
Core ML algorithms: An overview
What all exist out there


There are two types of people who try to learn machine learning.
The first kind spends weeks tweaking hyperparameters in a Kaggle notebook, watching their leaderboard score bounce like a ping-pong ball.
The second kind never gets started. They open a tutorial, stare at the alphabet soup of SVMs, CNNs, RNNs, LSTMs, and XGBoost, and quietly close the tab.
Both are missing something crucial - a map.
This article is about building that map.
Not a technical deep dive. Not a how-to guide.
Just a brutally honest overview of what exists in machine learning - so you can figure out what matters to you, and what does not.
Let us start with the most basic confusion.
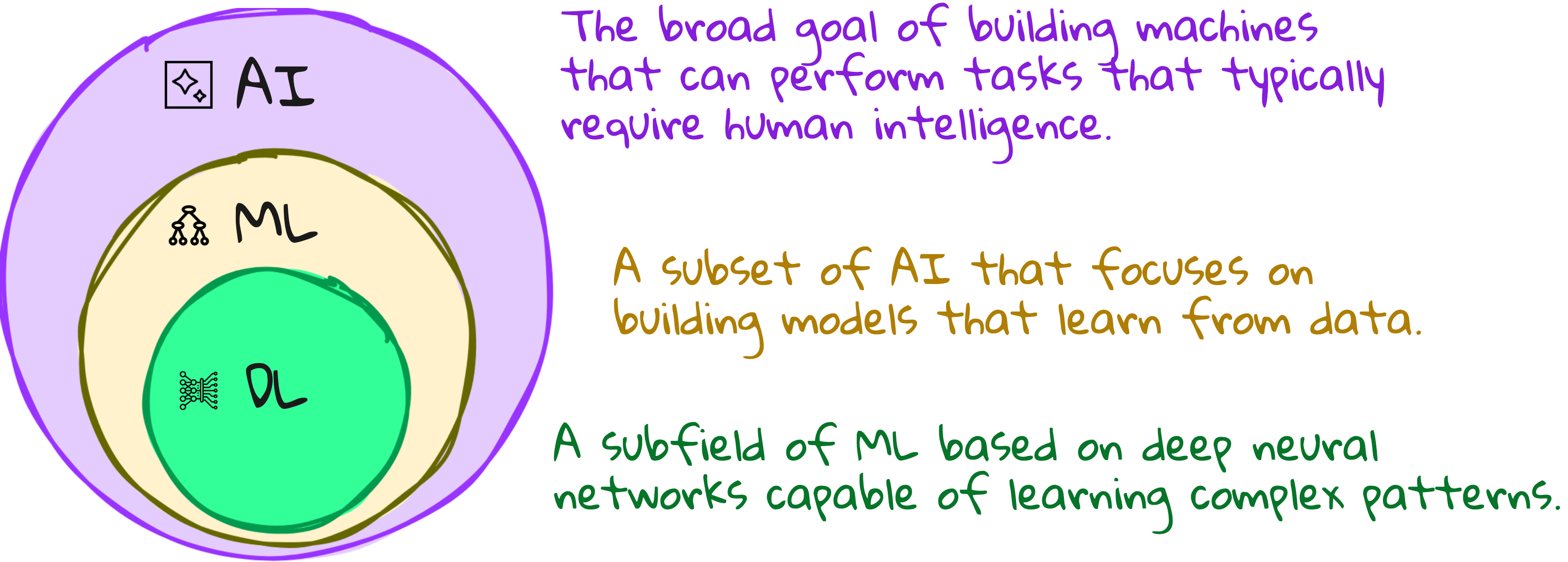
What is AI, ML, and DL, really?
You have heard these terms used interchangeably. They should not be.
AI is the superset. It is the ambition - to make machines behave intelligently. This includes everything from robotics to planning to fuzzy logic.
Machine Learning (ML) is a subset of AI that focuses on data-driven learning. You give it data, it makes predictions. Think of models that learn rules from tabular datasets.
Deep Learning (DL) is a further subset of ML where the features are not handcrafted. Instead, neural networks learn features from raw data like images, audio, or text.
Put simply:
AI is the goal.
ML is the strategy.
DL is the tactic.
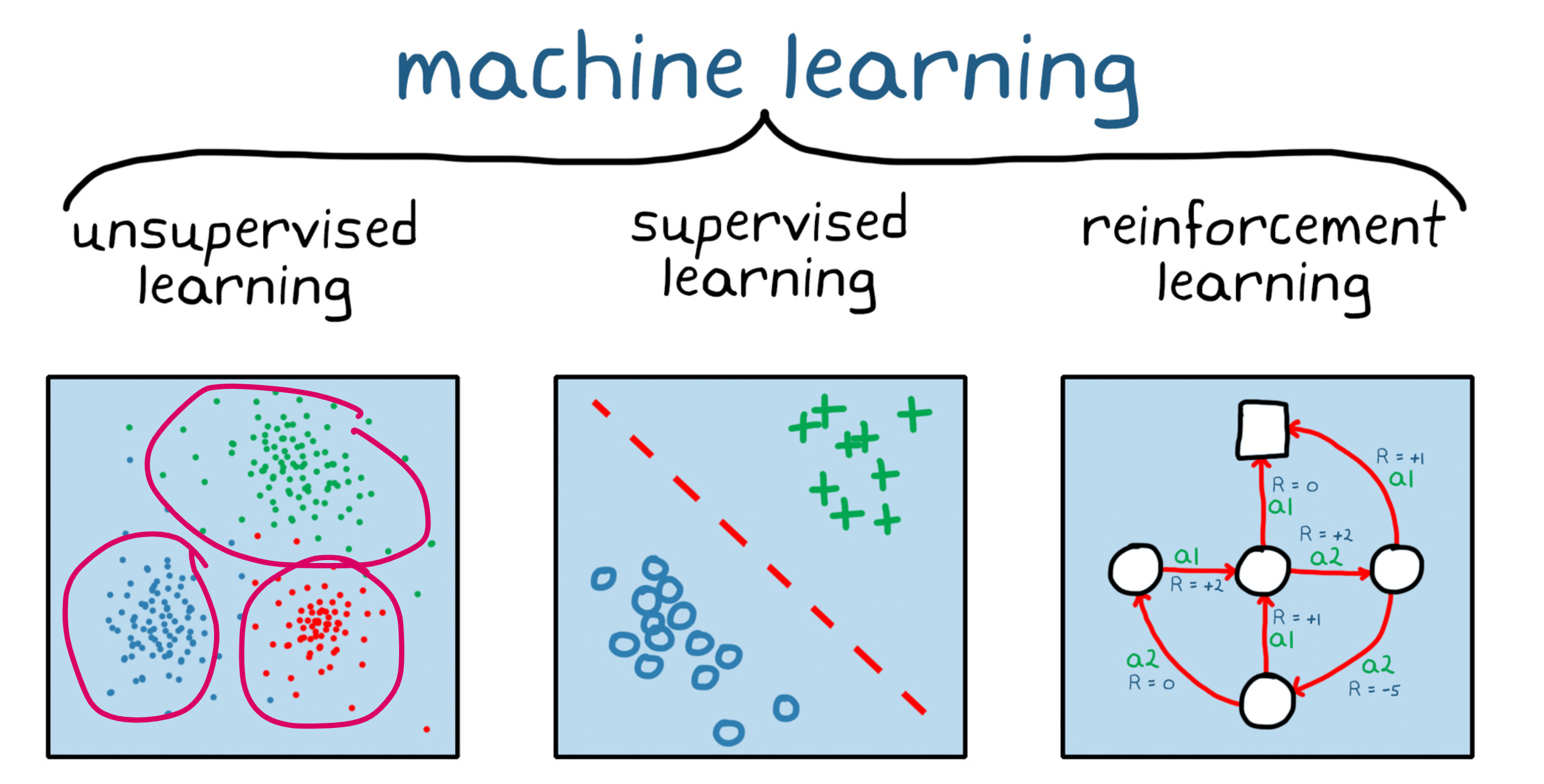
Three types of learning in Machine Learning
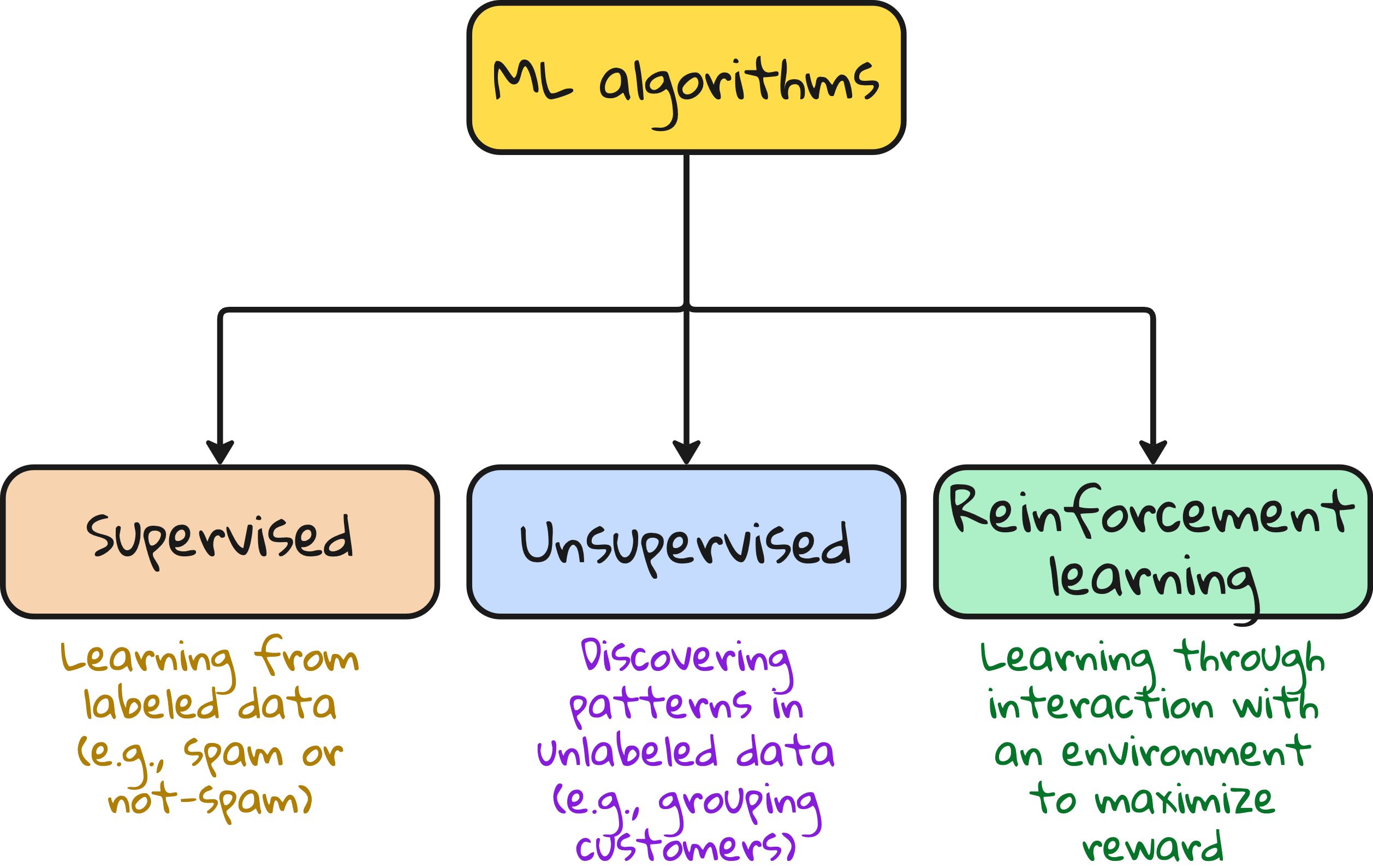
If you had to divide the machine learning universe into three neat buckets, it would look like this:
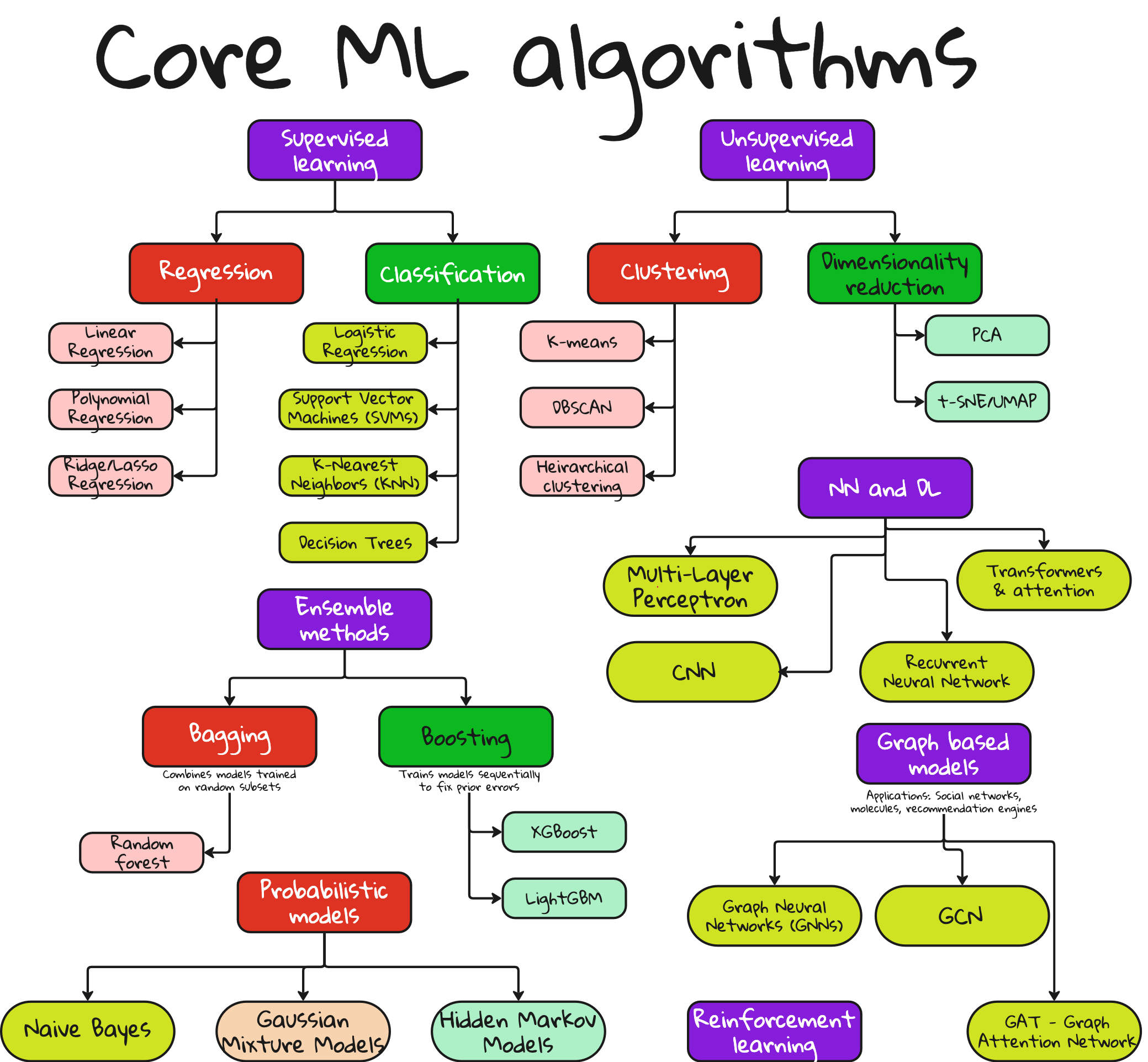
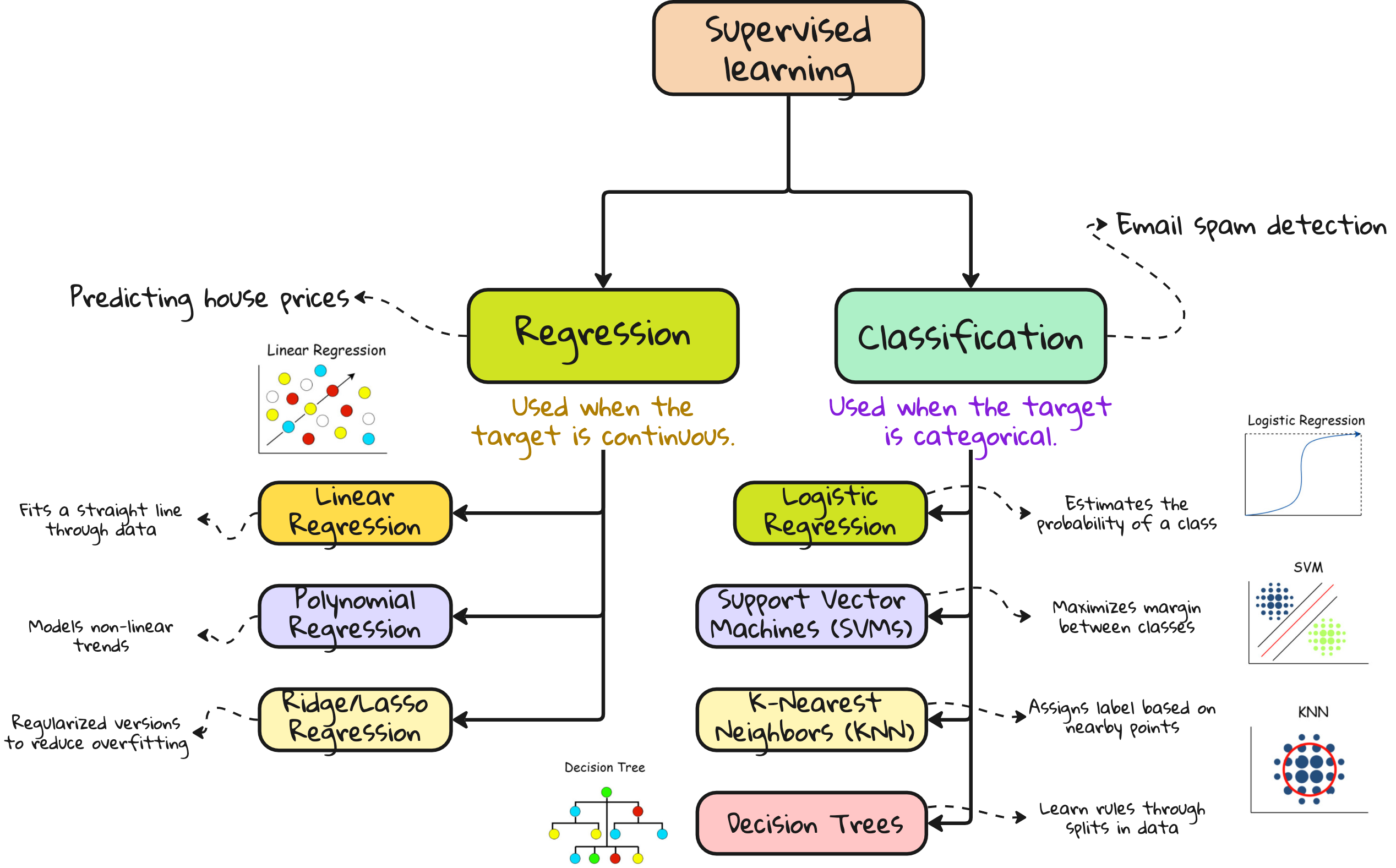
1. Supervised learning
You have data, and you know the labels.
Email marked as spam or not spam
Images tagged as cat or dog
Health records labeled as healthy or not
This is the most widely used form of ML in practice.
Popular tasks: classification and regression
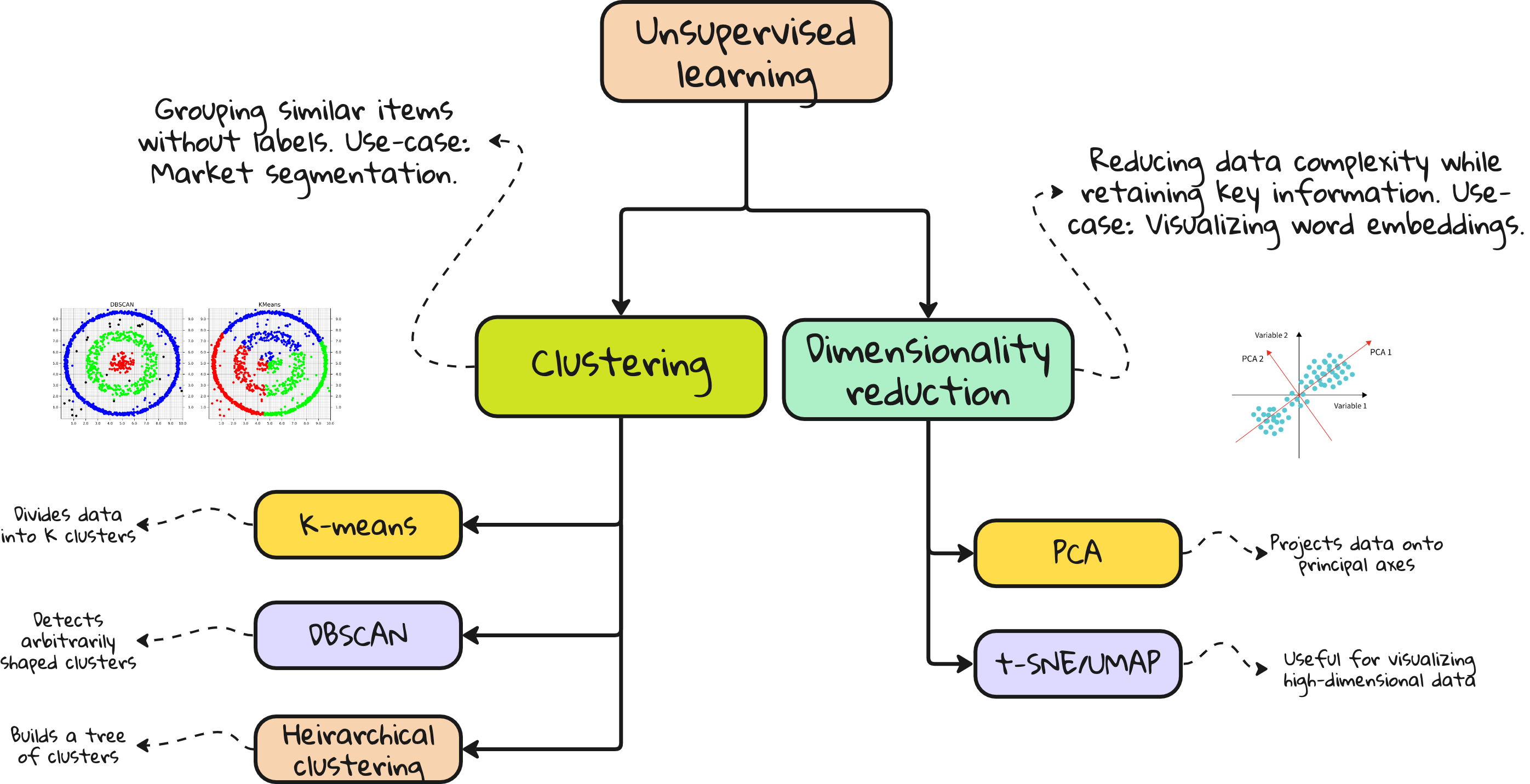
2. Unsupervised learning
You have data, but no labels. You want the model to find structure.
Grouping customers based on buying habits
Finding clusters in high-dimensional space
Reducing features before applying a supervised model
Popular methods: clustering, dimensionality reduction
3. Reinforcement learning
You train an agent to interact with an environment and learn through reward and punishment.
Teaching a robot to walk
Training a model to play Go
Optimizing delivery routes based on traffic patterns
The agent chooses an action, gets feedback, and updates its strategy. Over time, it learns what works.
Supervised learning algorithms you should know
Classification
Logistic regression – Linear decision boundary, great for binary tasks.
Support Vector Machine (SVM) – Maximizes margin between classes.
k-Nearest Neighbors (k-NN) – Lazy learning. Labels based on neighbor majority.
Decision Trees – Split data using feature thresholds.
Random Forest – Ensemble of decision trees using bagging.
Gradient Boosting / XGBoost – Fixes weaknesses of previous models. Very popular in industry.
Regression
Linear regression – Predicts a continuous value using a straight line.
Polynomial regression – Fits nonlinear curves.
Ridge / Lasso regression – Adds regularization to prevent overfitting.
Unsupervised learning algorithms that matter
Clustering
k-Means clustering – Partition data into k groups.
DBSCAN – Detects arbitrarily shaped clusters, robust to noise.
Hierarchical clustering – Builds tree-like structure of clusters.
Dimensionality reduction
Principal Component Analysis (PCA) – Projects data onto lower-dimensional space.
t-SNE / UMAP – Great for visualizing high-dimensional data.
These are not prediction tools. They are data understanding tools.
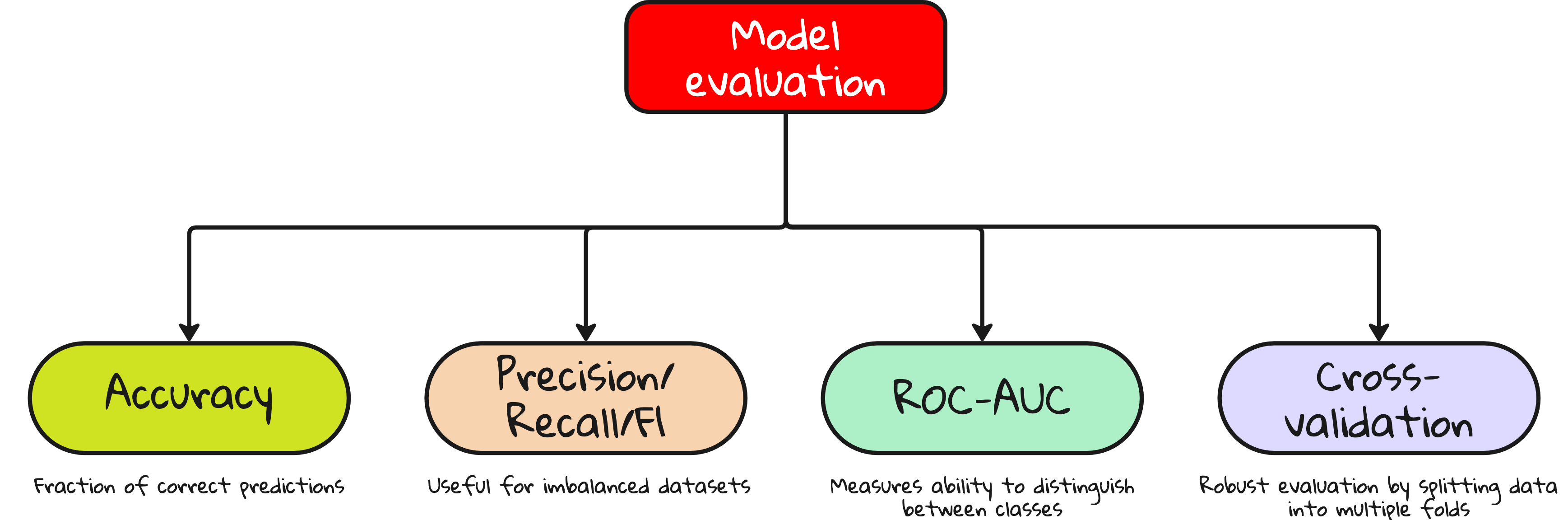
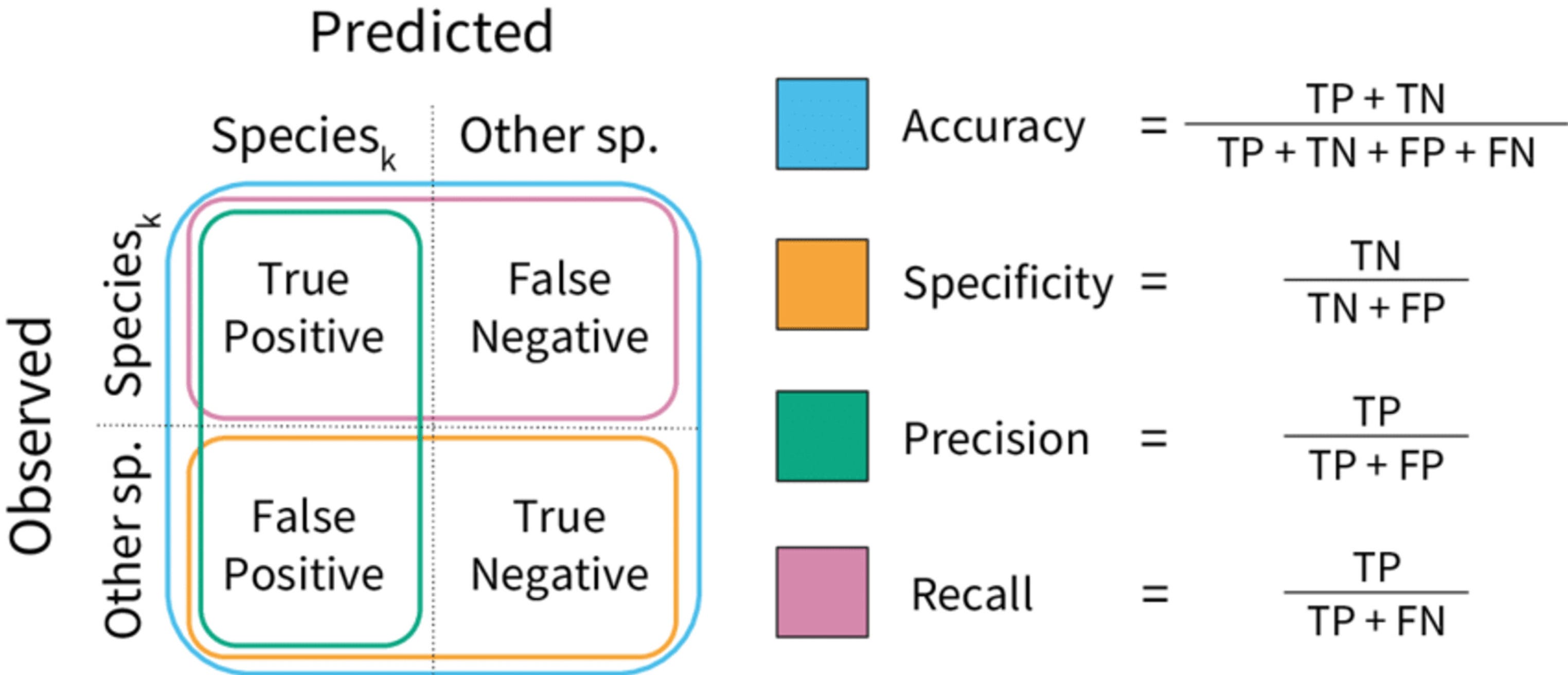
Evaluation metrics that actually tell you something
Accuracy is not enough.
Learn these terms if you want to convince anyone that your model works:
Precision – Of the positives predicted, how many were actually positive?
Recall – Of all actual positives, how many did you catch?
F1 Score – Harmonic mean of precision and recall.
ROC AUC – Tradeoff between true positive and false positive rate.
Cross-validation – Splitting data to ensure robustness.
If you are building real-world models, this section is not optional.
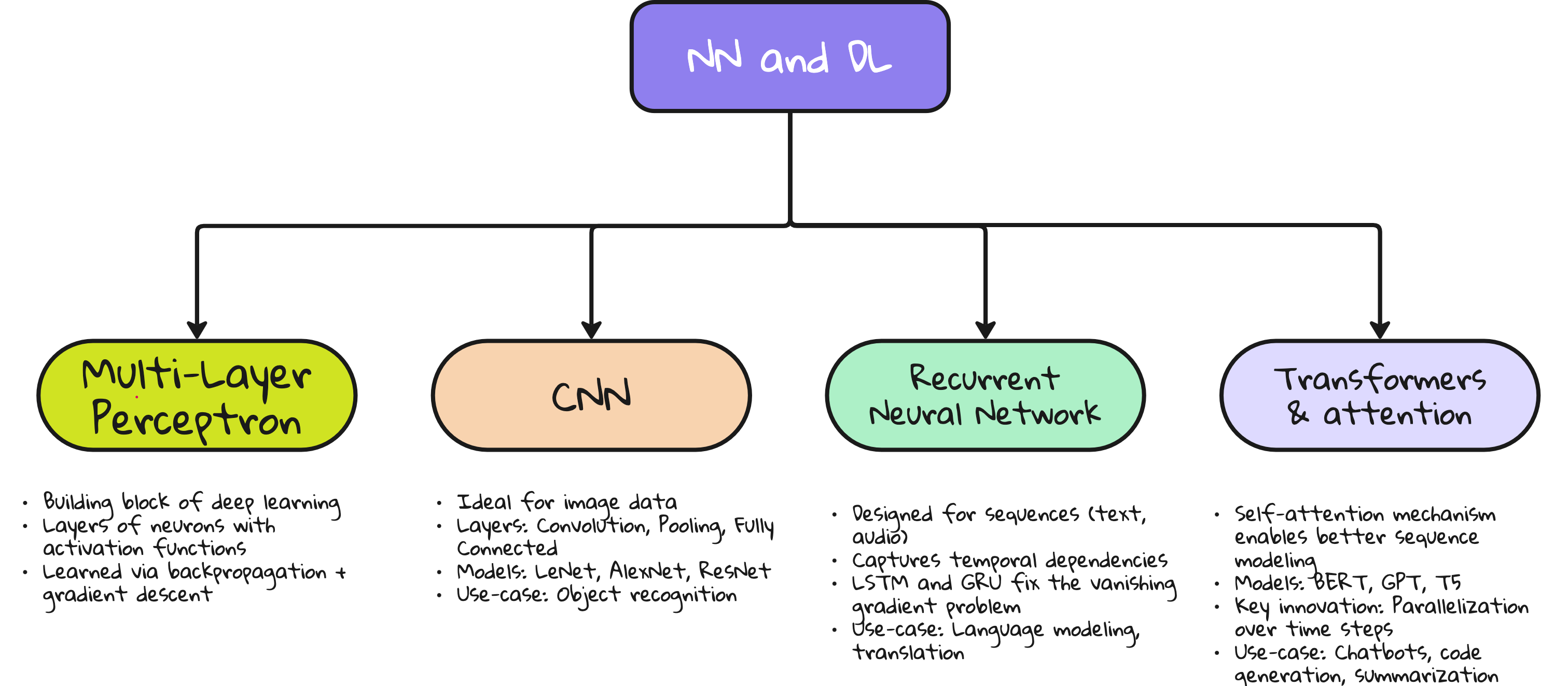
Deep Learning models that changed the game
Multi-Layer Perceptron (MLP)
A fully connected feedforward network.
Great for tabular data. But struggles with images or sequences.
Convolutional Neural Networks (CNNs)
Used for images.
Extracts spatial features using convolution filters.
Networks like AlexNet, VGG, ResNet revolutionized computer vision.
Recurrent Neural Networks (RNNs), LSTM, GRU
Used for sequences like time series or natural language.
LSTM and GRU fix the vanishing gradient problem in vanilla RNNs.
Transformers
Used for text, increasingly for images.
Self-attention mechanism.
Powers GPT, BERT, and Vision Transformers.
This is where most of the action in research and applications is today.
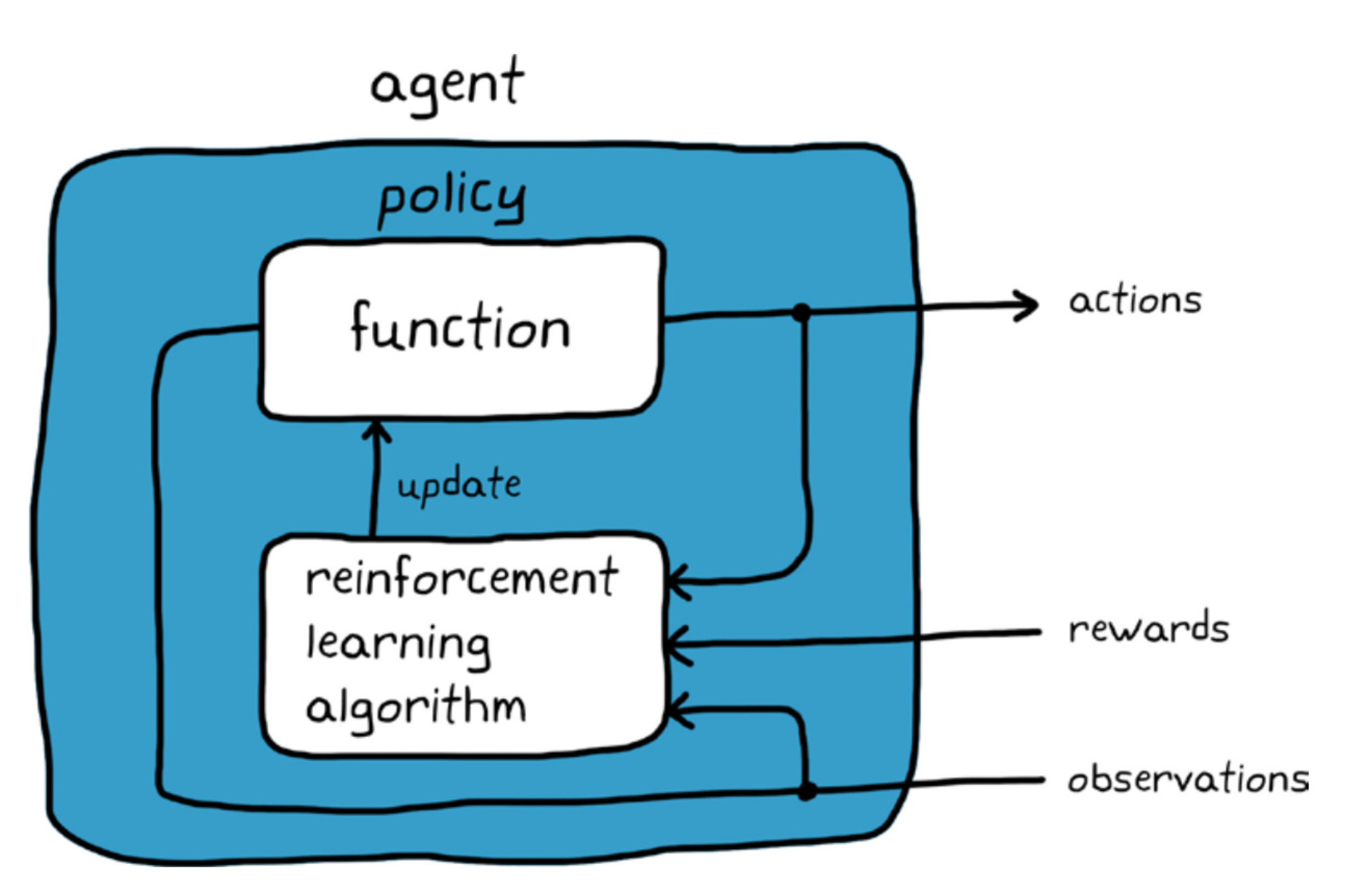
Reinforcement Learning in the real world
Agent, environment, action, reward.
The agent takes an action.
The environment gives a reward.
The agent updates its policy.
Examples:
Q-learning – Basic algorithm to learn optimal policy.
Deep Q Networks (DQN) – Combines Q-learning with deep neural networks.
From training humanoid robots to beating Go champions, this is one of the most fascinating areas in ML.
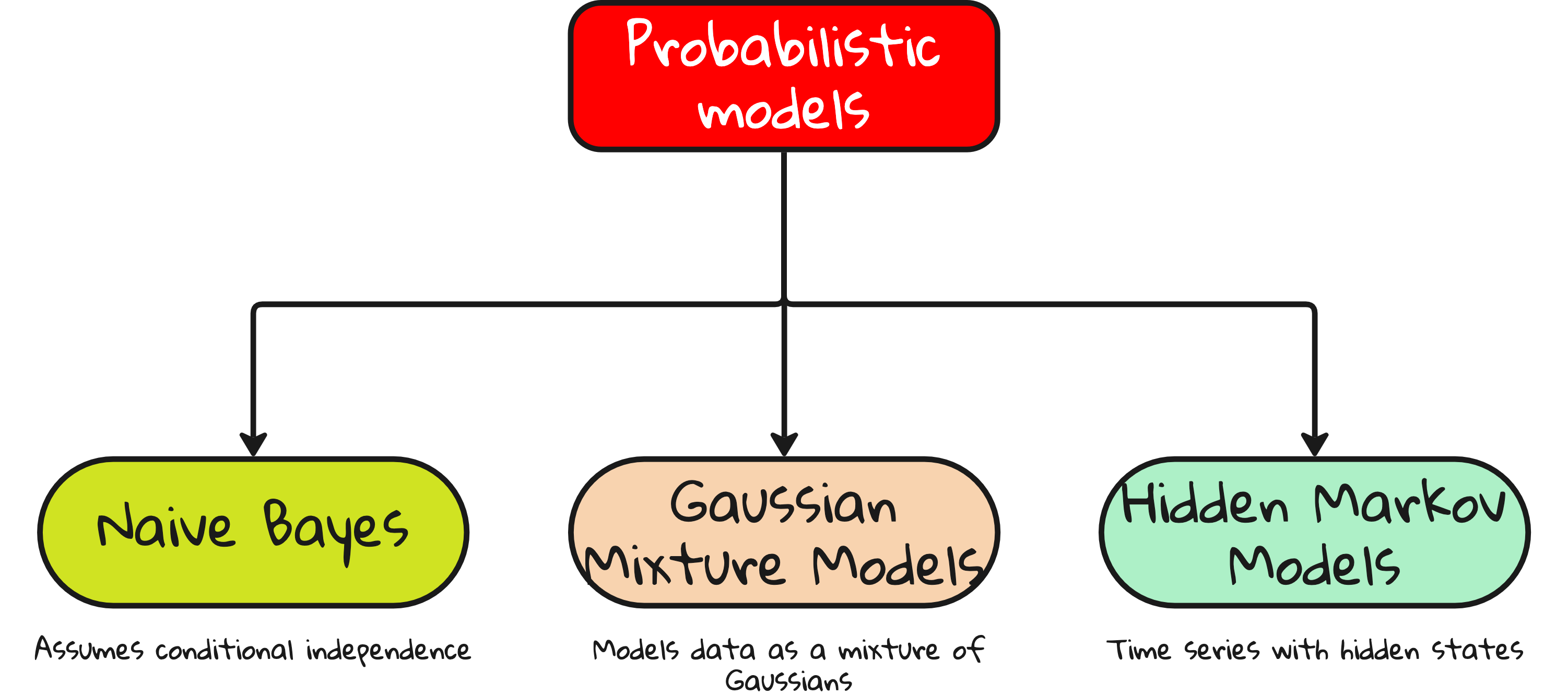
Probabilistic models
Based on probability theory. Great for interpretability.
Naive Bayes – Assumes feature independence. Surprisingly powerful.
Hidden Markov Models (HMMs) – Used for sequence modeling.
Gaussian Mixture Models (GMMs) – Model data as mixture of distributions.
Not flashy. But mathematically beautiful.
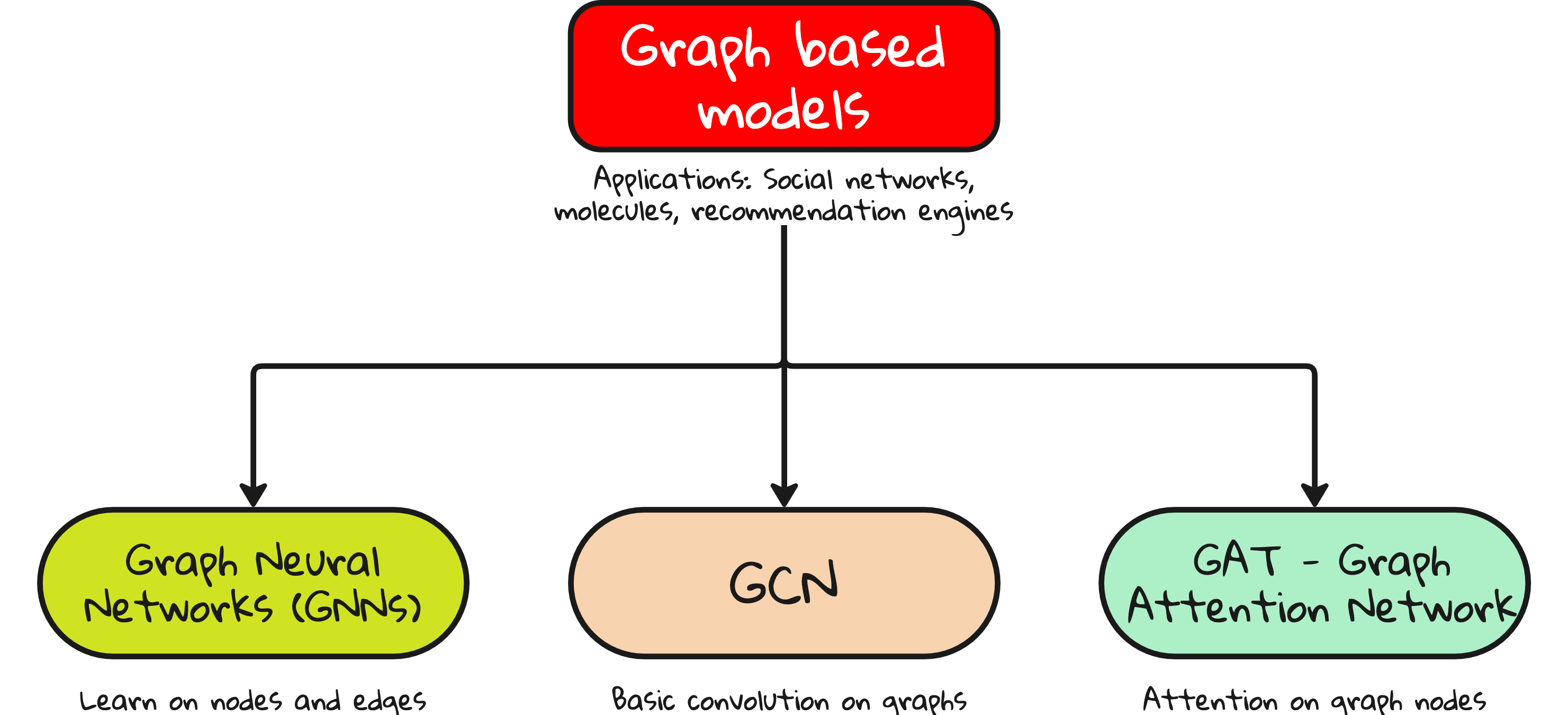
Graph-based learning
Data is not always tabular or image-like.
Sometimes, it is a network.
Graph Neural Networks (GNNs) – Learn over graph-structured data.
Graph Convolutional Networks (GCNs) – Use node neighborhoods.
Graph Attention Networks (GATs) – Apply attention over edges.
Used for molecules, social networks, recommendation systems. Hugely relevant in scientific ML.
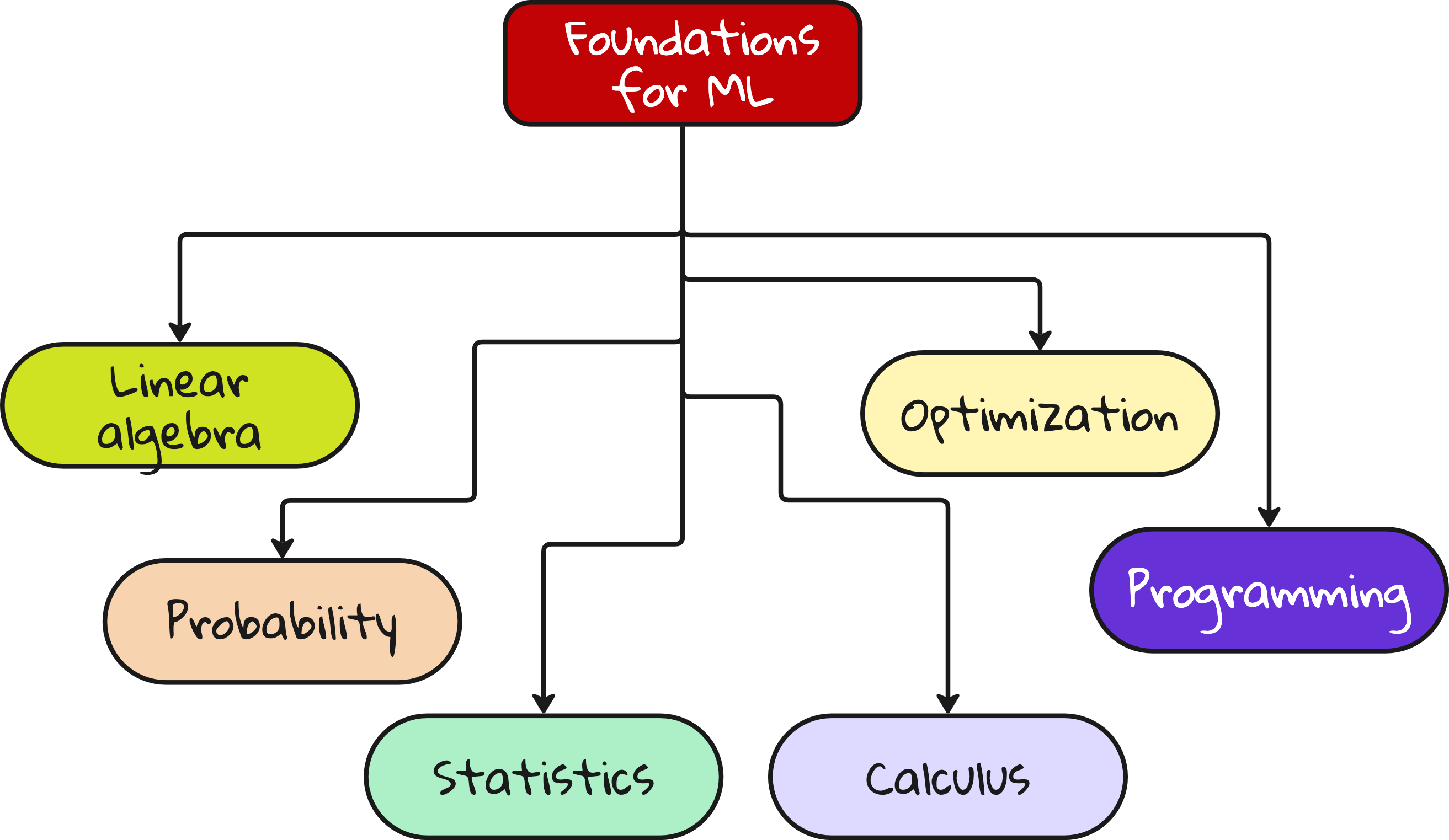
What you really need to master
At the root of it all lie six foundations:
Linear algebra – Vectors, matrices, eigenvalues
Probability – Distributions, Bayes theorem
Statistics – Hypothesis testing, confidence intervals
Calculus – Gradients, chain rule
Optimization – Gradient descent, convexity
Programming – Python, NumPy, PyTorch or TensorFlow
You cannot build skyscrapers on a foundation of sand.
And most people try to learn ML without even touching these.
So, where do you go from here?
You do not need to learn everything.
But you do need to know what exists.
This article was not meant to teach you the details.
It was meant to zoom out, so that when you zoom in, you do it with purpose.
Here is how you can use this:
Identify what aligns with your goals – career, research, startup
Build your roadmap accordingly
Be honest about what you do not know
And go deep in a few areas, not shallow in all
Learning machine learning is not a race. It is an expedition.
Bring a map.
Full lecture video
Interested in ML foundations?
Check this out: https://vizuara.ai/self-paced-courses