
A Brief History of Computer Vision
From hand-made filters to transformers (2010-2025)


The history of computer vision over the past 15 years is not merely about architecture improvement. It is the story of how algorithms began to see, first in edges and gradients, then in textures and shapes, and finally in full meaningful context .
This article from Computer Vision from Scratch series offers a timeline-driven account of how convolutional neural networks (CNNs) evolved between 2010 and 2020. My aim is to retell that story for the curious reader - one who might have heard of AlexNet or ResNet, but never paused to ask why these models were created or what problems they solved.
In the last three months I have spent a disproportionate amount of time on convolutional neural networks. I have coded several CNNs from scratch and now understand the inner workings of many models. But what makes me truly appreciate these models is the history of their evolution more than their beautiful mathematical construct. I feel like knowing the historical context adds an extra layer of meaning to what we learn. So although some models are obsolete now, I still feel like going into its technical details because I am able to place the model in its historical context. It is an oddly satisfying feeling.
Let us begin at the beginning.
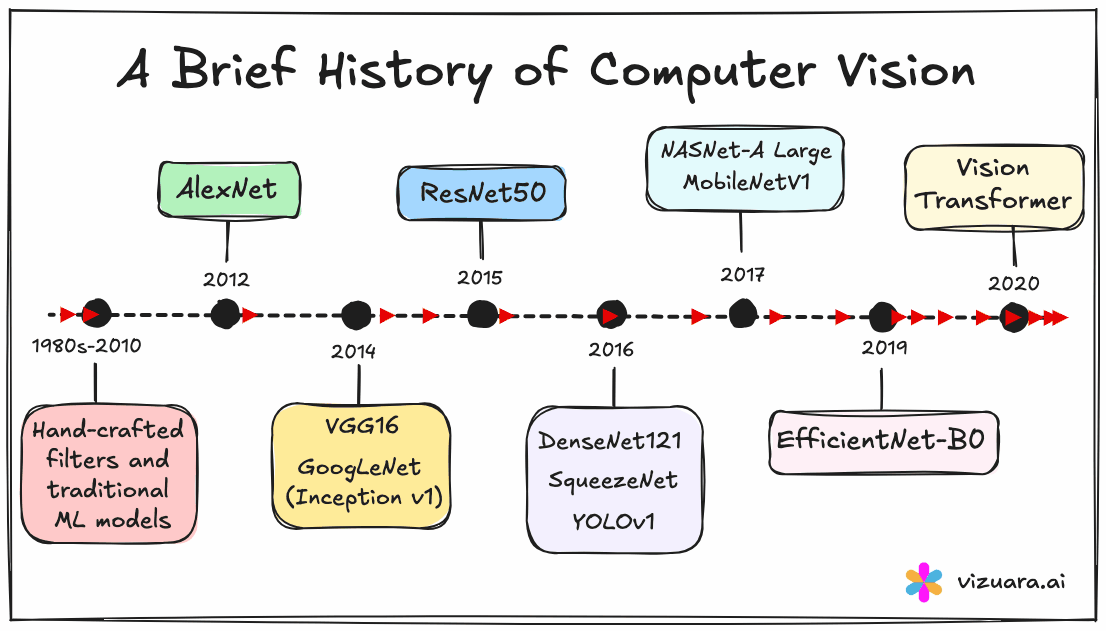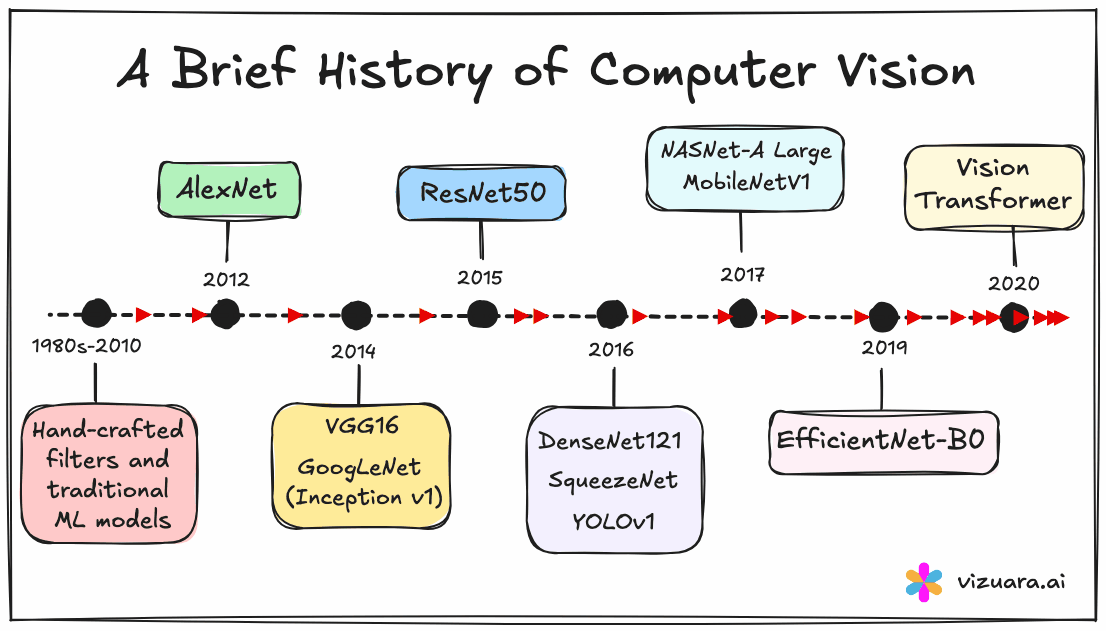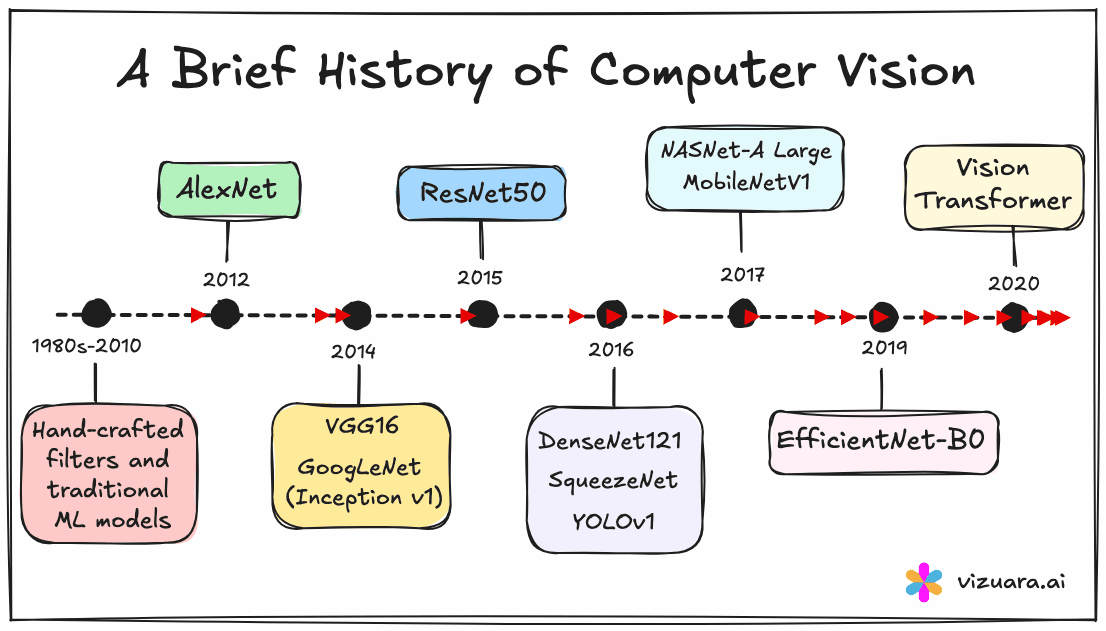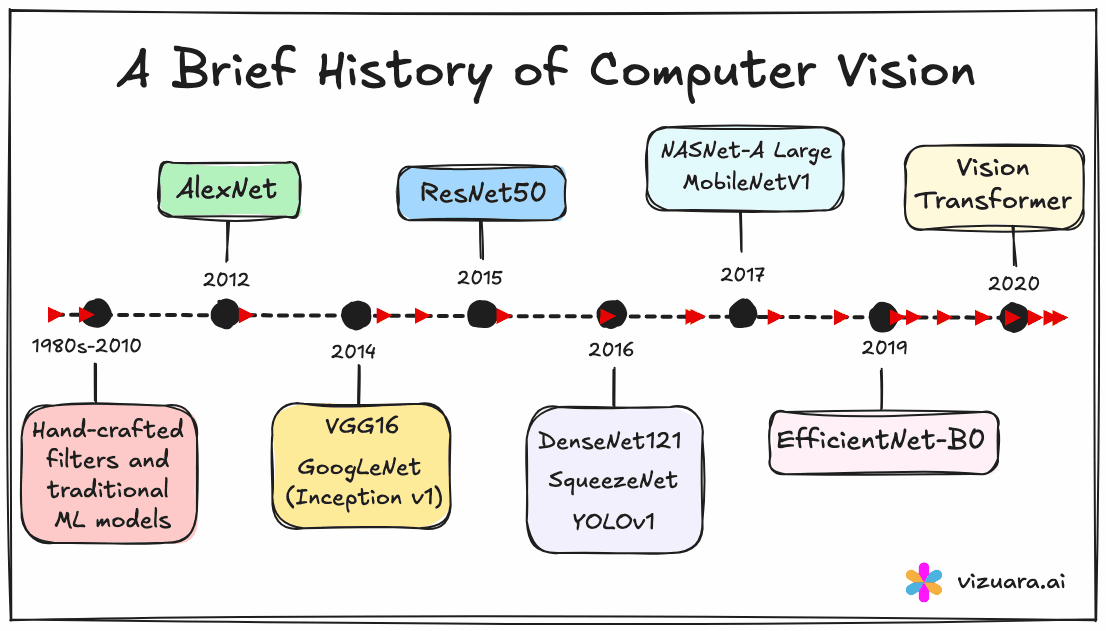
The era before Deep Learning
Before 2012, the dominant approach to computer vision was largely handcrafted. Researchers designed filters to extract useful information from images. The Sobel filter detected edges. The Laplacian operator found contours. Gradient-based descriptors like SIFT and HOG captured local shape patterns.

These features, once extracted, were passed into classical ML algorithms such as SVM or decision trees. These models worked with structured, engineered inputs. Vision, in this context, meant detecting what humans already believed to be useful.


Neural networks were not absent from the landscape. Their use, however, was rare and mostly academic. Training deep networks required computing power that was not readily available. Even if one had the will, one seldom had the means.
That changed in 2012.

The AlexNet breakthrough
In the 2012 ImageNet competition, a deep convolutional neural network called AlexNet entered the stage and changed everything. Developed at the University of Toronto by Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever, AlexNet outperformed the competition by a significant margin.

It was a deep model by the standards of the time - eight layers, around 60 million parameters. It employed ReLU activation functions, dropout regularization, and most importantly, it was trained on GPUs. These choices, now commonplace, were radical at the time.

AlexNet demonstrated that deep learning could work on large-scale vision problems without handcrafted features. From this moment on, the focus of research began to shift.

Depth and modularity: VGG and Inception
Following the AlexNet success, two different philosophies emerged in 2014.
The first was exemplified by VGG, a model from the Visual Geometry Group at Oxford. VGG was deep-16 to 19 layers-and simple. It used only 3x3 convolution filters and stacked them in sequence. The design choice was deliberate: rather than explore architectural complexity, VGG pursued uniformity and depth. However, the model was massive in size, with over 138 million parameters, making it difficult to deploy in resource-constrained environments.

The second philosophy came from Google, in the form of GoogLeNet or Inception V1. This model introduced the concept of modular design in CNNs. Each Inception module processed the input at multiple scales simultaneously-using 1x1, 3x3, and 5x5 convolutions in parallel-and concatenated the results. This allowed the model to extract both fine and coarse features within the same layer, making it both accurate and computationally efficient.



The key difference was this: VGG sought depth through repetition, while Inception sought depth through diversity.
The vanishing gradient problem and the rise of ResNet
As researchers began building deeper networks, they encountered a serious limitation-vanishing gradients. The early layers of a deep network often failed to receive meaningful updates during training. This problem made very deep networks unreliable.
In 2015, the ResNet architecture from Microsoft Research introduced a simple but powerful idea: skip connections. Instead of forcing each layer to learn a complete transformation, ResNet allowed layers to learn a residual-the difference between the input and the desired output. This residual was then added back to the input, effectively letting information flow across layers without degradation.

This technique enabled the successful training of networks with 50, 101, even 152 layers. The architecture became foundational. Many later models either built directly on ResNet or incorporated its principles.

Interestingly, the residual connection is mathematically similar to Euler integration. In numerical methods, we add small changes (derivatives) to known values to compute the next state. ResNet does something similar, layer by layer.
Compactness and connectivity: SqueezeNet and DenseNet
With the growing success of deep models came a new concern-model size. Large networks were difficult to train and even harder to deploy, especially on mobile or embedded systems.
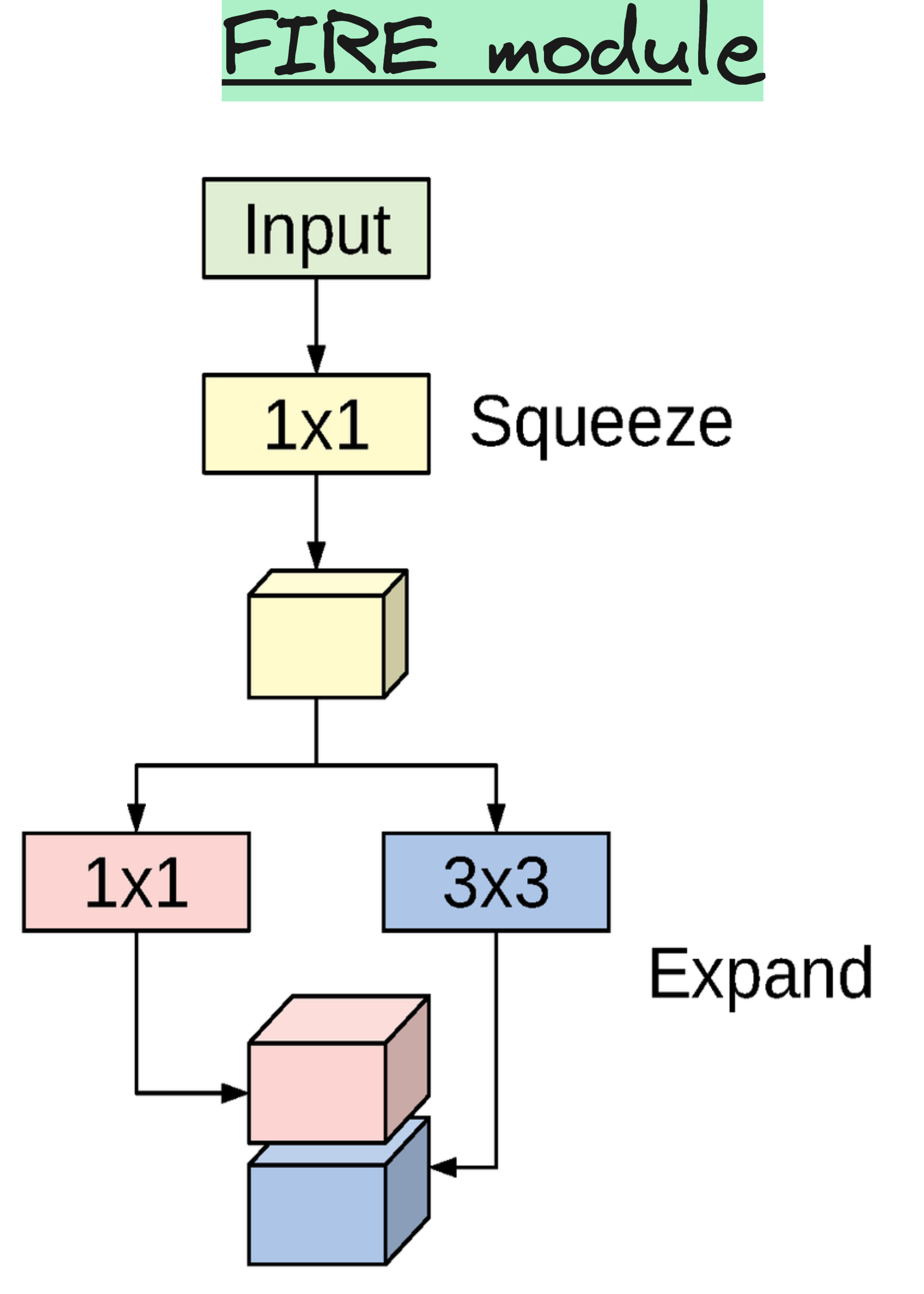
SqueezeNet, introduced in 2016, tackled this head-on. Its goal was to achieve AlexNet-level accuracy with fifty times fewer parameters. It introduced Fire modules, which used a squeeze layer (1x1 convolutions) followed by an expand layer (a mix of 1x1 and 3x3 convolutions). The result was a model under half a megabyte in size.

That same year, DenseNet proposed a different approach to connectivity. Instead of skipping one or two layers like ResNet, DenseNet connected every layer to every subsequent one. This design ensured better feature reuse and improved gradient flow. The model performed well but came at the cost of increased memory usage.


By now, the trend was clear. Researchers were no longer just stacking layers-they were designing architectures.
MobileNet and the edge AI movement
In 2017, Google introduced MobileNet. The purpose was clear: make deep learning usable on mobile devices.

MobileNet employed depthwise separable convolutions. In a traditional convolution, each filter operates across all input channels. In a depthwise separable convolution, each channel is processed separately (depthwise), followed by a pointwise convolution (1x1) to mix them. This approach reduced the computational load significantly while maintaining accuracy.

The message was simple: deep learning no longer belonged only to data centers.
Neural Architecture Search: NASNet
By 2018, architecture design had become increasingly complex. Google Brain posed a new question: could a neural network design another neural network?

This idea, called Neural Architecture Search (NAS), led to NASNet. A recurrent neural network (RNN) was trained to generate architectures, which were then evaluated using reinforcement learning. The process was computationally intensive-reportedly taking 500 GPUs and four days-but it worked.

NASNet produced two types of modules: normal cells and reduction cells. These modules were then repeated to build the final architecture. While the performance was strong, the cost of discovering the architecture made it impractical for most settings.

Still, the idea of automated model design had entered the field.
EfficientNet and the art of scaling
If NASNet asked how to design architectures automatically, EfficientNet asked how to scale them properly.

Rather than arbitrarily increasing depth or width, EfficientNet proposed a compound scaling method. Starting from a small baseline model (EfficientNet-B0), one could scale up depth, width, and input resolution together using fixed coefficients.
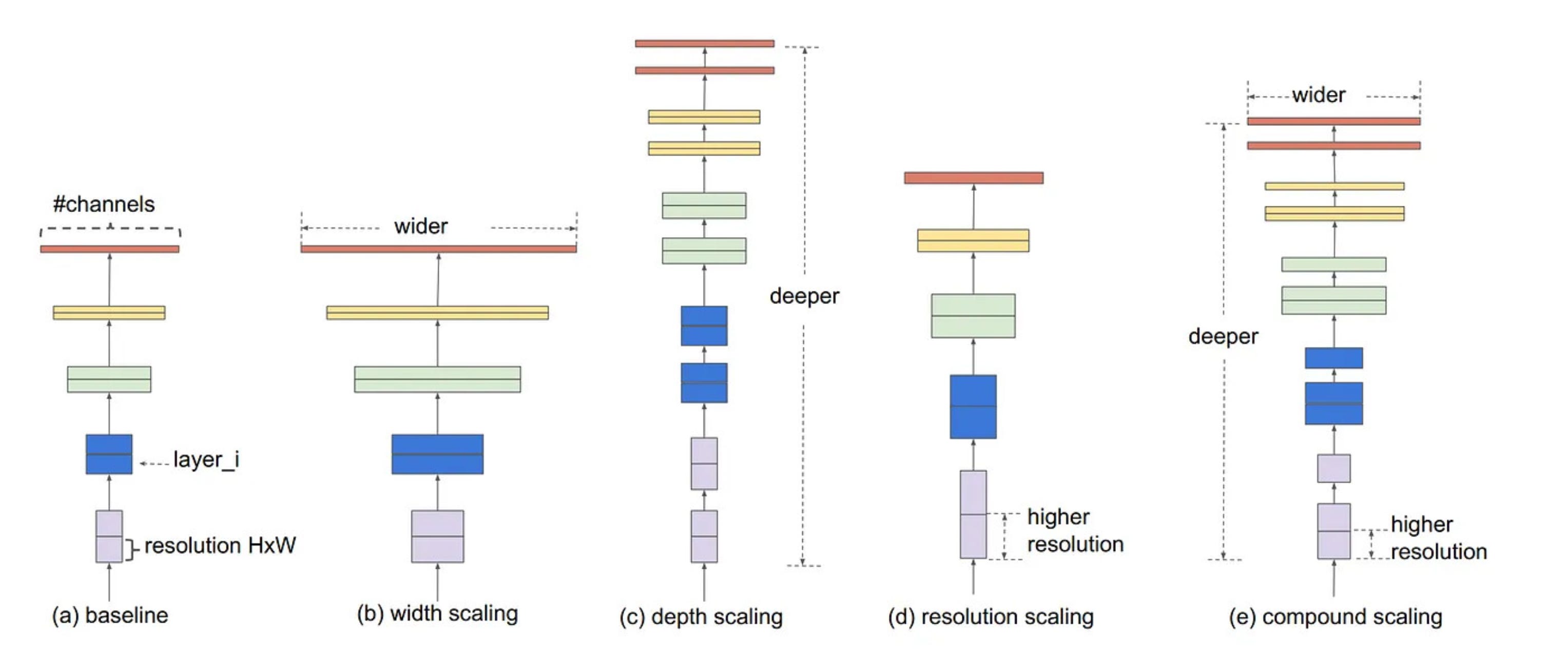
This method proved surprisingly effective. EfficientNet models achieved state-of-the-art accuracy with fewer parameters and computations. In practice, EfficientNet became one of the most popular models for both research and production settings.
Modular and non-modular CNNs

Competitions and community
None of these developments happened in isolation. They were driven, in large part, by competitions.
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ran from 2010 to 2017. It provided a standard benchmark-1.2 million labeled images, 1000 classes-and a visible leaderboard. Winning ImageNet became a mark of prestige.
Other competitions like the COCO challenge (focused on object detection and segmentation) and high-stakes Kaggle competitions further fueled innovation.
These public benchmarks created the conditions for progress: a shared goal, competitive pressure, and a community of motivated researchers.

Practical usages

What came after
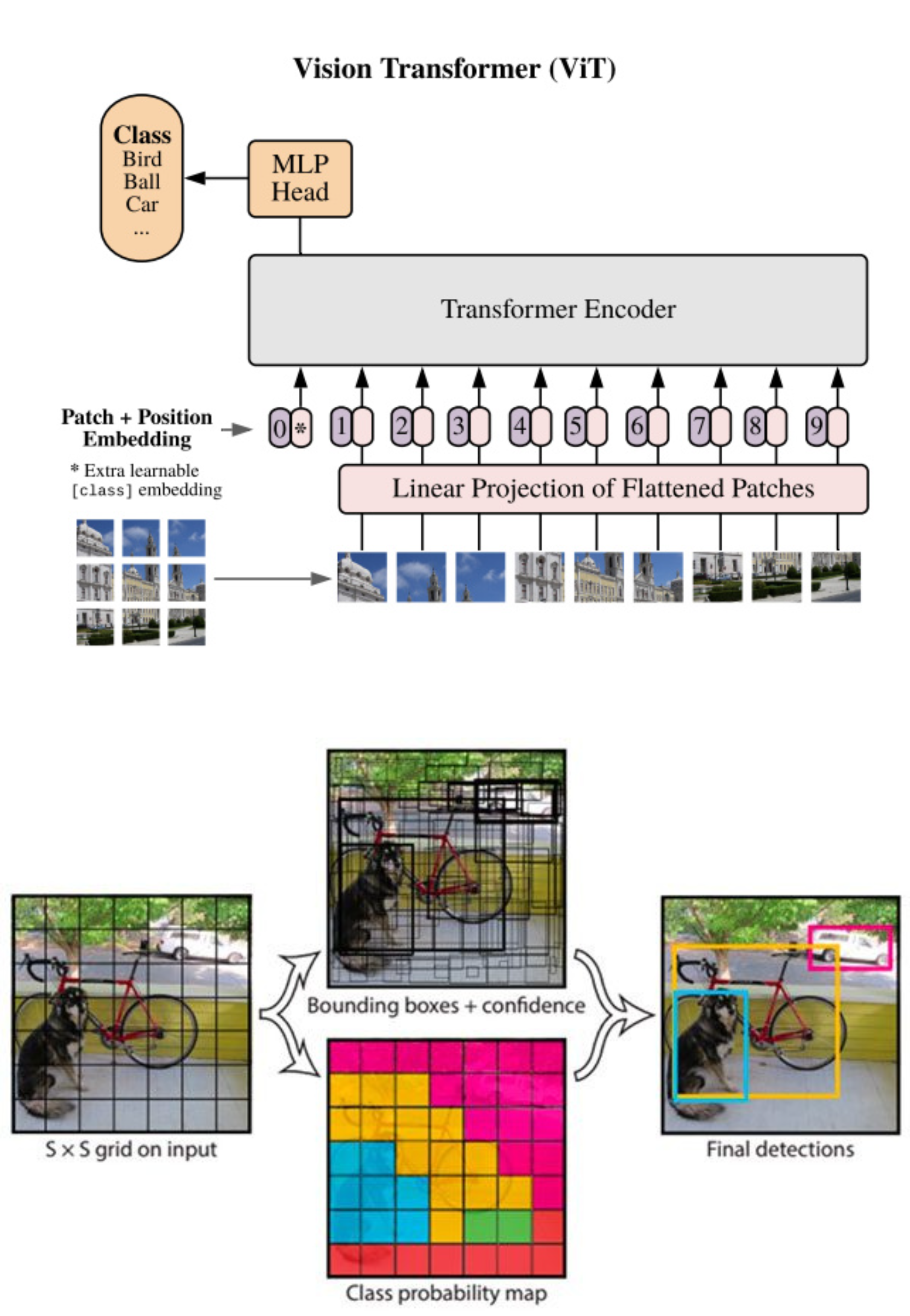
Post-2019, the field began exploring alternatives to CNNs. Vision Transformers (ViTs) applied the transformer architecture-originally developed for natural language processing-to image data. Hybrid models like ConvNeXt borrowed ideas from both CNNs and transformers. YOLOv7 and YOLOv8 continued to push the boundaries of real-time object detection.
But this is a separate story, one we will explore in a future lecture.
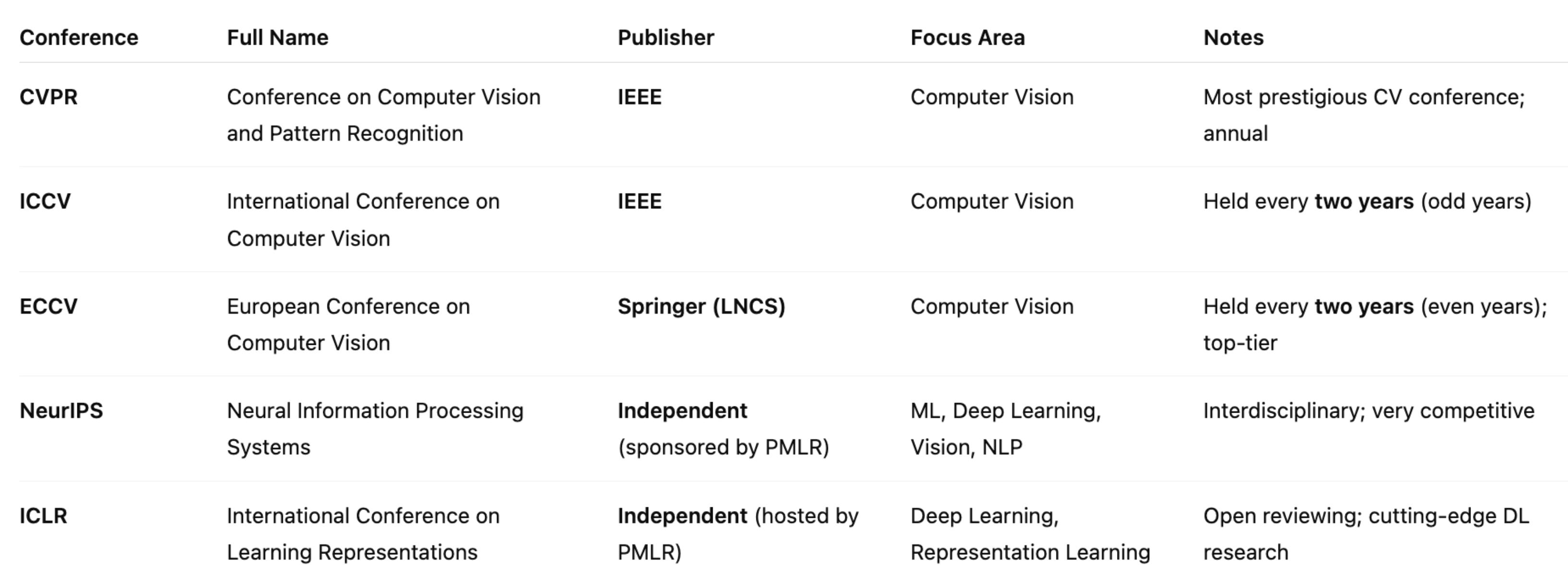
Conferences, journals, and influential papers

In conclusion
The history of convolutional neural networks is not just a technical chronology. It is a reflection of how problems were understood, how ideas evolved, and how constraints-computational, architectural, practical-shaped design.
AlexNet showed that deep learning worked. VGG proved that depth could be simple. Inception made models efficient. ResNet solved the gradient problem. SqueezeNet brought compression. DenseNet enhanced connectivity. MobileNet made vision mobile. NASNet automated design. EfficientNet scaled wisely.
Each of these models was a response to the needs of its time.
And each one reminds us that progress in AI is neither linear nor accidental. It is historical.
YouTube lecture
You can watch the full lecture that this article is based on here:
If you found this helpful, consider subscribing to the newsletter. We are building a library of AI content that balances depth, clarity, and curiosity.
Interested in learning AI/ML LIVE from us?
Check this out: https://vizuara.ai/live-ai-courses/
Moving illustrations looks cool, how create ?