
Day 1: Hands-on Computer Vision Bootcamp
An introduction to CV and OpenCV



The First Principles of Computer Vision: From Filters to Frameworks
When people hear the term computer vision, their first instinct is often to associate it with facial recognition, autonomous vehicles, or perhaps the classic example of classifying cats and dogs. These examples are certainly part of the domain, but they barely scratch the surface. The real depth of computer vision lies not in a few public use cases, but in the hundreds of invisible processes happening behind the scenes in diverse industries like healthcare, agriculture, security, industrial automation, and robotics. In this chapter, we begin our journey by revisiting the fundamental motivations, building the essential mental models, and writing our first few lines of code using OpenCV.
The aim of this first lecture - and by extension, this chapter - is not just to introduce tools or teach syntax. It is to reframe how we think about computer vision from the ground up. If you are coming from a background in computer science, engineering, or even something entirely different like biology or economics, this chapter will give you a clear and practical lens through which to approach the rest of the bootcamp.
A Personal Starting Point: Computer Vision as a Necessity

During my PhD at MIT, I was working on a very specific problem. The aim was to design a self-cleaning solar panel that could function without the use of water - a requirement that was especially important in arid desert regions where solar farms are common, but water is scarce. One of the critical variables in our system was something called the dust removal voltage. This voltage depended heavily on the size of dust particles on the panel’s surface. The smaller the particle, the higher the voltage required to repel it through electrostatic force.
The challenge was this: how do you determine the average dust particle size across a large solar panel in real-time? You cannot use a microscope, you cannot manually inspect every inch, and you cannot afford high-end equipment in a system that needs to be deployable and low-cost.

The solution came from computer vision.
I purchased a very cheap digital microscope camera with modest magnification capabilities. Using this, I was able to take frames of dust particles on the panel surface. These frames contained thousands of particles in a single image. The next step was to analyze this image to extract a meaningful particle size distribution. For that, I implemented a basic convolutional neural network that would classify the particles into predefined size buckets. Based on this classification, the controller could then apply the appropriate dust removal voltage for optimal cleaning.
This was my first real use of computer vision, and it was not done out of academic interest or curiosity. It was done because nothing else would work. And that is the most honest introduction to this field that I can give: computer vision is not a subject you learn for fun. It is a tool you are forced to learn when your problems become visual.
A Look Further Back: Traditional Computer Vision Without Neural Network
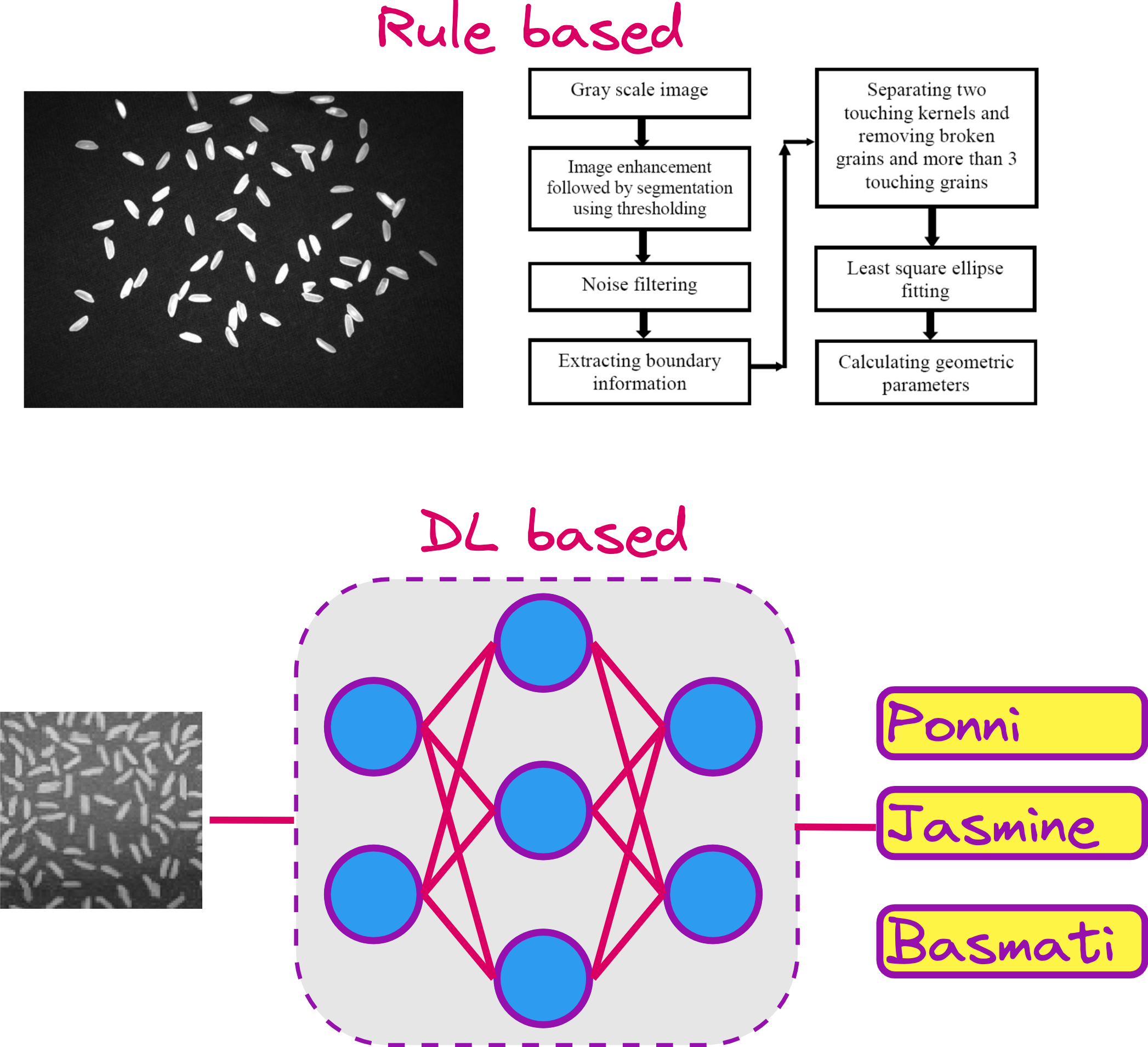
Years before my PhD, as an undergraduate, I worked on a simpler but still illuminating project. We wanted to classify different varieties of rice grains using images. The image would contain a scattered set of grains, and the goal was to identify the type of rice – basmati, jasmine, idli rice, and so on – purely based on their shape and size.

Deep learning was not yet the default approach, especially for small datasets. So we relied on traditional image processing techniques: thresholding, morphological operations, shape detection, and ellipse fitting. The goal was to isolate each rice grain, measure its major and minor axes, and cluster them based on their geometrical features.

Of course, complications arose. Grains often overlapped or touched each other. We had to write logic to detect touching objects, segment them, and then compute their geometries. We designed dozens of small algorithms to handle these edge cases. The process was long and error-prone, but it gave us a granular understanding of how images can be manipulated programmatically.
This project was eventually presented at the 9th International Conference on Machine Vision in Nice, France. And at that conference, it became abundantly clear that the research community was already shifting its attention toward deep learning. What we were doing was still valid, but increasingly obsolete.
The AlexNet Revolution and the End of Hand-Crafted Features
In 2012, a seismic shift occurred. AlexNet was introduced. Built using deep convolutional neural networks and trained on the ImageNet dataset, AlexNet crushed the competition in the ImageNet Challenge by a wide margin. But it was not just about the accuracy. The key breakthroughs were:
Using ReLU activations to accelerate convergence
Utilizing GPUs to enable large-scale training
Building a deep architecture that could learn hierarchical features
What AlexNet did was eliminate the need for hand-crafted filters. Until then, filters were manually designed to extract specific patterns from images – edges, corners, textures, etc. With CNNs, these filters were learned automatically as part of the training process. This meant the model could optimize itself to detect features most relevant to the dataset.
Since then, the use of hand-engineered features has dropped dramatically. And yet, to appreciate modern CV methods, we must understand the classical ones – not just from a historical perspective, but because they still work beautifully in constrained environments, especially when training data is scarce or computational resources are limited.
Understanding Filters: The Analogy of Light and Shadow
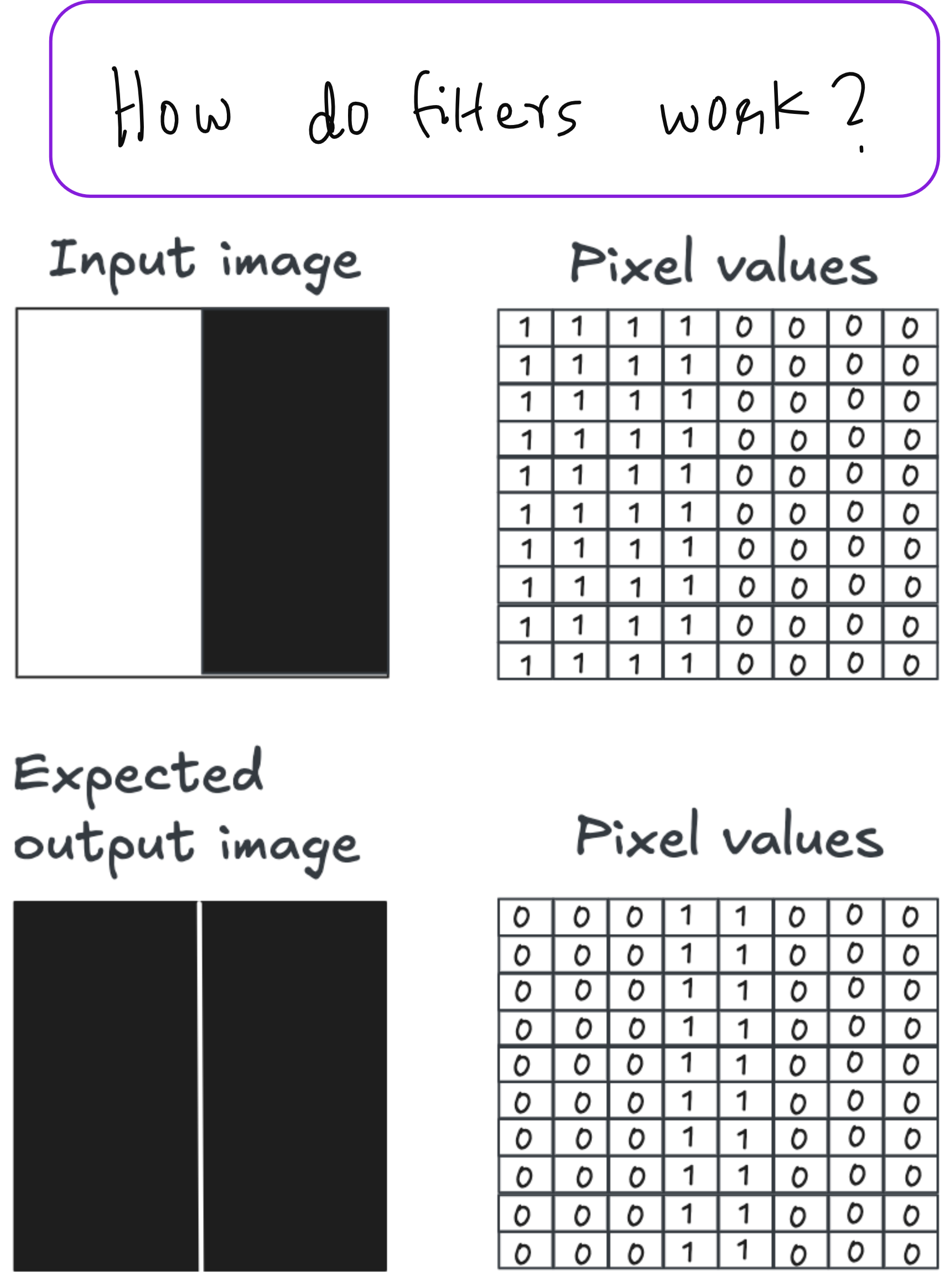
In the lecture, we explored filters using a very intuitive analogy. Imagine a 3x3 matrix, where each cell represents a source or a sink of light. If you want to detect the top edges of objects in an image, you can design a filter where the top row emits negative light (darkness), the bottom row absorbs it (brightness), and the middle row remains neutral.

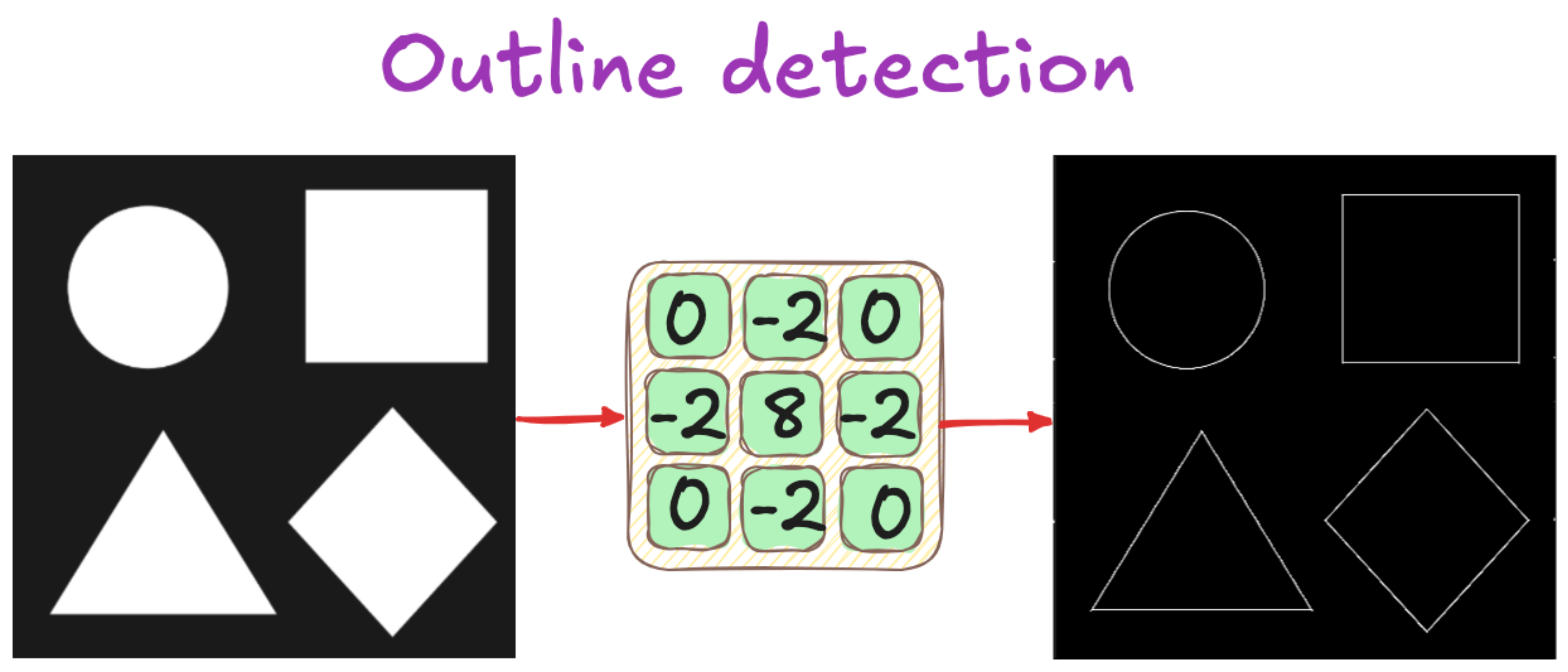
This analogy helps you design filters by thinking of the image as a 3D surface and the filter as a pattern of light rays. Applying such a filter using convolution highlights specific features – for example, vertical edges, diagonal contours, or textured regions.

This is the foundation of traditional computer vision. Before deep learning, people spent years refining these kinds of filters. And understanding them helps demystify what neural networks are doing under the hood. Because in essence, the filters in a CNN are also doing this – except they are learned through backpropagation rather than defined by hand.
OpenCV: Your First Real Tool
We introduced OpenCV as the primary tool for building vision applications. OpenCV is not just a library. It is the de facto standard for real-time image and video processing in Python and C++. It allows you to:
Read and display images and videos
Access webcam streams
Perform geometric transformations (resize, rotate, crop)
Apply classical filters (Gaussian blur, edge detectors, etc.)
Annotate images with shapes and text
Save modified images and frames

In this first session, we used OpenCV to read images, convert them to grayscale, apply Gaussian blur, and use the Canny edge detector to extract contours. We then visualized the output in real-time using OpenCV’s display functions.


Building Something Real: Burglar Detection Without Deep Learning
We wrapped up the session by building our first real application: a burglar detection system using just OpenCV and basic logic.

The idea is simple: take a live camera feed (or pre-recorded video), continuously capture frames, and compute the pixel-wise difference between frames taken at a short time interval. If the difference is significant, it indicates motion – potentially due to an intruder.
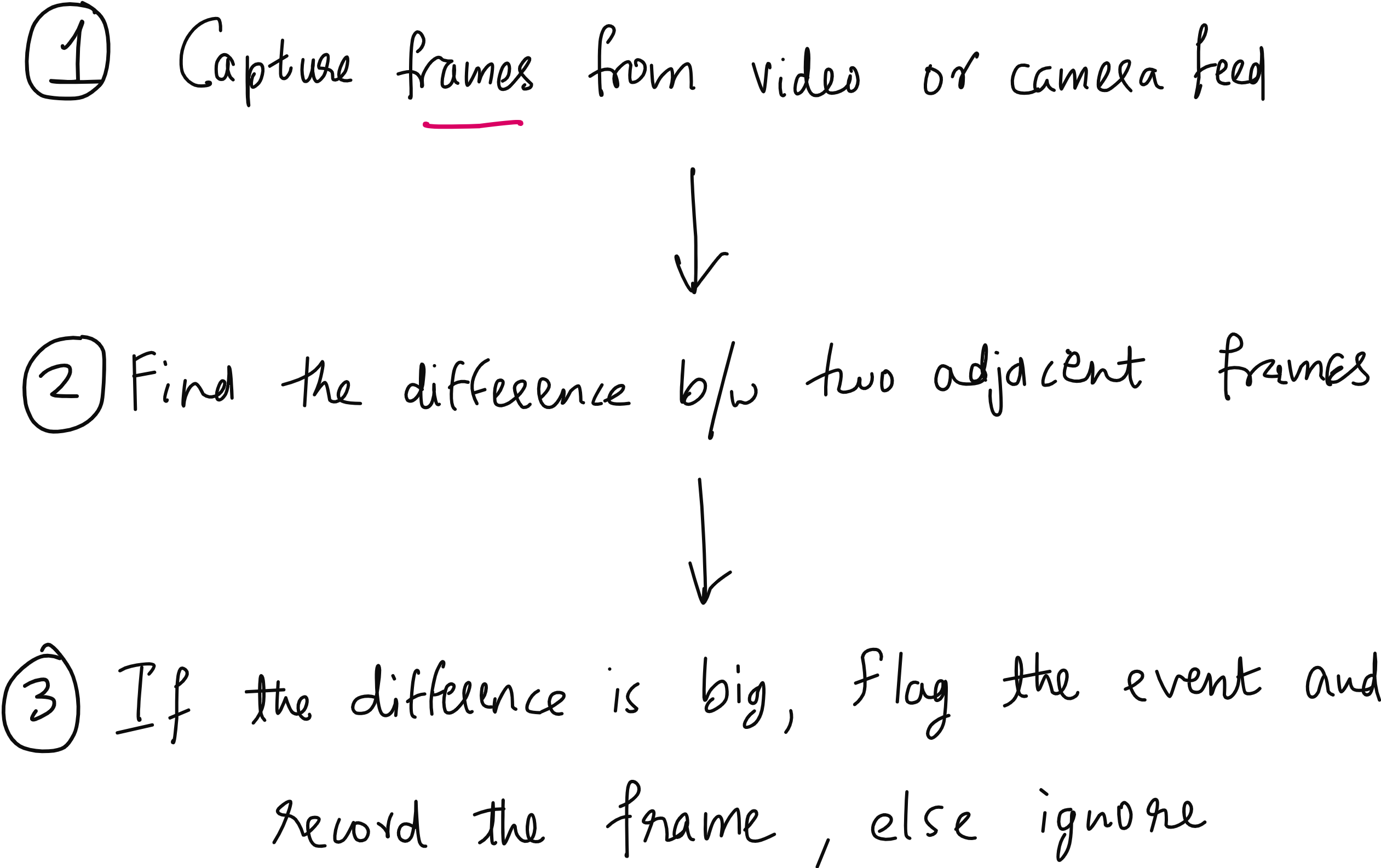
This method is naive. It does not distinguish between a person, a dog, or a falling object. But it is fast, lightweight, and surprisingly effective in indoor settings. And more importantly, it gives students a full pipeline experience:
Capturing and preprocessing video frames
Applying image subtraction
Thresholding to detect significant changes
Annotating frames with bounding boxes and alerts
Displaying and updating frames in real-time
By the end of this project, students not only understand what a basic CV pipeline looks like but also appreciate how powerful even classical methods can be when applied correctly.
Burglar detection code
import cv2
cap = cv2.VideoCapture('video.mp4')
frames = []
gap = 5
count = 0
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frames.append(gray)
if len(frames) > gap +1:
frames.pop(0)
cv2.putText(frame, f"Frame Count: {count}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
if len(frames) > gap:
diff = cv2.absdiff(frames[0],frames[-1])
_, thresh = cv2.threshold(diff, 30, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) < 200:
continue
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
motion = any(cv2.contourArea(c) > 200 for c in contours)
if motion:
cv2.putText(frame, "Motion Detected!", (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imwrite(f"motion_frame_{count}.jpg", frame)
print(f"Saved: motion_frame_{count}.jpg")
cv2.imshow("Motion Detection", frame)
count += 1
if cv2.waitKey(1) & 0xFF == 27: # ESC to exit
breakLooking Ahead: From Basics to State-of-the-Art
In the coming lectures, we will dive into state-of-the-art models and architectures:
R-CNN and its derivatives for region-based detection
U-Net for pixel-level semantic segmentation
YOLOv8 for ultra-fast real-time object detection
Object tracking, pose estimation, and counting
Deployment pipelines using Roboflow


But none of that makes sense without the foundation we built today. Because before you implement YOLO, you need to know why you would not just use a bounding box manually. Before you deploy a segmentation model, you must understand what edge detection fails to do.
And that is why this first chapter is so important. It does not rush. It lays the ground. Because in computer vision, as in anything else, understanding why matters more than knowing how.
YouTube video
Watch the entire lecture here
Enroll in the pro-plan
Get Access to Pro Material If you want access to lecture recordings, assignments, GitHub code, handwritten notes, and our Hands-on CV Book (in progress), visit: 👉