
𝗪𝗵𝘆 𝗗𝗼𝗲𝘀 𝗟𝟭 𝗥𝗲𝗴𝘂𝗹𝗮𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗗𝗿𝗶𝘃𝗲 𝗖𝗼𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁𝘀 𝘁𝗼 𝗭𝗲𝗿𝗼?


Regularization is a crucial technique in Machine Learning to address overfitting, with 𝗟𝟭 (𝗟𝗮𝘀𝘀𝗼) and 𝗟𝟮 (𝗥𝗶𝗱𝗴𝗲) being the most widely used methods. Understanding their differences can significantly enhance model performance.
𝗟𝟭 𝗥𝗲𝗴𝘂𝗹𝗮𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 adds a penalty term to the loss function:
Loss Function = MSE + 𝛼 ∑ ∣𝑤𝑗∣
𝗟𝟮 𝗥𝗲𝗴𝘂𝗹𝗮𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 uses a squared penalty term:
Loss Function = MSE + 𝛼 ∑(𝑤𝑗)2
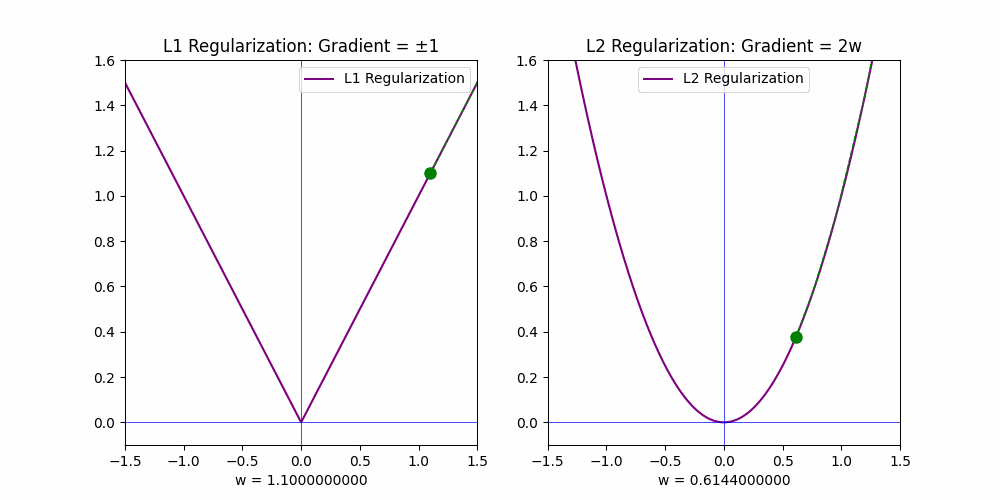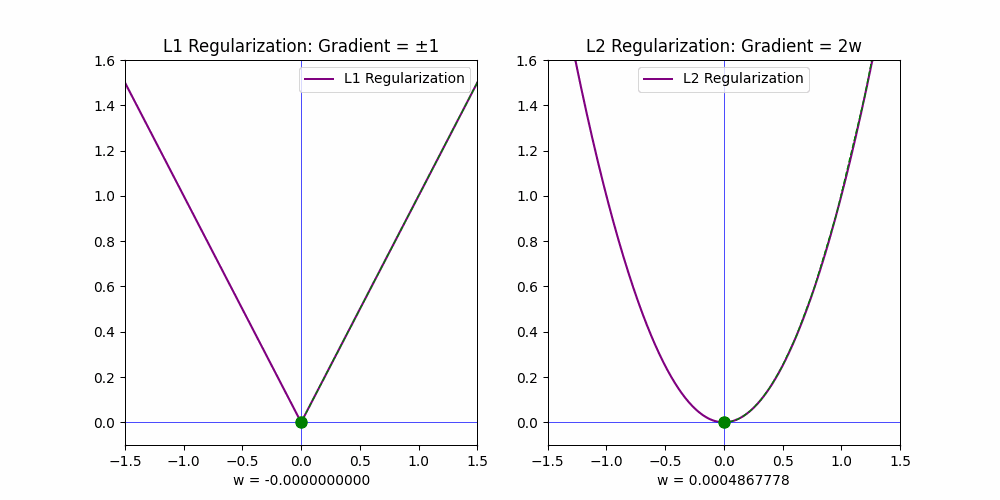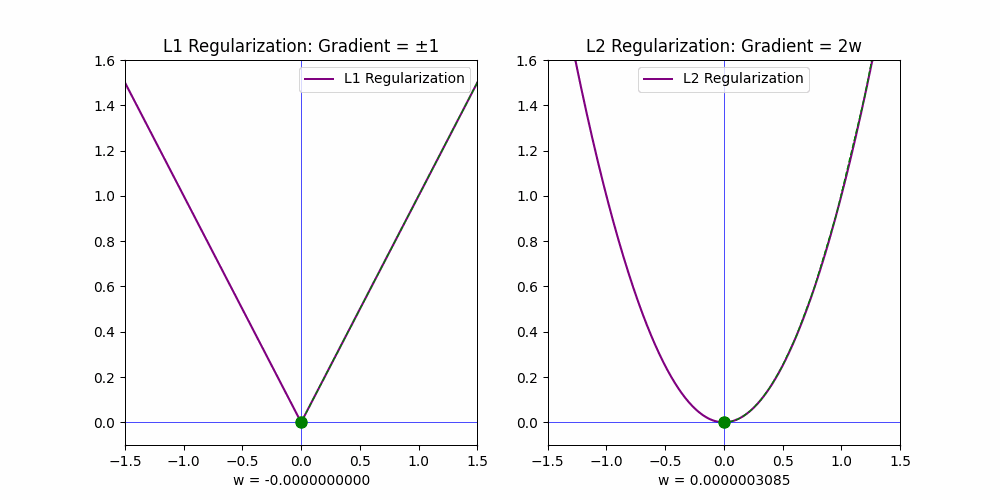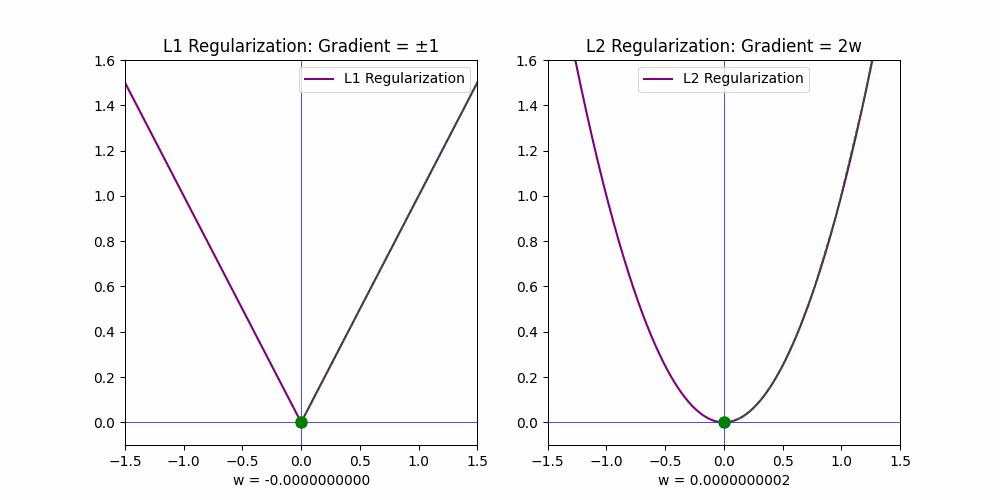
The gradients of these penalties explain their behavior:
• For L1, the gradient is constant (+1 or −1), which drives weights to zero quickly.
• For L2, the gradient is proportional to the weight (2w), so it decays as the weights approach zero, leading to small but non-zero values.
This distinction makes 𝗟𝟭 𝗶𝗱𝗲𝗮𝗹 𝗳𝗼𝗿 𝗳𝗲𝗮𝘁𝘂𝗿𝗲 𝘀𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻, as it reduces the weights of irrelevant features to exact zero, while L2 generally shrinks weights closer to zero without fully eliminating them.
To better understand the impact of L1 and L2 regularization, I created an animation that visualizes their effects. The animation demonstrates how L1 effectively removes irrelevant features while L2 merely reduces their influence.
📂 𝗖𝗼𝗱𝗲 𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗹𝗲 𝗟𝟭 𝘃𝘀 𝗟𝟮 𝗥𝗲𝗴𝘂𝗹𝗮𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗔𝗻𝗶𝗺𝗮𝘁𝗶𝗼𝗻 : https://github.com/pritkudale/Code_for_LinkedIn/blob/main/L1_vs_L2_Regulerization.ipynb
📹 Watch my latest video on tackling overfitting with practical strategies: Ways to Improve Testing Accuracy: Overfitting & Underfitting by Pritam Kudale
#MachineLearning #DataScience #Regularization #L1L2 #Overfitting #AI #FeatureSelection