
Contrastive learning in VLMs
A simple idea that made text and vision alignment possible


If there is one idea that completely transformed how machines understand images and text together, it is contrastive learning. It’s a simple idea mathematically, but its impact was so big that it enabled OpenAI’s CLIP model - one of the most influential vision-language models ever created.
In this article, we will break down:
What contrastive learning really means
Why it became essential for vision-language models
The math behind contrastive loss
How CLIP uses this idea to align images and text
Why temperature (τ) in the loss formula matters more than you think
1. The Problem: How Do You Make Images and Text Speak the Same Language?
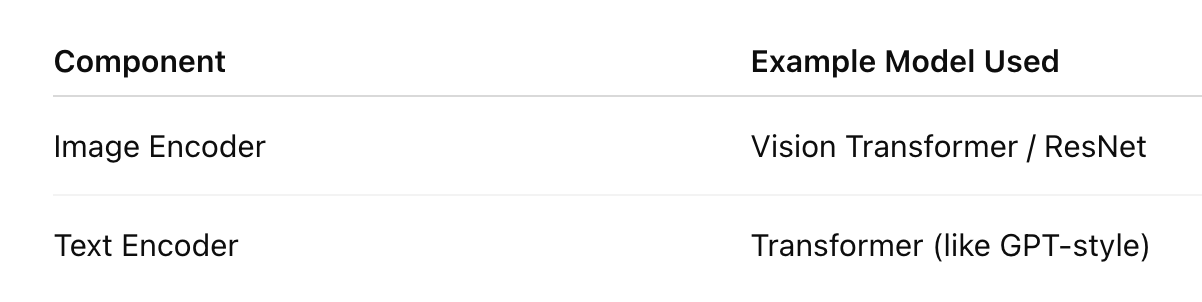
A basic vision-language model has two parts:
An image encoder (like a Vision Transformer or CNN)
A text encoder (like BERT or a Transformer decoder)
Both convert their inputs into vector embeddings. Now the challenge is this — if we give an image of a dog and the text “a happy dog running towards the camera,” both their embeddings should be close in the joint embedding space.
If we can achieve this reliably, then tasks like image search, captioning, and text-to-image similarity become natural.
But how do we train a model to do this?
2. The Core Idea: Contrastive Learning
Contrastive learning solves one simple problem —
Bring similar things closer, and push dissimilar things apart in the embedding space.
To do this, we create two types of pairs:

So the model learns a metric space — where correct image-text pairs are close, and unrelated pairs are far apart.
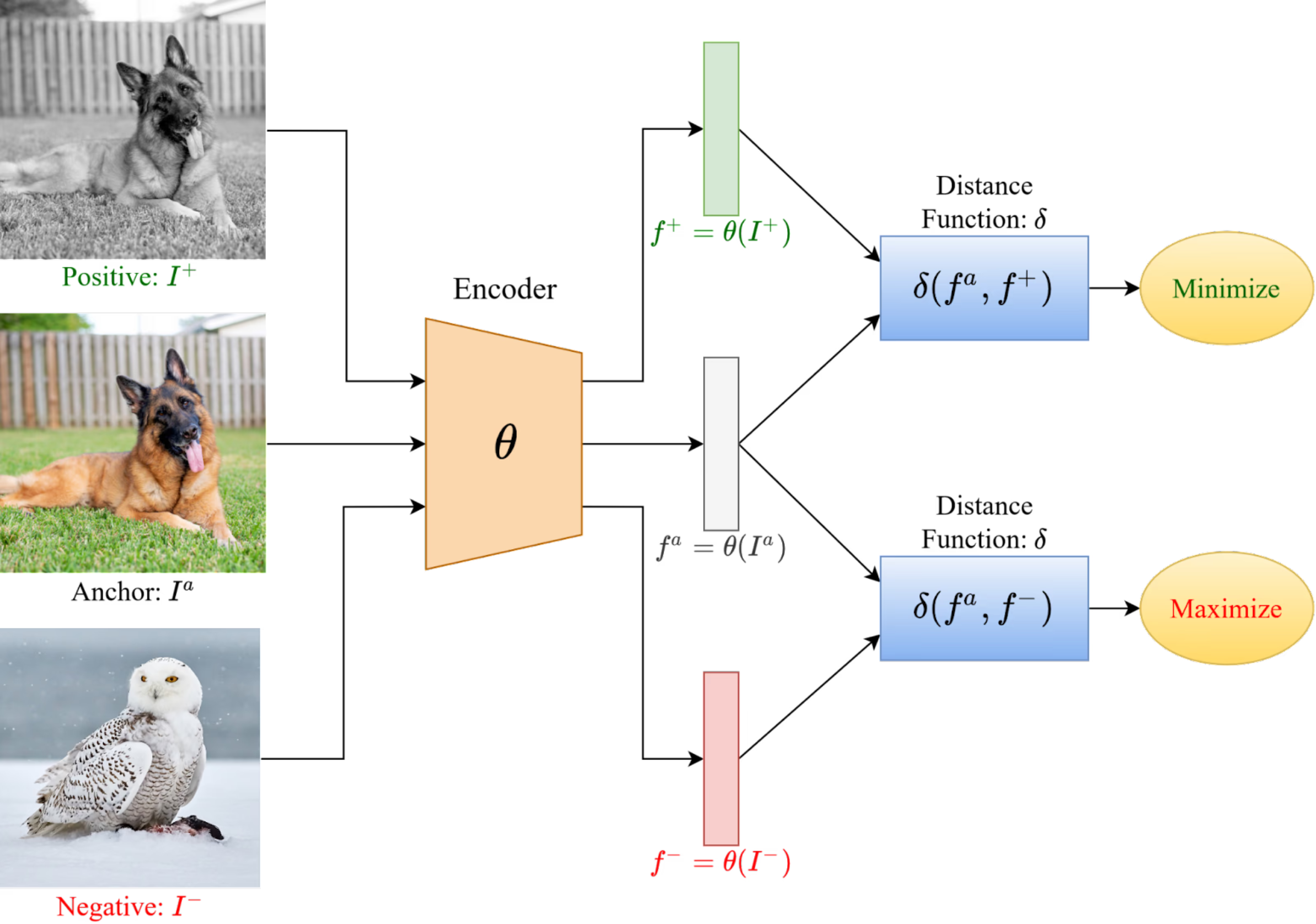
3. Positive Pairs Through Augmentation: Creating Two Views of One Image
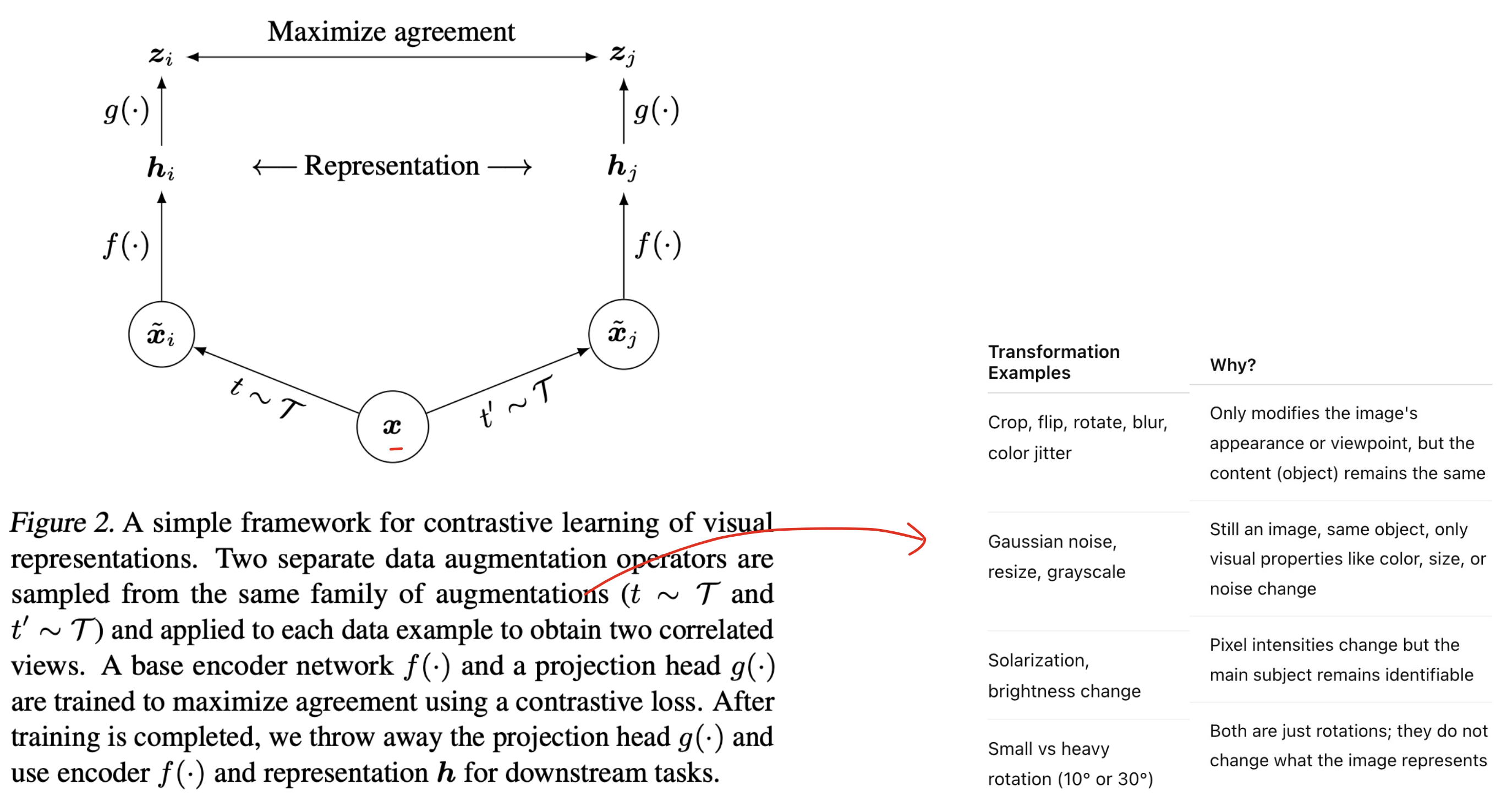
In pure image-only contrastive learning (like SimCLR), positive pairs are created by applying different augmentations to the same image:
Random cropping
Horizontal flip
Color jitter
Grayscale
Rotation
Gaussian blur

Both augmented images still mean the same thing — so the model must learn that they belong together.

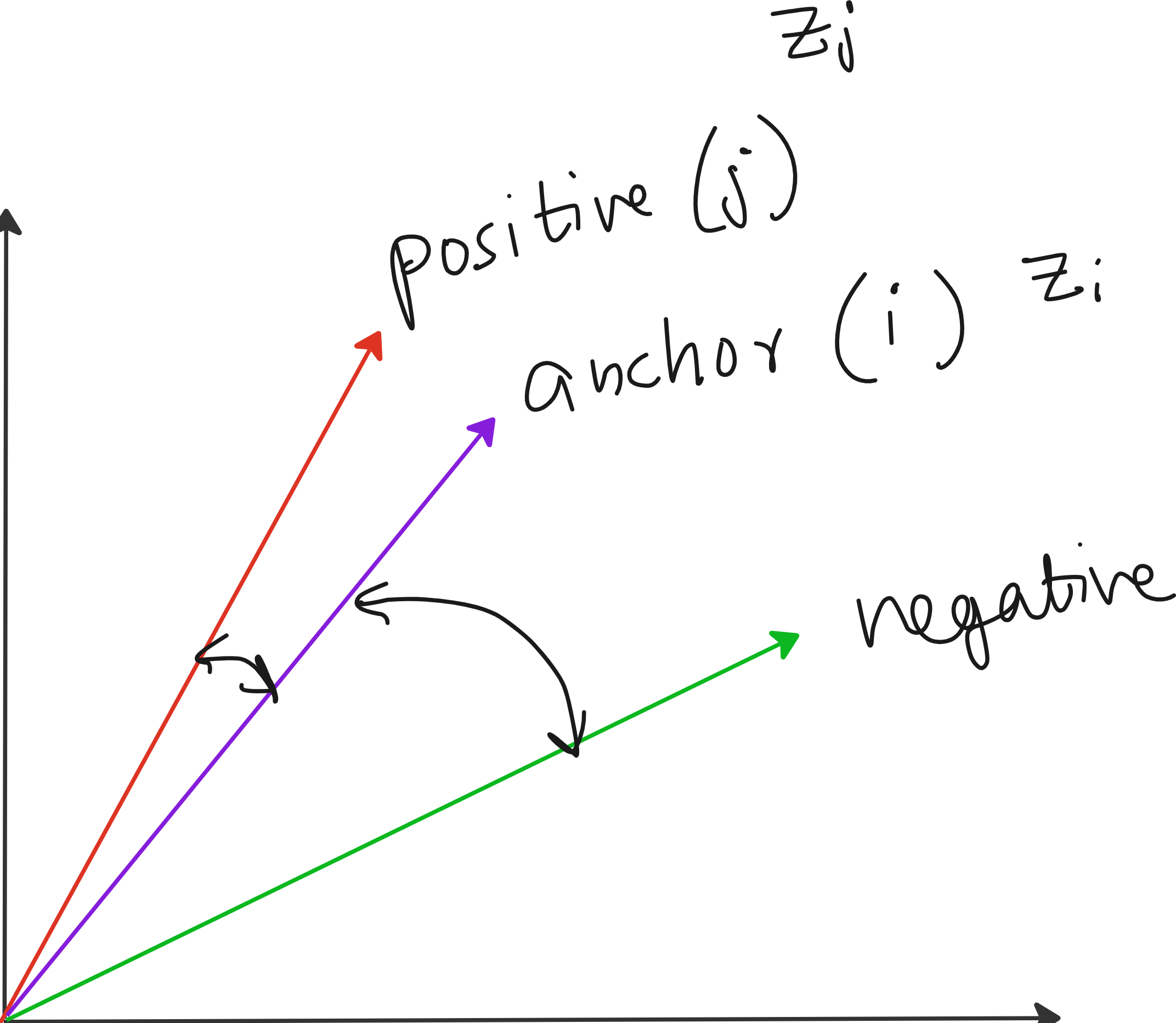
4. The Math Behind Contrastive Loss
Let’s say:
We take an image as anchor → create two augmented versions
Pass them through an encoder + projection head
Get two embeddings: zᵢ and zⱼ
We want them to be similar, so we use cosine similarity:
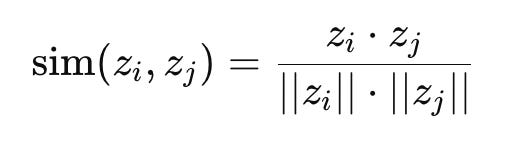
To convert this into a loss, we use softmax + negative log likelihood:
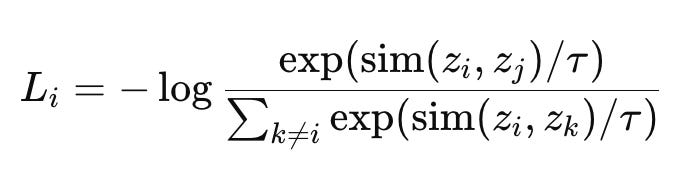
Where:
τ is temperature
Lower τ makes softmax sharper → model focuses more on hard negatives
Higher τ gives smoother gradients → slower, but more stable learning
5. CLIP: Contrastive Learning with Images and Text
OpenAI took this idea and scaled it to 400 million image-text pairs from the internet.
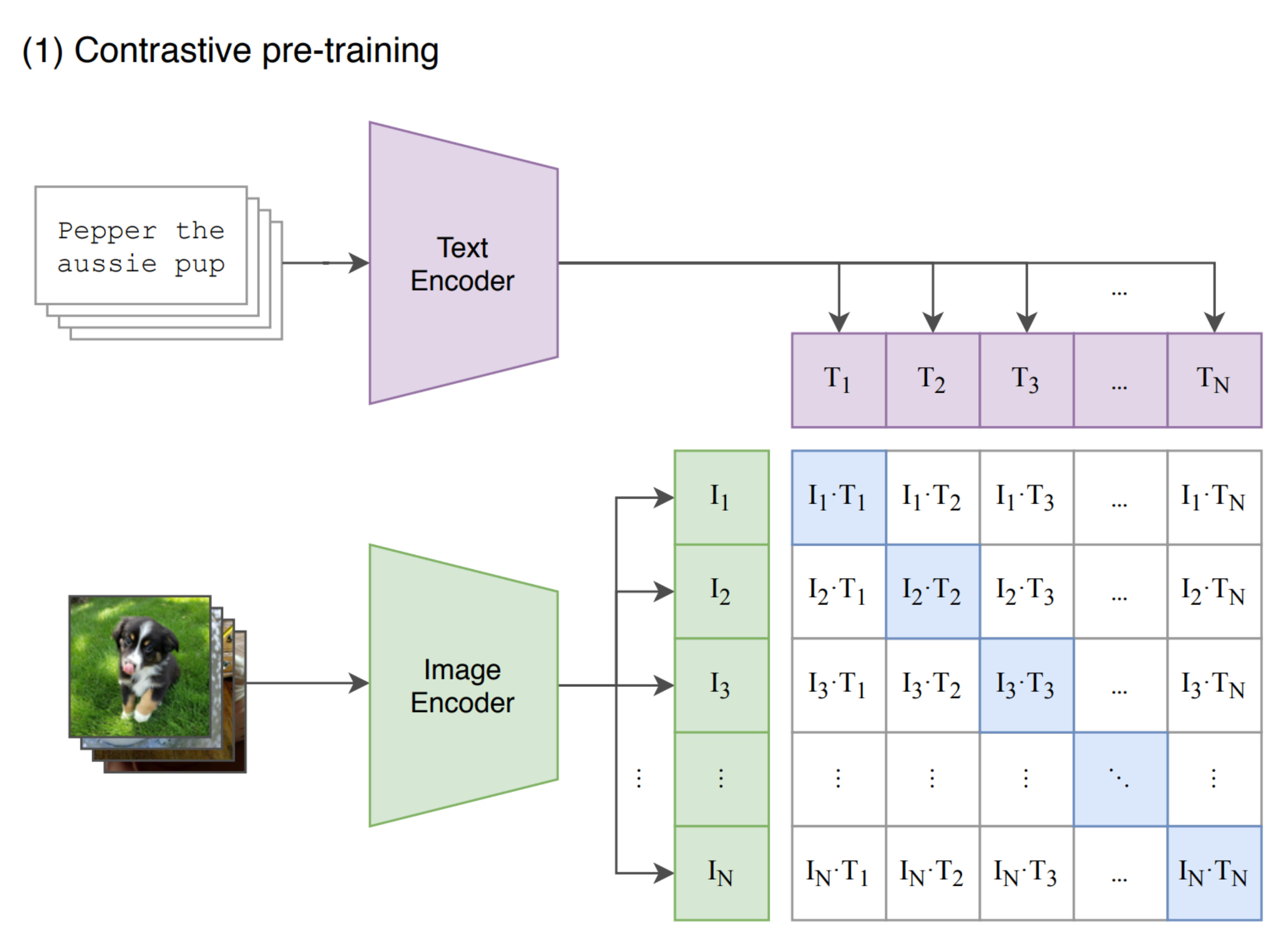
For a batch of N images and N texts:
Image embeddings → I₁, I₂, ..., Iₙ
Text embeddings → T₁, T₂, ..., Tₙ
The only correct pairs are (I₁, T₁), (I₂, T₂), ..., (Iₙ, Tₙ).
Everything else is a negative pair.
So CLIP uses symmetric contrastive loss:

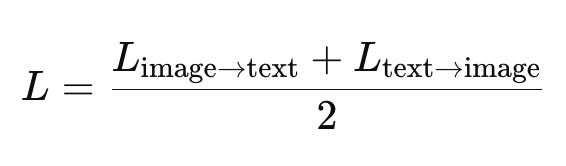
This makes sure that:
Each image is closest to its caption
Each caption is closest to its image
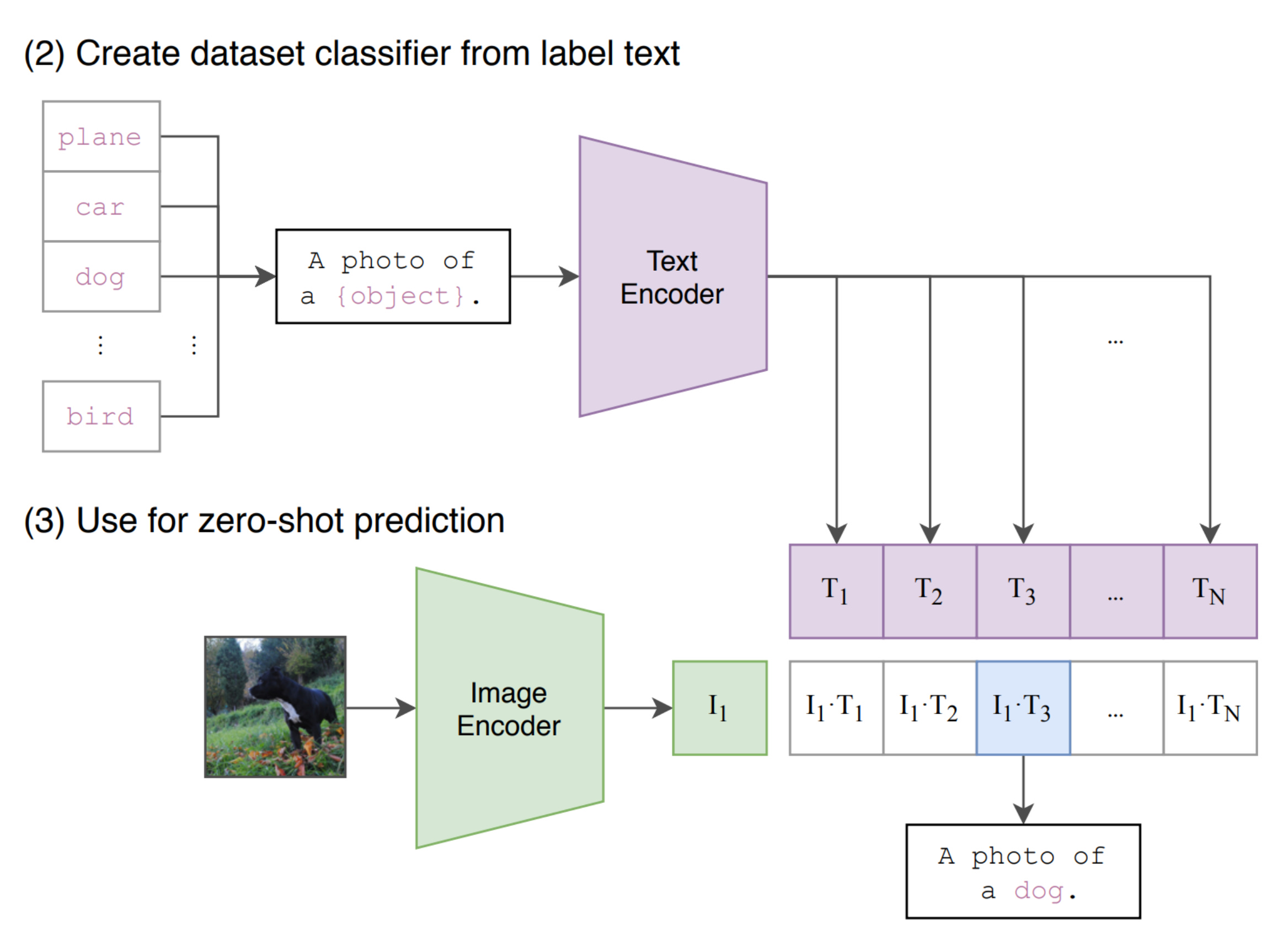
This simple idea made CLIP capable of zero-shot image classification. No need for ImageNet fine-tuning. Just type:
“A photo of a golden retriever.”
And compare its embedding with image embeddings. The highest cosine similarity wins.
6. Why Contrastive Learning Works So Well
✔ No need for labelled datasets like ImageNet.
✔ Only needs (image, caption) pairs — which are freely available on the internet.
✔ Learns a universal visual-semantic understanding.
✔ Works for classification, retrieval, and multimodal reasoning.
7. What’s Next?
In the next lecture/article, we will build a Nano Vision-Language Model from scratch and implement the same CLIP-style loss function.
You will see:
Custom image and text encoder
Contrastive loss implementation
Training on a mini dataset
YouTube lecture
Join Vision Transformer PRO
– Access to all lecture videos
– Hand-written notes
– Private GitHub repo
– Private Discord
– “Transformers for Vision” book by Team Vizuara (PDF)
– Email support
– Hands-on assignments
– Certificate
This article comes at the perfect time, your explanation of how to make images and text speak the same language felt truly magica. How do you see these models handling irony or complex metaphors in the future?