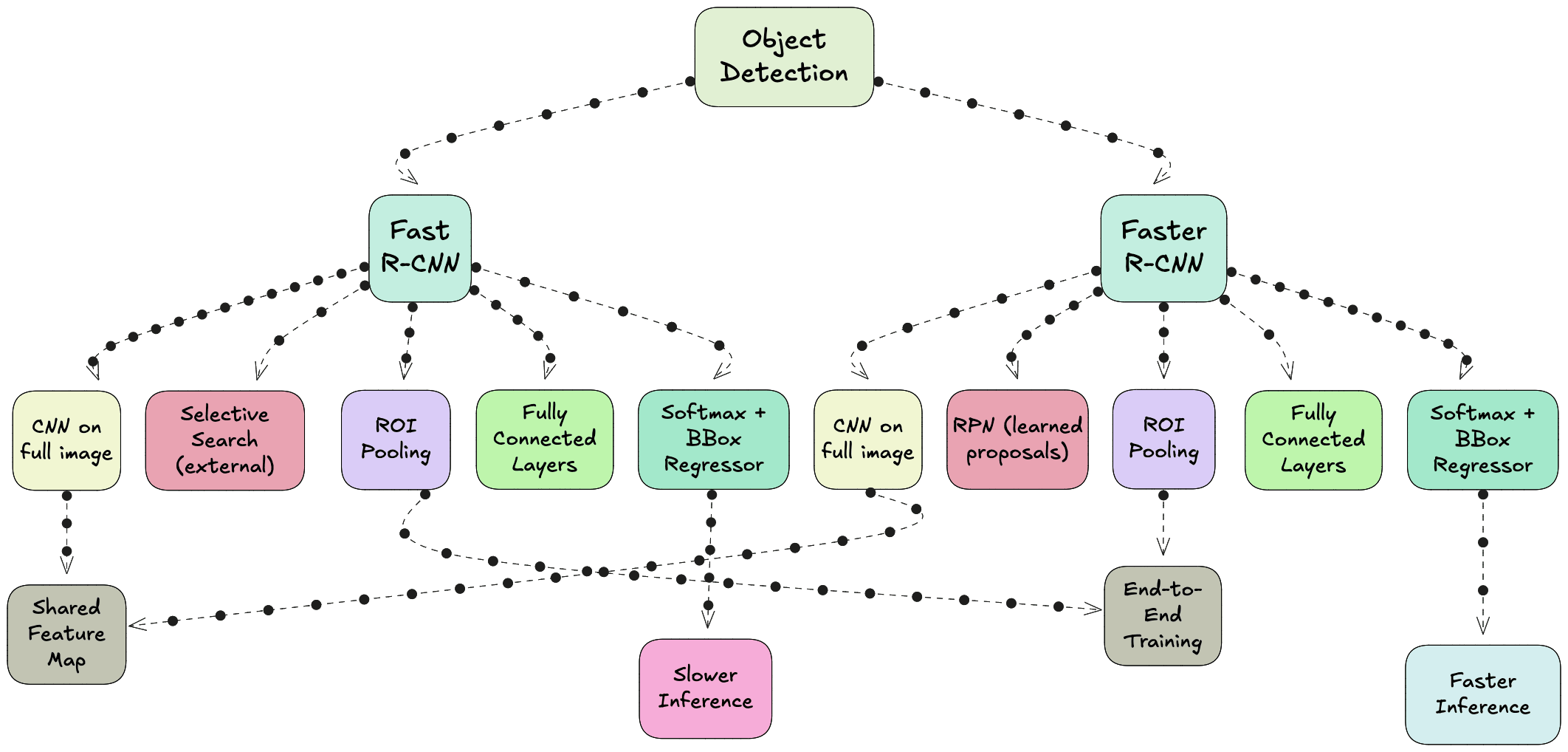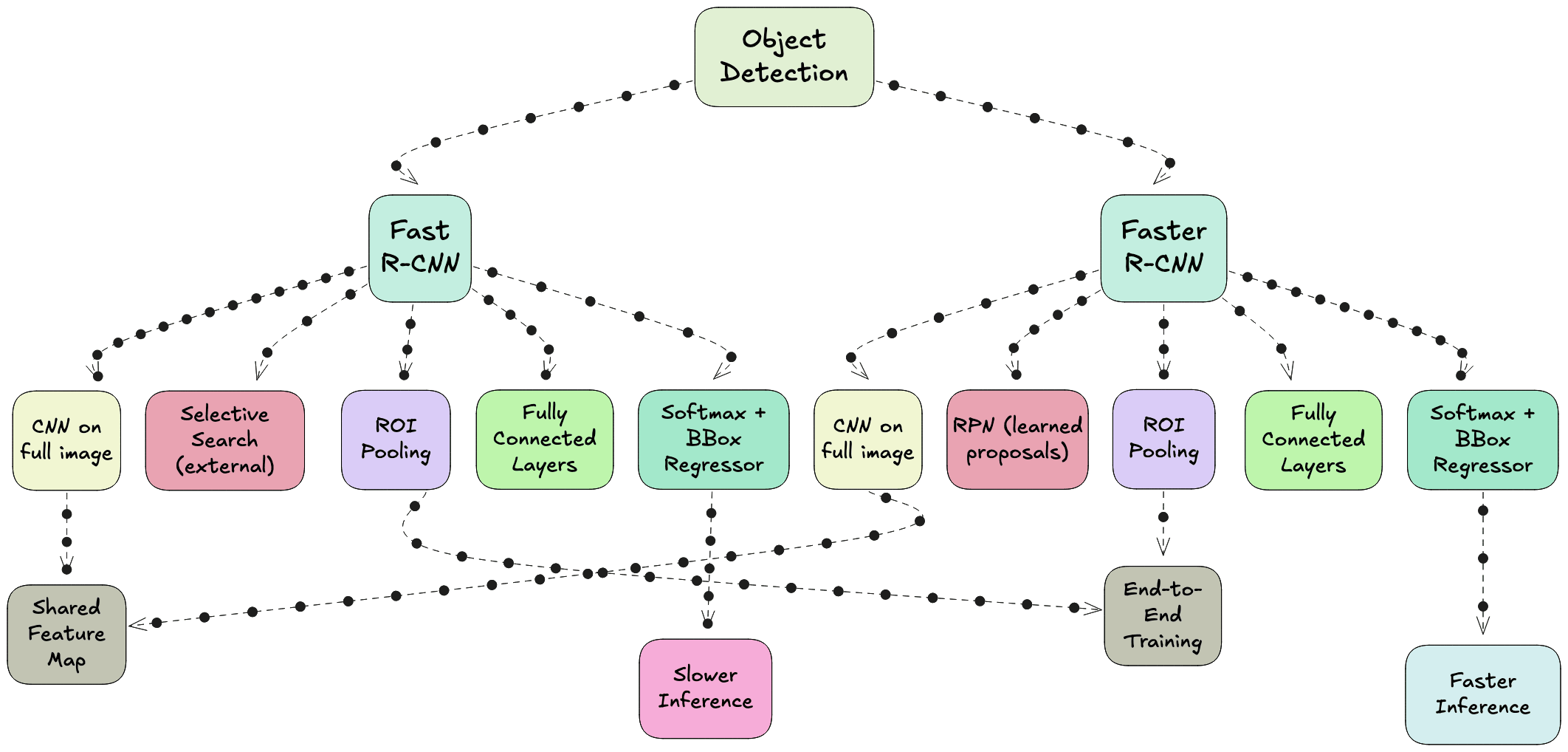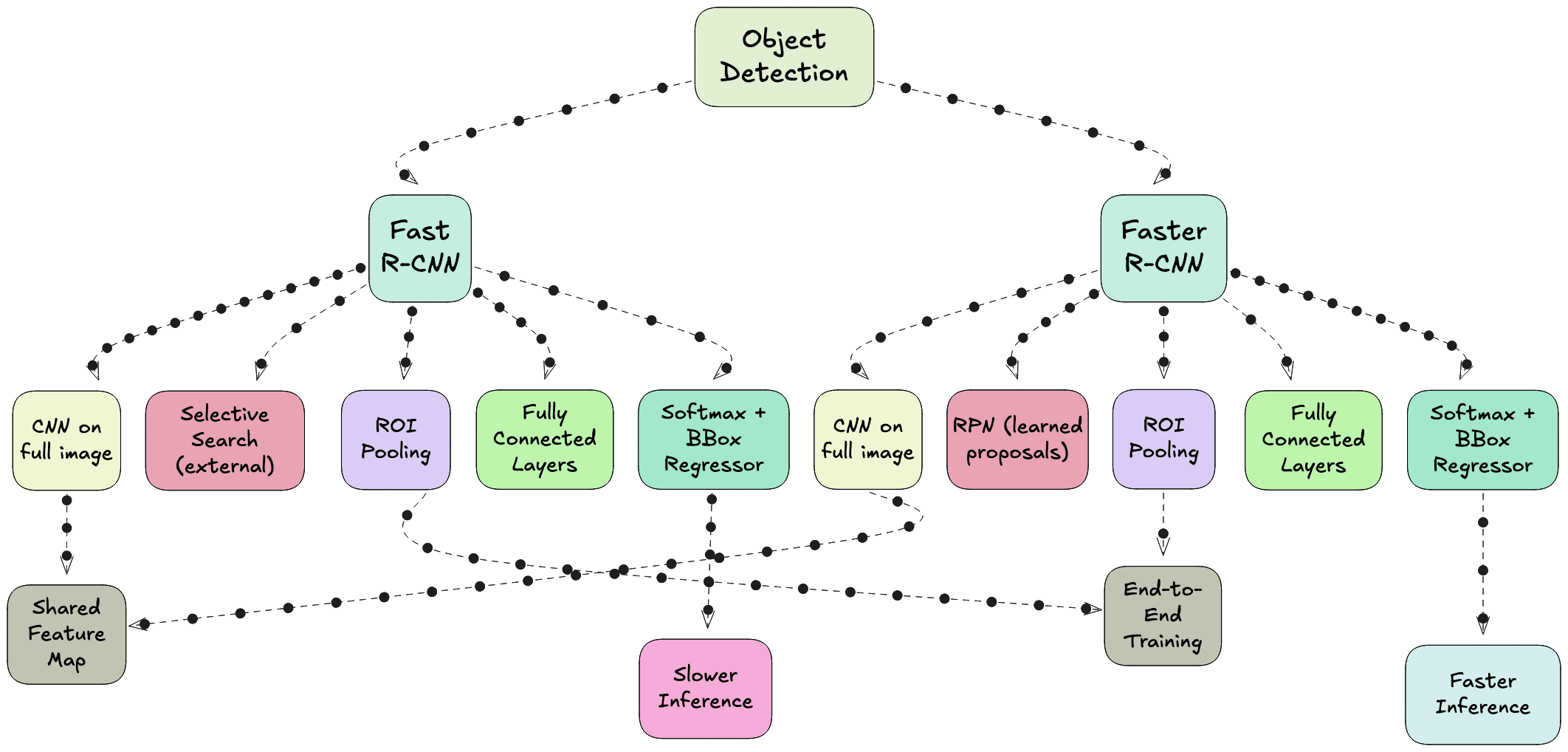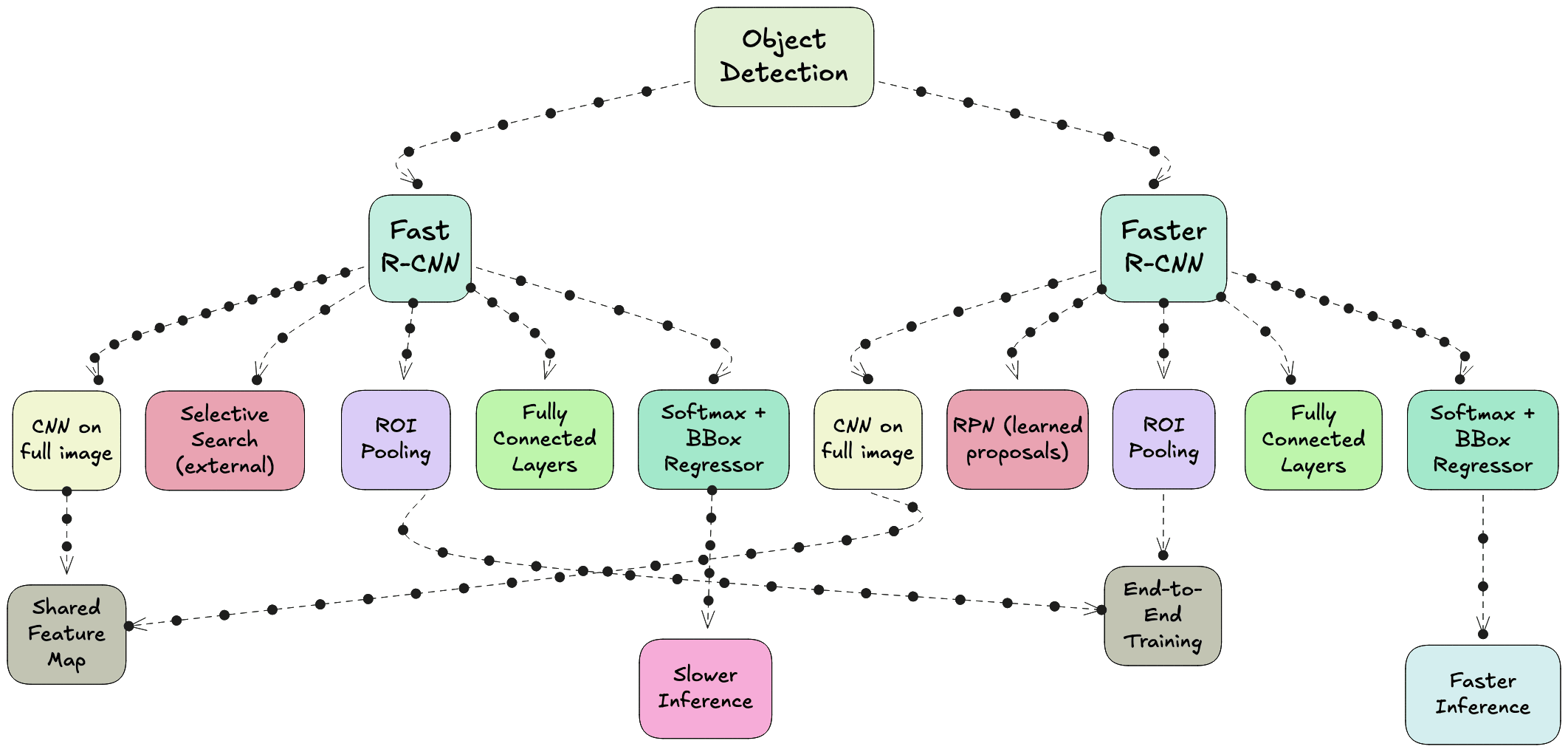
The RPN generates proposals by sliding a small network over the convolutional feature map and predicting both objectness scores and bounding box coordinates for a set of anchor boxes at each position. These proposals are then fed into the detection head, which is essentially the Fast RCNN network, for final classification and bounding box regression. Because the RPN shares the same convolutional features as the detection head, the computation is extremely efficient.
Key Similarities Across the Three Models
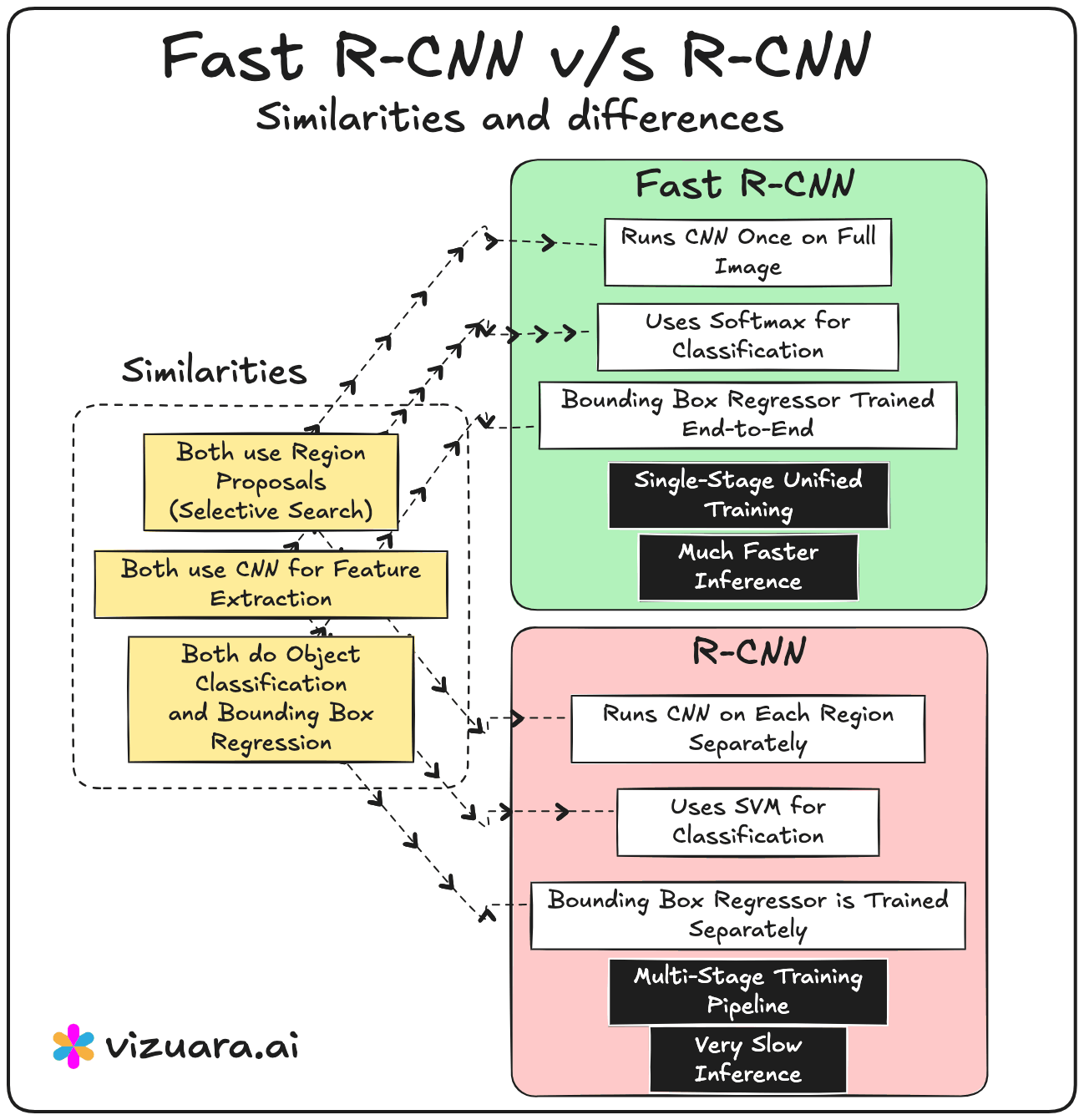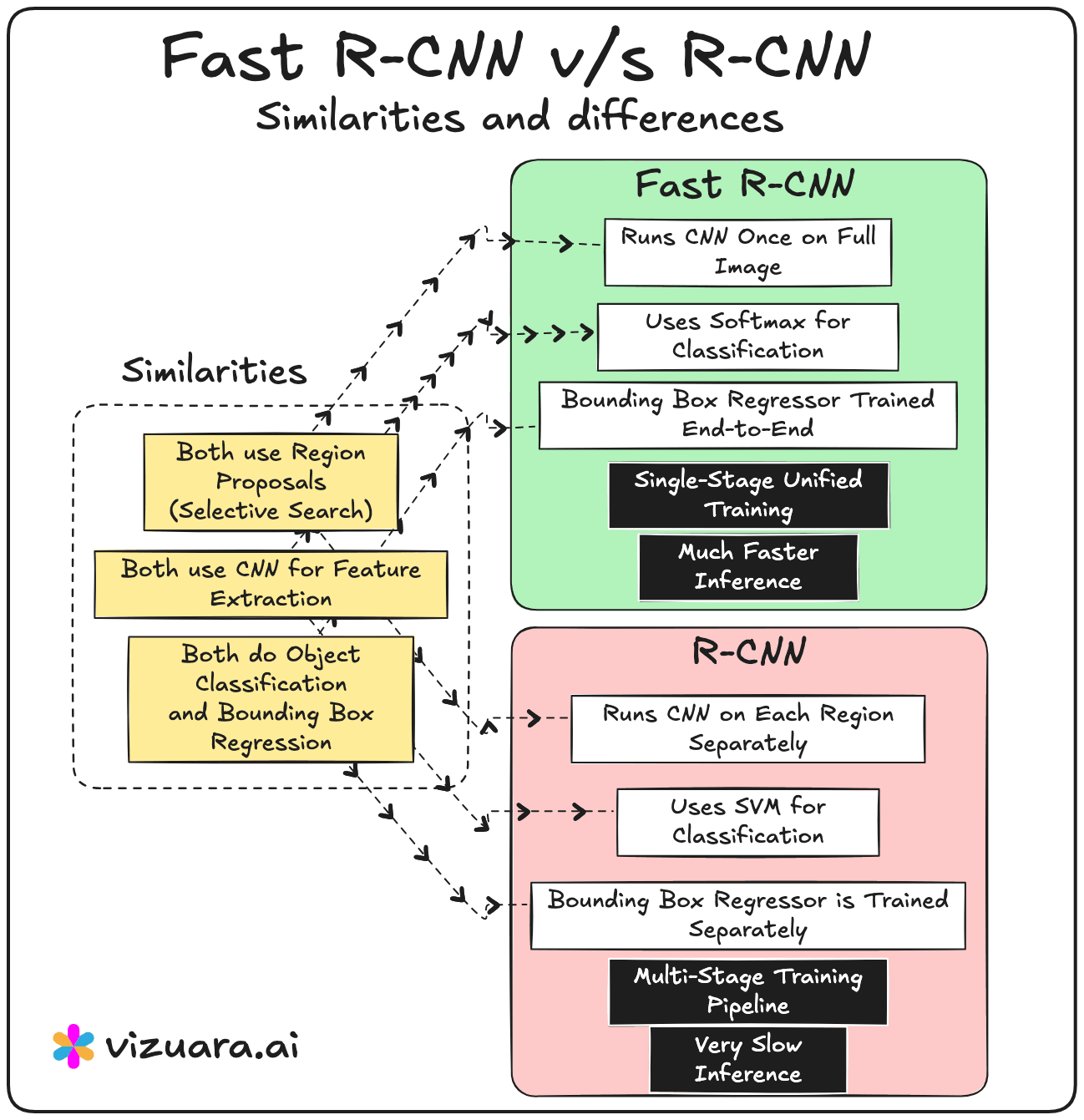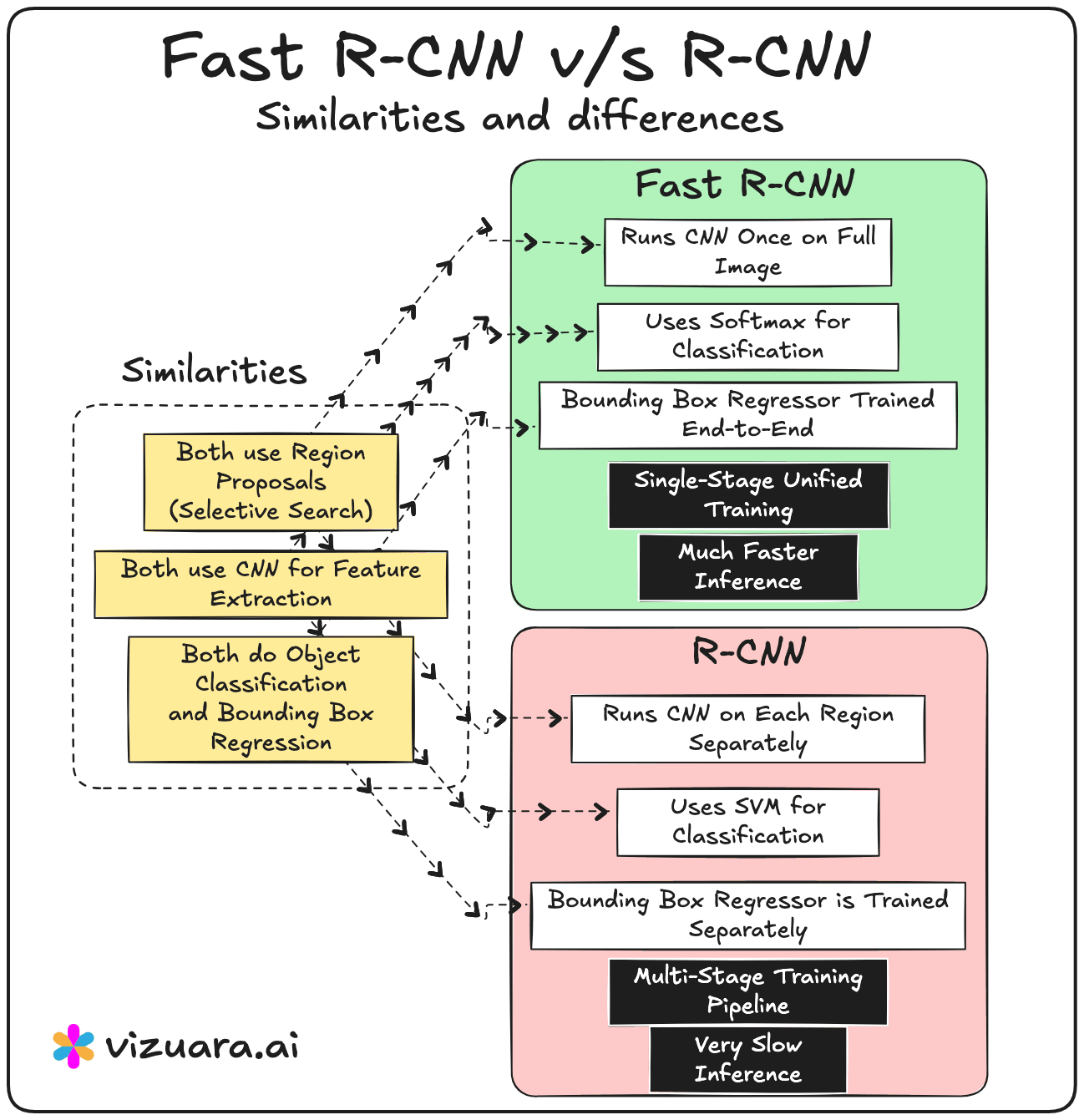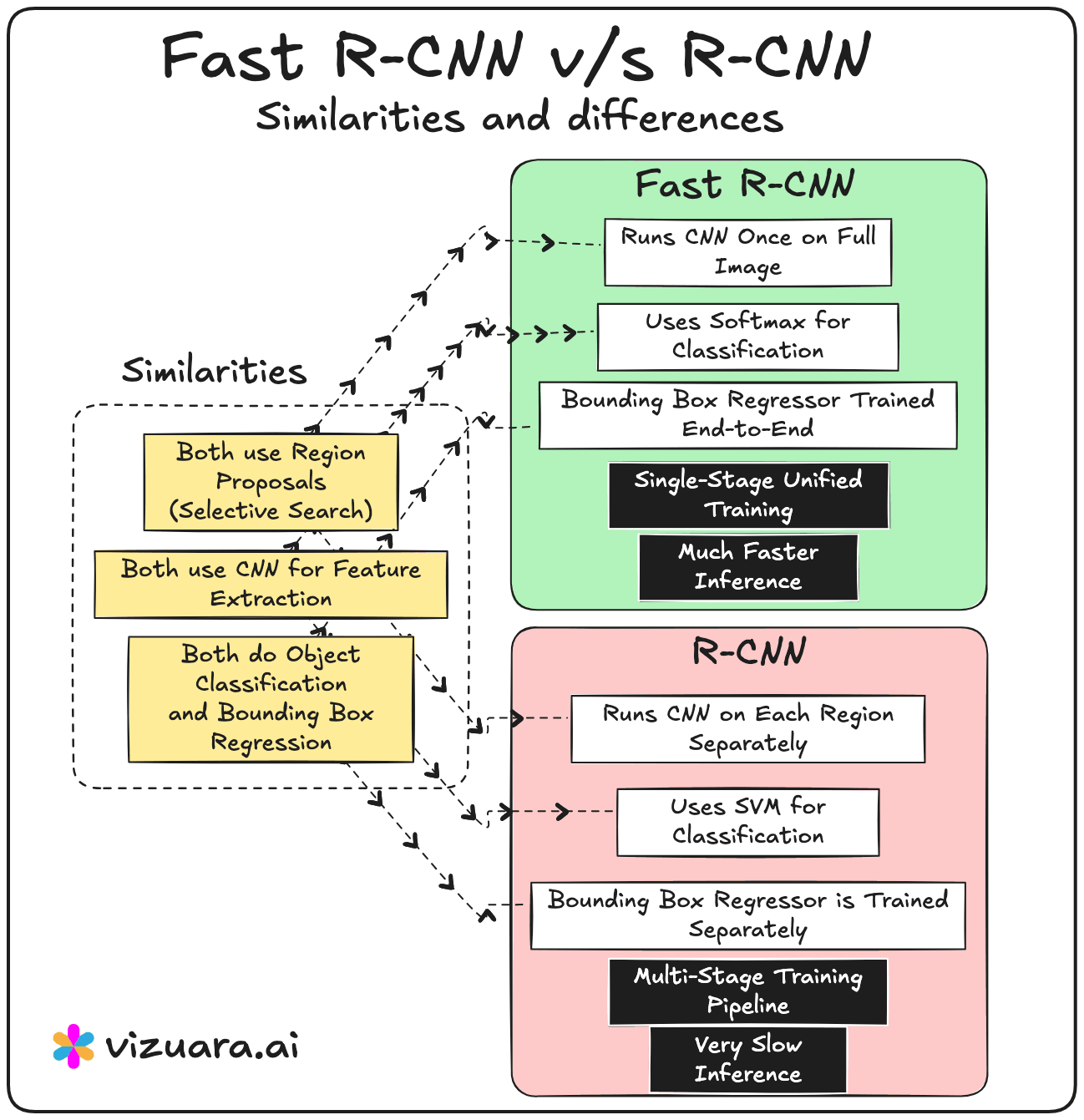
Despite the architectural differences, RCNN, Fast RCNN, and Faster RCNN share a common high-level structure. All of them follow the general sequence of generating region proposals, extracting features from those proposals, and then classifying and refining bounding boxes. All of them use convolutional neural networks for feature extraction, and all of them employ a bounding box regression step to improve localisation accuracy.

Key Differences that drove progress
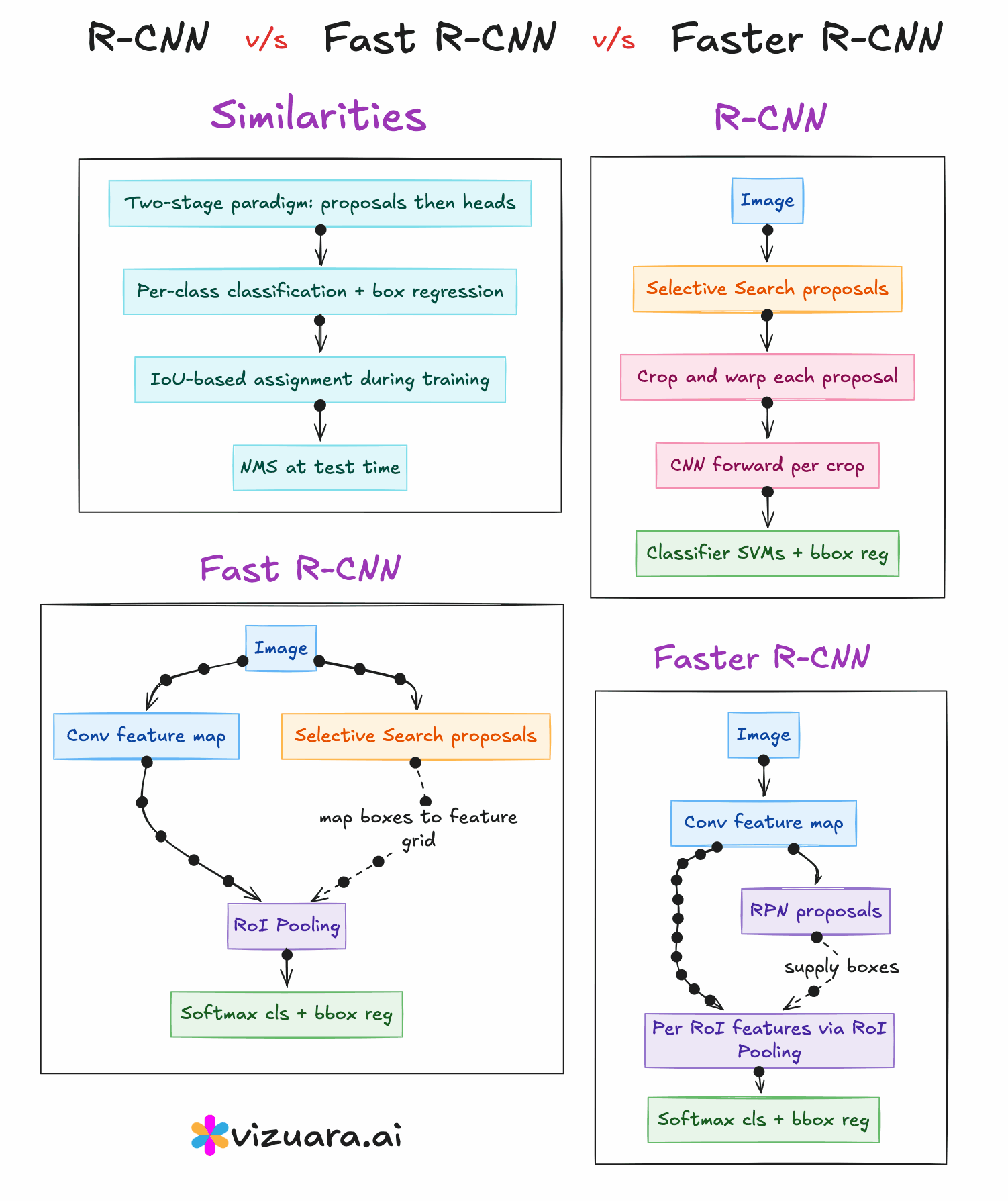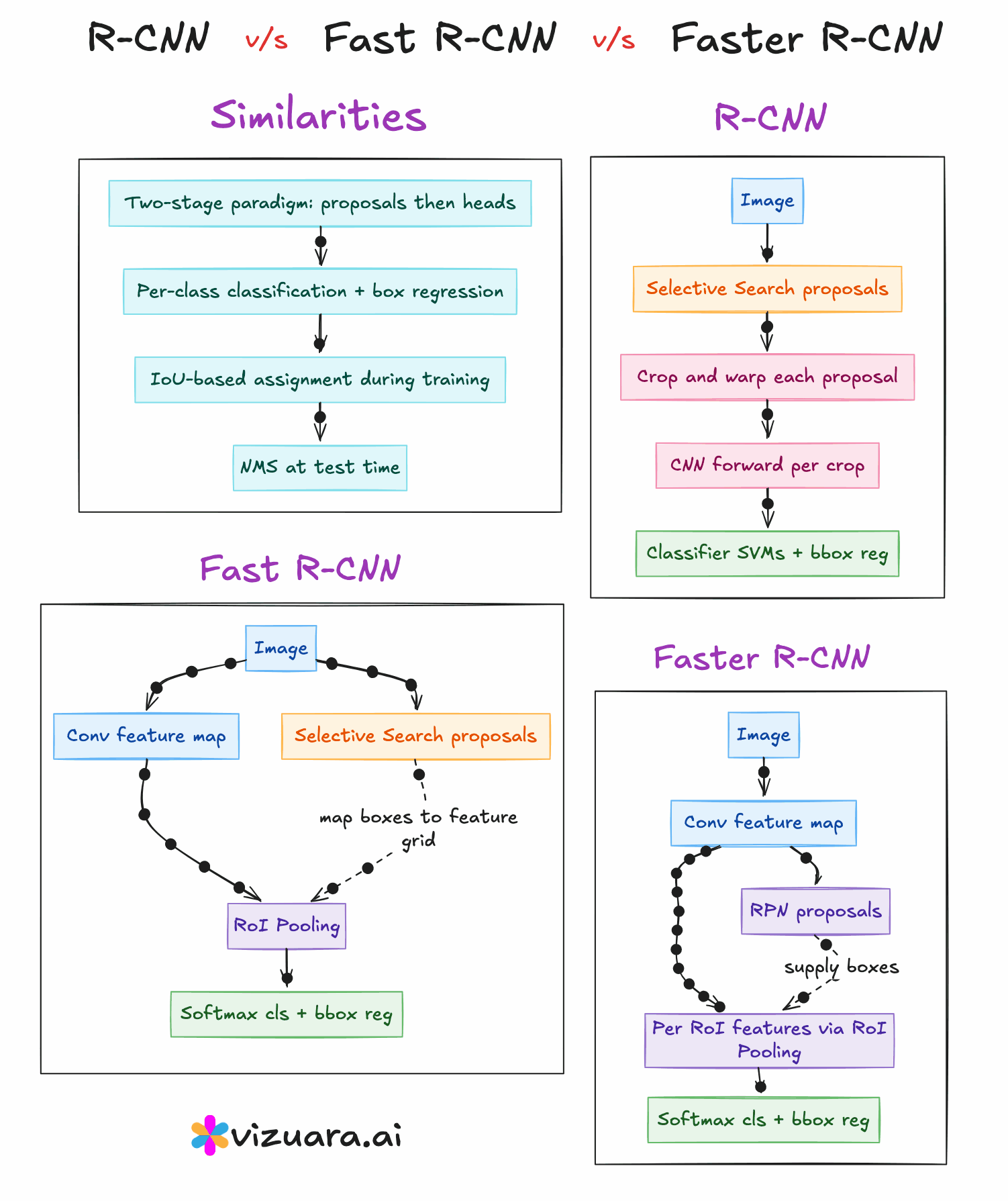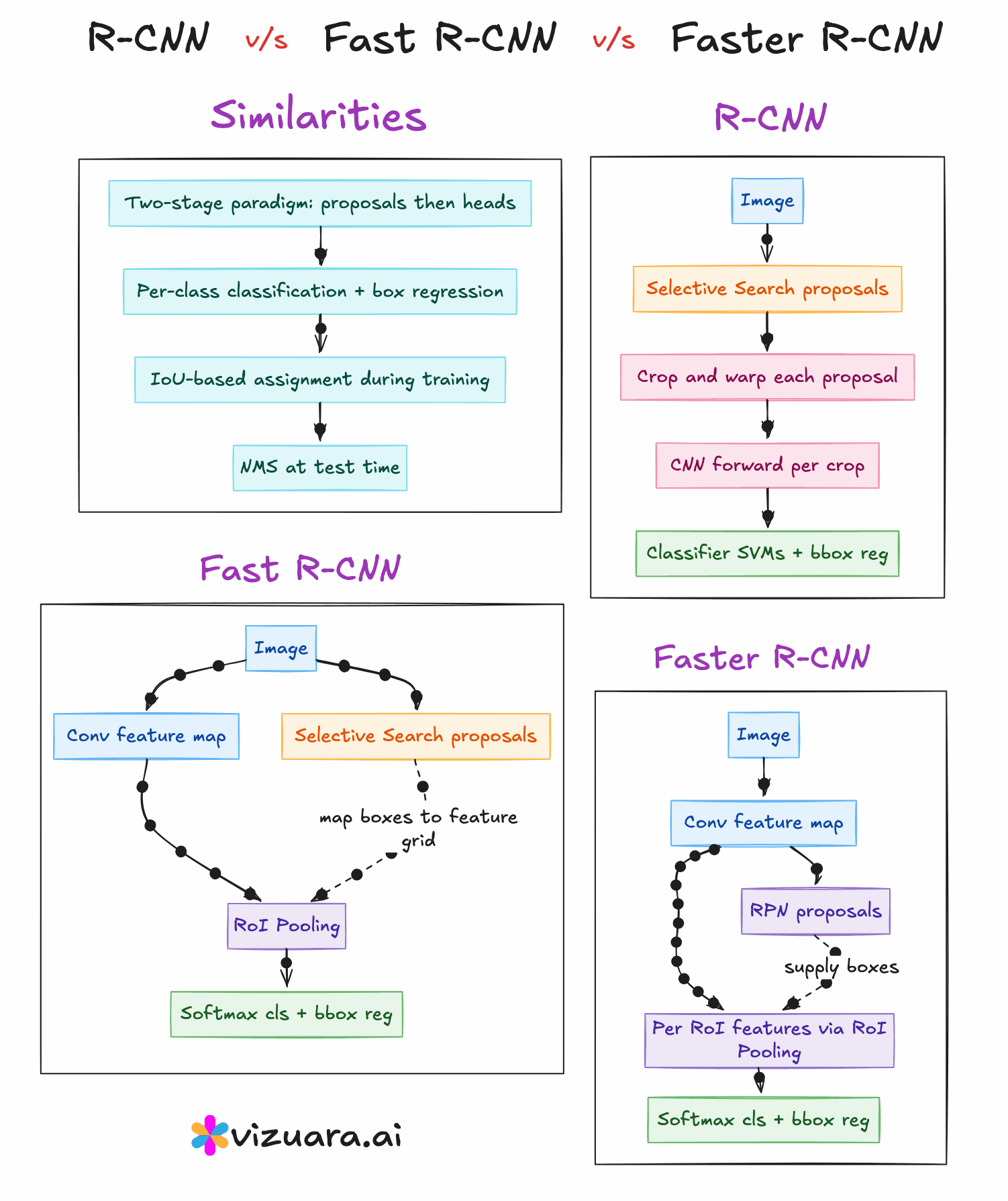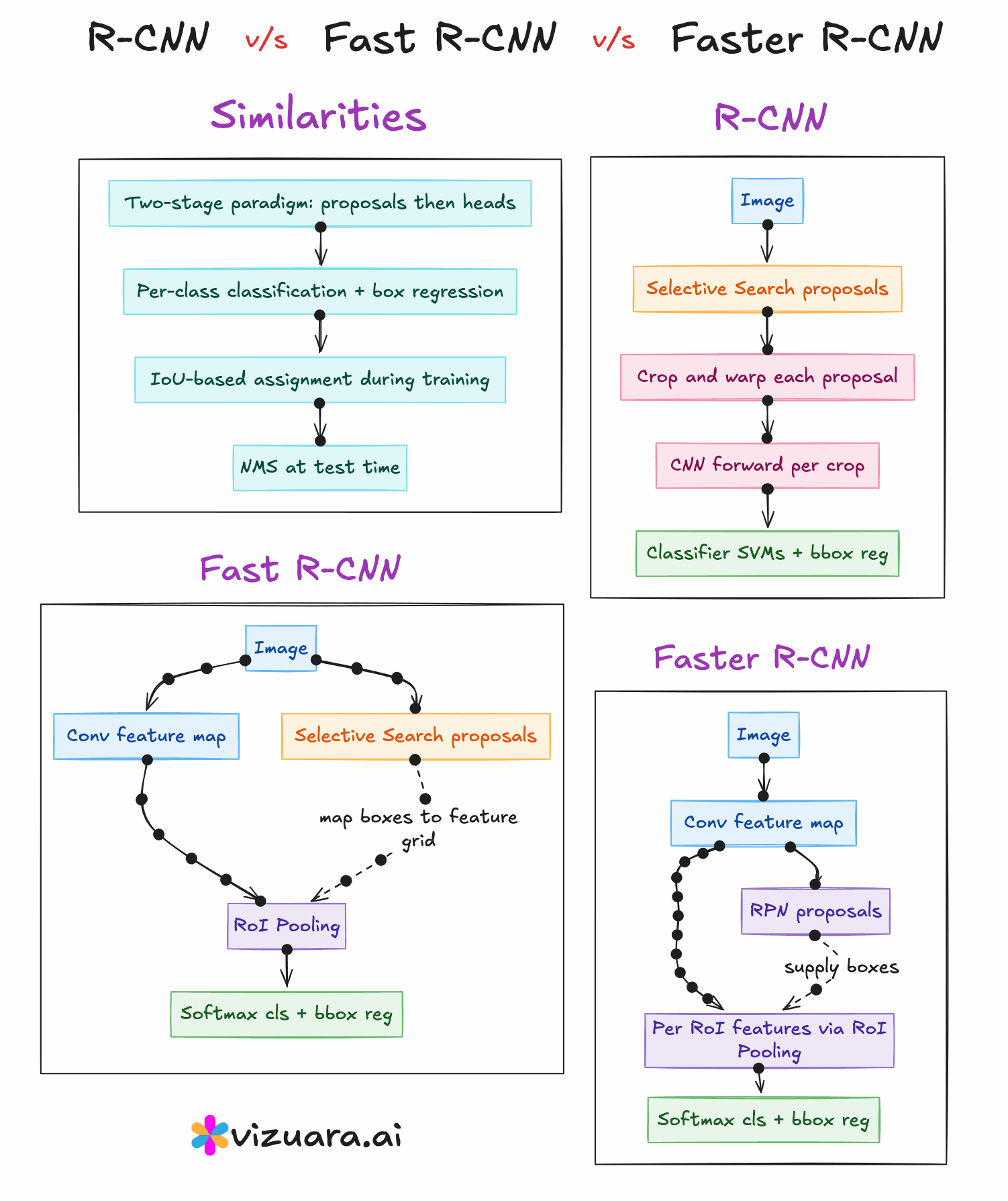
Region Proposal Generation
RCNN and Fast RCNN rely on Selective Search, which is slow and hand-engineered.
Faster RCNN replaces this with a learnable Region Proposal Network that is trained jointly with the detection network.
Feature Extraction
RCNN runs the CNN separately for each region proposal, which is computationally expensive.
Fast RCNN and Faster RCNN run the CNN only once per image, then use RoI pooling to extract proposal features from a shared feature map.
Training Process
RCNN has a multi-stage training process (CNN → SVM → bounding box regression).
Fast RCNN and Faster RCNN use unified, end-to-end training for classification and bounding box regression.
Inference Speed
RCNN is the slowest because of repeated CNN passes.
Fast RCNN is much faster because of shared computation but still bottlenecked by Selective Search.
Faster RCNN achieves the highest speed while retaining strong accuracy because of its integrated RPN.
Why This Evolution Matters
Each step in this progression targeted a specific bottleneck. RCNN solved the accuracy problem by introducing CNN-based features, Fast RCNN solved the redundant computation problem, and Faster RCNN solved the slow, hand-crafted proposal problem. This systematic removal of inefficiencies is a recurring theme in the advancement of AI research.
Today, Faster RCNN remains one of the most widely used detection architectures in both academia and industry, often serving as a backbone for more specialised systems. While even faster one-stage detectors like YOLO and SSD emerged later, the RCNN family remains foundational for anyone who wants to deeply understand the principles behind object detection
If you are learning computer vision, I would strongly recommend not just jumping into the latest detection architecture but also understanding how we got here. The RCNN lineage provides a perfect case study in how deep learning research evolves through incremental yet significant improvements, each addressing the limitations of its predecessor.
Watch the full lecture here
I am teaching Computer Vision LIVE
If you wish to be part of the cohort check this out: