
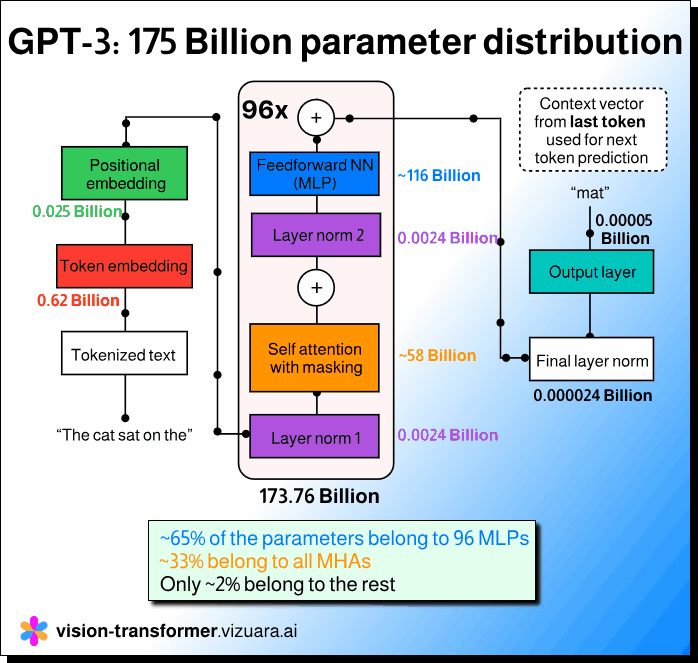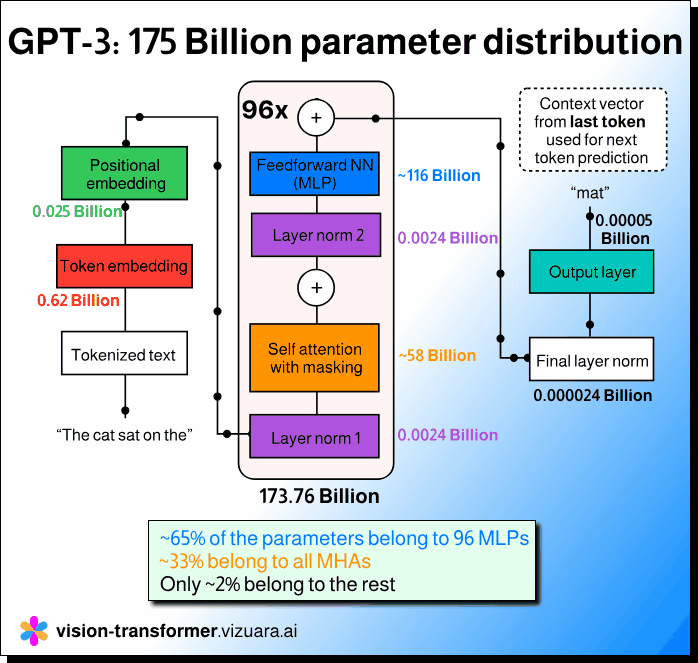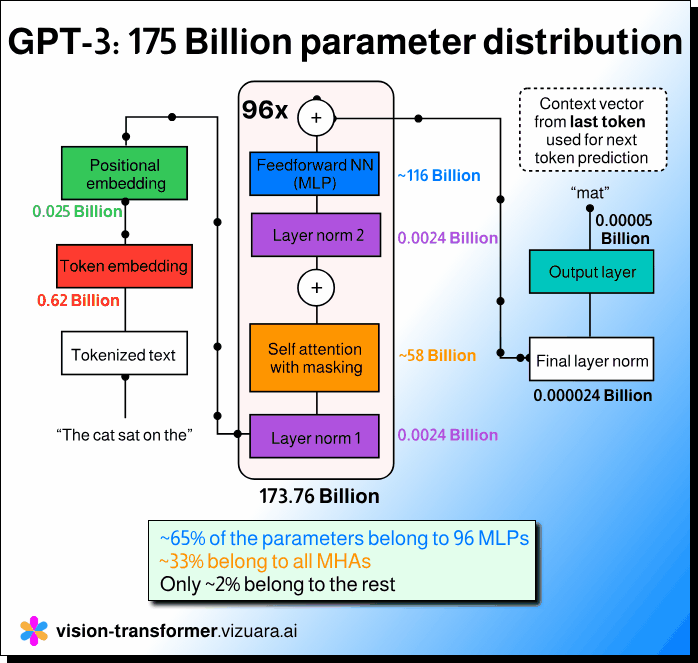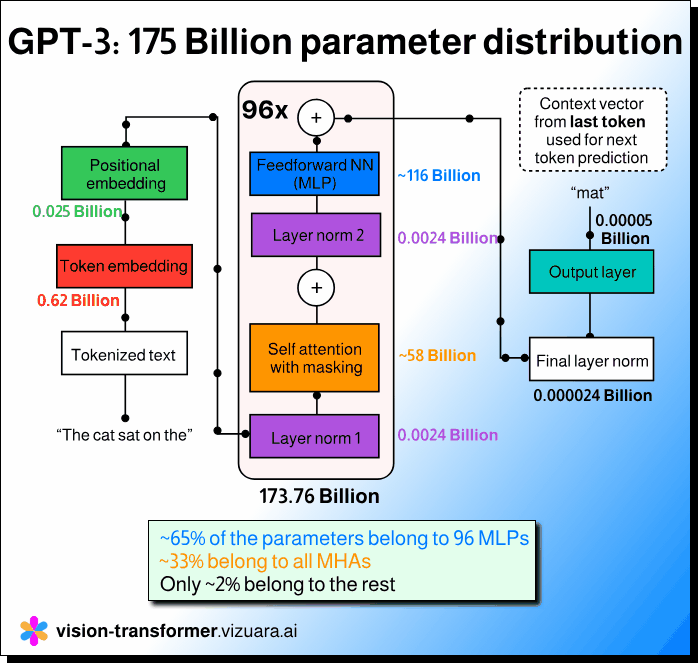
2/3rd of trainable parameters in GPT-3 belong to MLP. Not attention heads.
2-minute read


When people talk about Transformers, the first thing that comes to mind is the attention mechanism. It was the most significant innovation that allowed models to relate different parts of a sequence efficie
ntly and changed how deep learning models processed information. Because of this, there is a very common assumption that most of the parameters in large language models such as GPT-3 are concentrated inside the multi head attention. However, that assumption is not accurate.

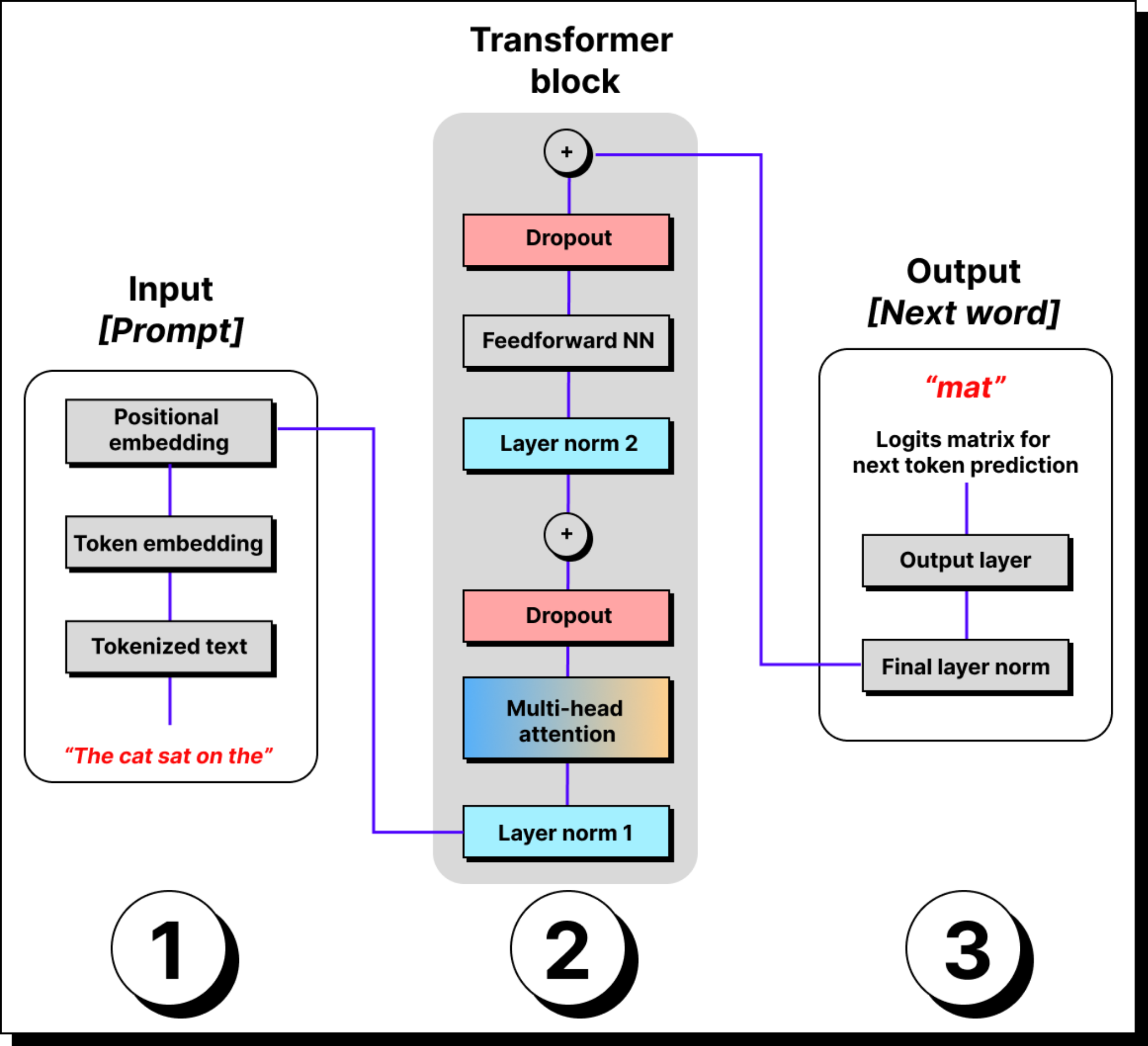


If we take the GPT-3 model with 175 billion parameters and actually study its architecture layer by layer, the picture looks quite different. About 65 to 66 percent of the trainable parameters belong to the feedforward networks, or the MLPs, that come after the attention layer in each Transformer block. The multi head attention layers, which receive most of the attention in discussions, account for only about one third of the total parameters. Everything else combined, including token and positional embeddings, layer norms, and the output projection layer, accounts for barely two percent.


This simple observation changes how one should think about model design and optimization. Each Transformer block in GPT-3 is repeated 96 times, and in every block the MLP section is the largest in terms of parameter count. While attention helps in capturing dependencies and context, the feedforward network actually contains the dense weight matrices that dominate memory and computation. This is why most of the model’s size and training cost lie in those MLP layers, not in the attention mechanism itself.




Understanding this distribution is important because it helps researchers and engineers make more informed decisions when they fine tune, prune, or compress large models. If the goal is to reduce size or improve inference speed, it is not enough to focus on the attention part alone. Knowing that the MLP layers hold most of the parameters helps guide where to apply optimization techniques.
I have explained this parameter distribution in detail in a lecture on Vizuara’s YouTube channel, using the same visual that breaks down GPT-3’s 175 billion parameters into attention, MLP, and other components. It is a concise but essential piece of understanding for anyone who wants to move beyond the surface of the Transformer architecture.
YouTube lecture
Join pro
